Spring Cloud Gateway一次请求调用源码解析
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Cloud Gateway一次请求调用源码解析相关的知识,希望对你有一定的参考价值。
简介: 最近通过深入学习Spring Cloud Gateway发现这个框架的架构设计非常简单、有效,很多组件的设计都非常值得学习,本文就Spring Cloud Gateway做一个简单的介绍,以及针对一次请求Spring Cloud Gateway的处理流程做一个较为详细的分析。

作者 | 寻筝
来源 | 阿里技术公众号
一 前言
最近通过深入学习Spring Cloud Gateway发现这个框架的架构设计非常简单、有效,很多组件的设计都非常值得学习,本文就Spring Cloud Gateway做一个简单的介绍,以及针对一次请求Spring Cloud Gateway的处理流程做一个较为详细的分析。
二 简介
Spring Cloud Gateway 即Spring官方推出的一款API网关,该框架包含了Spring5、SpringBoot2、Project Reactor,其中底层通信框架用的netty。Spring Cloud Gateway在推出之初的时候,Netflix公司已经推出了类似功能的API网关框架ZUUL,但ZUUL有一个缺点是通信方式是阻塞的,虽然后来升级到了非阻塞式的ZUUL2,但是由于Spring Cloud Gateway已经推出一段时间,同时自身也面临资料少、维护性较差的因素没有被广泛应用。
1 关键术语
在使用Spring Cloud Gateway的时候需要理解三个模块,即
Route:
即一套路由规则,是集URI、predicate、filter等属性的一个元数据类。
Predicate:
这是Java8函数式编程的一个方法,这里可以看做是满足什么条件的时候,route规则进行生效。
Filter:
filter可以认为是Spring Cloud Gateway最核心的模块,熔断、安全、逻辑执行、网络调用都是filter来完成的,其中又细分为gateway filter和global filter,区别在于是具体一个route规则生效还是所有route规则都生效。
可以先上一段代码来看看:
@RequestMapping("/paramTest")
public Object paramTest(@RequestParam Map<String,Object> param)
return param.get("name");
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder)
return builder.routes()
.route("path_route", r ->
r.path("/get")
.filters(f -> f.addRequestParameter("name", "value"))
.uri("forward:///paramTest"))
.build();
- route方法代表的就是一个路由规则;
- path方法代表的就是一个predicate,背后的现实是PathRoutePredicateFactory,在这段代码的含义即当路径包含/get的时候,当前规则生效。
- filters方法的意思即给当前路由规则添加一个增加请求参数的filter,每次请求都对参数里添加 name:value 的键值对;
- uri 方法的含义即最终路由到哪里去,这里的forward前缀会将请求交给spring mvc的DispatcherHandler进行路由,进行本机的逻辑调用,除了forward以外还可以使用http、https前缀进行http调用,lb前缀可以在配置注册中心后进行rpc调用。

上图是Spring Cloud Gateway官方文档给出的一个工作原理图,Spring Cloud Gateway 接收到请求后进行路由规则的匹配,然后交给web handler 进行处理,web handler 会执行一系列的filter逻辑。
三 流程分析
1 接受请求
Spring Cloud Gateway的底层框架是netty,接受请求的关键类是ReactorHttpHandlerAdapter,做的事情很简单,就是将netty的请求、响应转为http的请求、响应并交给一个http handler执行后面的逻辑,下图为该类的源码仅保留核心逻辑。
@Override
public Mono< Void> apply(HttpServerRequest request, HttpServerResponse response)
NettyDataBufferFactory bufferFactory = new NettyDataBufferFactory(response.alloc());
ServerHttpRequest adaptedRequest;
ServerHttpResponse adaptedResponse;
//转换请求
try
adaptedRequest = new ReactorServerHttpRequest(request, bufferFactory);
adaptedResponse = new ReactorServerHttpResponse(response, bufferFactory);
catch (URISyntaxException ex)
if (logger.isWarnEnabled())
...
...
return this.httpHandler.handle(adaptedRequest, adaptedResponse)
.doOnError(ex -> logger.warn("Handling completed with error: " + ex.getMessage()))
.doOnSuccess(aVoid -> logger.debug("Handling completed with success"));
2 WEB过滤器链
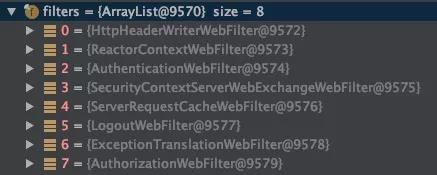
http handler做的事情第一是将request 和 response转为一个exchange,这个exchange非常核心,是各个filter之间参数流转的载体,该类包含request、response、attributes(扩展字段),接着做的事情就是web filter链的执行,其中的逻辑主要是监控。

其中WebfilterChainParoxy 又会引出新的一条filter链,主要是安全、日志、认证相关的逻辑,由此可见Spring Cloud Gateway的过滤器设计是层层嵌套,扩展性很强。
3 寻找路由规则
核心类是RoutePredicateHandlerMapping,逻辑也非常简单,就是把所有的route规则的predicate遍历一遍看哪个predicate能够命中,核心代码是:
return this.routeLocator.getRoutes()
.filter(route ->
...
return route.getPredicate().test(exchange);
)因为我这里用的是path进行过滤,所以背后的逻辑是PathRoutePredicateFactory来完成的,除了PathRoutePredicateFactory还有很多predicate规则。
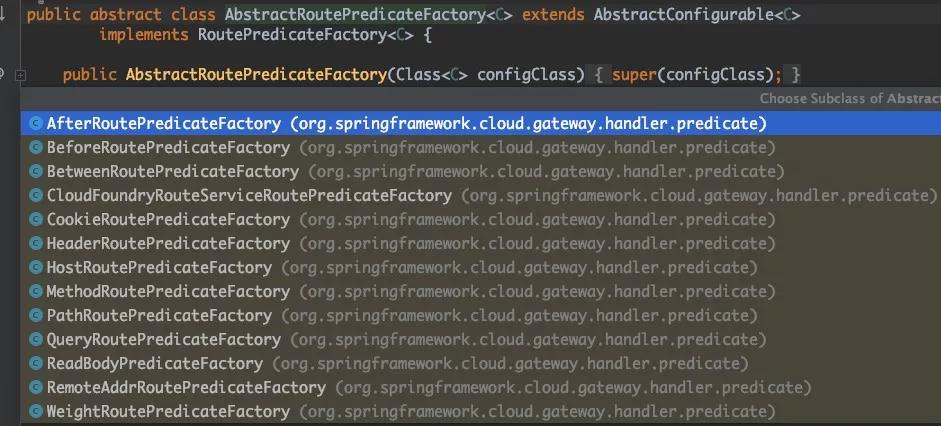
这些路由规则都能从官方文档上找到影子。
4 核心过滤器链执行
找到路由规则后下一步就是执行了,这里的核心类是FilteringWebHandler,其中的源码为:

做的事情很简单:
- 获取route级别的过滤器
- 获取全局过滤器
- 两种过滤器放在一起并根据order进行排序
- 执行过滤器链

因为我的配置里包含了一个添加请求参数的逻辑,所以红线箭头处就是我配置的gateway filter名为 AddRequestParameterGatewayFilterFactory,其余全是Gloabl Filter,这些过滤器的功能主要是url解析,请求转发,响应回写等逻辑,因为我们这里用的是forward schema,所以请求转发会由ForwardRoutingFilter进行执行。
5 请求转发
ForwardRoutingFilter做的事情也很简单,直接复用了spring mvc的能力,将请求提交给dispatcherHandler进行处理,dispatcherHandler会根据path前缀找到需要目标处理器执行逻辑。
@Override
public Mono< Void> filter(ServerWebExchange exchange, GatewayFilterChain chain)
URI requestUrl = exchange.getRequiredAttribute(GATEWAY_REQUEST_URL_ATTR);
String scheme = requestUrl.getScheme();
if (isAlreadyRouted(exchange) || !"forward".equals(scheme))
return chain.filter(exchange);
setAlreadyRouted(exchange);
//TODO: translate url?
if (log.isTraceEnabled())
log.trace("Forwarding to URI: "+requestUrl);
return this.dispatcherHandler.handle(exchange);
6 响应回写
响应回写的核心类是NettyWriteResponseFilter,但是大家可以注意到执行器链中NettyWriteResponseFilter的排序是在最前面的,按道理这种响应处理的类应该是在靠后才对,这里的设计比较巧妙。大家可以看到chain.filter(exchange).then(),意思就是执行到我的时候直接跳过下一个,等后面的过滤器都执行完后才执行这段逻辑,这种行为控制的方法值得学习。
@Override
public Mono< Void> filter(ServerWebExchange exchange, GatewayFilterChain chain)
// NOTICE: nothing in "pre" filter stage as CLIENT_RESPONSE_ATTR is not added
// until the WebHandler is run
return chain.filter(exchange).then(Mono.defer(() ->
HttpClientResponse clientResponse = exchange.getAttribute(CLIENT_RESPONSE_ATTR);
if (clientResponse == null)
return Mono.empty();
log.trace("NettyWriteResponseFilter start");
ServerHttpResponse response = exchange.getResponse();
NettyDataBufferFactory factory = (NettyDataBufferFactory) response.bufferFactory();
//TODO: what if it's not netty
final Flux< NettyDataBuffer> body = clientResponse.receive()
.retain() //TODO: needed?
.map(factory::wrap);
MediaType contentType = response.getHeaders().getContentType();
return (isStreamingMediaType(contentType) ?
response.writeAndFlushWith(body.map(Flux::just)) : response.writeWith(body));
));
四 总结
整体读完Spring Cloud Gateway请求流程代码后,有几点感受:
- 过滤器是Spring Cloud Gateway最核心的设计,甚至于可以夸张说Spring Cloud Gateway是一个过滤器链执行框架而不是一个API网关,因为API网关实际的请求转发、请求响应回写都是在过滤器中做的,这些是Spring Cloud Gateway感知不到的逻辑。
- Spring Cloud Gateway路由规则获取的模块具备优化的空间,因为是循环遍历进行获取的,如果每个route规则较多,predicate规则较复杂,就可以考虑用map进行优化了,当日route规则,predicate规则也不会很复杂,兼顾到代码的可读性,当前方式也没有什么问题。
- 作为API网关框架,内置了非常多的过滤器,如果有过滤器的卸载功能可能会更好,用户可用根据实际情况卸载不必要的功能,背后减少的逻辑开销,在调用量极大的API网关场景,收益也会很可观。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于Spring Cloud Gateway一次请求调用源码解析的主要内容,如果未能解决你的问题,请参考以下文章
java spring cloud gateway读取请求正文