Day431.Raft算法实现分布式系统一致性 -谷粒商城
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day431.Raft算法实现分布式系统一致性 -谷粒商城相关的知识,希望对你有一定的参考价值。
Raft 算法实现分布式系统一致性
下面的内容是描述演示动画,
详细地址为:http://thesecretlivesofdata.com/raft/ 跳转
一、简介
我们来看一下 Raft 算法,它帮我们来理解我们这个分布式系统 Consunsus,这个就是一致性。
首先我们来说它说什么是我们分布式系统的一致性。我们以一个例子来作为示范
那假设我们现在有一个单节点的系统,假设就一个节点我们一台机器,我们现在就一台机器

举一个例子,我们现在就是这个节点,

这个机器想要保存一个数据,那我们就给它保存一个数据,比如我们就叫 x 它保存了一个数据。

然后我们有一个客户端(绿的),还有一个数据库(蓝的),客户端可以让数据库保存数据,可以理解成订单服务让数据库保存一条数据,
这就是非常常见的服务调用 mysql 保存数据

那么现在我们就给它发一个8,我们让它保存为8,

现在必须来同意在我们这个单节点系统里边 很容易达成一致性。
也就是说我只要给我们的数据库发送 insert,比如保存一个9。
数据库能给我返回保存。成功了,那肯定就成功了。
所以这块的一致性是很好做的,因为就不需要一致,就它一个系统。
但是如果我们现在变成多个节点的话,我们怎么让多个节点都能保存相同的数据。因为我们后来要做一个集群,你访问任何节点都行。
就是我们说的分布式一致性问题。

这个 R 它是一个协议。
它可以来实现我们这个分布式系统的这个一致性。

我们站在一个上帝角度,我们来看一下它是怎么样工作的来。
我们现在一个节点node,它有三种状态。
这三种状态我们先来记一下。
第一种叫Follower,就是我们的随从。翻译过来,它叫随从。

第二个状态叫Candidate。这就是我们说的候选者,虚线框表示,我就是一个候选人。

然后还有第三个状态叫Leader。如果是实线,那它就是一个领导。

也就是说任何一个节点都有三种状态:随从、候选人、领导。
二、领导选举
那来看我们现在所有的节点,我们现在一号机器,二号机器,三号机器。
假如我们现在启动,我们都是以一个随从状态启动的,所以默认三个节点都是随从状态。

如果我们的这个随从,没有监听到领导者给它发的消息,那它就会变成一个候选人,也就是它觉得没有领导命令它了,那它就是候选人了,它准备当领导了,假设就是虚线这个随从,它没有听到人命令它,它变成一个候选人,接下来看它怎么工作。

首先我们这个候选者,它会给我们所有的其它节点来发送一个投票。

那发完投票以后,接下来其它节点。就会回复它的这个投票,相当于它要让它们投它为领导。

好,那现在它们都投它,它变成领导了

然后,这个节点只要收到我们大多数节点的投票,像现在这样我们有三个节点。算上候选人自己只要有两个节点能同意它成为领导。那它就是领导。
我们管这个过程叫一个 Leader Election,就是领导的选举过程,就是为了保证分布式系统的一致性,我们先来选一个领导,选一个领导以后,接下来怎么办?
三、日志复制
接下来所有对于我们这个系统的改变,现在都得通过我们这个领导来变。所以你想要修改这两个节点数据,你也得给领导发请求才能修改。

现在假设我们有一个客户端,然后它想要让我们这个分布式系统里面保存一个五,所以它会给领导发送一个保存五的命令。假设领导现在记录了一下,我要保存5,set 5

接下来每一个这个改变的这个命令,它们都会被添加成一个节点日志的方式。所以如果我们这个客户端命令它保存5,我们领导先会给它里边放一个日志,叫 set 5。

然后我们这个日志当前是没提交状态。我们现在看 set 5 的颜色,如果是红色,那就是 uncommitted 没提交。所以我们这个领导其实不会改变它这个节点的数据。比如说客户端命令领导保存五,领导只要没提交,那其它的人从领导这读数据,那就不是5。

那接下来领导提交这个日志,它会将自己的日志 set 5 复制给其它的随从节点,相当于随从节点也收到了日志 set 5
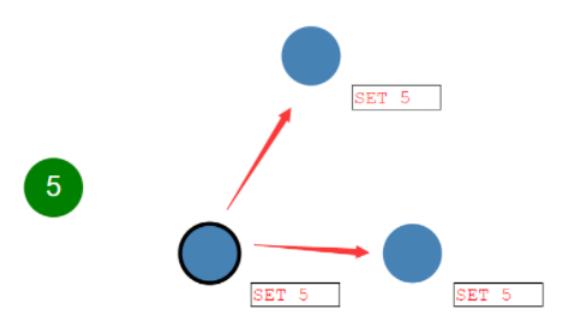
只要随从节点收到了日志并且也写入了,它们就会给领导响应:日志已经写好了,领导就会等待大多数的随同节点,只要把这个日志都写好了。然后领导这一块,只要收到大多数节点说日志写好了。它就提交了,它的 set 5 变成黑色,黑色就代表提交了 committed,

所以我们这个领导节点的这个数据,现在就是一个5。
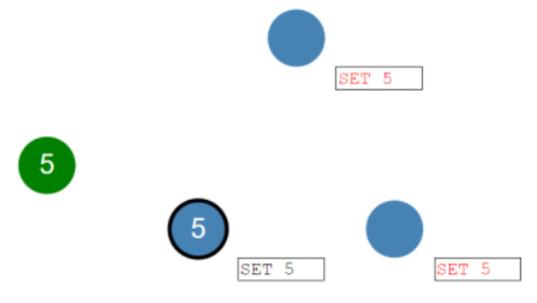
领导只要一变成5,领导就会通知其它随从节点,只要它自己能提交成功,有可能领导自己刚要提交,自己还炸了。
所以它只要自己提交成功了,它就告诉其它随从节点,我已经提交了,你们也可以提交了。那其它的随从节点,现在都提交成了5。
那至此,客户端命令领导保存一个5,它经过这么一个流程以后,5才算保存成功,才会给我们这个客户端响应保存成功。
只要我们客户端收到了保存成功,那一定是我们分布式系统里面这三个节点全都保存了,这就是领导选举的过程。

那么现在的整个分布式系统就变成了一致性的了。所有的三个节点。现在数据保存的都是五。

所以我们把刚才的这个过程又叫做日志复制。因为我只要有啥变动,我都写一个日志,然后再来通知我的随从,把日志记录一下,我提交了,它们的也得都提交。所以我们把这个过程叫日志复制。

四、小总结
现在我们有两个概念,
- 领导选举,在分布式系统里边,我们得选一个领导,
- 日志复制,所有的改变通过领导,领导写一个日志,让随从也跟着写。
只要按照我们的领导选举加上日志复制,我们就可以保证分布式系统的一致性。
五、领导选举的具体过程
首先我们这个 Raft,它有两个time out 超时时间,这个超时时间是来控制我们整个领导选举过程的

第一个超时时间叫选举超时election time out

这个选举超时是指随从想要变成一个候选者的中间的这一段时间,相当于我这个随从想要变候选者了。有一段间隔时间。
这个间隔时间是什么?一般是一百五十毫秒到三百毫秒,我们一般把这个称为节点的自旋时间,就是一百五十毫秒到三百毫秒之间。
我们自己自旋,比如我们一百五十毫秒过后,还没有领导人给我发命令,我觉得我没领导了,那我就可以变成候选者了,我让其它人选我当领导。
所以相当于每一个节点先得有一个自旋时间。
那接下来我们来看,那现在我们三个节点都自旋,由于它们时间是随机的。假设 C 先结束,结束以后,它就变成了候选人,
然后它先给自己投了一票,Vote Count 变为了1

然后再让另外两个节点过来投票

其它节点收到消息了,然后就开始纷纷把票投给 C
这里有个注意点,如果选民接收到投票要求时,它还没有投过票,那它可以给你投票,如果还有另外一个节点跟你一样,也给它发了投票请求,它投给另一个节点了,那它就不会投给你了。
所以每一个节点可能只能投一票,那就是现在大家都投了 C 。只要大多数人都给 C 节点投票成功,那它就能成为领导。

但是这一块还有个注意点,只要A、B投票一成功以后,它们的这个节点会重置它们的选举超时时间。
就是我们看它们头上都有一个自旋,只要它把票投出去了,它就从零开始又自旋。所以只要它这有收到命令或投了票,它就会重新自旋。

所以我们现在看到就是这个样子,a b 都投票给 c 了,c 现在就变成了领导,

只要 c 变成领导,那接下来这个领导就会给它的随从发日志

接下来再注意我们这个消息的发送,它也有一个超时时间叫 heartbeat timeout,就是心跳时间,相当于 c 每隔一段时间就要给它的随从们发一个消息,相当于我们要维护一个心跳连接。所以我们现在看 c 收到投票以后,在发送下一个心跳之前,会把这些信息发给其它节点。

其它节点一收到消息又自动重置它们的选举时间,就是自旋时间。

所以我们接下来整个节点跟其它节点就一直会维护这个心跳。
当然这个心跳肯定不能超过三百毫秒,一超三百毫秒大家都自旋成候选者了,所以心跳时间很短,比如十毫秒、五毫秒或者一百毫秒。
那现在只要节点系统建立好关系,谁是领导,谁是随从,它们之间就会不断的使用心跳机制来维护它们的关联。
然后,这个领导选举会一直维持到有一个随从节点 stop,我们有一个随从节点停止了接收心跳。并且成为了一个候选者。

什么叫停止接受心跳?来看一下,假设我们现在是这种情况情况,心跳维护的很好,

然后领导节点突然停掉了,相当于这个领导节点干活干的很好的,结果机器突然断电了,那怎么办?
领导节点没了以后,A、B这两个随从会重新自旋,看谁快,结果发现这个A 旋的更快,所以它就变成了候选者,它要让别人给它投票。因为 C 给它投不了票,它自己一票加上 B 一票。两票,已经超过大多数节点了,最终 A 就变成了新领导。
以后,所有的改变跟着这个新领导走。新领导的数据其实就是老领导之前的数据。
所以整个数据是一致的。
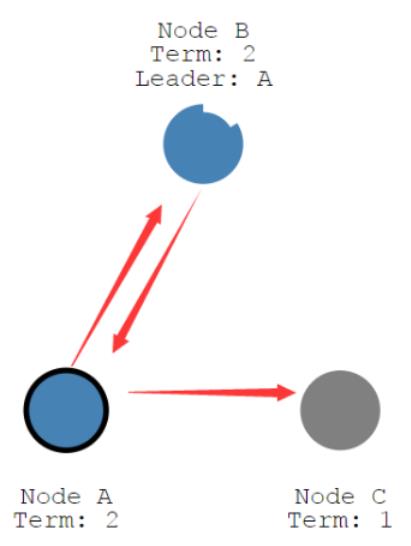
新领导的选出还是需要大多数投票,而且每一轮只能选取出一个领导,这是肯定的。

但是现在如果有两个节点都变成了候选者,那就会出现投票分离的现象,

六、什么是投票分离?
现在大家都在这自旋,没有领导人命令了。B、C 会同时旋到时间

B 和 C 现在两个节点同时旋到时间了,它们是第四轮选举,然后 B 先投自己一票,C 也先投自己一票,然后,它们再给其它三个人发命令投票,相当于它们去拉票了

- 那怎么拉票?
B、C 候选人发出拉票请求之后,A 和 D 这两个节点是随从
B 的这个拉票请求先到达了 A ,所以 A 就把票投给了 B,当 C 过来找 A 拉票的时候,发现它把票已经投给 B 了,所以 C 就没拉到票
而 C 的这个拉票请求则是先到达了 D ,所以 D 就把票投给了 C,当 B 找 D 拉票的时候,发现它把票已经投给 C 了 ,所以 B 也没拉到票
相当于每一次的拉票请求只能先到达一个随从节点。

现在它们都投票了以后,假设票数统计还一样。
B 和 C 节点现在假设都投到了两票,那接下来怎么办?它然后又重新来了一轮自旋。

结果 B 执行的比 C 快

B 就变成了领导,这就是领导选举的具体过程

七、小总结
自旋的过程中,可能会同时有多个节点同时变为候选者,候选者会不断的让选民为其投票,每个选民只能投一个候选人,
候选者们会不断的尝试,假设第一次两个候选人票数一致,也就是都失败了,那么就重新投第二次,再失败了,再重新投,
直到最终有一个候选人的票数多于其他候选人,那么这个人就会成为一个新的领导。
以后就跟着这个领导人来同步它的状态,这就是领导选举
八、日志复制的具体过程
我们假设B 节点它现在是领导,A 和 C 都是随从。
也就是说我们这个领导人,它必须把我们所有的这个改变,我们都得复制给我们这个节点系统的其它节点。

那怎么复制?我们就是使用这个日志的方式,而且这个日志是在每一个心跳的时候发出去的。

假设我们这有一个客户端,让领导变成一个5,那这个五的日志写到这以后,不是说领导收到请求立马发出去。

而是在它下一个心跳该发请求的时候,那就把下一个心跳来发给其它所有的节点。
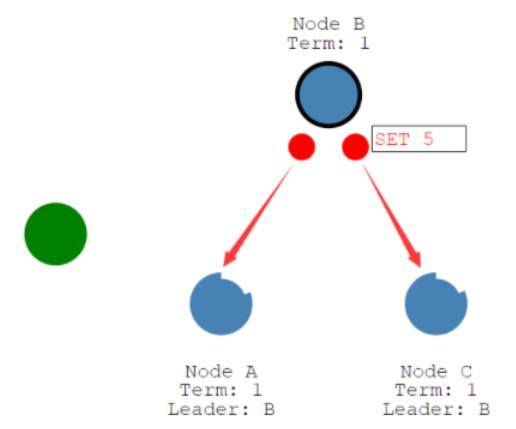
那所有的节点带上我们这个日志。
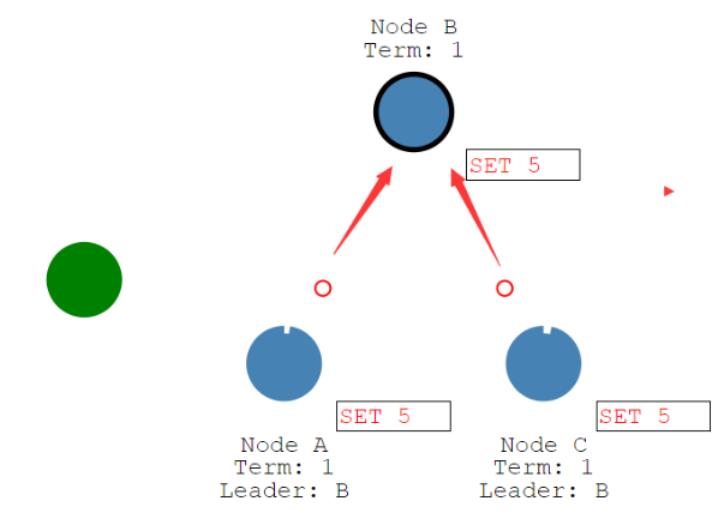
所有的节点现在都同步了,有一个set 5日志,而且大多数节点,只要都给它回复了,那么这个领导就觉得大多数人都跟它,那我们就可以提交了。

那领导在下一个心跳时间,只要一提交,它就会响应给客户端。告诉客户端它已经变成5了,

在下一个心跳时间,告诉其它的系统,再去提交一下。

所以其它的系统,其他系统就提交了,并且会把将提交后的消息重新通知一次 B

假设我们客户端又要让它保存5,那还是与上面一样的流程



所以我们现在整个系统就是我们这么一个流程,我们是通过在心跳时间给它发送日志的时候,我们让其它的节点同步我们这个改变日志。这是我们说的日志复制。
九、Raft 可以保持一致性
首先我们处于这样一个场景,

在面临我们这个网络分区的时候,如果我们先发生了这个网络故障,假设我们现在来分割 A B 和 C D E,那就是 A B 这两个节点。
假设我们把它放到了一个机房,C D E 这几个在一个机房,本来两个机房之间有连线,结果这个线突然断了

现在出现了分区,一出现分区以后,就各自选领导了。那我们上边儿的这一块儿,也得选领导。下边原来 B 是领导则不变,
而上面的 C D E 则重新投了一个领导,就是 C,这个 C 就是上面这个区域的领导,所有上面的数据都要通过它来改变

如果我们现在有两个客户端都想要操作我们这个集群。
我们第一个客户端,假设它命令我们这个 B 节点去来改成3,B 节点让 A 节点同步保存3。

然后,A节点给它回复,由于我们这个 B 节点它之前总共有 A B C D E 五个节点。所以它想要提交它的这个保存三请求,那必须得大多数节点同意才行
但是现在算上 B 它自己,再加上 A 也才两个节点。
所以它做的任何事情都不能收到大多数人的响应。这样的话,我们这个 B 节点的这个三就是一直没有提交的。
不管客户端给它发命令保存什么,它都告诉你没有保存成功,没有提交。

那接下来,假设上面的客户端,让 C 节点保存八,C 节点保存8以后,C 节点又让其它人同步好,因为 C 会收到大多数人的请求,所以最终会保存成功,C 会通知客户端

此时需要注意,B 节点是在·第一轮选举产生的领导。C 是分区之后,上边的这个分区选出来的新领导,
那一恢复分区以后,我们现在有两个领导。然后我们的 B 领导由于它是老领导,他会跟新领导作比较,如果新领导之前领导的随从比他多,那它会退位

然后 A、B因为更换了新领导,那它两个节点中没提交的那些日志,全部都会回滚。
回滚了以后,再来匹配新领导的日志,相当于把新领导的 set 8 拿过来同步,同步以后,我们整个系统都变成了 set 8

所以这就是我们说的,它能容忍我们这个分区错误。整个容忍过程就是这样子的。那现在我们所有的这个日志就都是一个一致性状态。我们整个节点集群现在都是一致的。

十、大总结
这个 Raft 算法有两个核心
-
第一个是
领导选举, -
第二个是
日志复制。
通过它们来保证我们整个集群的一致性,即使有分区错误,我们也能产生一致性。
当然,领导选举以及发送这些日志牵扯到两个时间,一个自旋时间,决定我们要不要变成候选人当领导,另外一个心跳时间,我们在心跳时间把日志发出去,所以这是我们说的 Raft 算法。
通过 Raft,我们更应该深刻的理解什么叫一致性,特别是分布式系统里面的一致性。
一旦网络分区出现错误以后,它又怎么样去来恢复这个一致性。
其实我们这个分布式的事务就是想要这样,A B C 三个节点,系统、订单、库存,以及我们的用户系统。
它倒不是说只保存一个八这个数据这么简单。
它们想要达成一个一致状态,三个都成功了。那就算成功,有一个失败了,都得失败。而且就算不失败,有两个成功了,另一个服务期间宕机了,那也也要保证它只要启动起来了,就得跟其他人保持一致。
要么成功,要么失败。所以这是我们分布式事务要做的事情,在分布式系统里边,保证我们这些数据的一致性
以上是关于Day431.Raft算法实现分布式系统一致性 -谷粒商城的主要内容,如果未能解决你的问题,请参考以下文章