万字详解玩转MySQL
Posted 八只脚抠脚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万字详解玩转MySQL相关的知识,希望对你有一定的参考价值。
mysql语法
前言
MySQL的语法虽然简单,但是内容还是比较多的,因此写上这篇文章,方便与大家一起学习,共同进步,欢迎各位大佬的批评指正错误.
数据库的分类
数据库可以分为关系型数据库与非关系型数据库
关系型数据库:是指采用了关系模型来组织的数据库.相当于一个二维的表格(此处可以联想到Excel表格),常见的关系型数据库有(Oracle/MySQL/SQL Server).
非关系型数据库(NoSQL):通常值数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定.非关系型数据库存储数据的格式可以是Key- Value形式(memcached/redis),基于文档型(mongodb),基于图形(Neo4j)等等.
MySQL安装
相信各位大佬看完这些链接就能顺利安装成功MySQL.
数据库的基础操作
安装好之后我们就可以来编写SQL代码
创建数据库:
语法:
create database (数据库名)
示例:创建blog数据库
create database blog; -- blog为数据库名
注:-- 为SQL的注释
运行上述代码之后我们的数据库就创建好了,那么我们怎么样才能查看我们创建成功的数据库呢?通过下面代码就能显示已有的数据库.
显示数据库
语法:
SHOW DATABASES;
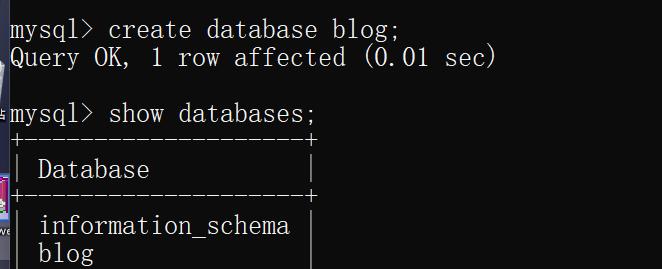
创建好数据库之后我们就要对数据库进行操作前,我们先要选中数据库才能对数据库进行操作,
运行下面的代码就能操作你想操作的数据库.
使用数据库
语法
use (数据库名);
示例:使用blog数据库
use bolg;

删除数据库
语法:
drop database (数据库名);
示例:删除blog数据库
drop database blog;
通过上述代码就能成功删除我们创建的blog数据库,但是我们在工作中要谨慎使用这个操作,不然就得准备跑路了.

SQL中的基本类型
数值类型
| 数据类型 | 大小 | 说明 | 对应的java类型 |
|---|---|---|---|
| BIT(M) | M指定位数默认为1 | 二进制数,m的范围从1到64 存储数值范围从0 - 2^m - 1. | 常用Boolean对应BIT,此时默认是1位,即只能存0和1 |
| TINYINT | 1字节 | Byte | |
| SMALLINT | 2字节 | Short | |
| INT | 4字节 | Integer | |
| BIGINT | 8字节 | Long | |
| FLOAT(M,D) | 4字节 | 单精度,m指定长度,D指定小数位数,会发生精度丢失. | Float |
| DOUBLE(M,D) | 8字节 | Double | |
| DECIMAL(M,D) | M/D最大值+2 | 双进度,M指定 长度,D表示小数点位数,精确数值 | BigDecimal |
| NUMERIC(M,D) | M/D最大值+2 | 和DECIMAL一样 | BigDecimal |
1.数值类型可以指定为无符号类型
2.对应的数字范围:
有符号:-2^(字节数8 - 1) 到 2 ^(字节数8 - 1) -1
无符号:0 - 2^(字节数*8) -1
3.decimal类型以时间以及空间的代价,来使表示的精度更精确.
字符串类型
| 数据类型 | 大小 | 说明 | 对应java类型 | 对应c类型 |
|---|---|---|---|---|
| VARCHAR[SIZE] | 0-65535字节 | 可变长度字符串 | String | char[] |
| TEXT | 0-65535字节 | 长文本数据 | String | char[] |
| MEDIUMTEXT | 0-16777215字节 | 中长度文本数据 | String | char[] |
| BLOB | 0-65535字节 | 二进制形式的长文本数据 | BYTE[] | char[] |
日期类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| DATETIME | 8字节 | 范围从1000到9999年,不会进行时区的检索及转换 | java.util.Date/java.sql.Timestamp |
| TIMESTAMP(时间戳) | 4字节 | 范围从1970到2038年,自动检索当前时区进行转换 | java.util.Date/java.sql.Timestamp |
timestamp是以1970年1月日0时0分为基准时间,截止到2038-01-19 03:14:07
timestamp的日期格式为YYYY-MM-DD HH:MM:SS
MySQL中表的操作
1)创建表
语法:
create table [表名] (列名 类型名,列名 类型名)
注意:表名不能和SQL的关键字冲突,也可以使用 (`)反引号来引用
示例: 创建一个学生表,包含学号,姓名,省份证号码,成绩.
create table student (id int,name varchar(20),chinese decimal(5,2),math decimal(5,2),english decimal(5,2));
2)查看已创建的表
语法:
show tables;
示例:显示已创建的表
show tables;
运行结果:

通过该语句我们可以查看我们所选中的数据库中的表.
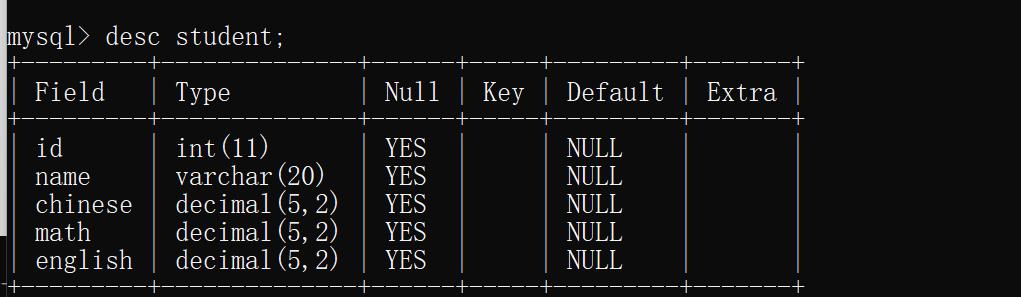
3)查看指定表结构
语法:
desc [表名]
desc student;
运行结果:
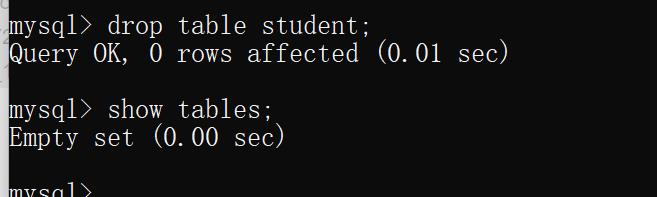
4)删除表
语法:
drop table [表名]
示例:删除 student 表
drop table student;
与删除数据库相同,删除表操作的风险极大,请谨慎使用.
运行结果:
SQL语句使用--空格+描述 来注释
create table student (id int,name varchar(20),chinese decimal(5,2),math decimal(5,2),english decimal(5,2)); -- 我是注释
运行上述代码 – 后的代码不执行.
运行结果:

MySQL表的增删改查(CRUD)
新增元素(create)
语法:
insert into [表名] values ();-- 插入所有列的数据
insert into [表名] (指定的列名) values();-- 插入指定列的数据
insert into [表名] values (),(),…;-- 插入多行数据
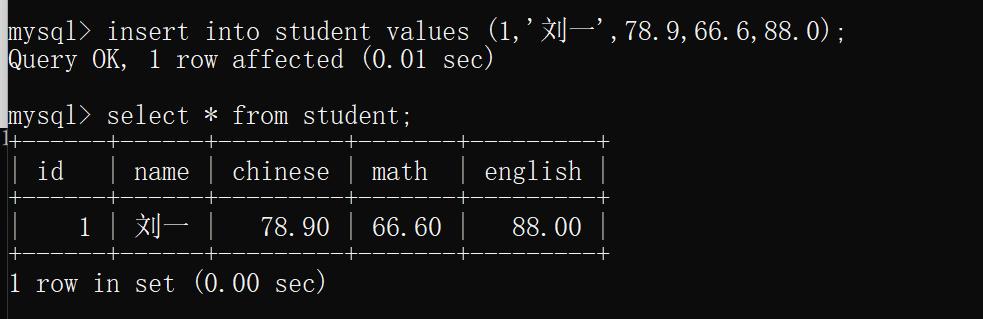
示例1: 插入一行数据
insert into student values (1,'刘一',78.9,66.6,88.0);
运行结果:
示例二:只插入姓名与语数英的成绩(没有插入的列默认为null)
insert into student (name,score) values ('陈二',88.7);
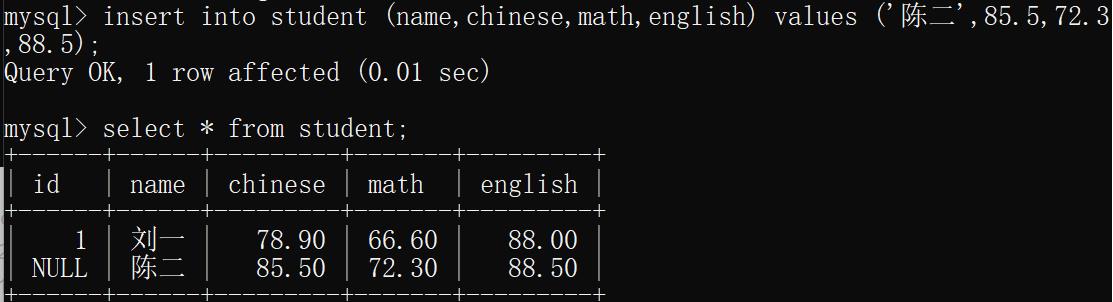
示例三: 插入多行数据
insert into student values
(3,'张三',89.7,52.5,76.5),
(4,'李四',99.6,79.5,89.7),
(5,'王五',71.5,99.5,88.6);
运行结果:
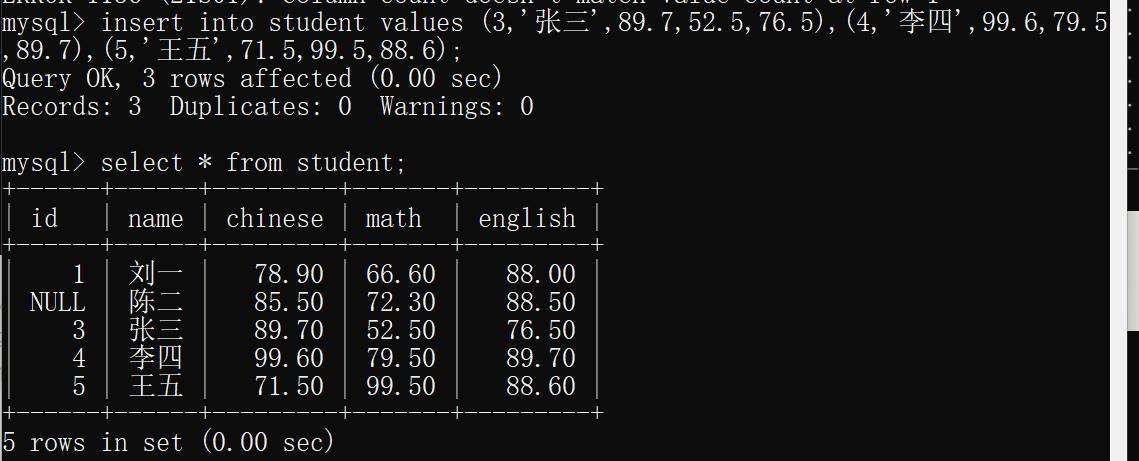
示例四:插入多行指定列数据(姓名,成绩)
insert into student (name,Chinese) values
('赵六',66.7),
('孙七',77.7),
('周八',88.8);
运行结果:

查找(retrieve)
1)全列查找
语法:
select * from [表名]; (这样的查找方式仅限在测试环境中使用,切不能再生产环境中使用,否则会给生产环境的服务器造成很大的负担,甚至服务器卡死.)
示例:查看学生表中的所有列的数据
select * from student;
运行结果:
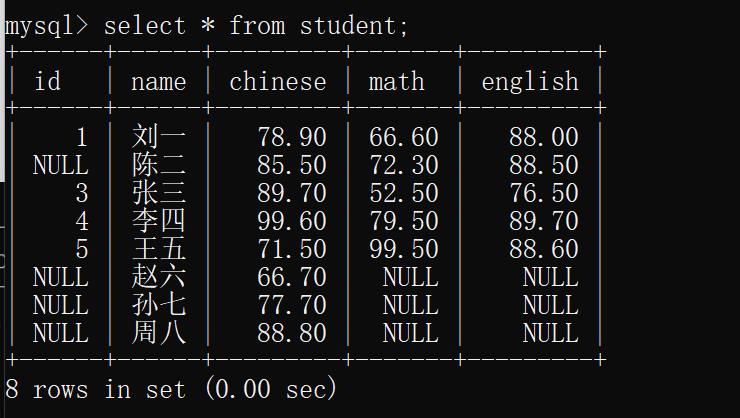
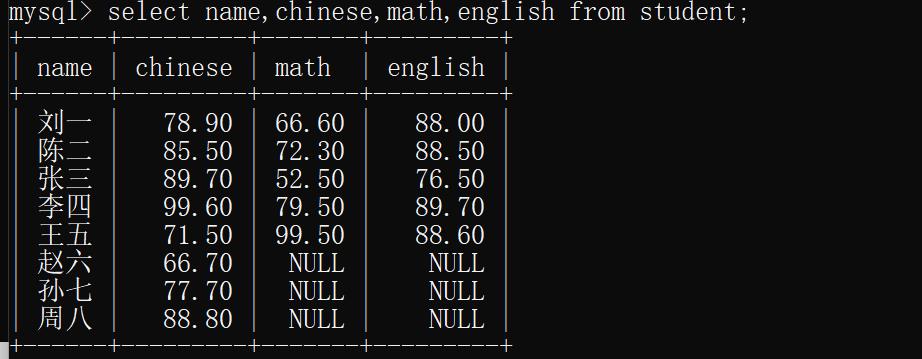
2)指定列查找
语法:
select [列名] from [表名];
示例:只查看姓名与成绩
select name,chinese,math,english from student;
运行结果:
3)查询字段为表达式
select 表达式 from 表名;
示例: 查找所有同学的姓名和总成绩
select name,chinese+math+english from student;
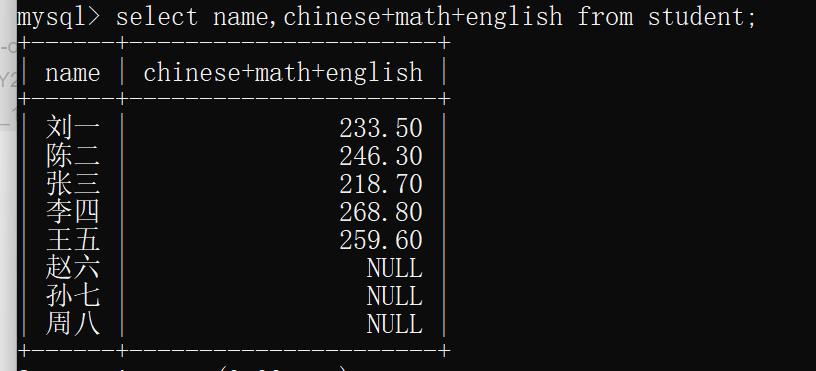
注:任何数与null球和都为null上图中后三位同学的成绩为NULL.
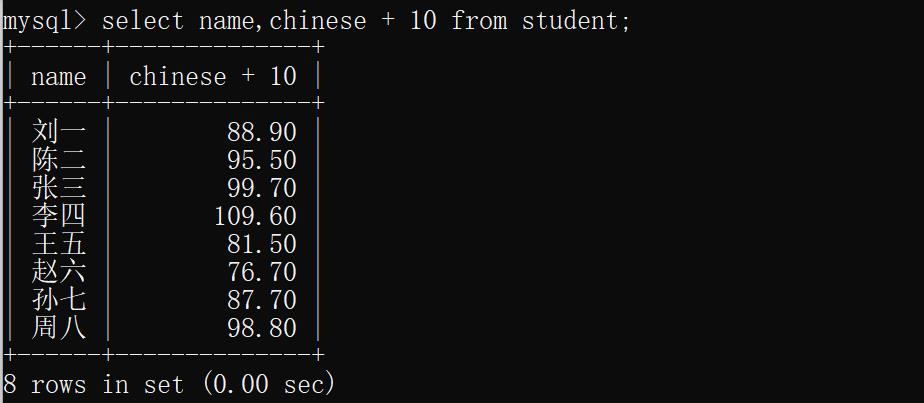
示例2:所有同学的语文成绩+10分
select name,chinese + 10 from student;
运行结果:
4)查找字段指定别名
语法
select [列名] (as) [别名] from [表名];-- 其中ask可以省略
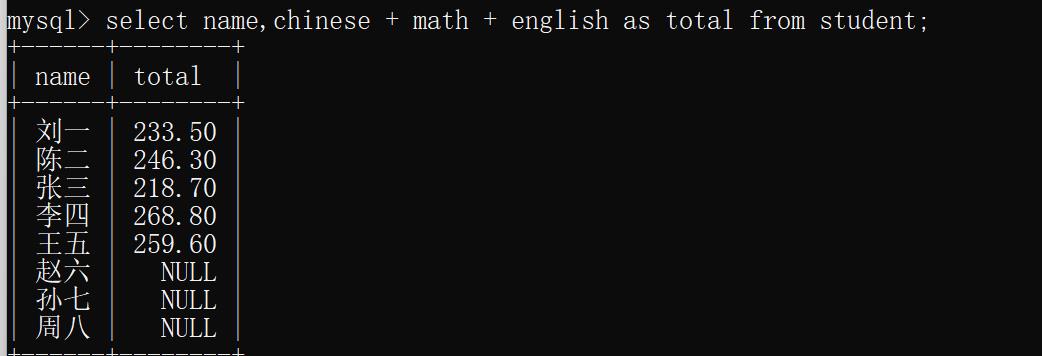
示例: 将总成绩列名指定为total;
select name,chinese + math + english as total from student;
运行结果:
5)去重
语法:
select distinct [列名] from [表名];
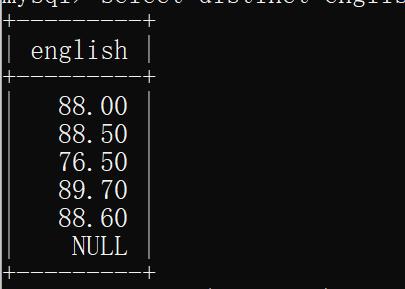
示例:去除重复的英语成绩
select distinct english from student;
运行结果:(将成绩为null的成绩去重了)
6)排序
语法:
select [列名] from [表名] order by [列名] acs(升序)/desc(降序);-- 默认为升序
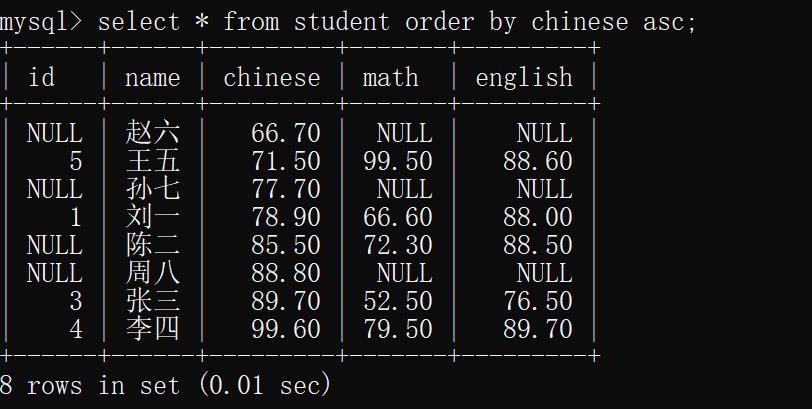
示例1:查找同学的信息并按照语文成绩升序
select * from student order by chinese asc;
运行结果:
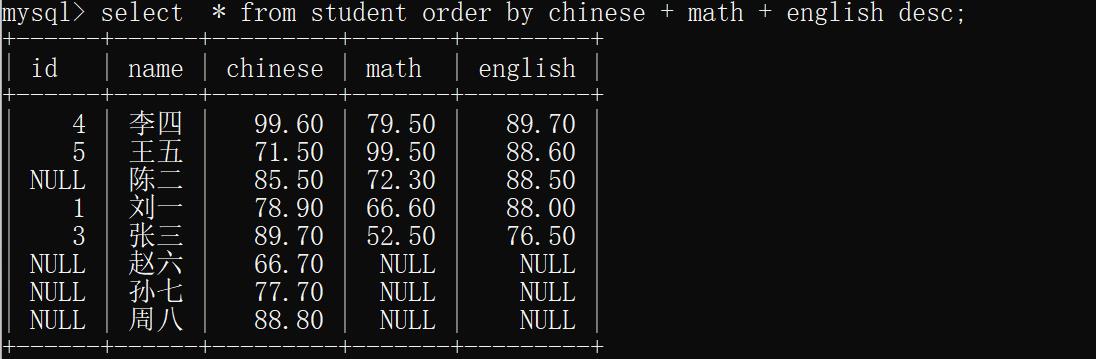
示例2:查找同学信息并按照总成绩降序
select * from studnt order by chinese + math + english desc;
运行结果:(其中默认NULL为最小值)
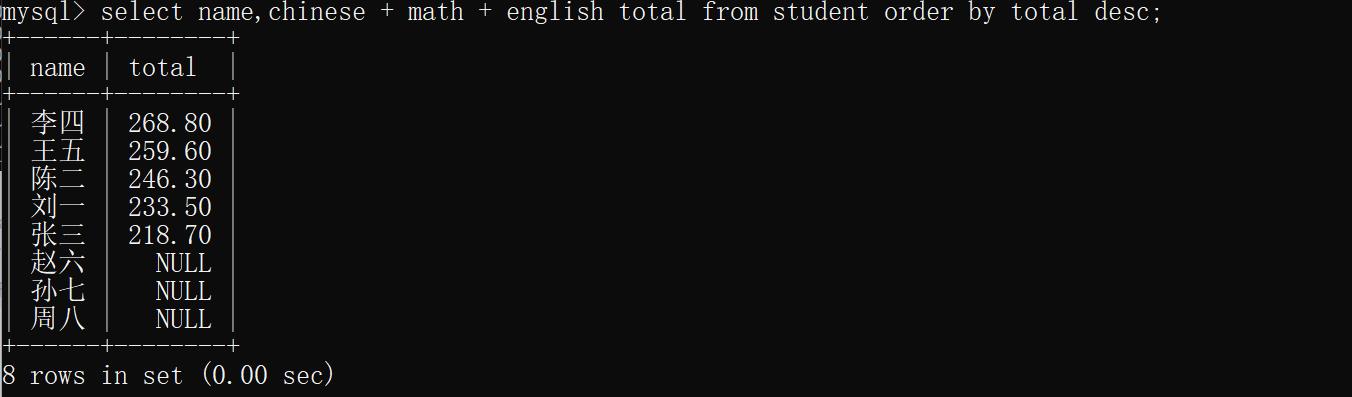
示例3:按照总成绩排序,使用别名
select name,chinese + math + english total from student order by total desc;
运行结果:
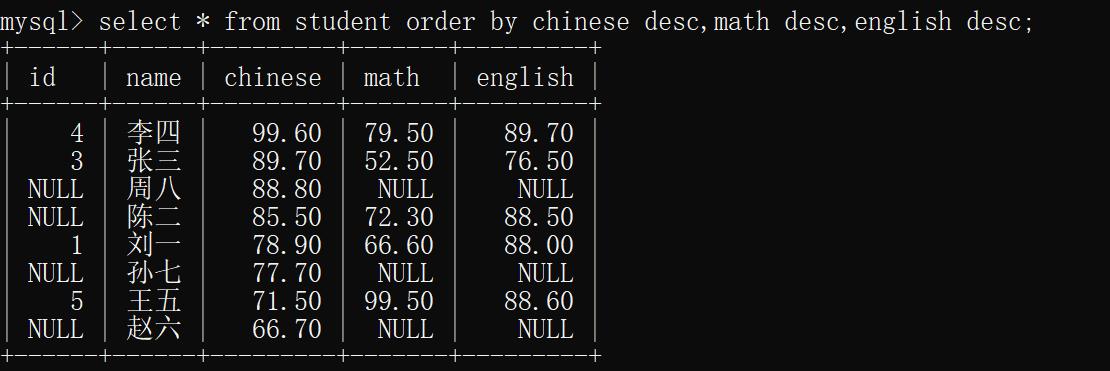
示例4:按照多个列进行排序(先把所有同学的信息按照语文,数学,英语的顺序降序排序)
select * from student order by chinese desc,math desc,english desc;
运行结果:(当前一项相同时比较后一项)
7)条件查询(where)
条件查询中涉及的运算符:
| 运算符 | 说明 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于,不能比价NULL,当NULL = NULL 的结果是null |
| <=> | 可以比较NULL,null<=>null的结果是true |
| != /<> | 不等于 |
| between A and B | 范围匹配[A,B],当A<= VALUE<=B,返回true |
| in(option,…) | 如果是option中任意一个,返回ture |
| IS NULL | 是NULL |
| IS NOT NULL | 不是NULL |
| LIKE | 模糊匹配.%表示任意多个(包括0个)任意字符;_表示任意一个字符 |
| and | 多个条件都为true,结果才是true |
| or | 任意一个条件为true,结果就是true |
| not | 条件为true,结果为false |
示例1:查找math为null的记录
select * from student where math <=> null;
//select * from student where math is null;
运行结果:

示例2:查找数学成绩不及格的同学
select * from student where math < 60;
运行结果:

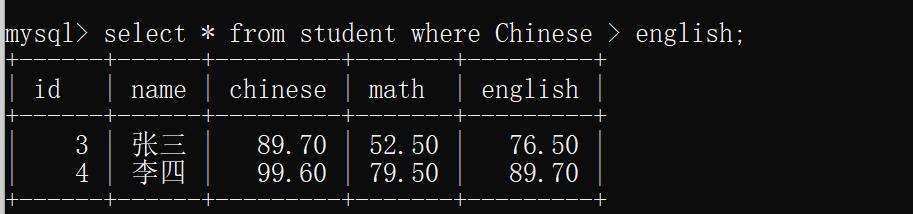
示例3:查找语文成绩比英语好的同学
select * from student where Chinese > english;
运行结果:
示例4:查找总分大于200分的数据
select name,chinese + math + english total from student where chinese + math + english > 200;
运行结果:

示例5:查询语文成绩大于80并且英语大于80
select * from student where Chinese > 80 and English > 80;

示例6:查询英语成绩大于80或者语文成绩大于80的数据.
select * from student where Chinese > 80 or English > 80;
运行结果:

注:当and和or同时出现是,and的优先级要更高一些,所以建议使用时适当加上括号.
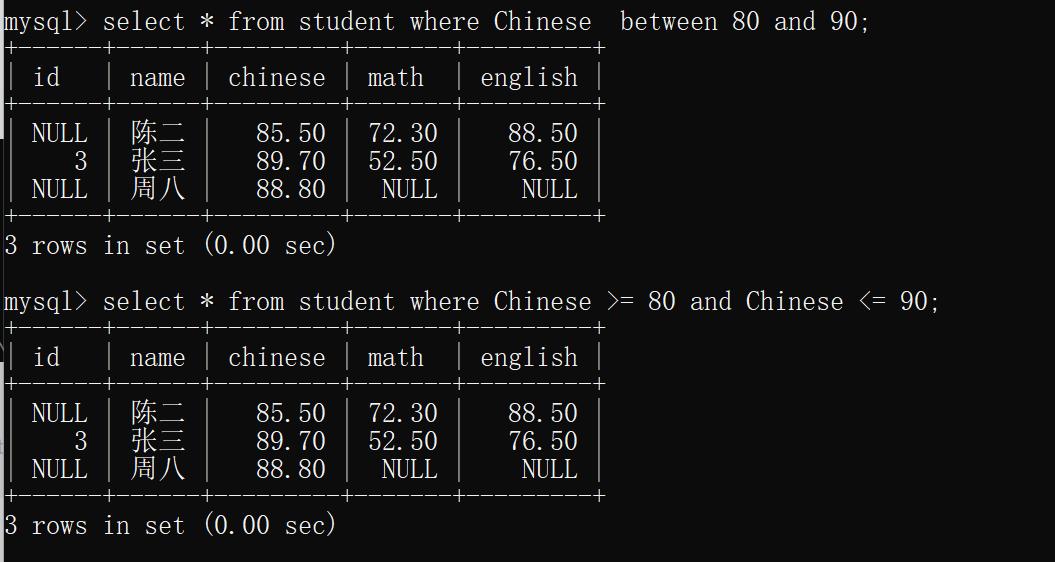
示例7:查询语文成绩在[80,90]之间的数据
select * from student where Chinese between 80 and 90;
select * from student where Chinese >= 80 and Chinese <= 90;
运行结果:
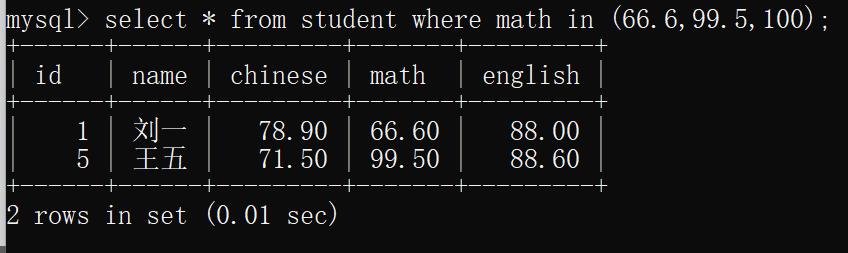
示例8:查询数学成绩是66.6,99.5,100的数据
select * from student where math in (66.6,99.5,100);
运行结果:
示例9)查找姓李的同学的数据
select * from student where name like '李%';
运行结果:

示例9:查找所有同学语文成绩为9开头的数据.
select * from student where Chinese like '9%';

8)分页查找(limit)
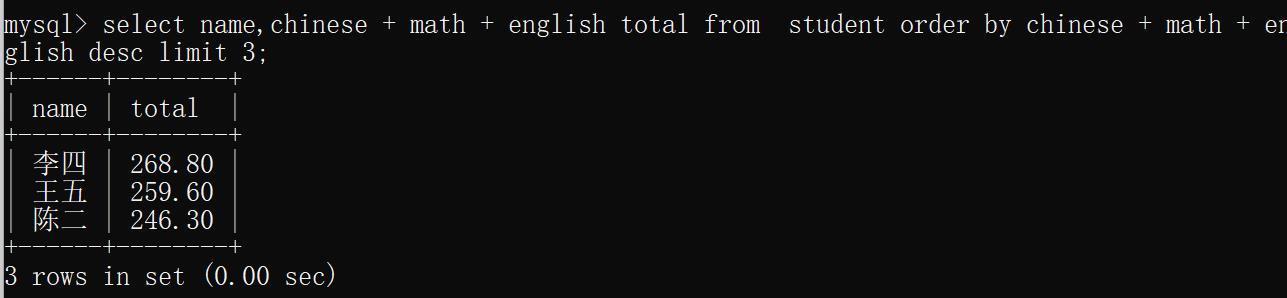
示例1:查找总成绩前三的同学
select name,chinese + math + english total from student order by chinese + math + english desc limit 3;
运行结果:
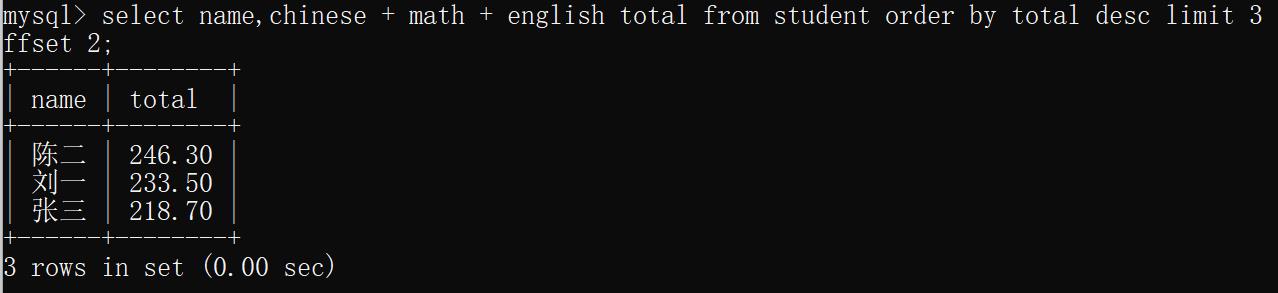
示例2:查找同学信息总分排名为3-5名的数据
select name,chinese + math + english total from student order by total desc limit 3 offset 2;
运行结果:
当limit的数据大于数据的个数是被允许的此时显示的是所有数据.
select name,chinese + math + english total from student order by total desc limit 30 offset 2;
运行结果:

而当偏移量的数据大于数据的个数此时显示的数据就是null.
select name,chinese + math + english total from student order by total desc limit 3 offset 20;
运行结果:
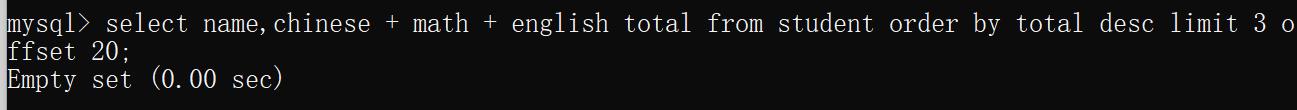
修改(update)
语法
update [表名] set [列名] where(条件)
示例1:把张三同学的数学成绩改成50,语文成绩改成95.
update student set math = 50,Chinese = 95 where name = '张三';
运行结果: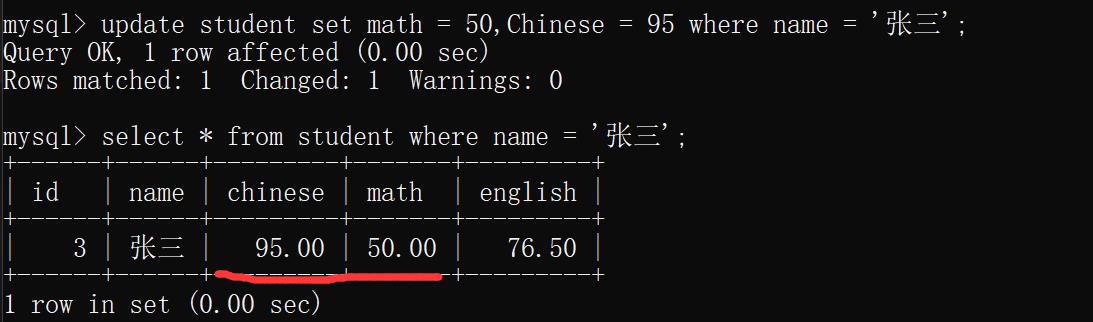
示例2:所有同学语文成绩-10;
update student set Chinese = Chinese -10;
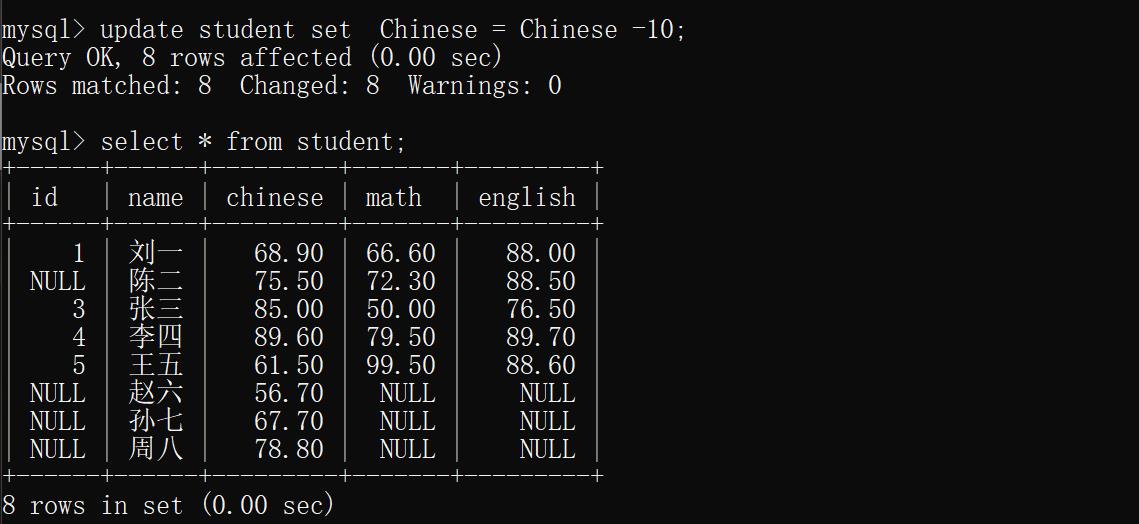
示例3 总成绩最后三位同学的语文成绩+ 20.
update student set Chinese= Chinese + 20 order by chinese + math + english limit 3;
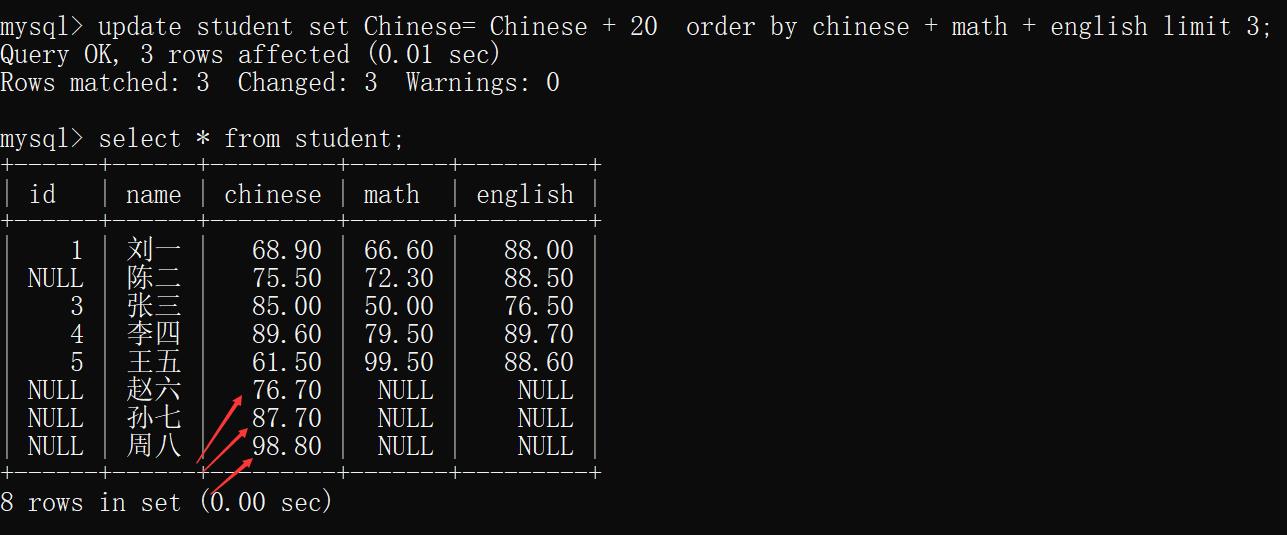
删除操作(delete)
语法:
delete from [表名] where [筛选条件];
示例1:删除周八同学的成绩.
delete from student where name = '周八';
运行结果:
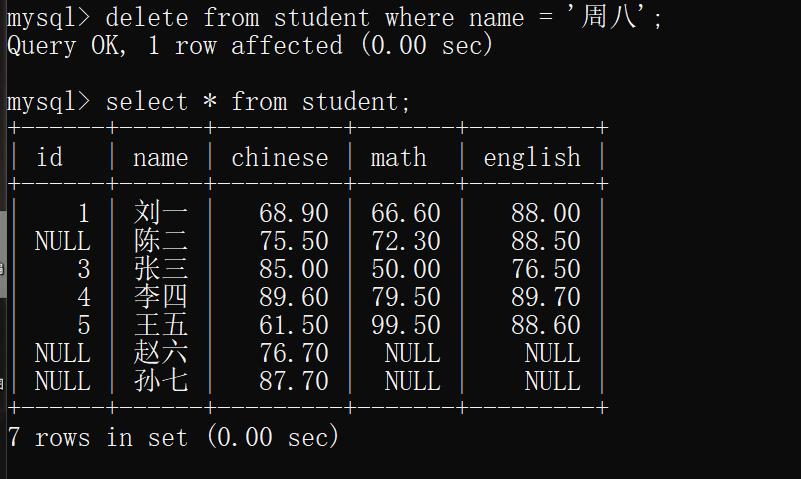
示例2 :删除表中全部数据
delete from student;
运行结果:
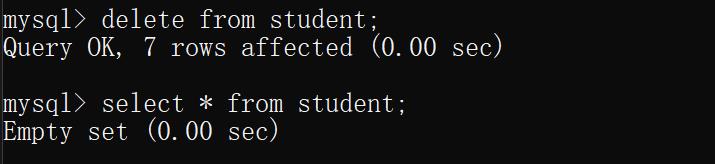
注:删除操作非常危险,一旦数据删除了,通常常规手段是无法恢复的,所以谨慎使用
数据库约束
1)约束类型
| 类型 | 说明 |
|---|---|
| NOT NULL | 指示某列不能存储NULL值 |
| UNIQUE | 保证某列的每行必须有唯一的值 |
| DEFAULT | 规定没有给列赋值时的默认值 |
| PRIMARY KEY | 是 NOT NULL 与 UNIQUE的结合,确保某列有唯一表示,有助于更容易更快速地找到表中的一个特定的记录 |
| FOREIGN KEY | 保证一个表中的数据匹配另一个表中的值的参照性完整 |
| check | 保证列中的值符合指定的条件 |
2)NOT NULL(非空)
指定某列不能为null.
create table student(id int not null,name varchar(20),score decimal(3,1));
insert into student values (null,'张三',99.9);
desc student;
运行结果:

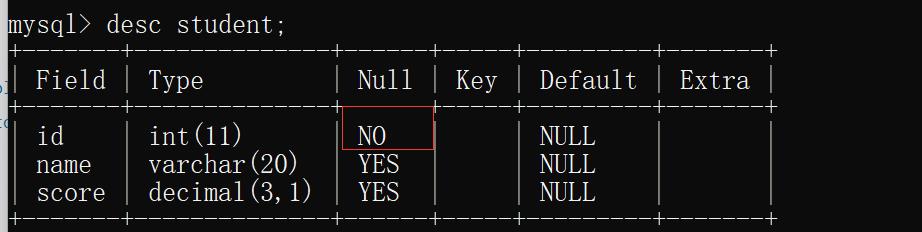
由于ID指定为非空,当插入数据为null时,就会报错.
3)UNIQUE(该列的所有行不能重复)
create table student1(id int unique,name varchar(20),score decimal(3,1));
desc student1;
insert into student1 values
(1,'张三',99.9),
(1,'李四',88.8);
运行结果:

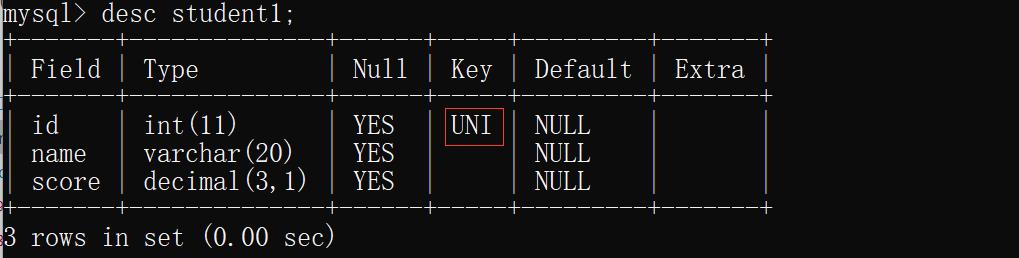
当id重复时就会报错.
4)not null 和 unique 可以同时使用,相当于PRIMARY KEY.
create table student2(id int unique not null,name varchar(20),score decimal(3,1));
create table student3(id int primary key,name varchar(20),score decimal(3,1));
desc stduent2;
desc student3;
运行结果:
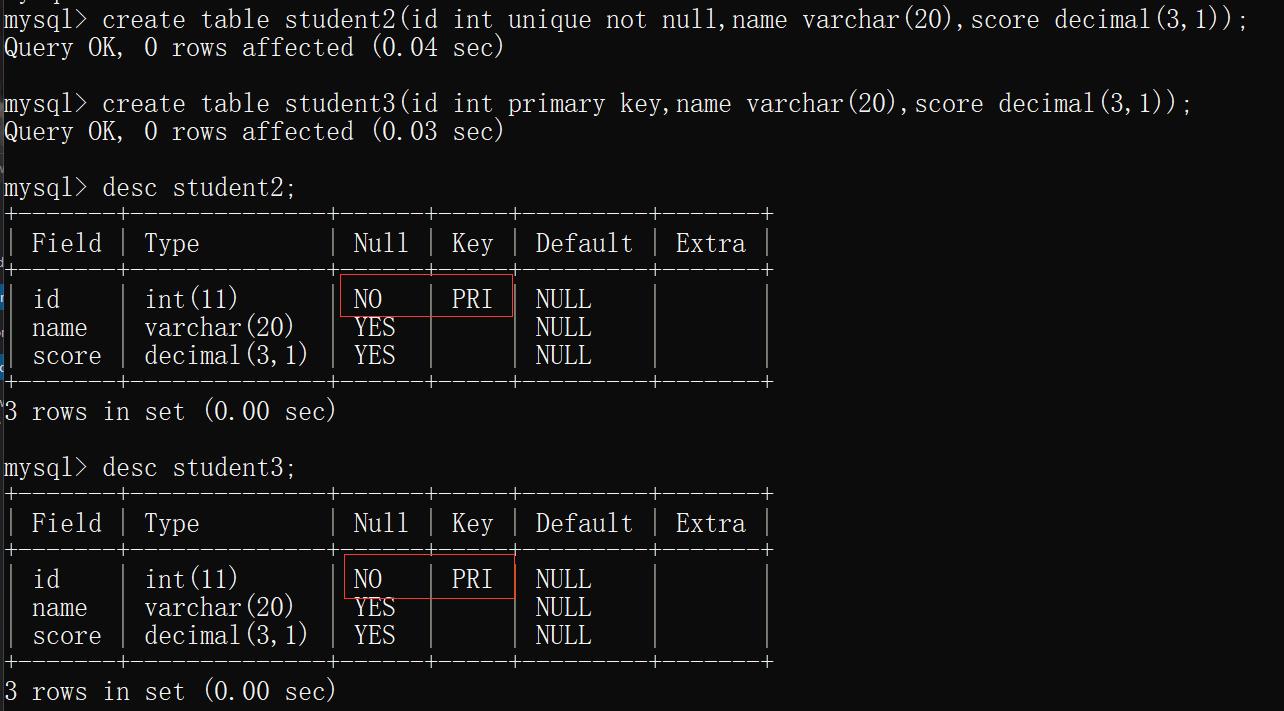
那怎样能能保证主键不重复呢?
我们可以使用auto_increment来自动生成主键的值,来保证主键值不重复.
create table student5(id int primary key auto_increment,name varchar(20),score decimal(3,1));
desc student5;
insert into student5 values
(null,'刘一',66.6),
(null,'陈二',77.7);
select * from student5;
运行结果:

冲上图可以看出,在我们插入数据的时候没有给定id的值,由于设置了自动生成主键的值,自动从1开始生成主键的值.
那要是我们删除其中一个自增主键的值,这个值会不会被重新利用呢?
delete from student5 where name = '陈二';
insert into student5 values
(null,'张三',66.6);
select * from student5;
运行结果:
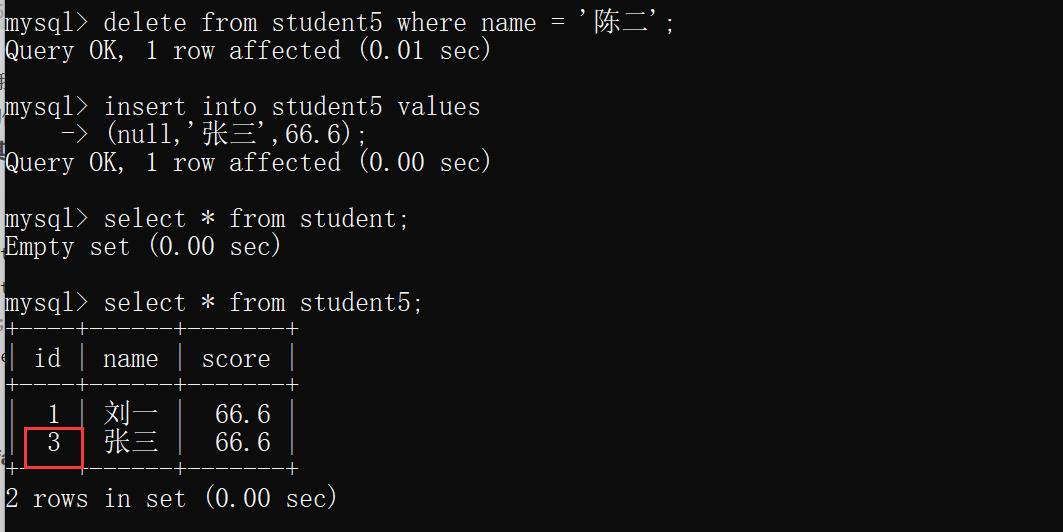
显然从运行结果我们能看出删除的自增主键值不会被重复利用.
需要注意的是,自增主键要注意不要超出数据类型的范围,否则数据会出现溢出的情况,造成严重的后果.
5)设置默认值(default)
create table student4(id int, name varchar(20) default 'unknown',score decimal(3,1));
desc student4;
运行结果;
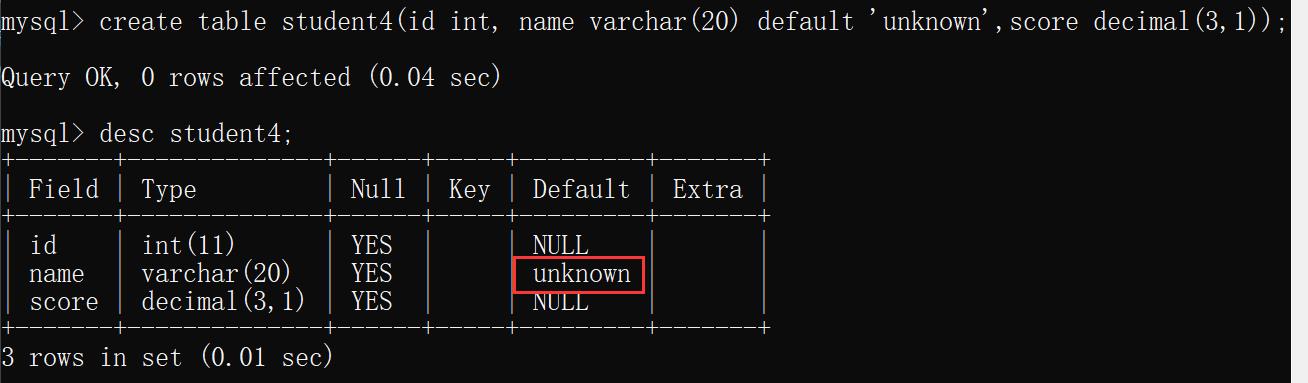
6)FOREIGN KEY(外键)
语法
foreign key [需关联的列名] references [关联的类名];
示例:创建学生表student,一个学生对应一个班级,一个班级对应多个学生。使用id为主键,classes_id为外键,关联班级表id.
create table class (id int primary key auto_increment,name varchar(20),`desc` varchar(100));
create table student (id int primary key auto_increment,name varchar(20),classes_id int, foreign key (classes_id) references class(id));
insert into class values
(null,'1班','年级排名第1'),
(null,'2班','年级排名第2');
select * from class;
insert into student values
(1,'刘一',1),
(2,'陈二',2),
(3,'张三',3);
select * from student;
运行结果:
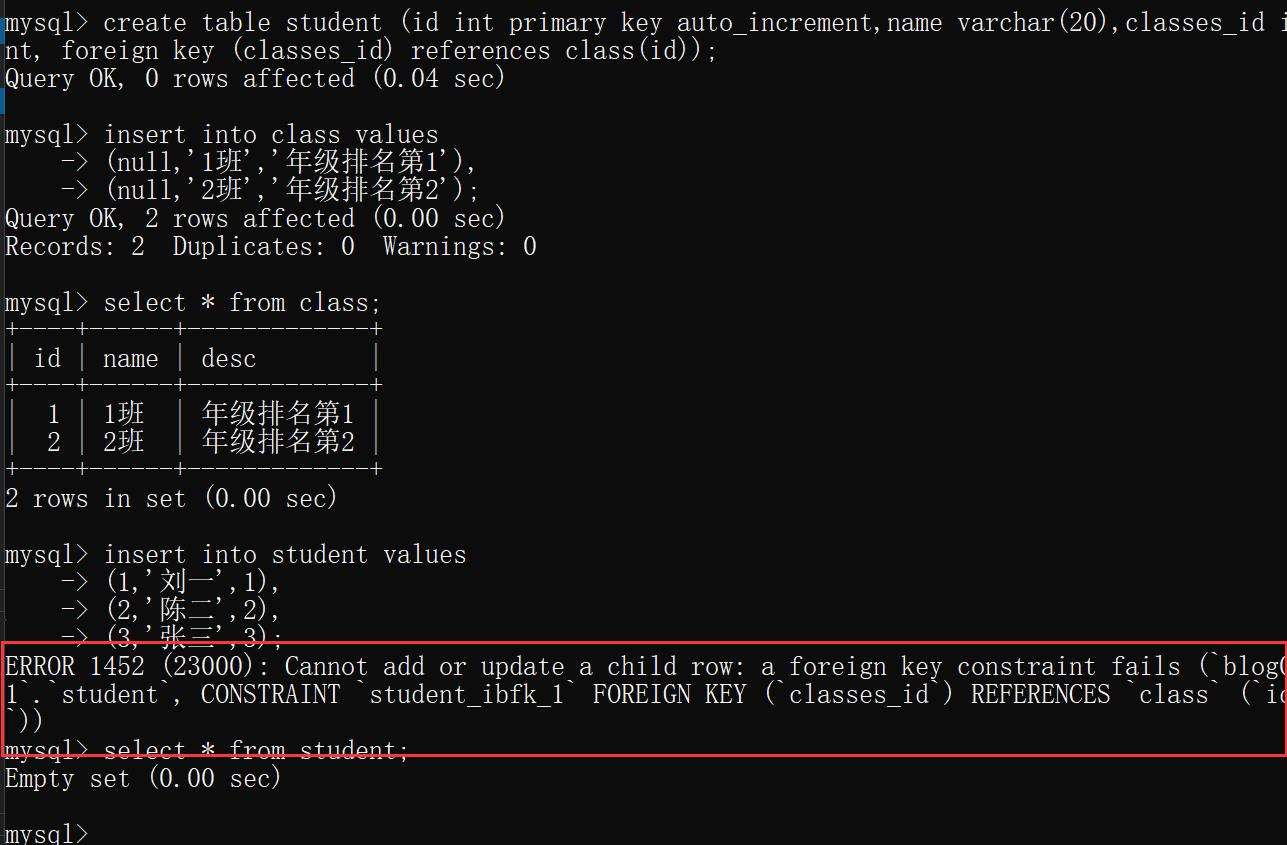
上述代码中class为父表,student为子表,用父表来限制子表,要求子表的数据得在父表中存在.
这里也要求子表中设置foreign key的时候,关联父表的列,需要带上primary key 或者unique.
数据库的设计
1)1对1
每个人与它的身份证就是一一对应的关系的关系.
只需一个表就能描述这种情况.
个人信息/身份证信息(个人id,个人姓名,…,身份证号);
2)1对多
学生与班级之间的关系;一个学生可以属于一个班级,而一个班级可以包含多名学生.
方式1:
班级表:
| 班级id | 班级名称 | 学生id |
|---|---|---|
| 1 | 1班 | 1,2 |
| 2 | 2班 | 3 |
学生表:
| 学号 | 姓名 |
|---|---|
| 1 | 刘一 |
| 2 | 陈二 |
| 3 | 张三 |
方式2:
学生表:
| 学号 | 姓名 | 班级id |
|---|---|---|
| 1 | 刘一 | 1 |
| 2 | 陈二 | 1 |
| 3 | 张三 | 2 |
班级表:
| 班级id | 班级名字 |
|---|---|
| 1 | 1班 |
| 2 | 2班 |
3)多对多
学生 课程 一个学生可以选择多个课程;一个课程也可以被多个同学选择.
需要引入一个中间表
学生表:
| 学号 | 姓名 |
|---|---|
| 1 | 刘一 |
| 2 | 陈二 |
| 3 | 张三 |
课程表:
| 课程id | 课程名 |
|---|---|
| 1 | 语文 |
| 2 | 数学 |
| 3 | 英语 |
中间表:学生/课程表
| 学号 | 课程id | 说明 |
|---|---|---|
| 1 | 1 | 刘一选了语文 |
| 1 | 2 | 刘一选了数学 |
| 2 | 2 | 陈二选了数学 |
| 2 | 3 | 陈二选了英语 |
| 3 | 1 | 张三选了英语 |
插入查询结果
语法:
INSERT INTO TABLE_NAME (需插入的指定列) select 插入的指定列 from [插入数据的表名];
示例:构建user1表和user2表,其中user1为:
| id | name | description |
|---|---|---|
| 1 | 刘一 | 学神 |
| 2 | 陈二 | 学霸 |
| 3 | 张三 | 法外狂徒 |
将user1表中的name,description,列的信息插入user2表中
create table user1 (id int primary key auto_increment,name varchar(20),description varchar(100));
insert into user1 values
(1,'刘一','学神'),
(2,'陈二','学霸'),
(3MySQL 从入门到实践,万字详解!
肝了4.5万字,手把手带你玩转JavaScript(建议收藏)