mitmproxy与安卓模拟器搭配,助力Python爬虫工程师,然后就可以爬CSDN粉丝数据了
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mitmproxy与安卓模拟器搭配,助力Python爬虫工程师,然后就可以爬CSDN粉丝数据了相关的知识,希望对你有一定的参考价值。
本篇博客为大家介绍 mitmproxy,该工具与 Charles 和 Fiddler 实现的功能类似,都可以辅助我们分析接口。
mitmproxy 工具安装
mitmproxy 是一个免费且开源的交互式 HTTPS 代理,在爬虫领域一般将其用作手机模拟器,无头浏览器,可以用它作为代理去拦截爬虫获取到的数据。
mitmproxy 可以与 fiddler 工具一样,安装一个客户端进行操作,地址如下:
官网地址:https://mitmproxy.org/
6.0版本下载地址:https://mitmproxy.org/downloads/#6.0.2/
需要特殊的手段进行访问,国内已经将其地址屏蔽。
下载的最新 Windows Installer 版本即可(由于我电脑使用的是 Windows7 操作系统,顾下载 6.0 版本),其文档说明也非常清楚:https://docs.mitmproxy.org/stable/
安装完毕,会自动运行控制台,启动 mitmproxy ui 。

通过浏览器访问上述地址,得到如下界面。
如果出现如下异常 缺少 api-ms-win-core-path-l1-1-0.dll ,打开下述链接下载 dll 组件即可。
https://download.csdn.net/download/hihell/38146147
接下来设置一下浏览器代理,是数据通过监听端口,按照如下步骤操作即可。

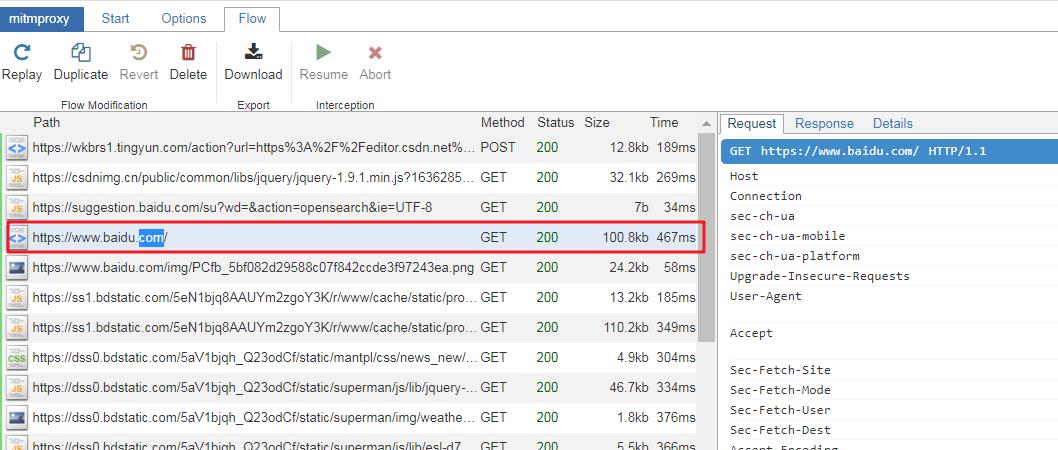
除此之外,为了捕获 HTTPS 协议的请求,还需要安装证书,在浏览器打开 http://mitm.it/ 下载 Windows 证书即可,下图就是抓取成功时候的样子。
证书也可以在目录
C:\\Users\\Administrator\\.mitmproxy查找,Windows 下选择mitmproxy-ca-cert.p12。
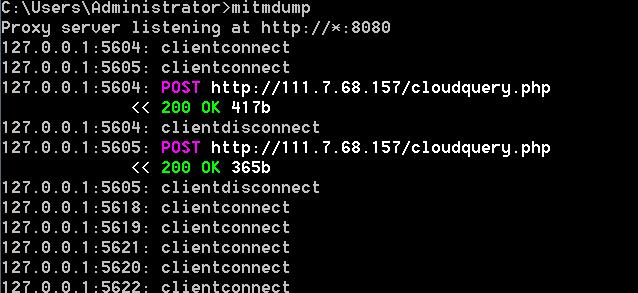
关闭浏览器和控制台之后,再次启动只需要在控制台输入 mitmweb 即可实现,还有一种启动方式,使用 mitmdump ,实现效果如下所示,该形式与 mitmweb 的差异是展示载体不一致,即一个是在网页端,一个是在控制台。
mitmproxy 配合安卓模拟器
有了前文的铺垫,在加上以前对 fiddler 和 Charles 的学习,mitmproxy 和模拟器连接操作就非常容易了。
配置模拟器的 Wlan 代理,指向电脑 IP,同时端口为 8080。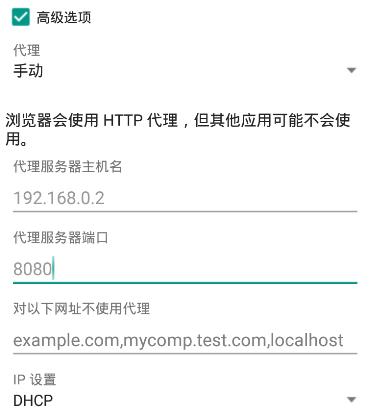
将证书 mitmproxy-ca-cert.cer 或者 mitmproxy-ca-cert.pem 拖拽到模拟器中,然后安装证书(如无法双击安装,通过【设置】->【安全】安装即可),完成以上操作之后,只需要通过模拟器访问百度,查看是否捕捉到数据请求即可。
仅使用如上功能是远远不够的,我们看中的是 mitmproxy 可以实现脚本二次开发,所以下面在 python 环境中安装 mitmproxy 库,实现其扩展功能。
在 python 环境下配置 mitmproxy
使用 pip install mitmproxy 即可实现该库的安装,mitmproxy 要求 python 最低版本是 python3.8,所以安装前需要确定你的 Python 版本是否满足要求(实测 Python3.7 也安装成功了)。
安装过程中,发现 pyperclip 无法安装成功,解决办法是下载其 tar.gz 文件,解压之后,使用 python setup.py install 进行本地安装。
mitmproxy 包含的模块比较多,其中任意模块失败,都无法安装成功。
Successfully installed Brotli-1.0.9 Jinja2-2.11.3 MarkupSafe-2.0.1 Werkzeug-1.0.1 asgiref-3.3.4 certifi-2021.10.8 cffi-1.15.0 click-7.1.2
0 hpack-4.0.0 hyperframe-6.0.1 itsdangerous-1.1.0 ldap3-2.8.1 mitmproxy-5.3.0 msgpack-1.0.2 passlib-1.7.4 protobuf-3.13.0 publicsuffix2-2
2.21 pydivert-2.1.0 pyparsing-2.4.7 ruamel.yaml-0.16.13 ruamel.yaml.clib-0.2.6 six-1.16.0 sortedcontainers-2.2.2 tornado-6.1 typing-exten
mitmproxy 官方提供了非常多参考案例
例子查看网址:https://docs.mitmproxy.org/stable/addons-examples/
你学习的第一个案例,就是修改 requests 请求,创建一个名称为 script.py 的文件,编写如下代码:
import mitmproxy.http
def request(flow: mitmproxy.http.HTTPFlow):
flow.request.headers['User-Agent'] = 'MitmProxy'
print(flow.request.headers)
在控制台使用 mitmdump -s script.py 启动文件,并开启浏览器代理,访问 http://httpbin.org/get,此时就会发现用户代理已经被我们成功修改。

还可以将多个方法合并在一个类中,然后再通过 addons 变量进行绑定,例如官方提供的案例。
from mitmproxy import ctx
class Counter:
def __init__(self):
self.num = 0
def request(self, flow):
self.num = self.num + 1
ctx.log.info("We've seen %d flows" % self.num)
addons = [
Counter()
]
在命令行重启 mitmproxy,刷新浏览器获取如下内容。
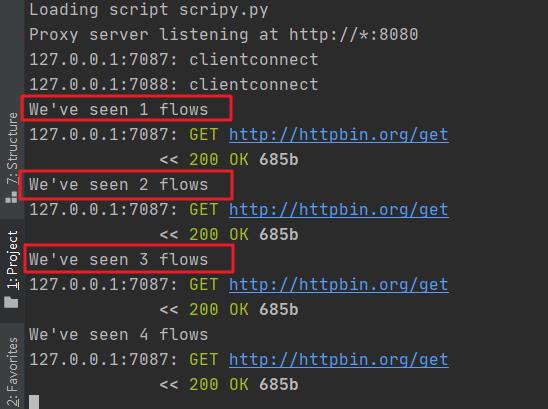
这里还需要了解的就是为了实现 mitmproxy 与 python 之间的交互,有一些固定名称的函数需要记忆一下。
def http_connect(self, flow: mitmproxy.http.HTTPFlow):与服务器建立连接;def requestheaders(self, flow: mitmproxy.http.HTTPFlow):客户端的 HTTP 请求的头部被成功读取,请求 body 没有读取;def request(self, flow: mitmproxy.http.HTTPFlow):客户端的 HTTP 请求被成功完整读取;def responseheaders(self, flow: mitmproxy.http.HTTPFlow):服务器返回的响应头被读取,响应 body 还没有返回;def response(self, flow: mitmproxy.http.HTTPFlow):响应完整返回;def error(self, flow: mitmproxy.http.HTTPFlow):异常状态。
这里对具体细节的 API 不做过多的说明,都可以从手册查阅出来,官方手册:https://docs.mitmproxy.org/stable/api/events.html
案例时间
本次实现的爬虫案例是,访问 CSDN 任意博主的粉丝列表,在控制台打印出粉丝数据(隐私问题,没有存储)。
那官方博客测试,发现接口如下:
https://blog.csdn.net/community/home-api/v1/get-fans-list?page=4&size=20&noMore=false&blogUsername=blogdevteam
请求方式为 get ,请求地址为 https://blog.csdn.net/community/home-api/v1/get-fans-list,修改 script.py 文件代码如下:
from mitmproxy import ctx
import json
def response(flow):
start_url = "https://blog.csdn.net/community/home-api/v1/get-fans-list"
response = flow.response
if flow.request.url.startswith(start_url):
text = response.text
data = json.loads(text)
print(data)
或者使用如下代码,也可以实现相同的效果。
import json
class GetFans(object):
def response(self, flow):
start_url = "https://blog.csdn.net/community/home-api/v1/get-fans-list"
response = flow.response
if flow.request.url.startswith(start_url):
text = response.text
data = json.loads(text)
print(data)
addons = [
GetFans()
]

这时候,如果我们能实现自动化下拉页面,是不是就能实现一个自动化的爬虫了呢???
订阅时间
今天是持续写作的第 267 / 365 天。
可以关注我,点赞我、评论我、收藏我啦。
更多精彩

以上是关于mitmproxy与安卓模拟器搭配,助力Python爬虫工程师,然后就可以爬CSDN粉丝数据了的主要内容,如果未能解决你的问题,请参考以下文章
多图预警,Appium 实现手机自动化,搭配 mitmproxy 不就实现自动采集了吗?
fiddler软件+手机模拟器搭配抓包,这篇博客有Python爬虫与百家号的事