使用 arxiv-sanity &paperwithcode 跟进最新研究领域的文章
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 arxiv-sanity &paperwithcode 跟进最新研究领域的文章相关的知识,希望对你有一定的参考价值。
1.arxiv-sanity介绍
arxiv.org是一个非常大的预印本资源库,里面有大量的最新的论文,但缺点是浏览、搜索和排序不是很方便。这个资源库每天会更新大量的论文,如果通过手动搜索和浏览则效率很低,高引用的好文章难以及时的找到并阅读,造成时间的浪费。从而,arxiv-sanity 因运而生。
1.2 arxiv-sanity基本功能
1、便捷的预览
首先,arxiv-sanity在展示最新更新的文献时,提供了可读性更强的缩略图预览模式方便读者来快速预览,并在缩略图下方的绿色区域显示文献的abstract 。

2.感兴趣相关度排序
点击右上角的 ‘show similar’,文献列表会按照与这篇文章的相关度进行排序,接下来会看到 arxiv 上所有关于 instance segmentation 的论文。这个功能是基于TF-DF算法来实现的,效果很好。

3.个人图书馆
注册和登录账户之后,点击右上角的那个保存图标就可以将感兴趣的 paper 收藏到个人图书馆。

4.感兴趣推荐系统
arxiv-sanity 还可以通过收藏的内容给你推荐你也许会感兴趣的论文。背后的实现原理是通过将Library 中的论文标记为positive,Library之外的论文标记为negative,然后基于bigram文本特征提取训练 personal SVM,最后在reconmmended 标签里推荐给你,并可通过设置时间进一步筛选文献。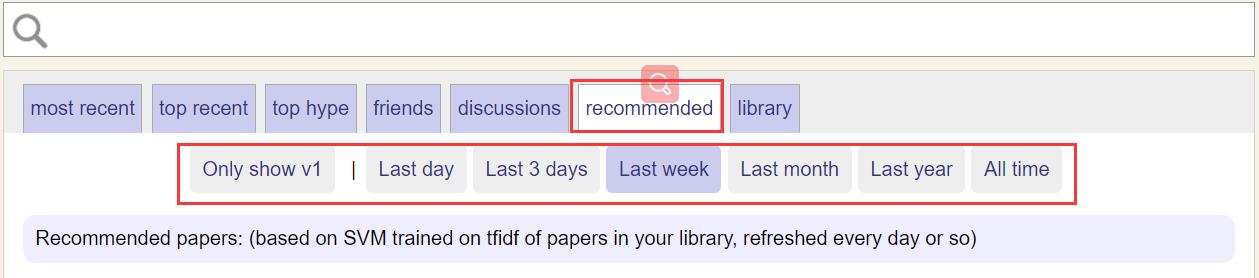
5.看看大家都在看什么
top recent 标签展示的是arxiv-sanity上被用户收藏最多的文献。这些文献也可以按照时间来筛选。即使你不是注册用户,也可以浏览到大家都在收藏的文献。
6.网站代码开源
在页面左上方可以看到,arxiv-sanity只展示machine learning的论文,如CV,CL等ML的分支领域,因为这是arxiv-sanity作者自己的研究领域。作者已经把 arxiv-sanity 开源了,所以如果你想根据自己的研究领域新建自己的arxiv-sanity,可以去GitHub fork arxiv-sanity-preserver。
cs.CV: Computer Vision and Pattern Recognition 计算机视觉与模式识别;
cs.CL:Computation and Language 计算语言学;
cs.LG:Learning 机器学习(计算机科学);
cs.AI:Artificial Intelligence 人工智能;
cs.NE:Neural and Evolutionary Computing 神经与演化计算;
stat.ML:Machine Learning 机器学习(统计学)
2.paperwithcode
阅读Paper,进一步阅读 Code 才能对论文的思路和 Trick 彻底的了解。
paperwithcode 网站将 ArXiv 上的最新机器学习论文与 GitHub 上的代码(TensorFlow/PyTorch/MXNet /等)对应起来。据网站开发者介绍,59858篇论文(带源码)、5151个数据集,且在不断的更新中。paperwithcode 网站广泛涉及了各类机器学习任务,包括计算机视觉、自然语言处理等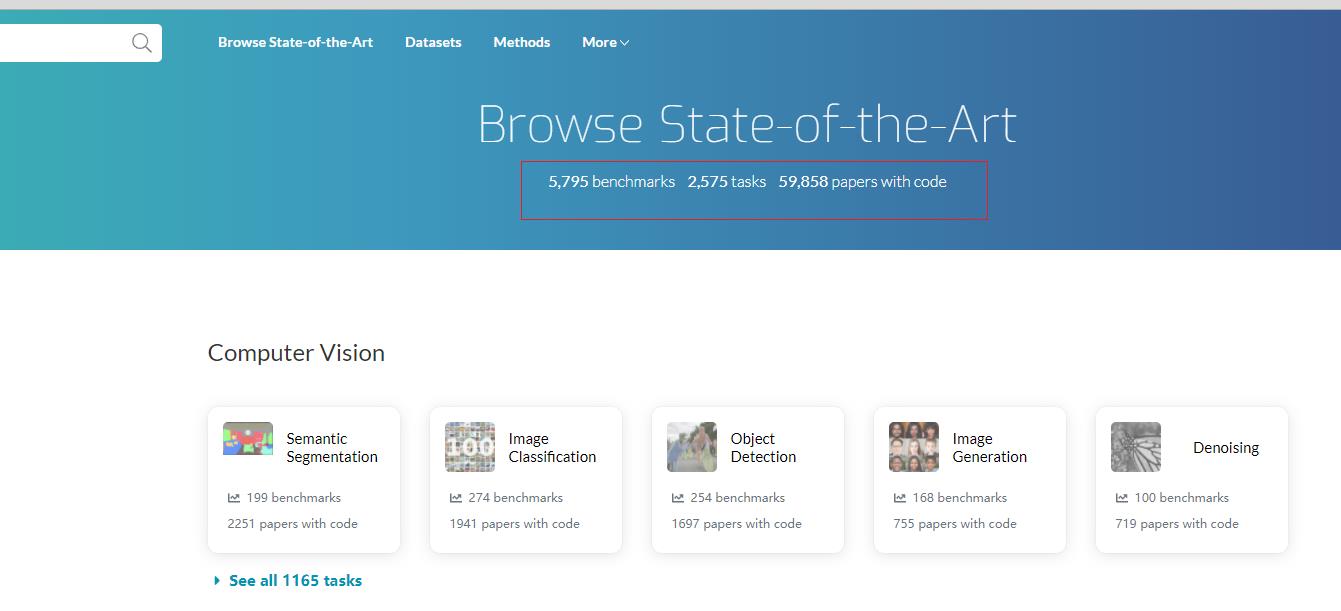
搜索后进行查找
参考链接:
以上是关于使用 arxiv-sanity &paperwithcode 跟进最新研究领域的文章的主要内容,如果未能解决你的问题,请参考以下文章
paping使用来测试联通&网站由于tcp协议导致的无法通信问题超时问题