React路由超详解...
Posted 永远没有404
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了React路由超详解...相关的知识,希望对你有一定的参考价值。
欢迎学习交流!!!
持续更新中…
文章目录
1. SPA与路由
SPA是指单页面Web应用(single page web application,即SPA):
- 整个浏览器应用只有一个完整的页面。
- 同时点击页面中的链接不会刷新页面,只会做页面的局部更新。
- 页面中的数据都需要通过ajax请求获取,并在前端异步展现。
- 目前常使用“单页面-多组件”。
什么是路由:
- 一个路由就是一个映射关系(key:value)
- key为路径, value可能是function或component
路由分类:详细点击 前端路由与后端路由
| – | 后端路由 | 前端路由 |
|---|---|---|
| 理解 | value即function, 用来处理客户端提交的请求 | 浏览器端路由,value是component,用于展示页面内容。 |
| 注册路由 | router.get(path, function(req, res)) | <Route path="/test" component=Test> |
| 工作过程 | 当node接收到一个请求时, 根据请求路径找到匹配的路由, 调用路由中的函数来处理请求, 返回响应数据 | 当浏览器的 path 变为 /test 时, 当前路由组件就会变为Test组件 |
react-router-dom
- 是react的一个插件库。
- 专门用来实现一个SPA应用。
- 基于react的项目基本都会用到此库
2. 路由的基本使用
- 明确界面中的导航区和展示区(页面一般分为导航区、头部标题、展示区)
- 导航区的a标签改为Link标签
<Link to="/xxxx">Demo</Link> - 展示区写Route标签进行路径的匹配
<Route path='/xxxx' component=Demo /> <App>的最外侧包裹了一个<BrowserRouter>或<HashRouter>
第3步会将Route标签中写的路径在运行过程中转换成a标签:
代码中:

运行后开发者工具中查看:

3. 普通组件与路由组件的区别
- 路由组件需要依靠路由匹配去渲染页面,一般组件不需要路由匹配
- 一般组件在传值的过程中,传什么收到什么,不传则什么也收不到,但路由组件在渲染的过程中会收到路由器传递的三个重要信息:history、location、match
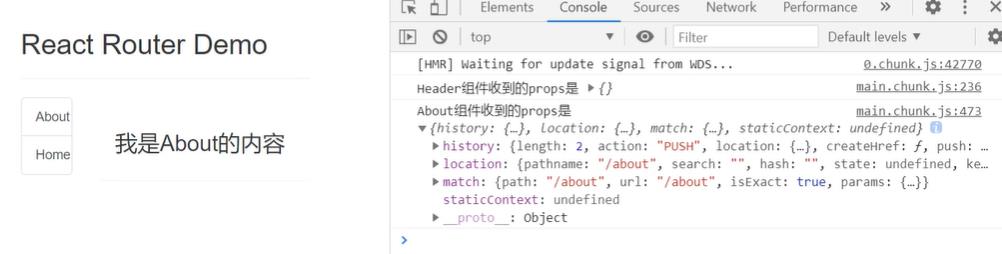
总结:
1、 写法不同:
一般组件:<Demo/>
路由组件:<Route path="/demo" component=Demo />
2、存放位置不同:一般组件放在component文件夹中,路由组件放在pages文件夹中
3、接收到的props不同:
一般组件:写组件标签时传递了什么,就能收到什么
路由组件:接收到三个固定的属性

4. NavLink
4.1 NavLink的使用
Link无法实现点击哪个,哪个组件就实现高亮效果,但是NavLink可以实现,通过activeClassName指定样式名。

4.2 NavLink的封装
定义一个组件<MyNavLink />,<NavLink />组件中公共部分全部封装在其中。因为<MyNavLink />是自己写的标签,所以是一般组件。
在App.js文件中:
<NavLink activeClassName="nl" className="list-group-item" to="/about">About</NavLink>
<NavLink activeClassName="nl" className="list-group-item" to="/home">Home</NavLink>
封装后:
在App.js文件中:
<MyNavLink to="/about">About</MyNavLink>
<MyNavLink to="/home">Home</MyNavLink>
新建一个MyNavLink的文件夹,下面新建index.js文件:
import React, Component from 'react'
import NavLink from 'react-router-dom'
export default class MyNavLink extends Component
render()
// console.log(this.props);
return (
<NavLink activeClassName="nl" className="list-group-item" ...this.props/>
)
其中props本身就是收到的对象,而...this.props即把收到的对象展开,其中包括了标签的属性和标签体的内容,其中,标签体是一种特殊的标签属性,也可以通过this.props去收集,用this.props.children在标签体位置可以获得组件标签标签体内容。
4.3 Switch
Switch可以提高路由匹配效率(单一匹配)。
如果匹配时两个路由相同,则组件内容在页面中均展示。
App.js文件:
<Route path="/about" component=About/>
<Route path="/home" component=Home/>
<Route path="/home" component=Test/>
效果:
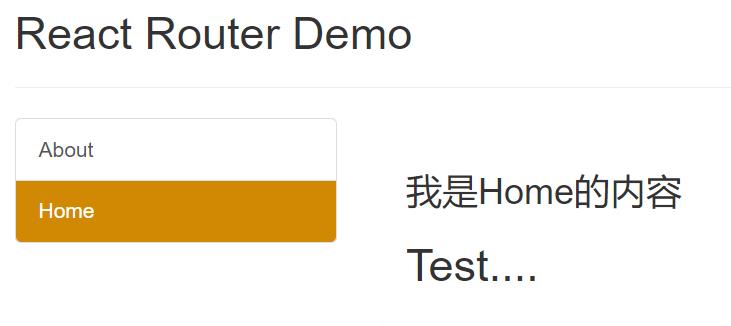
存在问题:
如果某个路由已经匹配上了组件,但还是会继续向下匹配直至结束,因此存在效率低下的问题。
解决:使用
Switch可以实现匹配一个组件后停止匹配
使用方法:用
Switch组件将需要匹配的路由包裹起来
<Switch>
<Route path="/about" component=About/>
<Route path="/home" component=Home/>
<Route path="/home" component=Test/>
</Switch>
注意:当注册路由有多个时再使用
4.4 样式丢失问题
如果在路由匹配时采用二级路由的方式:
<Switch>
<Route path="/nl/about" component=About/>
<Route path="/nl/home" component=Home/>
</Switch>
则在页面刷新后会出现样式丢失问题:
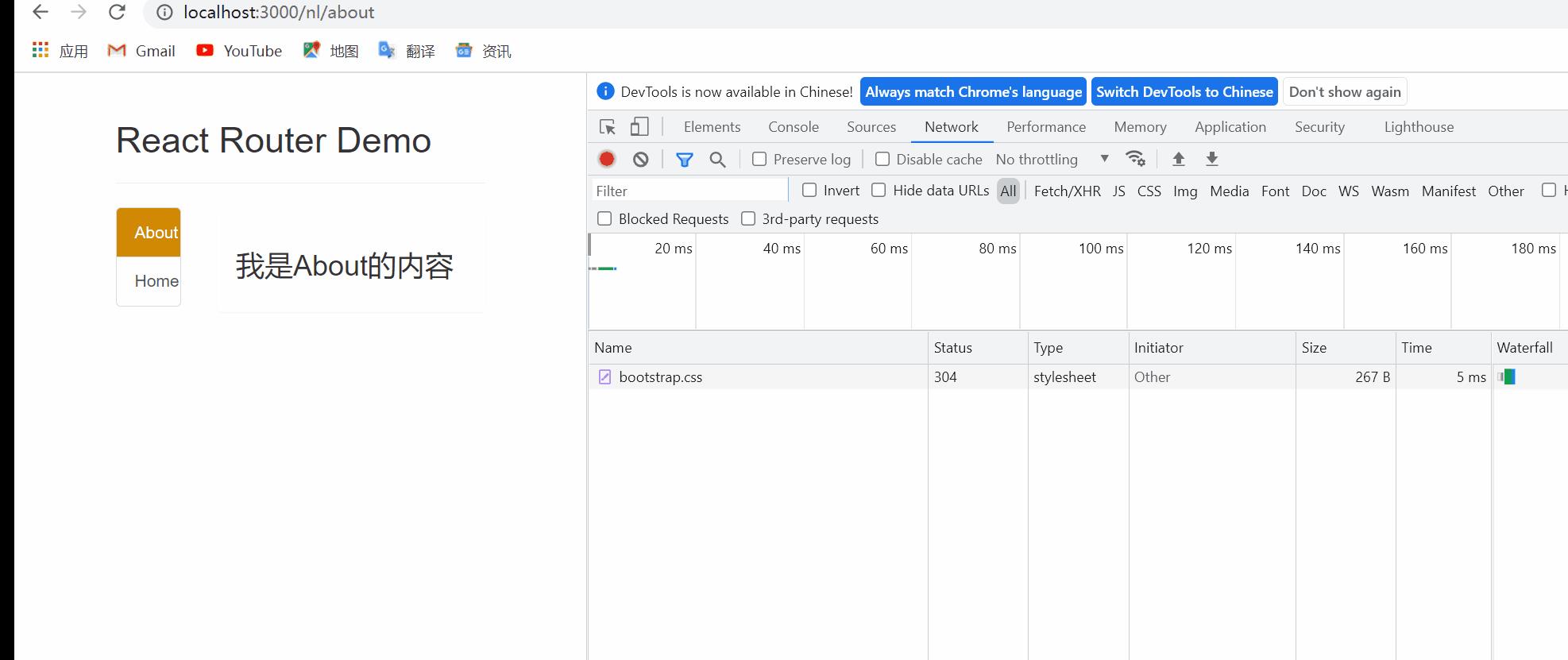
原因:bootstrap的样式文件存放在
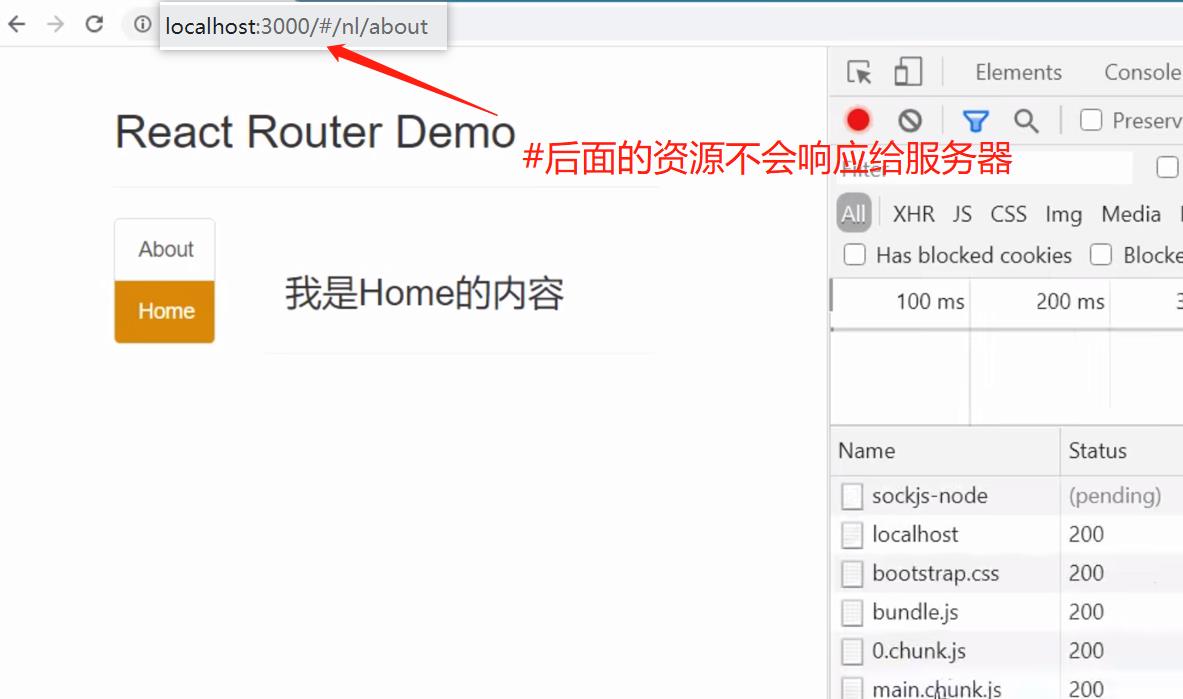
http://localhost:3000/css/bootstrap.css中,而不是http://localhost:3000/nl/css/bootstrap.css中,页面刷新即要与服务器进行请求响应,返回给服务器的地址则无法找到改文件,但是进行组件之间的路由切换并不会向服务器发出请求,所以组件之间的单纯切换不影响样式。
解决方法:
- public–>css–>index.html文件引入样式时由
./(指当前文件夹下的css文件夹中去查找)改成/(指直接请求3000下的css文件夹)。
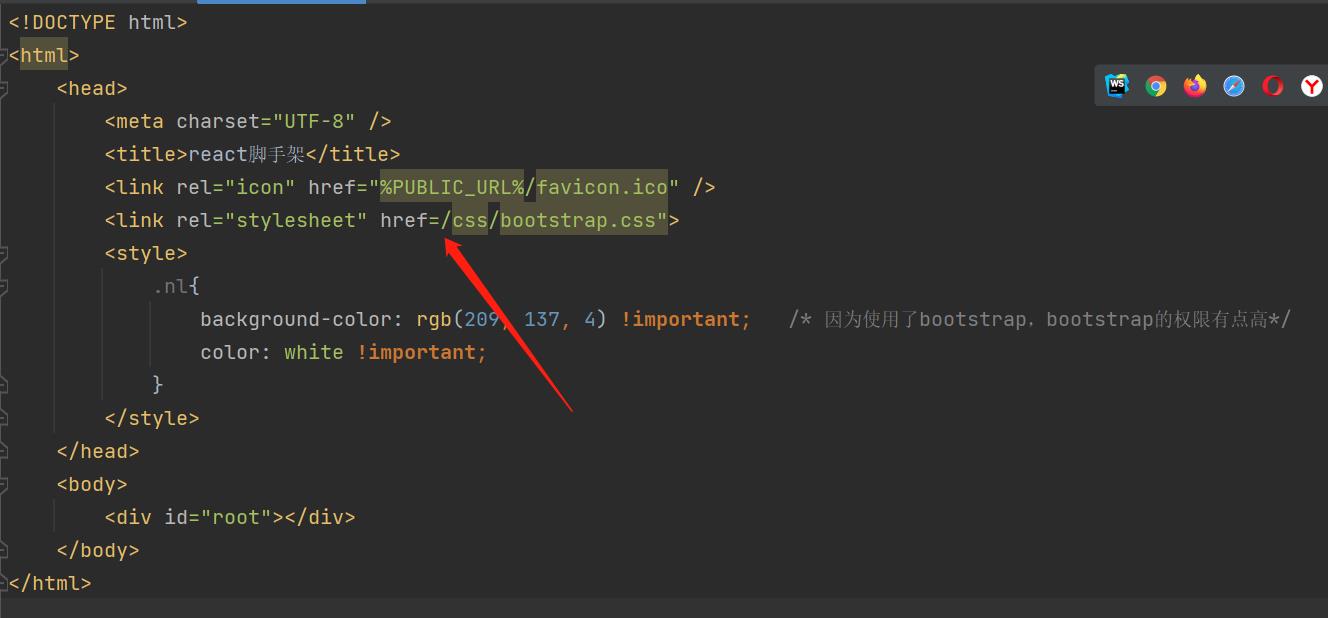
- public–>css–>index.html文件引入样式时不写
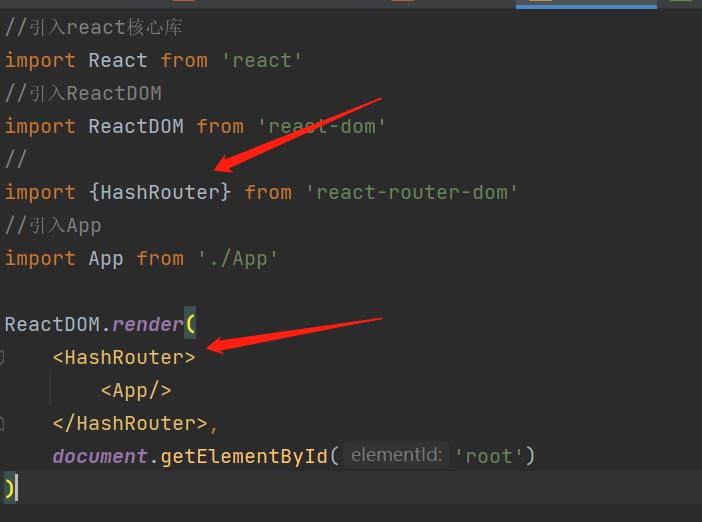
./(指当前文件夹下的css文件夹中去查找),改成%PUBLIC_URL%/(代表public文件夹的绝对路径) - 将index.js文件中的
BrowserRouter改成使用HashRouter(HashRouter中#后的资源默认为前端资源,不会响应给服务器)
4.5 路由的模糊匹配与严格/精准匹配
- 默认使用的是模糊匹配(【输入的路径】必须包含要【匹配的路径】,且顺序要一致)
输入路径:
<MyNavLink to="/about">About</MyNavLink>
<MyNavLink to="/home/a/b">Home</MyNavLink>
注册路由:
<Switch>
<Route path="/about" component=About/>
<Route path="/home" component=Home/>
</Switch>
- 开启严格匹配:
<Route exact=true path="/about" component=About/>
<Route exact path="/about" component=About/>
<Route exact path="/home" component=Home/>
- 严格匹配不要随便开启,需要再开,有些时候开启会导致无法继续匹配二级路由
开启前提:影响页面呈现时再使用
4.6 Redirect的使用
Redirect即重定向,一般写在所有路由注册的最下方,当所有路由都无法匹配时,跳转到Redirect指定的路由(即刚打开页面时的默认匹配路由)
<Switch>
<Route path="/about" component=About/>
<Route path="/home" component=Home/>
<Redirect to="/about"/>
</Switch>
5. 嵌套路由(二级/多级路由)
- 注册子路由时要写上父路由的path值,如在写
/news的路径时必须为/home/news - 路由的匹配是按照注册路由的顺序进行的
例:News—>index.js中:
<ul className="nav nav-tabs">
<li>
<MyNavLink to="/home/news">News</MyNavLink>
</li>
<li>
<MyNavLink to="/home/message">Message</MyNavLink>
</li>
</ul>
/* 注册路由 */
<Switch>
<Route path="/home/news" component=News/>
<Route path="/home/message" component=Message/>
<Redirect to="/home/news"/>
</Switch>
6. 向路由组件传参
1、params参数
- 路由链接(携带参数):
<Link to='/demo/test/tom/18'>详情</Link> - 注册路由(声明接收):
<Route path="/demo/test/:name/:age" component=Test/> - 接收参数:
this.props.match.params
2、search参数
- 路由链接(携带参数):
<Link to='/demo/test?name=tom&age=18'>详情</Link> - 注册路由(无需声明,正常注册即可):
<Route path="/demo/test" component=Test/> - 接收参数:
this.props.location.search - 备注:获取到的search是urlencoded编码字符串,需要借助querystring解析
3、state参数
- 路由链接(携带参数):
<Link to=pathname:'/demo/test',state:name:'tom',age:18>详情</Link> - 注册路由(无需声明,正常注册即可):
<Route path="/demo/test" component=Test/> - 接收参数:
this.props.location.state - 备注:刷新也可以保留住参数
7. 编程式路由导航
借助this.prosp.history对象上的API对操作路由跳转、前进、后退
- this.prosp.history.push()
- this.prosp.history.replace()
- this.prosp.history.goBack()
- this.prosp.history.goForward()
- this.prosp.history.go()
8. BrowserRouter和HashRouter的区别
1、底层原理不一样:
- BrowserRouter使用的是H5的history API,不兼容IE9及以下版本。
- HashRouter使用的是URL的哈希值。
2、path表现形式不一样
- BrowserRouter的路径中没有#,例如:localhost:3000/demo/test
- HashRouter的路径包含#,例如:localhost:3000/#/demo/test
3、刷新后对路由state参数的影响
- BrowserRouter没有任何影响,因为state保存在history对象中。
- HashRouter刷新后会导致路由state参数的丢失!!!
4、备注:HashRouter可以用于解决一些路径错误相关的问题。
以上是关于React路由超详解...的主要内容,如果未能解决你的问题,请参考以下文章