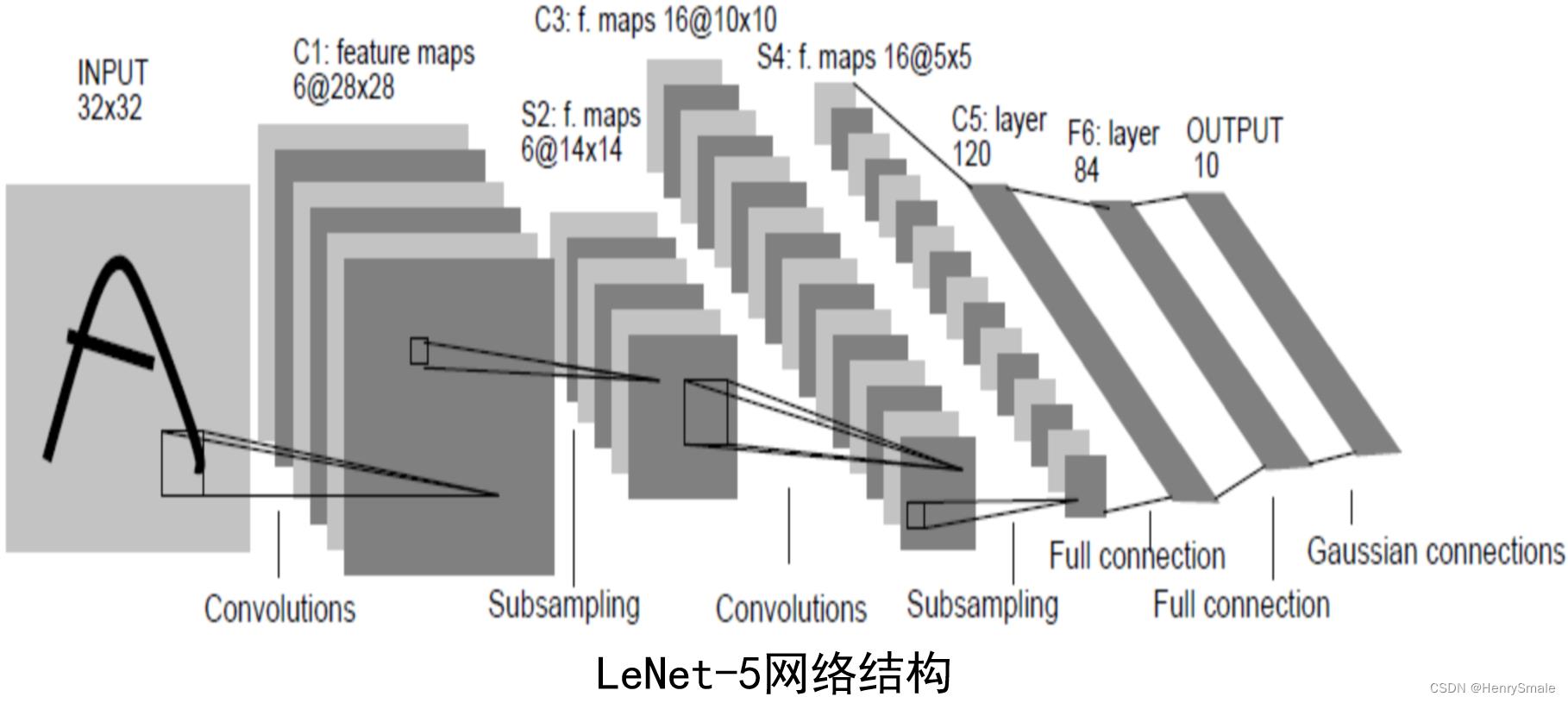
10 卷积神经网络及python实现
Posted HenrySmale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了10 卷积神经网络及python实现相关的知识,希望对你有一定的参考价值。
1 卷积神经网络简介
卷积神经网络(Convolutional Neural Network, CNN)由LeCun在上世纪90年代提出。
LeCun Y., Bottou L., Bengio Y., and Haffner P., Gradient-based learning applied to document recognition, Proceedings of the IEEE, pp. 1-7, 1998.
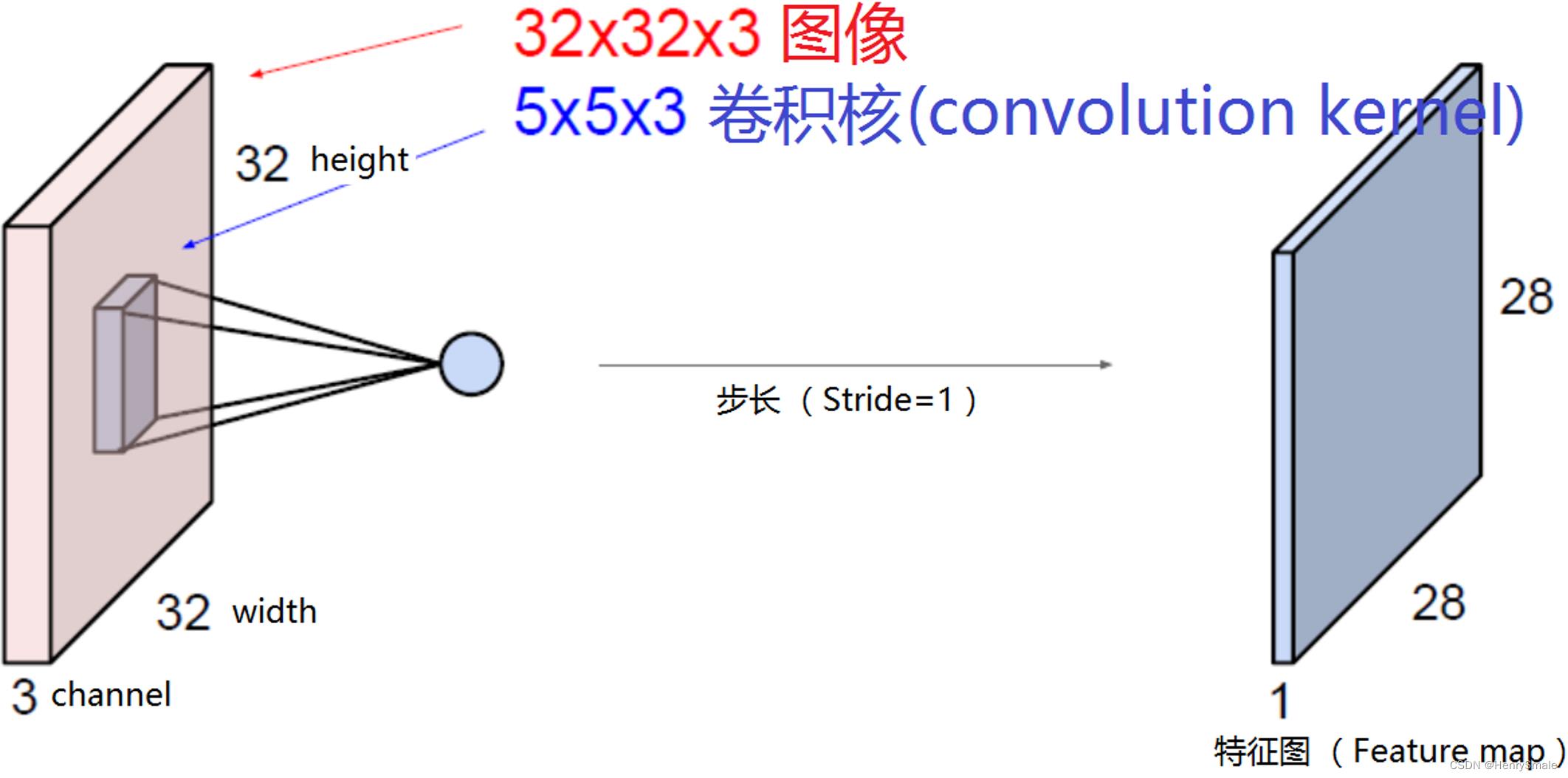
卷积核和特征图:
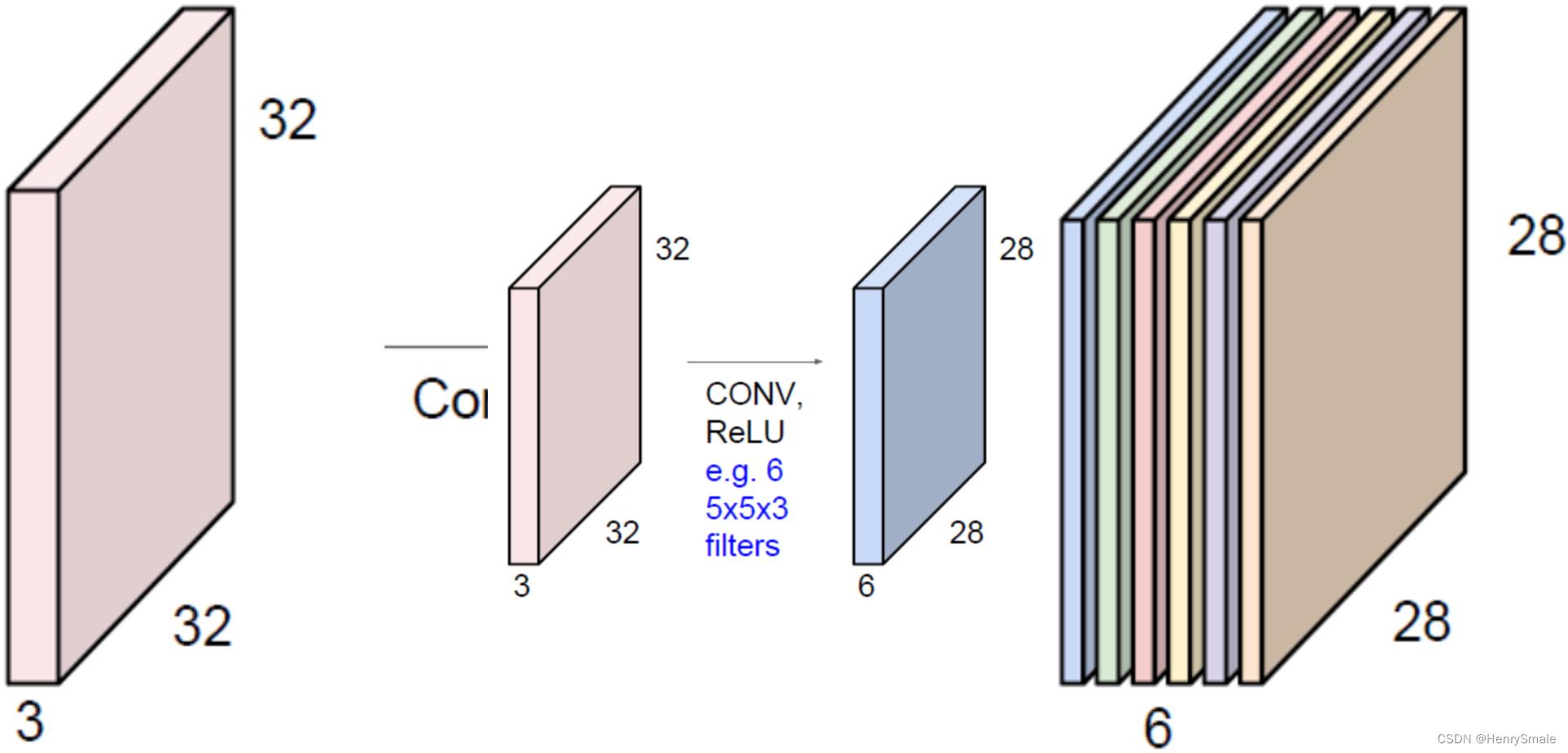
如果我们用6个卷积核,就能获得6个特征图(feature map)。你也可以把产生的6个特征图看成一个新的“图像”,其height, width, channel数目分别是28,28,6。
2 基本操作
2.1 卷积层
卷积层:特征提取
可以将图像卷积看成全连接网络的权值共享(weight sharing)
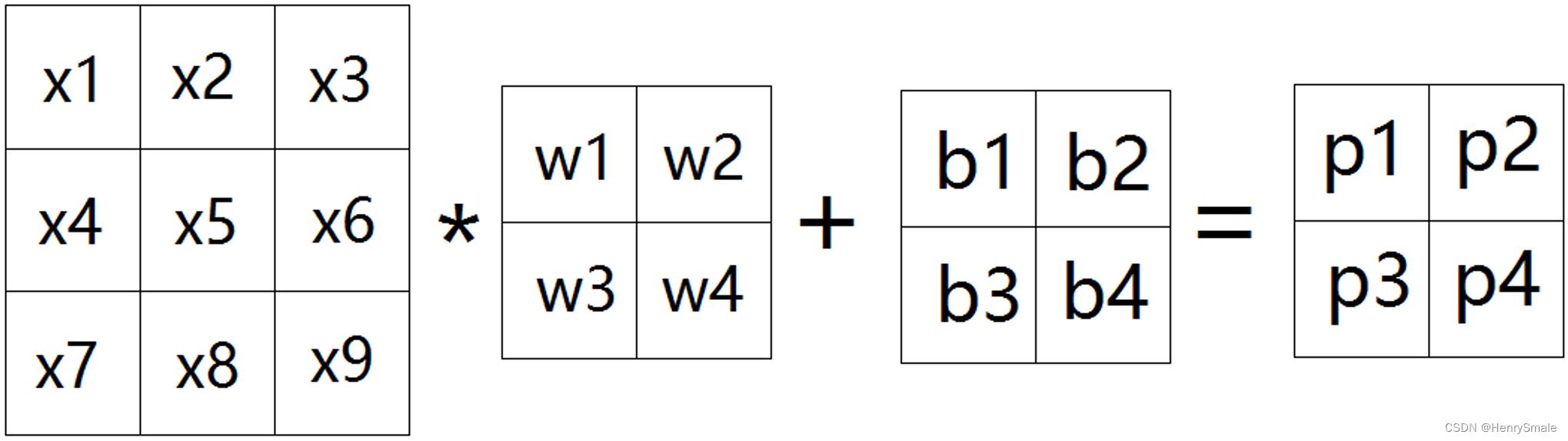
p
1
=
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
4
+
w
4
∗
x
5
+
b
1
p
2
=
w
1
∗
x
2
+
w
2
∗
x
3
+
w
3
∗
x
5
+
w
4
∗
x
6
+
b
2
p
3
=
w
1
∗
x
4
+
w
2
∗
x
5
+
w
3
∗
x
7
+
w
4
∗
x
8
+
b
3
p
4
=
w
1
∗
x
5
+
w
2
∗
x
6
+
w
3
∗
x
8
+
w
4
∗
x
9
+
b
4
\\beginarrayl p_1 = w_1 * x_1 + w_2 * x_2 + w_3 * x_4 + w_4 * x_5 + b_1 \\\\ p_2 = w_1 * x_2 + w_2 * x_3 + w_3 * x_5 + w_4 * x_6 + b_2 \\\\ p_3 = w_1 * x_4 + w_2 * x_5 + w_3 * x_7 + w_4 * x_8 + b_3 \\\\ p_4 = w_1 * x_5 + w_2 * x_6 + w_3 * x_8 + w_4 * x_9 + b_4 \\endarray
p1=w1∗x1+w2∗x2+w3∗x4+w4∗x5+b1p2=w1∗x2+w2∗x3+w3∗x5+w4∗x6+b2p3=w1∗x4+w2∗x5+w3∗x7+w4∗x8+b3p4=w1∗x5+w2∗x6+w3∗x8+w4∗x9+b4
上一页中的卷积操作,等价于如下权值共享网络:
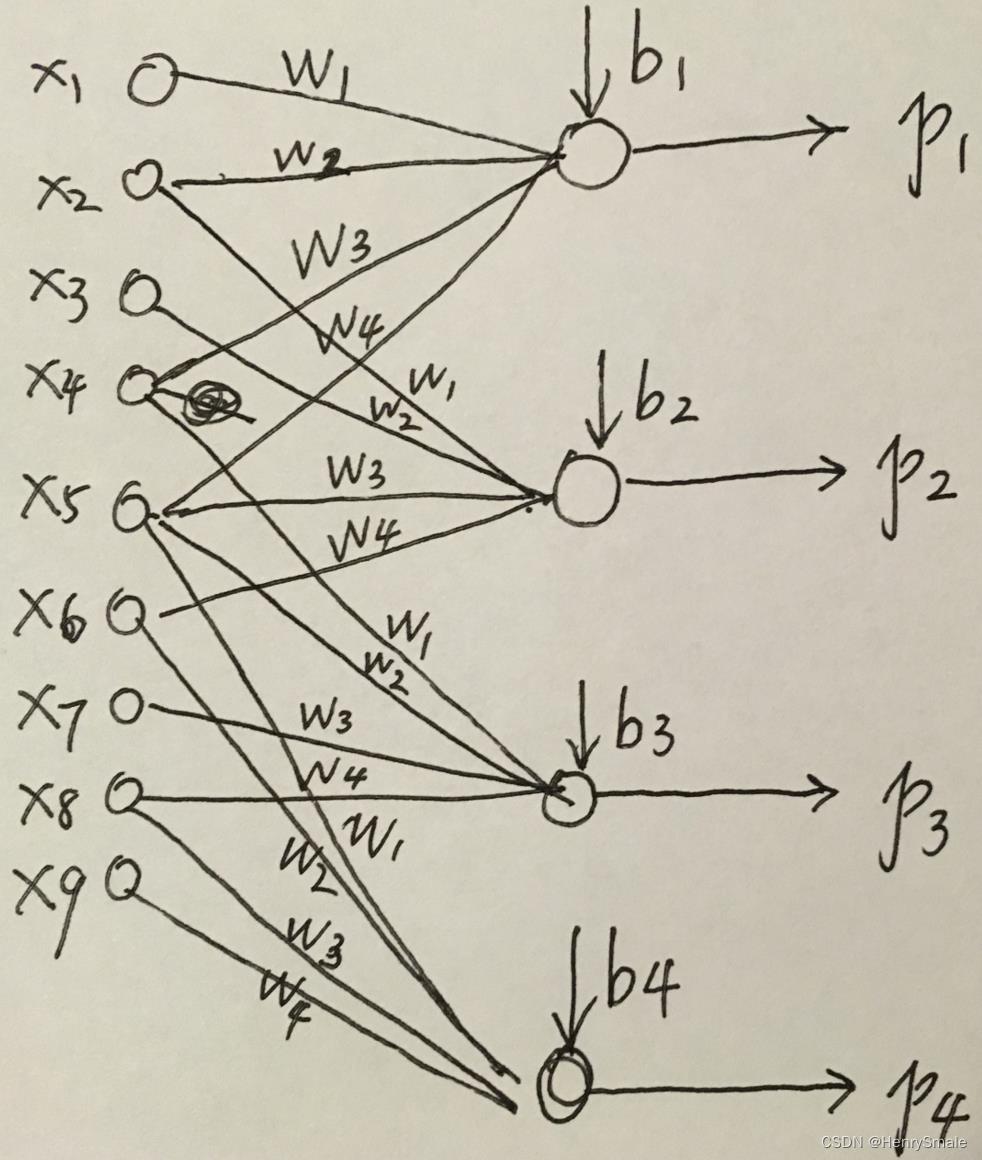
参数个数计算:
第1层(convolutional layer): (55+1)6=156
第2层(subsampling layer): 0
第3层(convolutional layer): (556+1)16=2416
第4层(subsampling layer): 0
第5层(fully connected layer): (55*16+1)*120=48120
第6层(fully connected layer): (120+1)*84=10164
第7层(fully connected layer): (84+1)*10=850
参数总数:61,706
2.2 ReLU 激活层
加入非线性因素,将卷积层输出结果做非线性映射。
ReLU 函数:
- 对于输入负值,输出全为0;
- 正值原样输出。
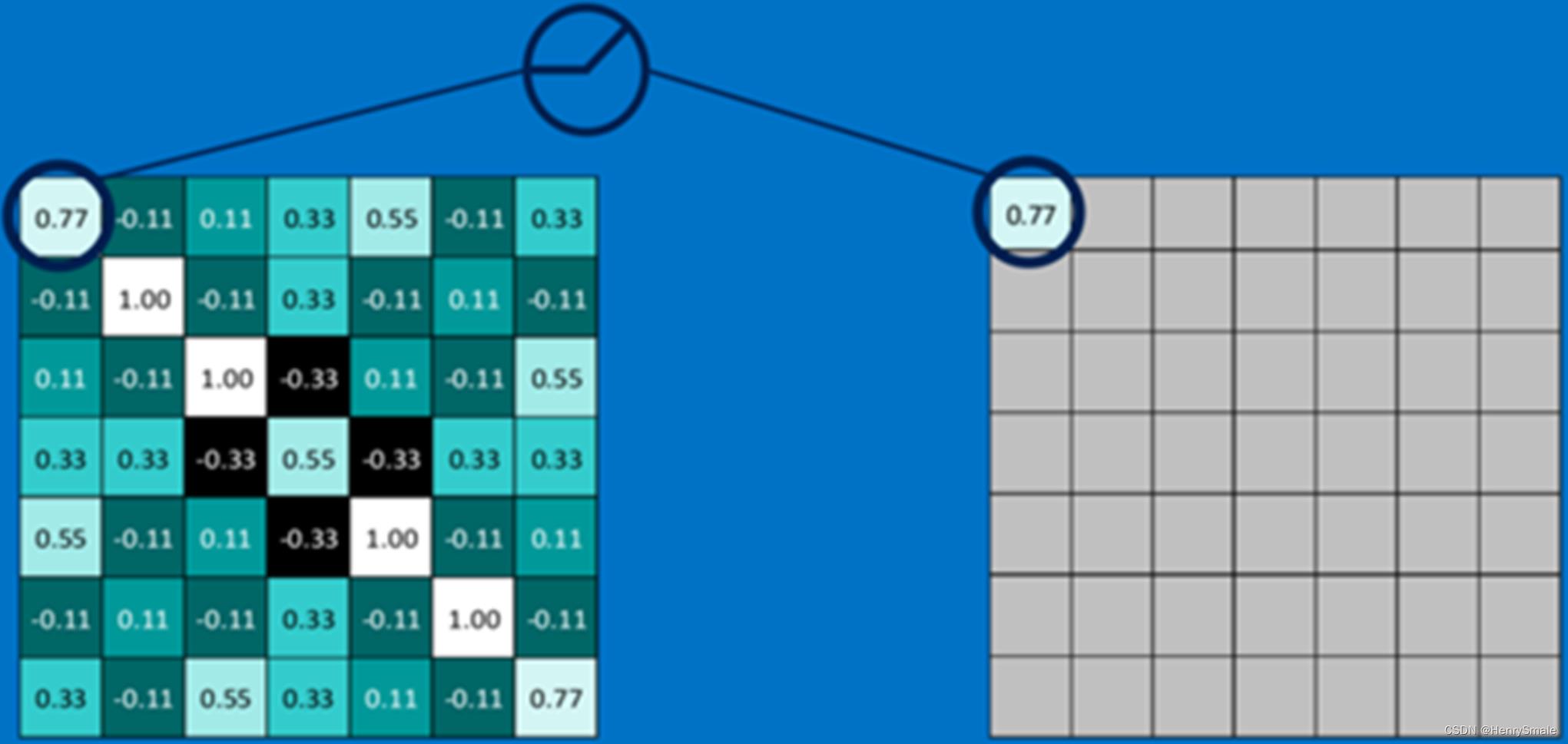
2.3 池化层
提取重要的特征信息。
将输入图像进行缩小,减少像素信息,保留重要信息。
取最大值、平均值等。
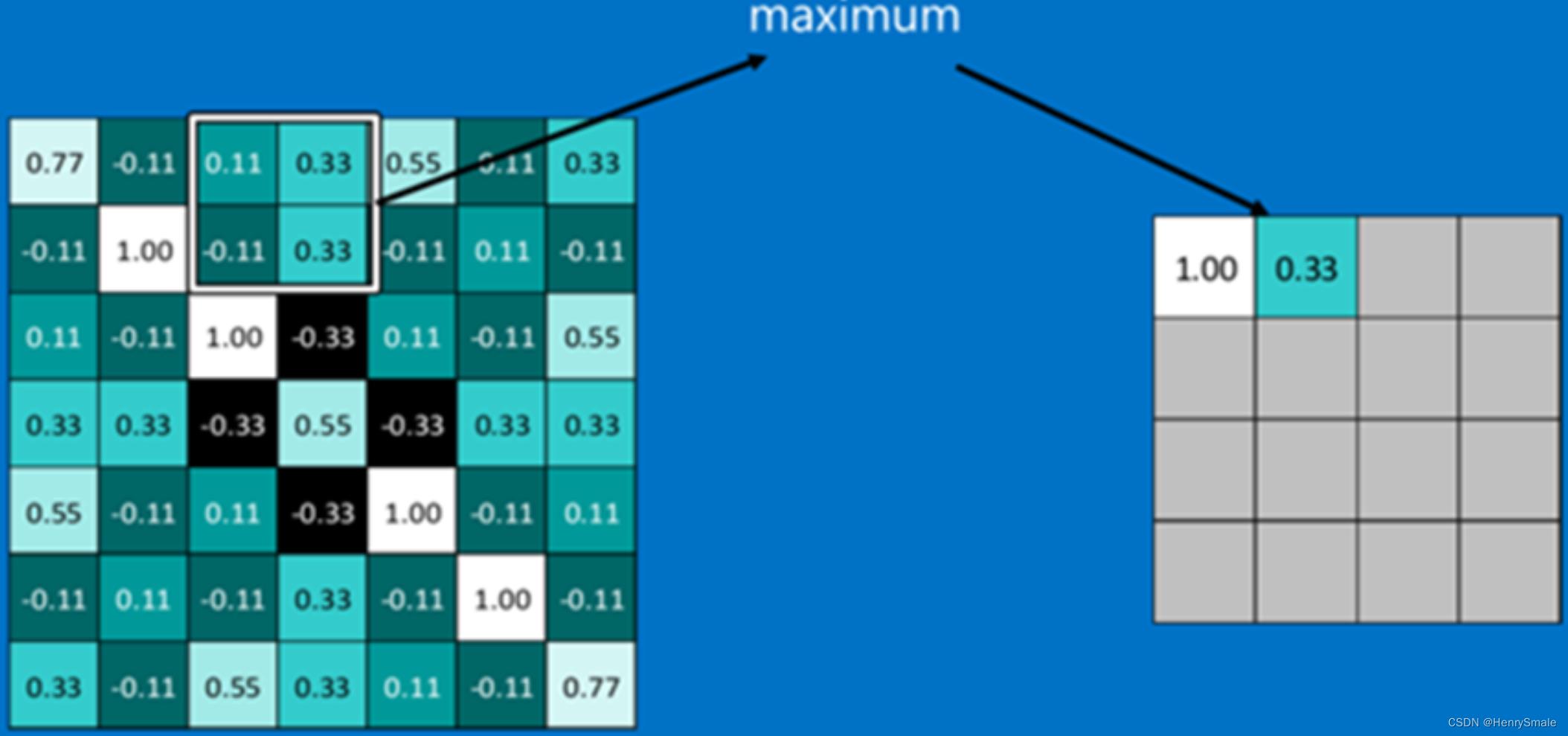
2.4 单层卷积神经网络
卷积、激活函数、池化组合在一起。

2.5 全连接层
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、池化等深度网络后,再经过全连接层对结果进行识别分类。
2.6 卷积神经网络流程
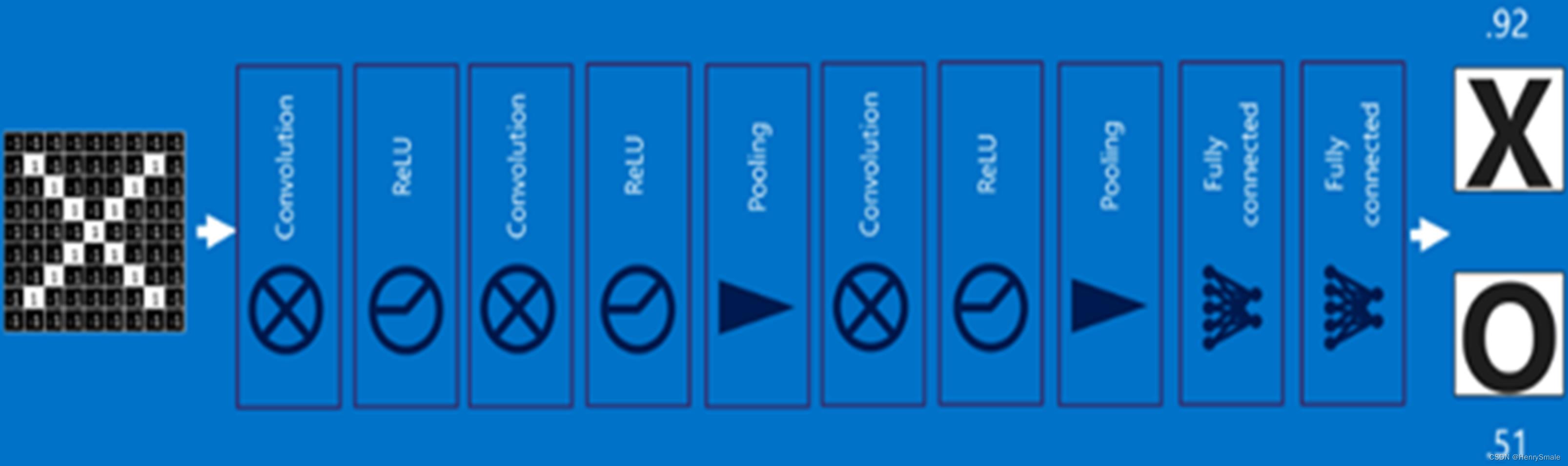
3 代码分析
import numpy as np
import tensorflow as tf
from keras import datasets, layers, models # 这里keras版本是2.8.0
import matplotlib.pyplot as plt
# 设置采用GPU训练程序
gpus = tf.config.list_physical_devices("GPU") # 获取电脑GPU列表
if gpus: # gpus不为空
gpu0 = gpus[0] # 选取GPU列表中的第一个
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显卡按需使用
tf.config.set_visible_devices([gpu0], "GPU") # 设置GPU可见的设备清单,默认是都可见,这里只设置了gpu0可见
# 导入数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data() # datasets内部集成了MNIST数据集,
# 归一化
# 将像素的值标准化至0到1的区间内,rgb像素值 0~255 0为黑 1为白
train_images, test_images = train_images / 255.0, test_images / 255.0
# 根据数据集大小调整数据到我们需要的格式
print(train_images.size) # 47040000
print(test_images.size) # 7840000
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
# 构建CNN网络模型
model = models.Sequential([ # 采用Sequential 顺序模型
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
# 卷积层1,卷积核个数32,卷积核3*3*1 relu激活去除负值保留正值,输入是28*28*1
layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'),
# 卷积层2,卷积核64个,卷积核3*3,relu激活去除负值保留正值
layers.MaxPooling2D((2, 2)), # 池化层2,2*2采样
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), # 全连接层,64张特征图,特征进一步提取
layers.Dense(10) # 输出层,输出预期结果
])
# 打印网络结构
model.summary()
# 编译
model.compile(optimizer='adam', # 优化器
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置损失函数from_logits: 为True时,会将y_pred转化为概率
metrics=['accuracy'])
# 训练
# epochs为训练轮数
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
print(history)
# 绘制测试集图片
plt.figure(figsize=(20, 10)) # 这里只看20张,实际上并不需要可视化图片这一步骤
for i in range(20):
plt.subplot(5, 10, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(test_images[i], cmap=plt.cm.binary)
plt.xlabel(test_labels[i])
plt.show()
# 预测
pre = model.predict(test_images) # 对所有测试图片进行预测
for x in range(5):
print(pre[x])
for x in range(5):
print(np.array(pre[x]).argmax())
4 AlexNet
2013 AlexNet
A. Krizhevsky, I. Sutskever and G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing 25, MIT Press, Cambridge, MA, 2012.
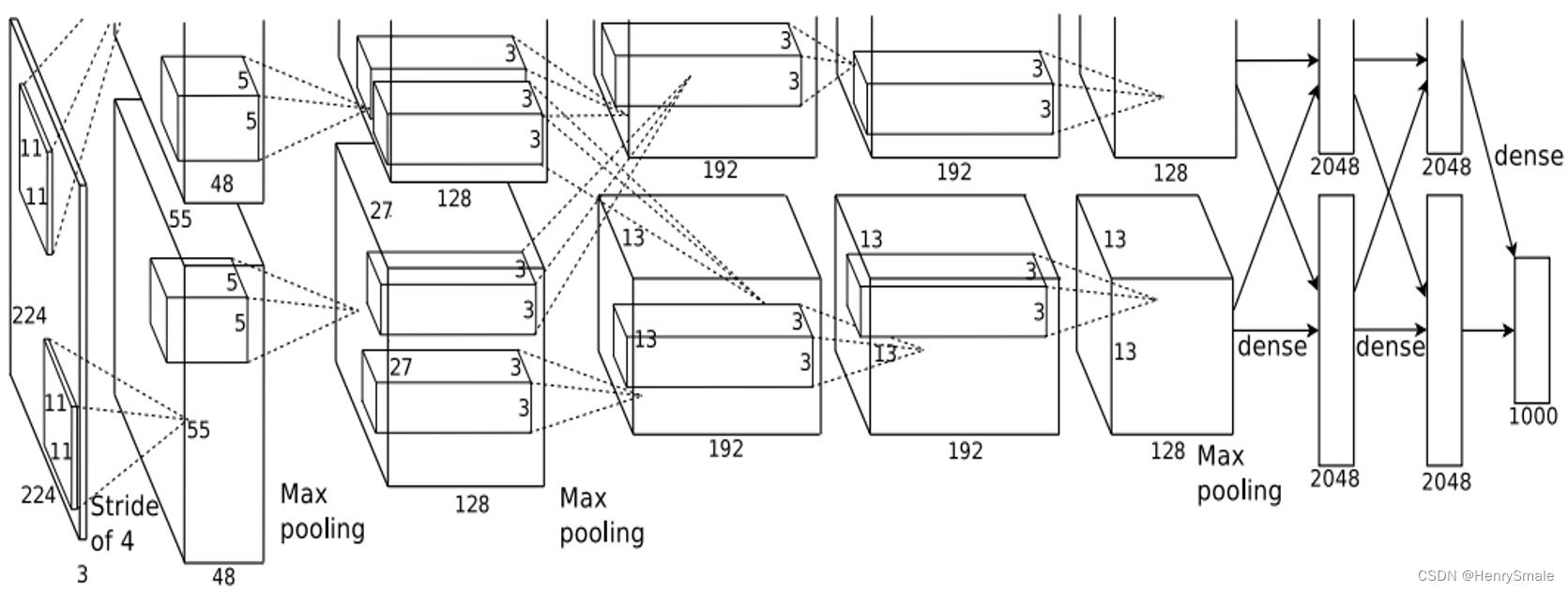
ImageNet包含超过120万张彩色图片,属于1000个不同类别,这是目前为止最大的图像识别数据库。Alex Krizhevsky等人构建了一个包含65万多个神经元,待估计参数超过6000万的大规模网络,这一网络被称为AlexNet。
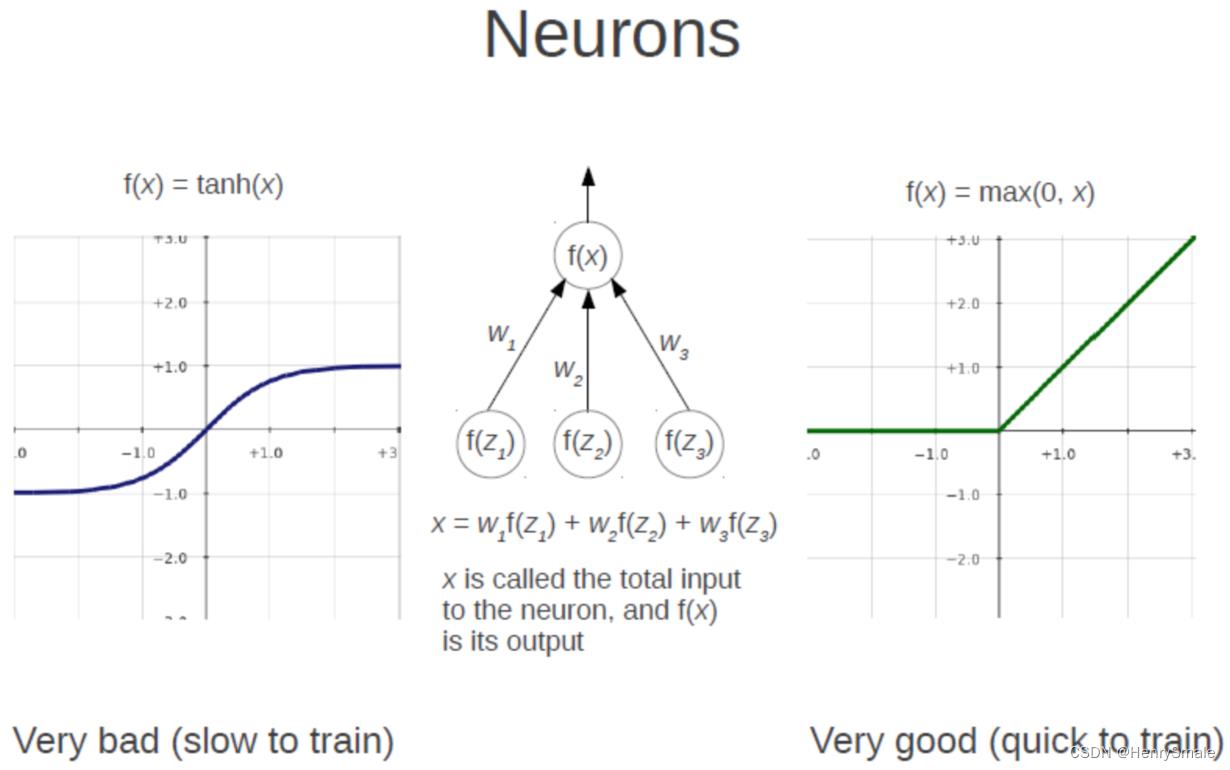
4.1 改进1:ReLU
以ReLU函数代替sigmoid或tanh函数:
R
E
L
U
(
x
)
=
max
(
0
,
x
)
\\mathbfRELU(x) = \\max(0, x)
RELU(x)=max(0,x)
实践证明,这样做能使网络训练以更快速度收敛。
4.2 改进2:池化
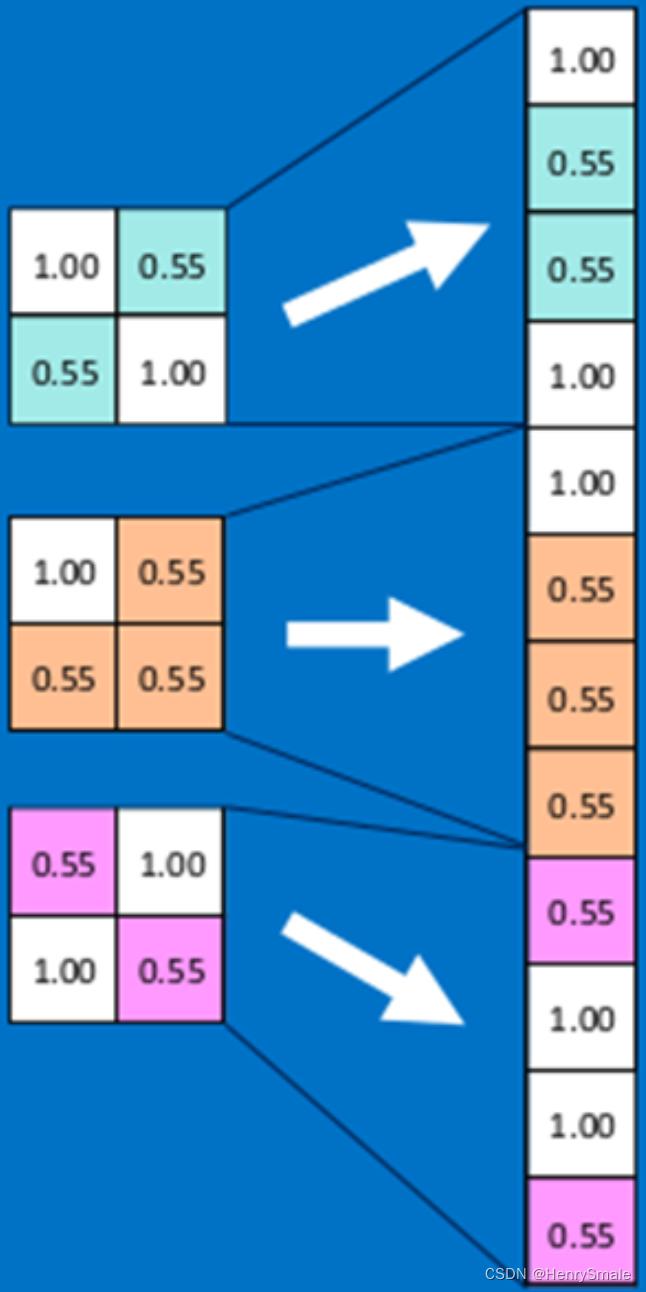
为降采样操作起了一个新的名字—池化(Pooling),意思是把邻近的像素作为一个“池子”来重新考虑。如图所示,左边所有红色的像素值可以看做是一个“池子”,经过池化操作后,变成右边的一个蓝色像素。
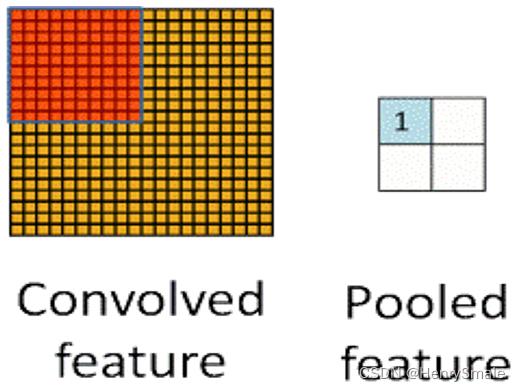
在AlexNet中,提出了最大池化(Max Pooling)的概念,即对每一个邻近像素组成的“池子”,选取像素最大值作为输出。在LeNet中,池化的像素是不重叠的;而在AlexNet中进行的是有重叠的池化。实践表明,有重叠的最大池化能够很好的克服过拟合问题,提升系统性能。
4.3 改进3:随机丢弃
随机丢弃(Dropout)。
为了避免系统参数更新过快导致过拟合,每次利用训练样本更新参数时候,随机的“丢弃”一定比例的神经元,被丢弃的神经元将不参加训练过程,输入和输出该神经元的权重系数也不做更新。这样每次训练时,训练的网络架构都不一样,而这些不同的网络架构却分享共同的权重系数。实验表明,随机丢弃技术减缓了网络收敛速度,也以大概率避免了过拟合的发生。
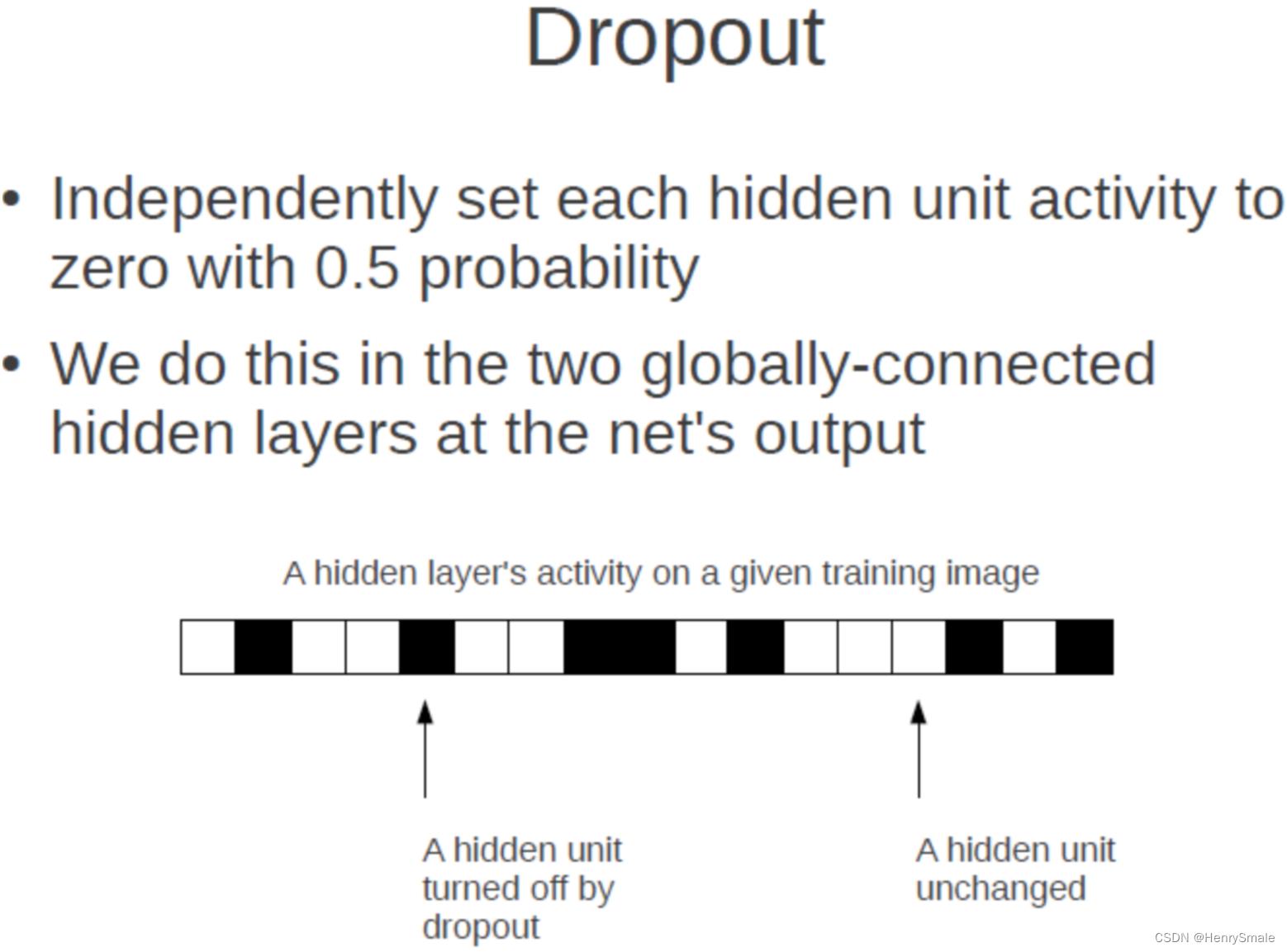
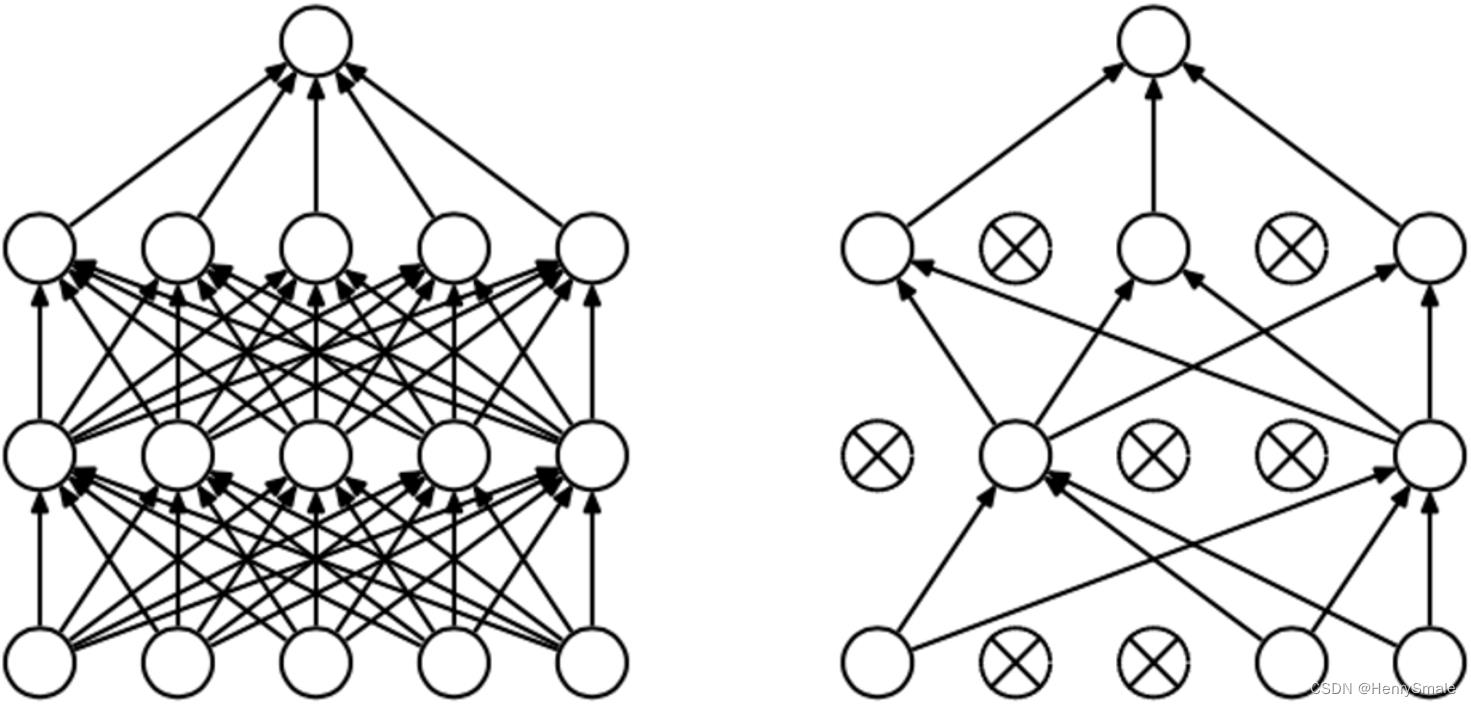
Dropout做法是:
- 对每一层,每次训练时以概率 p p p丢弃一些神经元,这样每次训练的网络都不一样。
- 训练结束后的测试流程,要用完整的网络结构,同时对该层的所有的参数 ( W , b ) (W,b) (W,b)都要乘以 ( 1 − p ) (1-p) (1−p)。
4.4 改进4:增加训练样本
尽管ImageNet的训练样本数量有超过120万幅图片,但相对于6千万待估计参数来说,训练图像仍然不够。
Alex等人采用了多种方法增加训练样本,包括:
- 将原图水平翻转;
- 将256×256的图像随机选取224×224的片段作为输入图像。
运用上面两种方法的组合可以将一幅图像变为2048幅图像。还可以对每幅图片引入一定的噪声,构成新的图像。这样做可以较大规模增加训练样本,避免由于训练样本不够造成的性能损失。
4.5 改进5:GPU加速
用GPU加速训练过程。采用2片GTX 580 GPU对训练过程进行加速,由于GPU强大的并行计算能力,使得训练过程的时间缩短数十倍,哪怕这样,训练时间仍然用了六天。
参考文献
以上是关于10 卷积神经网络及python实现的主要内容,如果未能解决你的问题,请参考以下文章