全球计算机一起炼丹是怎样的体验?
Posted Wang_AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全球计算机一起炼丹是怎样的体验?相关的知识,希望对你有一定的参考价值。
你好,我是黑泪。最近在逛全球最大交友网站Github时,无意中发现了一个“宝库”:hivemind[1],短短时间内已经积攒了840多个🌟,这个仓库可以实现“跨网络Pytorch分布式训练”。
简单来说,它可以实现不同大学、公司和个人的数百台计算机上合作训练一个基于Pytorch框架的大型深度学习模型。
仔细想想觉得还挺有意思的,以前大家都是独自炼丹,现在全球的小伙伴可以跨越种族与地域合作,大家各自提供硬件设备,共同训练一个超大模型。
一、主要特点
跨网络分布式训练主要有以下4个特点:
1)“人人都是主角”:分布式训练不存在主节点,每台设备都很重要,因为底层的分布式哈希表允许在一个分散的网络中连接计算机;
2)“眼里可以容沙子”:反向传播具有容错性,即使一些节点没有反应或反应时间过长,前向传播和反向传播也能成功;
3)“雨露均沾”:模型参数的平均化分散进行,逐步地迭代聚合来自多个计算机的参数更新,而不需要在整个网络中同步[2];
4)“有容乃大”:可以训练任意大小的神经网络,其部分网络层可以分布在具有Decentralized Mixture-of-Experts[3]功能的计算机之间。
二、安装方法
在满足Python 3.7+ 和 PyTorch>=1.6.0的环境下,可以直接pip install安装:
pip install hivemind或者从源码安装:
git clone https://github.com/learning-at-home/hivemind.git
cd hivemind
pip install .安装后如果需要验证是否成功,可以运行一下命令
pip install .[dev]pytest tests/三、使用方法
官方库提供了基于CIFAR-10数据集训练简单神经网络的样例[4]以及基于WikiText103数据集训练ALBERT-large-v2的样例[5]。
我按照教程的代码运行了一下CIFAR-10的训练样例,进程会先下载CIFAR-10的数据集,然后开始训练,此时这个库会在网络上搜索小伙伴。

由于这是官方教程,大概率同一时刻只有我自己在训练。所以我新增了一个同样的训练进程,按照教程修改了关键部分的代码,来演示是否真的可以做到分布式训练。
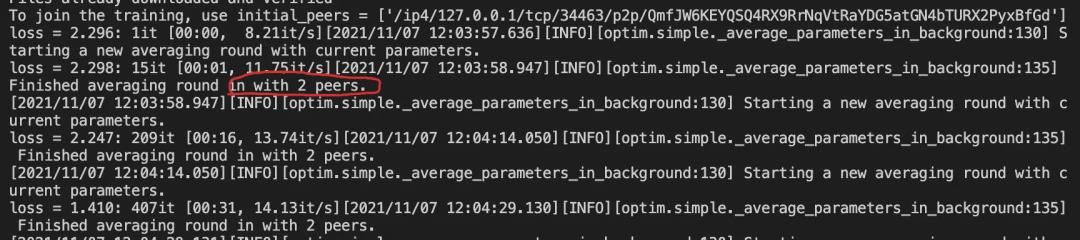
可以看到命令行输出变成了2个小伙伴,这两个进程的损失会进行平均化,于是我又新增了一个训练进程。

果不其然,命令行输出变成3个小伙伴了,也就意味着,哪怕你的伙伴在国外,只要你们的网络能连接上,能互相提供“唯一的任务识别ID”,就能一起训练了,就算你只有CPU,只要他有GPU不就行了

四、小结
分布式训练ALBERT-large-v2就不在这里演示啦,感兴趣的小伙伴可以去官方库实操一下,官方样例只需要在优化器那里改动一下即可,使用起来还是很方便的。
这个库整体挺有意思的,我之前接触的分布式训练最多是基于torch的多机多卡,这个库直接把深度学习训练整成了社群,就像蚁群一样,努力实现共同的目标。
参考链接
[1]https://github.com/learning-at-home/hivemind
[2]https://arxiv.org/abs/2103.03239
[3]https://arxiv.org/abs/2002.04013
[4]https://learning-at-home.readthedocs.io/en/latest/user/quickstart.html
[5]https://github.com/learning-at-home/hivemind/tree/master/examples/albert
觉得还不错就给我一个小小的鼓励吧!以上是关于全球计算机一起炼丹是怎样的体验?的主要内容,如果未能解决你的问题,请参考以下文章
全球网友元宵一起创作赏月图,体验百度文心大模型AIGC创造力