数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析
Posted AOAIYII
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析相关的知识,希望对你有一定的参考价值。
数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析
作者:AOAIYI
作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:数据分析 |
|---|
| 数据分析:某电商优惠卷数据分析 |
| 数据分析:旅游景点销售门票和消费情况分析 |
| 数据分析:消费者数据分析 |
| 数据分析:餐厅订单数据分析 |
| 数据分析:基于随机森林(RFC)对酒店预订分析预测 |
文章目录
一、前言
k-近邻算法是分类数据最简单最有效的算法,k-近邻算法是基于实例的学习,使用算法时我们必须有接近实际数据的训练样本数据。k-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外,由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。k-近邻算法的另一个缺陷是它无法给出任何数据的基础结构信息,因此我们也无法知晓平均实例样本和典型实例样本具有什么特征。
二、数据准备
1.数据准备

2.导入数据
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
data = pd.read_csv("../input/Diabetes/pima-indians-diabetes.csv")
data.head()
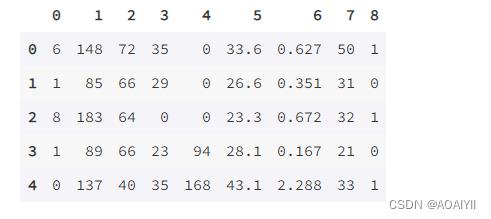
data.shape

三、数据预处理
1.将每一列的标签重新命名
data.columns = ["Pregnancies","Glucose","BloodPressure","SkinThickness","Insulin","BMI","DiabetesPedigreeFunction","Age","Outcome"]
data.head()
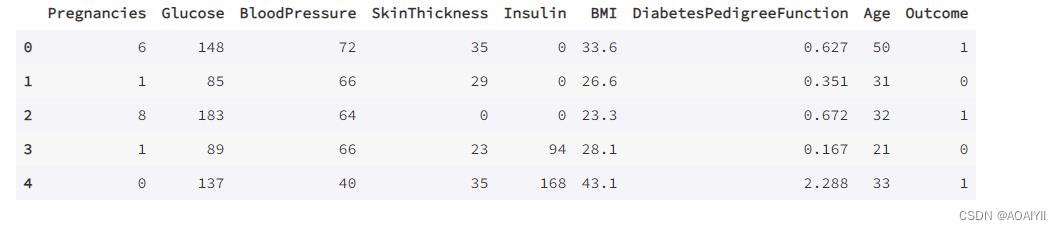
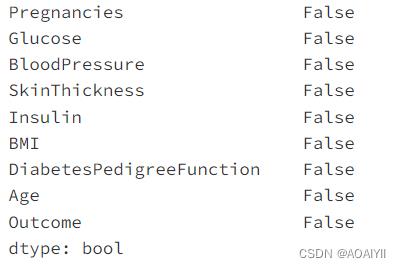
2.查看有没有空值数据
data.isnull().any()
3.观察样本中阳性和阴性的个数
data.groupby("Outcome").size()

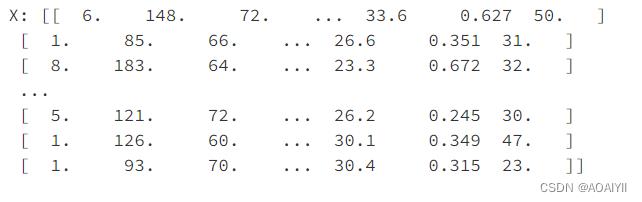
4.分离特征和标签
X=data.iloc[:,0:8]
Y=data.iloc[:,8]
X=np.array(X)
Y=np.array(Y)
print("X:",X)
print('\\n')
print("Y",Y)

5.划分训练集和测试集
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier,RadiusNeighborsClassifier
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2)
四、建立模型
models = []
models.append(("KNN",KNeighborsClassifier(n_neighbors=2)))
models.append(("KNN with weights",KNeighborsClassifier(n_neighbors=2,weights="distance")))
models.append(("Radius Neighbors",RadiusNeighborsClassifier(n_neighbors=2,radius=500.0)))
models

分别训练三个模型,计算平均评分
results = []
for name,model in models:
model.fit(X_train,Y_train)
results.append((name,model.score(X_test,Y_test)))
for i in range(len(results)):
print("name:,score:".format(results[i][0],results[i][1]))

利用交叉验证准确对比算法的精确性
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
results = []
for name,model in models:
Kfold = KFold(n_splits=10)
cv_result = cross_val_score(model,X_train,Y_train,cv=Kfold)
results.append((name,cv_result))
for i in range(len(results)):
print("name:;cross_val_score:".format(results[i][0],results[i][1].mean()))

通过以上结果显示,普通KNN算法的性能更优一些,接下来用普通KNN进行训练
五、模型验证
knn =KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train,Y_train)

train_score = knn.score(X_train,Y_train)
test_score = knn.score(X_test,Y_test)
print("train_score:;test score:".format(train_score,test_score))

以上结果显示表明,训练样本的拟合情况不佳,模型的准确性欠佳
通过画学习率曲线来观察这一结论.
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt
%matplotlib inline
knn = KNeighborsClassifier(n_neighbors=2)
cv= ShuffleSplit(n_splits=10,test_size=0.2,random_state=0)
plt.figure(figsize=(10,6),dpi=200)
plot_learning_curve(knn,"Learning Curve for KNN Diabetes",X,Y,ylim=(0.0,1.01),cv=cv)
plt.show()
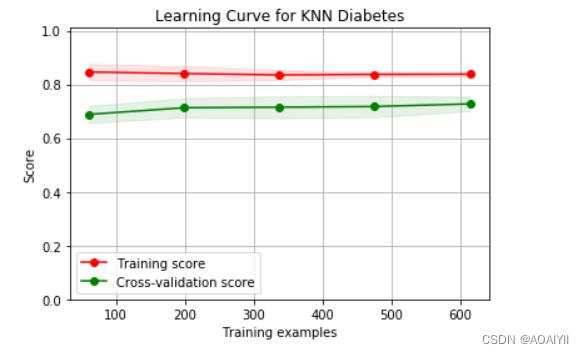
学习曲线分析
从图中可以看出来,训练样本的评分较低,且测试样本与训练样本距离较大,这是典型的欠拟合现象,KNN算法没有更好的措施解决欠拟合的问题,可以尝试用其他的分类器。
总结
k-近邻算法是分类数据最简单最有效的算法,k-近邻算法是基于实例的学习,使用算法时我们必须有接近实际数据的训练样本数据。k-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外,由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。k-近邻算法的另一个缺陷是它无法给出任何数据的基础结构信息,因此我们也无法知晓平均实例样本和典型实例样本具有什么特征。
以上是关于数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析的主要内容,如果未能解决你的问题,请参考以下文章