Day428.RabbitMq消息队列--2 -谷粒商城
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day428.RabbitMq消息队列--2 -谷粒商城相关的知识,希望对你有一定的参考价值。
RabbitMq消息队列–2 -谷粒商城
一、RabbitMQ消息确认机制
1、可靠抵达
在分布式系统中,比如现在有很多微服务,微服务连接上消息队列服务器,其它微服务可能还要监听这些消息,
但是可能会因为服务器抖动、宕机,MQ 的宕机、资源耗尽,以及无论是发消息的生产者、还是收消息的消费者,它们的卡顿、宕机等各种问题,都会导致消息的丢失,比如发送者发消息的时候,给弄丢了 ,看起来消息是发出去了,MQ网络抖动没接到, 或者MQ接到了,但是它消费消息的时候,因为网络抖动又没拿到,等等各种问题
所以在分布式系统里面,一些关键环节,我们需要保证消息一定不能不丢失,比如:订单消息发出去之后,该算库存的、该算积分的、该算优惠的等等 ,这些消息千万不能丢,因为这都是经济上的问题
所以,想要保证不丢失,也就是可靠抵达,无论是发消息,可靠的抵达MQ,还是收消息,MQ的消息可靠抵达到我们的消费端,我们一定要保证消息可靠抵达,包括如果出现错误,我们也应该知道哪些消息丢失了,
以前我们要做这种事情,可以使用事务消息,比如我们在发消息的时候,我们发消息的客户端首先会跟 MQ 建立一个连接,会在通道里面发消息,可以将通道设置成事务模式,这样发消息,只有整个消息发送过去,MQ消费成功给我们有完全的响应以后,我们才算消息成功,
但是使用事务消息,会使性能下降的很严重,官方文档说,性能会下降250倍…
为了保证在高并发期间能很快速的,确认哪些消息成功、哪些消息失败,我们引入了消息确认机制,
2、消息准确送达的流程

首先生产者准备一个消息,消息只要投递给 MQ 服务器,服务器收到以后,消息该怎么存怎么存,该投给哪投给哪,所以 Broker 首先会将消息交给 Exhchange,再有 Exchange 送达给 Queue,所以整个发送消息的过程,牵扯到两个
- P端到B端的过程
- E端到Q端的过程
3、如何保证消息的可靠送达
为了保证消息的可靠送达,每个消息被成功, 我们引入了发送者的两个确认回调
第一个是确认回调,叫 confirmCallback,就是P端给B端 发送消息的过程,Broker 一旦收到了消息,就会回调我们的方法 confirmCallback,这是第一个回调时机,这个时机就可以知道哪些消息到达服务器了
但是服务器收到消息以后,要使用 Exchange 交换机,最终投递给 Queue,但是投递给队列这个过程可能也会失败,比如我们指定的路由键有问题,或者我们队列正在使用的过程中,被其它的一些客户端删除等操作,可能都会投递失败,投递失败就会调用 returnCallback
当然,这两种回调都是针对的发送端
同样的,消费端,只要消息安安稳稳的存到了消息队列,接下来就由我们消费端进行消费了,但是消费端引用消费,会引入 ack 机制(消息确认机制)
这个机制能保证, 让 Broker 知道哪些消息都被消费者正确的拿到了,如果消费者正确接到,这个消息就要从队列里面删除,如果没有正确接到,可能就需要重新投递消息
- 总结
整个可靠抵达,分为两端处理,第一种是发送端的两种确认模式,第二个是消费端的 ack机制
4、发送端确认
成功与否都会触发
生产者发送给broker后的回调
①确认回调-ConfimCallback
spring:
rabbitmq:
publisher-confirms: true # 开启发送端确认
-
在创建 connectionFactory 的时候设置 PublisherConfirms(true) 选项,开启confirmcallback 。
-
CorrelationData:用来表示当前消息唯一性。
-
消息只要被 broker 接收到就会执行 confirmCallback,如果是 cluster 模式,需要所有broker 接收到才会调用 confirmCallback。
-
被 broker 接收到只能表示 message 已经到达服务器,并不能保证消息一定会被投递到目标 queue 里。所以需要用到接下来的 returnCallback 。
-
代码
@Configuration public class MyRabbitConfig @Autowired private RabbitTemplate rabbitTemplate; //自定义初始化initRabbitTemplate @PostConstruct //MyRabbitConfig对象构造器完成之后调用 public void initRabbitTemplate() rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() /** * 生产者发送给broker后的回调 * @param correlationData 当前消息的唯一关联数据(这个是消息的唯一id) * @param b 消息是否成功收到 * @param s 失败的原因 */ @Override public void confirm(CorrelationData correlationData, boolean b, String s) //指定你要做什么 ); );
②退回回调-ReturnCallback
成功不会触发
broker发送给队列(Queue)后的失败回调
spring:
rabbitmq:
publisher-returns: true # 开启发送端消息抵达队列的确认
template:
mandatory: true # 只要消息抵达了队列,以异步发送优先回调这个returnconfirm
- 代码
@Configuration
public class MyRabbitConfig
@Autowired
private RabbitTemplate rabbitTemplate;
//自定义初始化initRabbitTemplate
@PostConstruct //MyRabbitConfig对象构造器完成之后调用
public void initRabbitTemplate()
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback()
/**
* broker发送给队列(Queue)后的失败回调
* @param message 哪个投递失败的消息信息
* @param i 回复码
* @param s 回复的文本内容
* @param s1 当时这个消息发送给哪个交换机
* @param s2 但是这个消息用的哪个路由键
*/
@Override
public void returnedMessage(Message message, int i, String s, String s1, String s2)
//指定你要做什么
);
5、消费端确认-Ack消息确认机制
保证每个消息被正确消费,此时broker才可以删除这个消息
消费端默认是自动确认的,只要消息接收到,客户端会自动确认,服务端就会移除这个消息
queue无消费者,消息依然会被存储,直到消费者消费
①带来的问题
- 消费端收到很多消息,自动回复给服务器ack,只有一个消息处理成功,消费端突然宕机了,结果MQ中剩下的消息全部丢失了
②解决
- 消费端如果无法确定此消息是否被处理完成,可以手动确认消息,即处理一个确认一个,未确认的消息不会被删除
③手动确认模式
rabbitmq:
listener:
simple:
acknowledge-mode: manual #手动确认模式
只要我们没有明确告诉MQ收到消息。没有 Ack,消息就一直是 Unacked 状态,即使 consumer 宕机,消息也不会丢失,会重新变为 Ready,等待下次有新的 Consumer 连接进来时,再发给新的 Consumer
消费者获取到消息,成功处理,可以回复 Ack 给 Broker

-
ack()用于肯定确认;broker 将移除此消息 -
nack()用于否定确认;可以指定broker 是否丢弃此消息,可以批量 -
reject()用于否定确认;同上,但不能批量

消息如果一直没有调用ack()的话,则会一直处于 Unacked 状态,这些 Unacked 状态的消息,都不会被丢弃,如果客户端宕机,等服务端感知到消费端宕机了,它就会将这个消息改为 Ready 状态,Ready 状态的消息,全部都会被重新投递
- 总结
结合消费端与发送端的消息确认机制,就能保证消息一定发出去,也能一定让别人接收到,即使没接收到,也可以重新发送,最终达到消息百分百不丢失!
二、Spring Boot整合RabbitMQ
引入在订单服务:achangmall-order
1、导入依赖
<!--RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2、添加配置
spring:
rabbitmq:
host: 192.168.109.101
port: 5672
virtual-host: /
3、开启RabbitMQ功能
启动类上添加com.achang.achangmall.AchangmallOrderApplication
@EnableRabbit
- 通过
AMQPAdmin来操作RabbitMQ - 通过
RabbitTemplete来发送消息
4、注解使用
/*
类和方法上面都可以加,一般加在类上
表示监听哪些队列
*/
// queues:声明需要监听的所有队列
@RabbitListener(queues = "hello-java-queue")
/*
与@RabbitListener组合使用可以区分不同重载的消息
只能加在方法上
指明哪个方法接收消息
*/
@RabbitHandler

5、自定义消息转换器为:Json类型
com.achang.achangmall.order.conf.MyRabbitConfig
@Configuration
public class MyRabbitConfig
@Bean
public MessageConverter messageConversionException()
return new Jackson2JsonMessageConverter();
三、RabbitMQ延时队列
1、延时队列场景
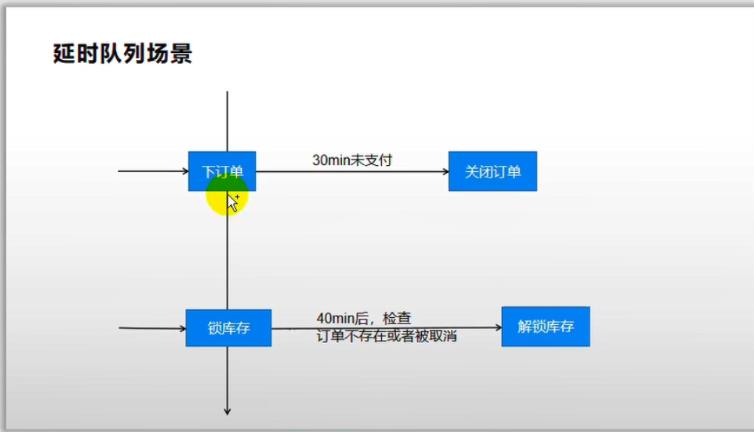
比如这个库存锁成功了,我们害怕订单后续操作失败了,导致库存没法回滚,我们库存要自己解锁,
那么可以把锁成功的消息,先发给消息队列,但是让消息队列先暂存一会儿。比如我们存上三十分钟,
因为我们现在的订单有可能是成功了,也有可能是失败。
无论是成功失败,我们三十分钟以后,再对订单进行操作,比如订单不支付,我们都给它关了。所以三十分钟以后订单肯定就见分晓了。
四十分钟以后我们把这个消息再发给解锁库存服务,解锁库存服务,一看这个订单早都没有了,或者订单都没有支付,被人取消了。
它就可以把当时锁的库存自动的解锁一下。
相当于我们整了一个定时的扫描订单、一个定时的库存解锁消息。
- 为什么是40分钟
因为订单是保存30分钟之后,再对其进行彻底检查,这个检查是需要时间的,我们需要确保所有订单都处理完了,再对库存进行操作,所以设置为40分钟
2、定时任务的问题
这两个业务都使用定时任务的话会给我们带来很大的问题。
首先我们定时任务消耗我们这个系统内存,并且它增加数据库压力
因为定时任务是每隔一段时间就要轮巡去来访问数据库。
相当于我们这个数据库呢每隔一段时间就要做一个全盘扫描,扫这些订单,扫这些库存,这样整个数据库的压力就会非常大。
定时任务最致命的问题是它有较大的时间误差。
比如我们来看下面这个场景。
- 定时任务的时效性问题

假设现在的时间是 10:00,如果我们使用定时任务,每隔 30分钟来扫一次,
假设第一次下单,这个订单是在 10:01 下的,在这个订单之前,刚有一个定时任务运行完,
10:30 的时候,定时任务开始扫描,扫描的时候,10:01 下的这个订单还没有经过 30分钟 的煎熬期。
因为我们设计的是只有 30分钟以后没支付才能关,它还差1分钟,所以我们这个定时任务扫到它的时候,发现它不符合条件,那不给它进行关单,
接下来
结果定时任务刚一结束,这个订单就相当于超时了。
超时了以后,那就得等下一次的定时任务,相当于我们再来等 29分钟,这样再加上前期订单保存的这 30分钟。
有1分钟是过期时间,相当于59分钟我们这个订单可能才会被扫到,被定时任务发现过期了要解锁库存了。
这就是定时任务可能会出现的时效性问题。
那基于这些考虑,我们就不会在这个场景下采用定时任务。
我们采用 MQ 的延时队列
3、延时队列使用介绍
延时队列,它是基于消息的 TTL(存活时间)以及死信Exchange (路由)结合的
那有了这个延时队列,应该是这样工作的。
比如说我们这个下订单,订单一下成功以后,我们就给消息队列里发一个消息:哪个单下成功了。
我们发的这个消息发到队列里边,这个队列最大的特点就是它们这些消息三十分钟以后才能被人收到。
这样的话,我们如果有一个服务专门来监听这个队列,那我们这里边存来的这些订单下成功的消息。
只有三十分钟以后才会来到我们的监听者的这一块。那这样监听者拿到这个订单,再一查结果发现订单还没支付,那么就给你关了。
所以整个过程无需任何定时任务,我们相当于让 MQ 把消息暂缓一段时间。
包括我们这个锁库存也一样,只要我们库存锁成功了,我们就给 MQ 里边发一个消息。
MQ 先把消息保持上一段时间,不发然后到了保存时间以后,MQ 自己发出去,发出去之后,
解锁库存的服务,发现订单没支付或者订单早都没有了,就给它解锁库存。
所以我们如果使用延时队列,基本上就能解决定时任务的大面积时效性问题。
这个延时队列可能时效性差那么一秒、五秒乃至于一分钟,但是都不可能差上二十分钟。
所以,我们应该使用延时队列的这个场景来做我们的下订单、关闭订单、锁库存以后的解锁库存操作。
最终保证我们的事务一致性,也就是我们事务的最终一致性。
我们引入MQ 的第一个目的,就是来解决事务的最终一致性
因为我们这个订单最终还是要关的。所以我们使用 MQ 来暂缓一段时间消息。不占用系统的任何资源,只是多架设一个MQ 服务器,等时间到了以后,保证我们最终的数据一致。
4、延时队列最大的特点
-
TTL
-
死信路由
四、消息的 TTL(Time To Live)
消息的TTL就是消息的存活时间
1、RabbitMQ 可以对队列和消息分别设置TTL
无论给哪个设置,它的意思都是一样的
就是指这个消息只要在我们指定的时间里边没有被人消费,那这个消息就相当于没用了,我们就把称为死信,然后这个消息相当于死了。
死了以后我们就可以把它做一个单独处理。
我们如果是给队列设置了过期时间,
队列里边的这些消息,我们存到里边。
如果这些消息一直没有被人监听,那一有人监听肯定就拿到了。
如果我们这个消息呢没有连上任何的消费者,队列里面的消息,只要三十分钟一过,那这些消息呢就会成为死信。
那就可以把它扔掉了,服务器默认就会把它进行丢弃。
那我们给消息设置,也是一样的效果。
如果我们给单独的每一个消息设置,设置了三十分钟过期时间,存到这个队列里边,
只要这个队列没人消费这个消息,消息三十分钟没有人消费,它就自己过期了。
设置消息的 TTL 的目的就是,在我们指定的这段时间内,没人把这个消息取走,这个消息就会被服务器认为是一个死信。
如果队列设置了,消息也设置了,那么会取小的。所以一个消息如果被路由到不同的队列中,这个消息死亡的时间有可能不一样(不同的队列设置)。这里单讲单个消息的TTL,因为它才是实现延迟任务的关键。可以通过设置消息的expiration字段或者x-message-ttl属性来设置时间,两者是一样的效果。
五、死信路由(Dead Letter Exchanges)DLX
1、什么是死信
一个消息如果满足以下条件,那它就会成为死信
- 被Consumer拒收了,并且reject方法的参数里requeue是false。
也就是说不会被再次放在队列里,被其他消费者使用。 ( basic.reject/ basic.nack ) requeue=false - 消息的TTL到了,消息过期了。
- 假设队列的长度限制满了,排在前面的消息就会被丢弃或者扔到死信路由上
但是如果这个消息死了,就直接把它丢掉,那就没有延时队列的功能了
2、死信路由的实现
假设我给队列设一个过期时间三十分钟,
然后三十分钟以后,只要这个消息没人消费,我们就认为是死信,我们让服务器把死信扔给隔壁的一个交换机。
这个交换机我们称为死信路由,它专门来收集这些死信,然后死信路由会把这些死信再送到另外一个新队列里边,别人专门监听这个新队列
注意:一开始我们设置30分钟过期的那个队列,我们不会让任何人监听,因为只要被人一监听,消息就算设置了过期时间,被人一拿,也就什么都没了。
死信去的那个新队列,里面其实存的都是初始队列里边过了三十分钟以后的这些消息,都是被死信路由给送过去的
这样就模拟了一个延迟,我们三十分钟让它在一开始的队列存一下,因为没人消费它,存完了以后又移到一个新的队列里。
如果我们解锁订单的服务,一直来监听那个新队列,
订单一下成功,先把订单消息放到初始队列延迟上三十分钟,延迟以后呢,交给交换机。
交换机再路由到新队列。
那么收到的这些订单消息一定都是过了30分钟的。
死信路由呢就是一个非常普通的路由而已。
只要 TTL 跟 死信路由两者结合,我们就能模拟出延时队列,
消息在初始队列保持三十分钟,这个队列一直不被人消费,然后三十分钟一过,消息被服务器认为是死信,再丢给交换机,然后,这个交换机再丢给我们指定的队列,然后这个指定的队列再被人消费。
六、延时队列的实现
1、设置队列过期时间

发送者:P
路由键:deal.message
非常普通的交换机:X
死信队列:delay.Sm.queue
死信路由:delay.exchange
新队列:test.queue
消费者:C
首先发送者发消息的时候,指定了一个路由键,然后这个消息先会被交给一个交换机,
交换机会按照路由键把它交给一个队列,那这个队列跟交换机的绑定关系就是那个路由键,
但这个队列很特殊,它有这么几项设置
-
x-message-ttl:消息的存活时间,它以毫秒为单位,相当于300秒,也就是五分钟以后消息过期 -
x-dead-letter-exchange:死信交换机,就是死信路由,意思就是告诉服务器当前这个队列里边的消息死了,别乱丢,扔给隔壁的死信路由 -
delay-message:死信队列往死信路由那扔消息用的路由键
所以我们的死信就会通过delay.message这个路由键交给我们的死信路由,一个普普通通的路由,
然后死信路由收到死信之后,一看路由键是delay.message,它就会找哪个队列绑定的路由键叫delay.message。
然后,死信路由发现test.queue这个队列的路由键是delay.message,它就把这个消息就交给了它,
以后只要有人监听test.queue这个队列,那这个人收到的消息都是在死信队列存过五分钟以后的过期消息,这是我们延时队列的第一种实现,设置队列过期时间。
2、设置消息过期时间

比如我们这个消费者发了一个消息,它为发的这个消息,单独设置了一个过期时间,比如它是三百秒,五分钟。
然后,这个消息经过交换机交给我们这个的死信队列,
由于消息存到死信队列以后,没有人会永远去监听里边的内容。所以这个消息就会一直呆在死信队列里边。
服务器就会来检查这个消息,结果发现它是五分钟以后过期的,所以五分钟以后服务器就会把第一个消息拿出来,
然后把这个消息,按照我们队列指定的:死了的消息交给死信路由,然后再交给test.queue
所以消费者最终收到的消息也都是五分钟以后的过期消息。
3、推荐使用哪种方式
- 推荐给队列设置过期时间
如果给消息设置过期时间的话,我们 Rabbit MQ 采用的是惰性检查机制,也就是懒检查,
什么叫懒检查,
假设我们这个 MQ 这个队列里边存了第一个消息。
第一个消息,我们指定它是一个五分钟以后过期的,我们给这个队列连发了三条消息。
第一个是五分钟以后过期,
第二个是一分钟以后过期
第三个是一秒以后过期,
我们按照正常情况,应该是一秒过期的,我们优先弹出这个队列,但是服务器不是这么检查的。
服务器是这样,它从队列里边呢先来拿第一个消息。
第一个消息呢,它刚一拿,发现是五分钟过期,然后呢,它又放回去了。五分钟以后再来拿
服务器呢五分钟以后会把第一个消息拿出来,那第一个消息呢相当于就过期了,变成死信交到交换机,最终进入死信队列,被消费者拿到
所以第一个消息过期了以后,服务器来拿第二个消息。
第二个消息,它说一分钟过期,但是服务器也不用等它一分钟,因为它发消息的时候又一个时间,服务器一看发现早过期了,然后就赶紧把它扔了。
然后,第三个它说一秒以后过期了。那我们也给它扔了,
但是我们会发现,扔后面的这两个消息,就会在五分钟以后才扔。
所以我们应该使用给整个队列设置一个过期时间,这样队列里边所有的消息都是这个过期时间,我们服务器直接批量全部拿出来,往后放就行了。
七、延时队列模拟订单关闭
1、基本设计

需求:让订单一旦下单成功以后,我们过了三十分钟没有人支付,让它来自动关闭订单。那么说以前可以用定时任务来做。那我们现在呢就用延时队列完成。
首先我们创建两个交换机,user.order.delay.exchange、user.order.exchange
我们还创建了两个队列,user.order.delay.queue、user.order.queue
首先生产者,就是我们的订单服务。
订单服务只要完成一个订单,也就是下单成功,他先给我们Rabbit MQ来发一个消息。这个消息用的路由键就叫order_delay。
然后这个消息,先发给user.order.delay.exchange这个交换机
然后这个交换机就一看,有消息来了,用的是这个order_delay的路由键,它就找到下面的user.order.delay.queue这个队列跟他进行绑定。
但是大家注意。
我们这个叫user.order.delay.queue的队列,是一个特殊的队列,
我们设置了三个参数。
-
:60000`:消息存活时间,1分钟
-
x-dead-letter-exchange:user.order.exchange:死信路由 -
x-dead-letter-routing-key:延时队列往死信路由那扔消息用的路由键
里面的消息只要一超过1分钟,我们的Rabbit MQ就会从队列里边把这个消息拿出来,这个消息变成死信了。
然后死信会交给我们这个隔壁的user.order.exchange交换机,
然后,这个交换机通过绑定的路由键order,找到下面的user.order.queue队列,
最终死信,就会跑到user.order.queue队列里边。
只要有消费者去来监听这个user.order.queue队列里边的内容,就会发现里面的消息一定是过期1分钟以后的消息。
所以只要这个队列收到内容了,我们就可以判断这个订单,只要没支付,就可以给他关单。
2、设计规范
每一个微服务有他自己的交换机,当前微服务加event,我们就是感知当前微服务各种事件的交换机。

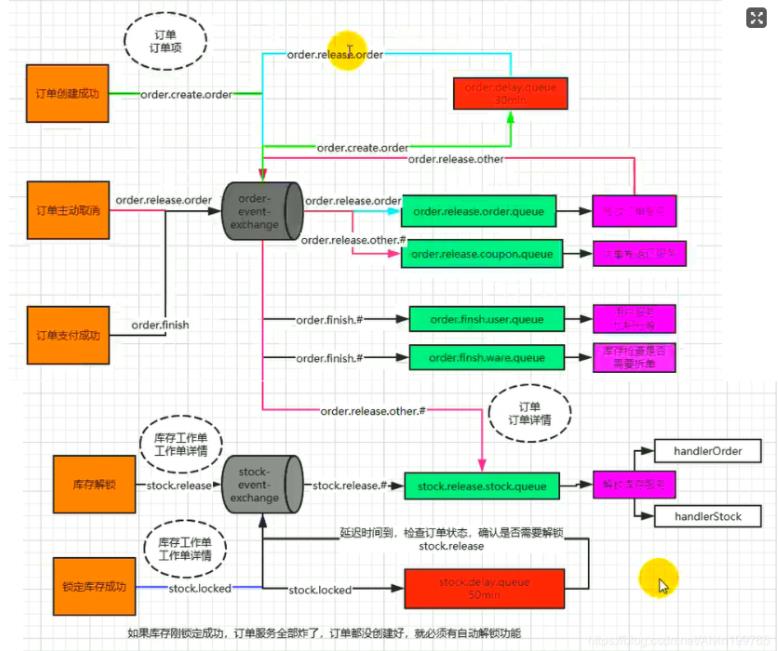
3、进阶设计

首先只要一下订单成功,给Rabbit MQ发消息,然后绑定order.create.order这个路由键,
路由键会把消息路由到order-event-exchange这个交换机,
这个交换机绑定了两个队列,
一个是通过order.create.order连接的order.delay.queue队列,
一个是通过order.relaease.order连接的order.release.order.queue队列,
交换机先按照order.create.order这个路由键找到order.delay.queue队列,
发送者的消息就会沿着这个绑定关系来到order.delay.queue,
里面有以下配置,一开始信进来的存活时间、死信的去向、送死信走的时候用的路由键,
然后这个order.delay.queue队列里面过期的消息就会去找order-event-exchange这个交换机
相当于死信重新交给我们的订单服务的这个事件交换机。
但是此次交出去的这个消息,用的路由键叫order.relaease.order。
所以他就根据这个路由键找到了order.release.order.queue队列。
最终死信就来到了order.release.order.queue这个队列
最后这个消费者,也就是我们的订单释放服务,我们就专门来监听这个order.release.order.queue队列。
这个队列里的内容,都是我们刚创建完订单过了一分钟以后来的。
最终就在这来判断关单。
接下来,就按照这个场景来做延时队列。
八、消息积压、丢失、重复
1、如何处理消息丢失
①消息发送出去,由于网络问题没有抵达服务器
- 做好容错方法(try-catch),发送消息可能会网络失败,失败后要有重试机制,可记录到数据库,采用定期扫描重发的方式
- 做好日志记录,每个消息状态是否都被服务器收到都应该记录,可以创建一张关于消息的数据表,存到数据库里
CREATE TABLE `mq_message` (
`message_id` char(32) NOT NULL,
`content` text,
`to_exchane` varchar(255) DEFAULT NULL,
`routing_key` varchar(255) DEFAULT NULL,
`class_type` varchar(255) DEFAULT NULL,
`message_status` int(1) DEFAULT '0' COMMENT '0-新建 1-已发送 2-错误抵达 3-已抵达',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`message_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
- 做好定期重发,如果消息没有发送成功,定期去数据库扫描未成功的消息进行重发
②消息抵达Broker之后,Broker要将消息写入磁盘(持久化)时宕机。
publisher必须加入确认回调机制,确认成功的消息,修改数据库消息状态。
③自动ACK的状态下。消费者收到消息,但没来得及消息然后宕机
一定开启手动ACK,消费成功再移除,失败或者没来得及处理就noAck并重新入队
2、如何解决消息重复
-
分以下几种情况:
-
消息消费成功,事务已经提交,ack时,机器宕机。导致没有ack成功,Broker的消息重新由unack变为ready,并发送给其他消费
-
消息消费失败,由于重试机制,自动又将消息发送出去
-
成功消费,ack时宕机,消息由unack变为ready,Broker又重新发送
-
-
解决:
- 消费者的业务消费接口应该设计为幂等性的。比如扣库存有工作单的状态
- 使用防重表(redis/mysql),发送消息每一个都有业务的唯一标识,处理过就不用处理
- rabbitMQ的每一个消息都有redelivered字段,可以获取是否是被重新投递过来的,而不是第一次投递过来的
3、如何解决消息积压
-
消费者宕机积压
-
消费者消费能力不足积压
-
发送者发送流量太大
解决:
- 上线更多的消费者,进行正常消费
- 上线专门的队列消费服务,将消息先批量取出来,记录数据库,离线慢慢处理
以上是关于Day428.RabbitMq消息队列--2 -谷粒商城的主要内容,如果未能解决你的问题,请参考以下文章
Day741.Redis消息队列 -Redis 核心技术与实战