机器看世界
Posted 心随而动
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器看世界相关的知识,希望对你有一定的参考价值。
博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究计算机视觉,涉及算法,案例实践,网络模型等知识。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里 订阅专栏 。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
计算机眼里的图像
图像一直以直观著称,一张图像包含的信息很多,所谓一图胜千言,对于人类来说,理解图像很方便,几乎是一眼就能理解图像表达的意思,科学研究表明这是因为人的大脑有一套注意力集中机制,对于图像中的海量信息,人脑能快速地找到其中最重要的信息。但是,计算机该如何去理解?这就涉及到了计算机视觉的知识,本专栏就是来描述计算机视觉。
计算机视觉的起源
1982年《视觉》(Marr,1982)一书的问世,标志着计算机视觉这门学科的诞生。此后,计算机视觉经历了四个阶段,第一个阶段,马尔计算视觉;第二个阶段,主动和目的视觉;第三阶段,多视几何和分层三维重建;第四个阶段,基于学习的视觉。四个阶段算然是依次进行的,但不能说哪一个好,哪一个不好,只是后者比前者更加顺应当时的时代。
马尔计算视觉
马尔计算视觉的主要思想是大脑可以快速完成三维重建,马尔认为,三维重建是可以完全靠计算来实现。他认为图象是物理实体在视网膜上的投影,所以理解了物理信息,就可以理解图像信息。简而言之,其计算机视觉计算理论就是要“挖掘物体的物理属性来完成对应的视觉问题”。其意义完在于,如果简单地从数学角度出发,很多图像具有歧义性。
主动和目的视觉
马尔视觉的泛化性不够理性,很难在工业界实现,可以想象,由计算机对任何物体做三维重建是多么困难。美国的R.Bajcsy教授,提出了主动视觉的概念,主要思想视觉要有目的性,例如在一张百人合影里面,人能轻松地找到自己的位置,或者自己好友的位置,而对其他人“视而不见”。三维重建并非视觉的目的,找到想看到的图像才是根本目的。
多视几何和分层三维重建
随着主动视觉昙花一现,多视几何走向繁荣,多视几何的代表性人物有法国的O.Faugeras、美国的R.Hartely和英国的A.Zisserman等。多视几何的目的是增加三维重建算法的效率和精度,使其能真正落地。三维重建就是从图像中选取合适的图像集,然后对拍摄位置信息进行标定并重建出场景的三维结构。
基于学习的视觉
基于学习的视觉是本书的主要内容,以机器学习为主要手段,包括流形学习和深度学习两大流派。
流形学习时域2000年,但是在后面的研究中发现,多数情况下流形学习的结果还不如传统的降维方法,如主成分分析和线性判别分析等。
深度学习虽然是近几年才火起来的,但是其效果非常好,并且模型层出不穷。深度学习更像是实践科学,和前几个阶段不同,并非有很完善的理论支持。往往在不停的尝试中,模型得到改善。在静态物体识别中,卷积神经网络已经超过人类的准确度。
计算及视觉的难点
计算机视觉的难点有两点:三维重建和鲁棒性。
三维重建之所以对人类来说非常简单,主要是因为人本身就生活在三维世界中,而计算机却是一个二维“生物”。就像我们去构建四维世界的东西,就会觉得非常困难,根本无从下手。对于计算机来说,完成三维世界的图像构建,对于他来说,无疑是降维打击。所以这才需要人类的帮助,让计算机能够识别图像。
鲁棒性的问题简单地说就是先验知识和注意机制问题。对于人来说,即使只是轮廓,或者很模糊的照片,也能大致猜测出图片的内容。但是计算机就不行,他对图像的识别都有很严格的限制,改变颜色,形状。模糊程度等,都会让计算机识别精度下降。这就是鲁棒性问题。
专栏研究方向
在介绍这篇专栏前,我先解释一下,博主之前一直在更新人工智能算法专栏,由于人工智能算法涉及到的面很广,知识面太过复杂,其中,就包含了深度学习,所以,博主打算出一期计算机视觉的专栏,先介绍一下,这样学习人工智能算法会简单很多。博主更新完计算机视觉专栏后,会继续更新人工智能算法。在这里给大家说一声抱歉!
计算机视觉主要研究方向有图像识别,目标检测,图像分割,目标跟踪等。
图像识别,也叫图像分类,可以分为i物种级分类,子类分类和实例级分类,主要模型有VGG,GoogleNet,RestNet等,常用的数据库有Minist手写数字,carfil10,cifar100,ImageNet等。
目标检测,拥有识别物体类别,还需要框出物体位置信息,例如智能相机,还能标注出人脸的位置。传统的,我们可以用OpenCV来解决这类问题,但是召回率低。常用的模型有Fast R-CNN,YOLO和SSD等。
图像分割,计算机视觉中最高层次的理解范畴。目标就是把图像分割成具有相似特性的若干个区域,并使他们对因物体的不同部分或不同的物体。常用的模型是全卷积神经网络。
目标跟踪也可以看成连续的目标检测,目的就是在视频中对物体进行连续跟踪。目标跟踪常用在监控系统中。跟踪算法可以被分为生成式和判别式两大类别。深度学习主要用在判别模式上,著名的模型有SO-DLT和FCNT等。不同于目标检测、物体识别等领域深度学习一家独大的形式,深度学习在目标跟踪方向还未能达成垄断地位,其主要难点在于数据缺失和物体快速移动。
提到深度学习相关的计算机视觉,不得不提到最近流行的风格迁移,以及GAN生成式对抗网络。例如现在使用的ZAO就是运用了此技术。
传统图像处理之OpenCV的妙用
OpenCV(Open Source Computer Vision Library)顾名思义就是开源的计算机视觉库,采用C,C++编写,也提供了Python和Matlab等语言的接口,并且在各大操作平台均可使用。OPenCV不只是一个简单的提供了计算机视觉常用的操作,更对其中关键算法进行了优化和提速,从而可以进行多线程处理。
OpenCV安装
pip install opencv-python
如果下载速度太慢,可以考虑使用镜像:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
OpenCV模块
CUDA-accelerated Computer Vision:CUDA加速模块。
Core functionality:和兴功能模块,包含各种c++操作,接口,矩阵运算。
Image Processing:图像处理模块,包含图像处理四大任务。
Image file reading and writing:图像读取和保存模块。
Video I/O:视频读取和保存模块。
Video Analysis:视频分析模块。
Camera Calibration and 3D Reconstruction:相机校准和3D重建模块。
2D Features Framework:2D功能框架模块。
Objecneural Dection: 目标检测模块。
Deep Network module:深度学习模块
Machine Learning:机器学习模块。
Clustering and Search in Multi-Dimensional Spaces::多维空间模块。
Computational Photography:计算摄影模块。
Images stitching:图像拼接模块。
G-API framework:图论框架模块。
ArUco Marker Detection:ArUco表i==标记检测模块。
Improved Background-Foreground Segmentation Methods:背景,前景分割模块。
Biologically inspired vision models and derivated tools:基于生物的视觉模型和工具模块。
Custom Calibration Pattern for 3D reconstruction:传统模式三维重建模块。
OpenCV的基本操作
OpenCV数据存取
opencv支持各种类型与格式的图像数据,读取方式非常简单,使用imread函数即可,该函数有两个参数,第一个参数path指图片路径,第二个参数flag表示读取方式,默认值为从v.IMREAD_COLOR,默认读取彩色图片,可选值为cv2.IMREAD_GRAYSCALE和cv2.IMREAD_UNCHANGED默认颜色空间是BGR而非常用的FGB。
import cv2 img=cv2.imread('F:\\Image\\\\test1.jpg',cv2.IMREAD_COLOR) cv2.imshow('图片名字',img) cv2.waitKey(0) #保存图片 cv2.imwrite('图片文件.png',img) #第一个参数是保存图片文件的名字,第二个是后缀
OpenCV图像缩放
当数据集的图像大小不一样时,我们就需要用到图像缩放,使所有的图片大小保持一致,函数时cv2.resize(),第一个参数是目标图像,第二个参数是缩减比例。
import cv2
import numpy as np
#读取图片
img=cv2.imread('F:\\Image\\\\test2.jpg',cv2.IMREAD_COLOR)
cv2.imshow('原有的图片',img)
#进行缩放
img=cv2.resize(img,(1000,1000)) #比例放缩1000:1000
#显示图片
cv2.imshow('图片缩放',img)
cv2.waitKey(0)
OpenCV图像裁剪
普通图像的裁剪非常简单,由于读取的图像存储方式时矩阵,所以我们只需取矩阵的一部分就完成了裁剪。


import numpy as np
import cv2
img=cv2.imread('F:\\Image\\\\test3.jpg',cv2.IMREAD_COLOR)
cv2.imshow('裁剪前',img)
patch=img[0:50,0:50]
#取左上角50x50小块
cv2.imshow('裁剪过后的图片',patch)
cv2.waitKey(0)当然,虽然我们不知道图片的大小,所以裁剪的时候很麻烦,这时我们就可以随机裁剪,l利用random模块:
import numpy as np
import cv2
import random
img=cv2.imread('F:\\Image\\\\test3.jpg',cv2.IMREAD_COLOR)
#得到图像形状
w,h,d=img.shape
cv2.imshow('裁剪前',img)
x=random.randint(0,w)
y=random.randint(0,h)
patch=img[x:w,y:h]
#取左上角50x50小块
cv2.imshow('裁剪过后的图片',patch)
cv2.waitKey(0)

OpenCV图像旋转
图像旋转也是重要的操作,当图像的方向为非水平方向时,就需要通过旋转成水平方向。
在OpenCV中,图像旋转有两种实现方式:
第一种主要通过仿射变换,所用函数为cv2.warpAffine(),此函数有三个参数:分别为需要旋转的图像,仿射变换矩阵,以及输出图像的大小。
仿射变换,也称仿射映射,是指一个向量空间通过一次线性变换后,变为另一个空间。可以用如下公式表示:
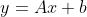
其中矩阵A表示旋转与缩放,向量b表示平移。
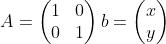
(1)旋转变换,顺时针旋转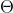
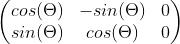
(2)缩放变换,水平方向为a倍,竖直方向变为b倍。
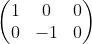
代码展示:
import numpy as np import cv2 img=cv2.imread('F:\\Image\\\\test4.jpg',cv2.IMREAD_COLOR) w,h,d=img.shape #放射变换矩阵 M=np.array([[0,0.5,-10],[0.5,0,0]]) #旋转图片 img1=cv2.warpAffine(img,M,(w,h)) #显示图片 cv2.imshow('图片旋转',img) cv2.waitKey(0)

第二种使用OpenCV内置函数,所用的函数为cv2.getRotationMatrix2D(),此函数共三个参数,分别为图片旋转中心,逆时针旋转角度,以及缩放的倍数。和裁剪一样,这里也可以使用random()实现随机选择和平移功能。
import numpy as np import cv2 img=cv2.imread('F:\\Image\\\\test4.jpg',cv2.IMREAD_COLOR) img1=cv2.getRotationMatrix2D((1,1),90,1) cv2.imshow('图片旋转',img1) cv2.waitKey(0)
从摄像头读取
OpenCV不仅能对图像进行处理,还能对视频进行处理,我们也可以直接调用摄像头进行计算机获取视频。函数是cv2.VideoCapture()函数,此函数只有一个参数,0为计算机摄像头,1为其他来源。
import cv2
import numpy as np
capture=cv2.VideoCapture(0)
while(True):
#读取一帧
ret,frame=capture.read()
#显示一帧
cv2.imshow('capture',frame)
#关闭摄像头
capture.release()读取视频后,可以用cv2.VideoWriter()函数创建视频保存器即可。和读取的时候一样,也需要一帧一帧的保存,使用从cv2.putText()函数,可选参数为帧名称,帧标题,标题位于左上角坐标,字体,字体大小,颜色,字体粗细。
#从摄像头读取并保存录像
import cv2
import numpy as np
#创建摄像头
capture=cv2.VideoCapture(0)
#帧率
fps=60
#保存格式(mp4)
fourcc=cv2.VideoWriter_fourcc(*'mp4v')
#创建保存器
vout=cv2.VideoWriter()
vout.open('F:\\Image\\\\temp.mp4',fourcc,fps,(1280,720),True)
#读取一帧并保存
for i in range(100):
_,frame=capture.read()
cv2.putText(frame,str(i),(10,20),cv2.FONT_HERSHEY_PLAIN,1,(0,255,0),1,cv2.LINE_AA)
vout.write(frame)
#释放资源
vout.release()
capture.release()
这样,就可以实现对摄像头的调用。你就可以知道谁打开了你的电脑。
矩阵操作
add 矩阵加法,A+B的更高级形式,支持mask
scaleAdd 矩阵加法,一个带有缩放因子dst(I) = scale * src1(I) + src2(I)
addWeighted 矩阵加法,两个带有缩放因子dst(I) = saturate(src1(I) * alpha + src2(I) * beta + gamma)
subtract 矩阵减法,A-B的更高级形式,支持mask
multiply 矩阵逐元素乘法,同Mat::mul()函数,与A*B区别,支持mask
gemm 一个广义的矩阵乘法操作
divide 矩阵逐元素除法,与A/B区别,支持mask
abs 对每个元素求绝对值
absdiff 两个矩阵的差的绝对值
exp 求每个矩阵元素 src(I) 的自然数 e 的 src(I) 次幂 dst[I] = esrc(I)
pow 求每个矩阵元素 src(I) 的 p 次幂 dst[I] = src(I)p
log 求每个矩阵元素的自然数底 dst[I] = log|src(I)| (if src != 0)
sqrt 求每个矩阵元素的平方根
min, max 求每个元素的最小值或最大值返回这个矩阵 dst(I) = min(src1(I), src2(I)), max同
minMaxLoc 定位矩阵中最小值、最大值的位置
compare 返回逐个元素比较结果的矩阵
bitwise_and, bitwise_not, bitwise_or, bitwise_xor 每个元素进行位运算,分别是和、非、或、异或
cvarrToMat 旧版数据CvMat,IplImage,CvMatND转换到新版数据Mat
extractImageCOI 从旧版数据中提取指定的通道矩阵给新版数据Mat
randu 以Uniform分布产生随机数填充矩阵,同 RNG::fill(mat, RNG::UNIFORM)
randn 以Normal分布产生随机数填充矩阵,同 RNG::fill(mat, RNG::NORMAL)
randShuffle 随机打乱一个一维向量的元素顺序
theRNG() 返回一个默认构造的RNG类的对象 theRNG()::fill(…)
reduce 矩阵缩成向量
repeat 矩阵拷贝的时候指定按x/y方向重复
split 多通道矩阵分解成多个单通道矩阵
merge 多个单通道矩阵合成一个多通道矩阵
mixChannels 矩阵间通道拷贝,如Rgba[]到Rgb[]和Alpha[]
sort, sortIdx 为矩阵的每行或每列元素排序
setIdentity 设置单元矩阵
completeSymm 矩阵上下三角拷贝
inRange 检查元素的取值范围是否在另两个矩阵的元素取值之间,返回验证矩阵
checkRange 检查矩阵的每个元素的取值是否在最小值与最大值之间,返回验证结果bool
sum 求矩阵的元素和
mean 求均值
meanStdDev 均值和标准差
countNonZero 统计非零值个数
cartToPolar, polarToCart 笛卡尔坐标与极坐标之间的转换
flip 矩阵翻转
transpose 矩阵转置,比较 Mat::t() AT
trace 矩阵的迹
determinant 行列式 |A|, det(A)
eigen 矩阵的特征值和特征向量
invert 矩阵的逆或者伪逆,比较 Mat::inv()
magnitude 向量长度计算 dst(I) = sqrt(x(I)2 + y(I)2)
Mahalanobis Mahalanobis距离计算
phase 相位计算,即两个向量之间的夹角
norm 求范数,1-范数、2-范数、无穷范数
normalize 标准化
mulTransposed 矩阵和它自己的转置相乘 AT * A, dst = scale(src - delta)T(src - delta)
convertScaleAbs 先缩放元素再取绝对值,最后转换格式为8bit型
calcCovarMatrix 计算协方差阵
solve 求解1个或多个线性系统或者求解最小平方问题(least-squares problem)
solveCubic 求解三次方程的根
solvePoly 求解多项式的实根和重根
dct, idct 正、逆离散余弦变换,idct同dct(src, dst, flags | DCT_INVERSE)
dft, idft 正、逆离散傅立叶变换, idft同dft(src, dst, flags | DTF_INVERSE)
LUT 查表变换
getOptimalDFTSize 返回一个优化过的DFT大小
mulSpecturms 两个傅立叶频谱间逐元素的乘法
好了,本节的内容就到此结束了,简单的解释了一下opencv,后续内容会继续更新的,关注博主,持续更新不迷路。拜了个拜。

以上是关于机器看世界的主要内容,如果未能解决你的问题,请参考以下文章