读者诉苦:Redis 宕机,数据丢了,老板要辞退我
Posted 微观技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读者诉苦:Redis 宕机,数据丢了,老板要辞退我相关的知识,希望对你有一定的参考价值。
微信搜索 【微观技术】,关注这个不喜欢内卷的程序员。
精彩文章汇总 GitHub https://github.com/aalansehaiyang/technology-talk ,Star 12K ,汇总java生态圈常用技术框架、开源中间件,系统架构、数据库、大公司架构案例、常用三方类库、项目管理、线上问题排查、个人成长、思考等知识
大家好,我是Tom哥~
最近跟一位读者聊天,小哥非常郁闷,公司的Redis宕机了,线上业务受到了影响,老板非常愤怒,小哥担心会不会被辞退!
我也很好奇,问小哥Redis主节点挂了,还有备机啊。怎么会影响到业务呢?
小哥说,他们的系统架构只部署一个Redis单实例。节点挂了,数据也丢了。

好吧,既然提到了备份,那今天,我们就来聊下 Redis的主从同步
首先,什么是主从?
主从也称主从集群,部署了多个Redis实例,如下图所示:
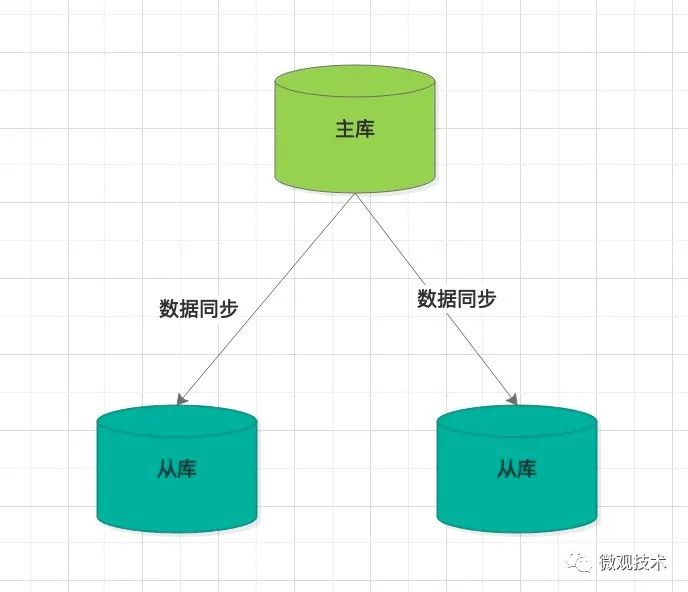
其中,每个实例又有自己的专属职责
-
主库:负责接收读操作、写操作
-
从库:定期同步主库的数据,对外提供读操作
好奇的宝宝可能要问了,为什么从库不能写?
考虑到数据合并的复杂性,假如一个key,多次更新,每次操作在不同的实例上执行,为了保证数据的全局一致性,势必要加全局锁,保证在集群范围上串行化操作且在最新的数据基础上更新,这个成本还是很大的。
为了降低系统复杂度,节约成本。主从同步架构方案一般都是在主库上写,在从库上读。分工明确,职责单一。
可能有同学会提到 Redis Cluster 模式,这个是另一种设计方案。采用水平分割方式,通过CRC16(key)算法,将数据拆分到若干个实例中,每个实例只对自己负责的槽位的数据读、写,从而分摊集群压力。这个属于另一种玩法,本期就不深入展开了。
整理了一份大厂常考面试题,这份pdf包括 Java基础、Java并发、JVM、mysql、Redis、Spring、MyBatis、Kafka、设计模式等面试题,分享给大家。
下载地址:百度云链接:https://pan.baidu.com/s/1XHT4ppXTp430MEMW2D0-Bg 提取码: s3ab
为了保证数据不丢失,Redis提供两种数据同步方式
1、RDB,全量数据同步
2、AOF,增量数据同步,回放日志
这两者有什么区别?
什么时候采用 RDB ? 什么时候采用 AOF ?
接下来,我们逐步分析展开
建立主从关系
首先,启动两个redis 实例,IP地址分别是 192.168.0.1 和 192.168.0.2 ,开始时,他们之间没有任何关联。
我们通过终端命令,登录 192.168.0.2 机器,执行命令
replicaof 192.168.0.1 6379
此时 192.168.0.2 实例就成了 192.168.0.1 的从库。
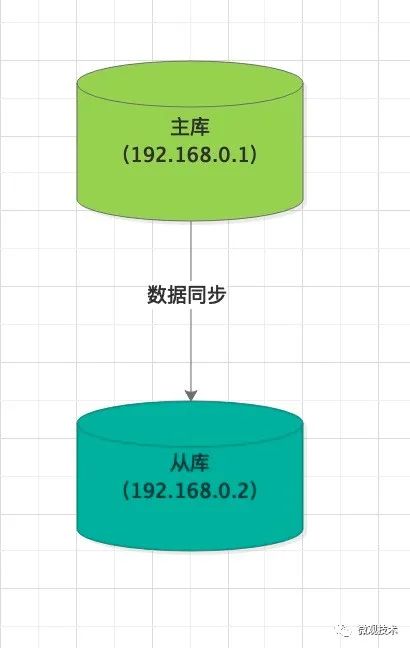
当主从实例建立好关联后,接下来,就开始进入数据同步环节
主从同步
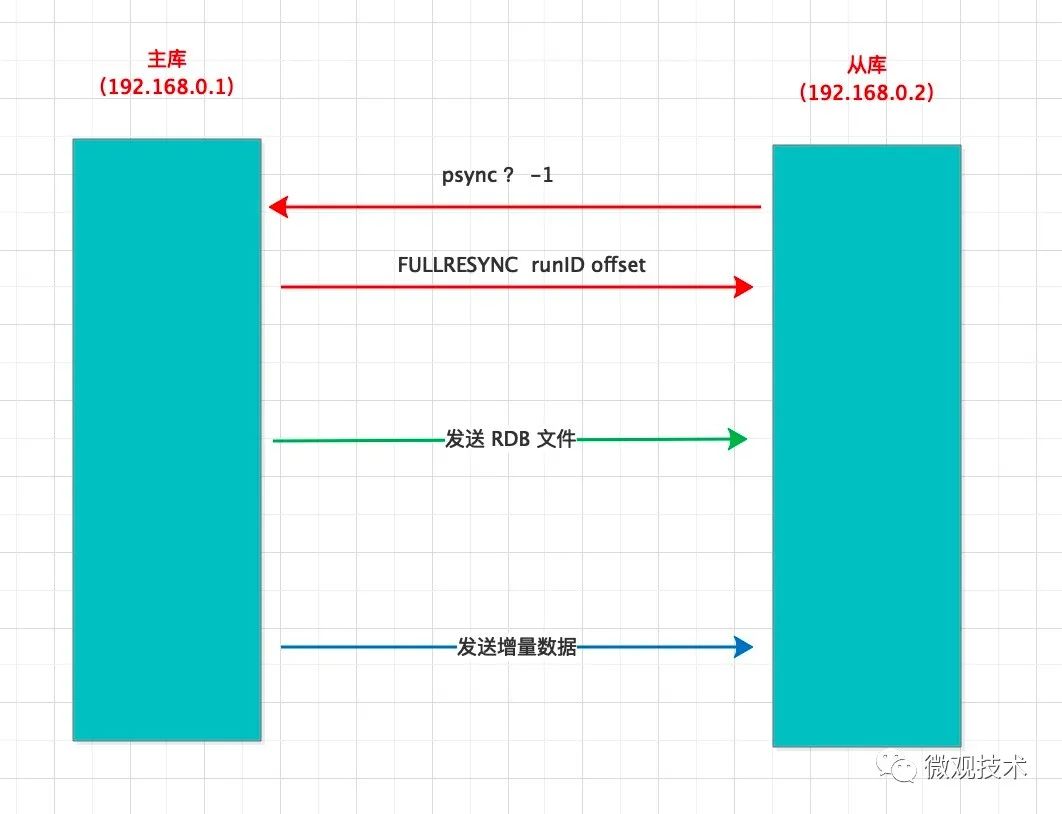
主从库数据同步分为三步:
1、第一步
从库(192.1768.0.2)向主库(192.168.0.1)发送 psync 命令,带了两个参数(主库的runID和同步进度offset)。
- 第一次建立连接时,从库并不知道主库的runID,所以会设置为 ?。offset = -1,表示第一次复制。
说明:每个 Redis 实例初始启动时,会自动生成一个随机ID,用来标识当前实例。
主库接收到psync请求后,会响应 FULLRESYNC ,带有两个参数(主库的runID和同步进度offset)
说明:FULLRESYNC 表示采用全量复制
2、第二步
-
主库fork子进程,执行
bgsave命令,生成 RDB 文件 -
主库将 RDB 文件发给从库
-
从库接到响应后,会先清空当前数据库,然后加载 RDB 文件
说明:主库在生成RDB文件时,主线程是阻塞的,对外不提供服务。一旦RDB文件生成,在数据同步过程中,不受影响,主库可以对外服务。后续的写命令数据会存到 replication buffer
3、第三步
主库将增量写命令发送给从库,从库放映式执行这些命令,从而实现了主从同步。
到这里,主从的核心逻辑基本讲完了。
但生产环境,通常是一主多从,每个从库初始同步时,都要主库生成RDB文件,显然开销很大。有什么解决方案?
一主多从,主库减压
当从节点存在多个时,主库的压力显著增加,具体体现在两个方面:
1、当从库同步主库时,要fork子进程,有多少个从节点,就要fork多少个子进程,每个子进程都要生成RDB。导致主库系统压力过大
2、生成的RDB要同步给从库,占用网络带宽
基于上面的困境,演化出新的模式,“主–从--从”模式,具体玩法如下图:
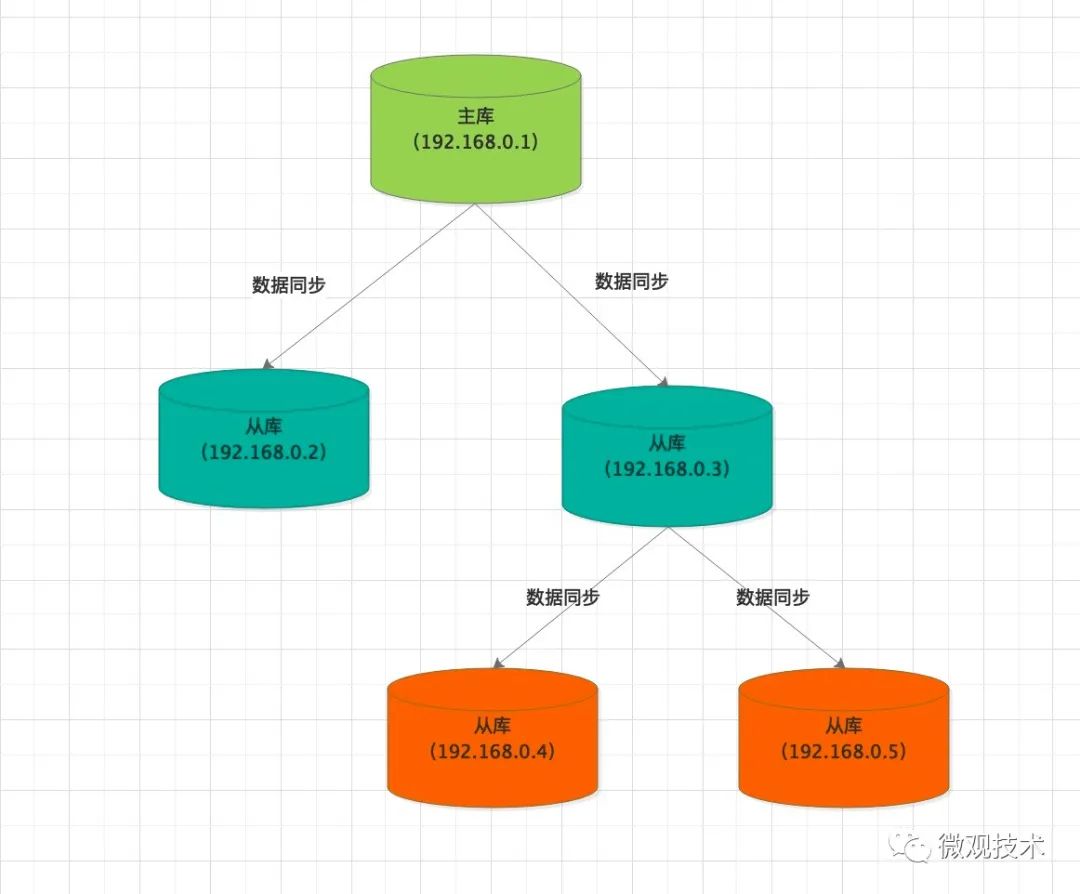
现有虽然有四个从库,但直接跟主库关联同步数据的只有 192.168.0.2 和 192.168.0.3 两个实例,大大减轻了主库的压力。
任何事情都不是一成不变的,网络传输就存在很大的风险,网络闪断了怎么办?对主从同步有什么影响?
网络闪断对主从同步的影响
我们知道主从实例间同步数据主要有两种方式:全量同步 和 增量同步 。 全量同步就是同步RDB文件,那增量同步是如何实现的呢?
这里要引入一个缓冲区,repl_backlog_buffer,它是一个环形设计,增量命令都是先存入这个缓冲区的。主库有生产位移,称之为master_repl_offset 。从库有拉取位移,称之为slave_repl_offset
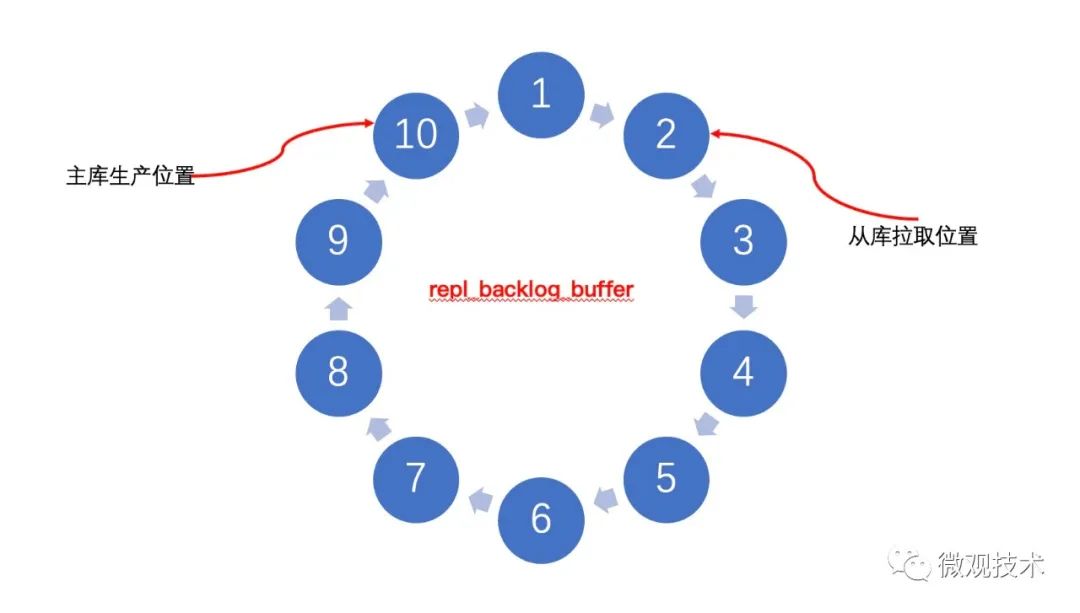
正常情况下,master_repl_offset 和 slave_repl_offset 大小是接近的,也就是说主从库两者间的数据近乎同步。
每次同步数据时,从库向主库发送 psync 命令,把自己的 slave_repl_offset 发给主库,主库基于此偏移位置,向从库发送增量数据。这个很容易理解。
是不是就万无一失了呢?
由于采用了环形结构,如果主库的生产速度比从库的拉取速度快很多时,就会出现套圈现象。
为什么采用环形?主要为了让空间循环使用,像市场的行车记录仪、监控设备等,大多都是采用循环覆盖式存储。如果空间满了,将之前最老的数据覆盖掉。虽然可能丢失了部分数据,但是性价比高。
回到上面的问题,如果被套圈了怎么办?
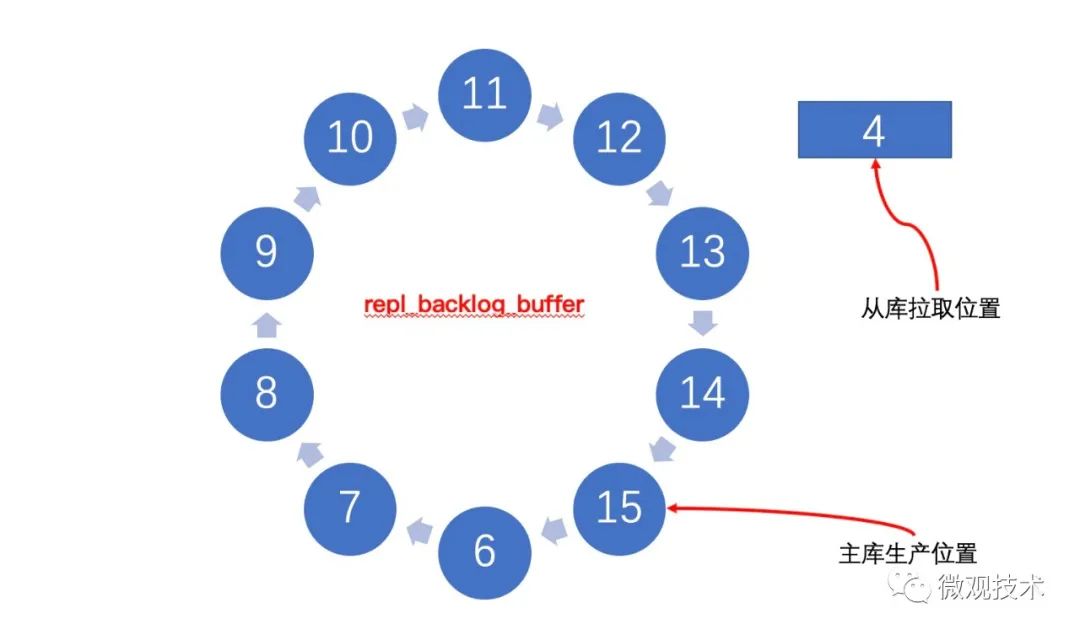
如上图所示,从库 psync 命令,请求的offset 是 4,但是主节点已经生产到了 15 ,将之前的 1、2、3、4、5 全部覆盖掉了。
这下傻眼了,需要同步的数据被覆盖了,惹大麻烦了…

有两个解决方案:
1、调大 repl_backlog_buffer 缓冲区大小,该值是由 repl_backlog_size参数控制
缓冲空间大小 = 主库写入速度 * 操作大小 - 从库拉取速度 * 操作大小
这是我们能主观控制的。比如担心大促带来的流量高峰,可以将这个值调大2倍、3倍、4倍,大家可以根据自己的业务情况自由设置。
2、还有一种方式是Redis 自身提供的解决方案。
此时会触发全量复制,跟第一次建立主从关系同步数据一样。通过全量方式,一次性弥补主从间的数据大缺口。
主节****点挂了怎么办
如果只是传统意义上的主从模式,主节点挂了,通常要手工完成切换。
效率不言而喻了,尤其是线上生产系统,根本没法接受这种方案。
这时候,要引入哨兵机制了,哨兵机制可以实现主从库的自动切换,有效解决了故障转移。整个过程分为三个阶段:监控、选主、通知。
1、监控。哨兵进程会周期给所有的主库、从库发送 PING 命令,检测机器是否处于服务状态。如果没有在设置时间内收到回复,则判定为下线。
当然,网络抖动,也会存在误判可能,如何避免?
引入哨兵集群,多个哨兵实例一起判断,降低误判率。判断标准就是,假如 n 个哨兵实例,至少有 n/2+1 个判定一致,才可以定论。
2、选主。主要是看各个节点的打分情况,打分规则分为 从库优先级、从库复制进度、从库ID号。只要有一轮,某个从库得分最高,则选举它为主库。
-
从库优先级,主要是考虑到不同的机器可能配置不一样,配置高的机器,优先级高一些,通过
slave-priority来配置 -
从库复制进度,主要是看
slave_repl_offset的值大小,值越大表示已经同步的数据越多,得分越高。 -
从库ID号,每个Redis 实例启动时,都会生成一个 ID,在优先级和复制进度相同的条件下,ID号最小的从库分数最高,会被选为新主库。
3、通知。把选举后的新主库发送给所有节点,让所有的从库执行 replicaof 命令,和master建立主从关系、数据同步复制。另外,也会把最新的主库信息同步给客户端。
关于我:Tom哥,前阿里P7技术专家,出过专利,多年大厂实战经验。欢迎关注,我会持续输出更多经典原创文章,为你大厂助力。
欢迎小伙伴找Tom哥唠嗑聊天, 技术交流,围观朋友圈,人生打怪不再寂寞。

以上是关于读者诉苦:Redis 宕机,数据丢了,老板要辞退我的主要内容,如果未能解决你的问题,请参考以下文章