第四届大数据竞赛-线上选拔赛 -----Hadoop集群配置
Posted 路酴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第四届大数据竞赛-线上选拔赛 -----Hadoop集群配置相关的知识,希望对你有一定的参考价值。
这个比赛我负责集群配置方向
集群配置如下:
| master | slave1 | slave2 | |
| ip地址 | 192.168.1.10 | 192.168.1.11 | 192.168.1.12 |
| 系统 | centos7.2 | centos7.2 | centos7.2 |
一、基础环境
1.修改主机名
master(192.168.1.10)上执行:
hostnamectl set-hostname masterslave1(192.168.1.11)上执行:
hostnamectl set-hostname slave1slave2(192.168.1.12)上执行:
hostnamectl set-hostname slave22.关闭防火墙:
在三台机子上都执行(暂时关闭):
systemctl stop firewalld.servicesystemctl disable firewalld.service(永久关闭)————>看情况使用这个命令
3.配置主机名:
在三台机子上执行:
vi /etc/hosts然后按o换行进入编辑模式输入:
192.168.1.10 master
192.168.1.11 slave1
192.168.1.12 slave2输入完之后摁esc键推出编辑模式,然后摁shift+;键输入wq推出即可。
如下图所示:

4.将时区更改为东八区(中国北京):
在三台机子上执行:
vi /etc/profile在文件末尾输入:
TZ='Asia/Shanghai'; export TZ退出/etc/profile文件后:
source /etc/profile出现如下信息即可:

5.安装并配置ntp服务:
在三台机子上执行:
yum -y install ntp在master上执行:
vi /etc/ntp.conf在文件中注释所有server开头的文件:

在文件末端加上如下代码:
server 127.127.1.0
fudge 127.127.1.0 stratum 10
然后退出配置文件重启ntp服务:
systemctl restart ntpd在slave1、slave2上执行:
ntpdate master出现如下则成功

6.创建一个定时任务(从节点在早十-晚五时间段内每隔半个小时同步一次主节点时间)
在slave1、slave2上执行:
写定时任务:
crontab -e在文件中输入:
*/30 10-17 * * * /usr/sbin/ntpdate master7.远程免密登入
在master上执行:
ssh slave1输入yes,然后输入slave1密码。 这一步是要生成.ssh/目录
cd /~/.ssh/ssh-keygen -t rsa然后摁三次回车
然后在依次输入命令:
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave28.安装jdk软件包
在master上执行:
1.创建文件夹:
mkdir -p /usr/java2.解压压缩包(注意压缩包所处的路径)
tar -zxvf /opt/software/jdk-8u141-linux-x64.tar.gz -C /usr/java/
3.修改/etc/profile文件:
vi /etc/profile在文件末尾追加上
export JAVA_HOME=/usr/java/jdk1.8.0_141
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
退出文件后:
source /etc/profile
然后分发文件到slave1,slave2机子上:
scp -r /usr/java/ slave1:/usr/
scp -r /usr/java/ slave2:/usr/
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/
在slave1、slave2上执行:
source /etc/profile
二、Hadoop集群安装
在master上操作:
1.安装Hadoop安装包
mkdir -p /usr/hadoop
tar -zxvf /opt/software/hadoop-2.7.2.tar.gz -C /usr/hadoop/
2.配置hadoop运行环境
vi /etc/profile
在文件末端输入如下内容:
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.2/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
退出文件后:
source /etc/profile3.配置全局参数:
cd /usr/hadoop/hadoop-2.7.2/etc/hadoop/
进入到目录后:
vi hadoop-env.sh
找到如下图:

修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_141
然后修改全局文件:
vi core-site.xml
然后在<configuration>和</configuration>中间加入以下配置文件:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/Hadoop_Data/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
4.配置hdfs参数:
在master上执行:
vi hdfs-site.xml
然后在<configuration>和</configuration>中间加入以下配置文件:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/Hadoop_Data/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/Hadoop_Data/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>5.配置mapreduce参数:
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
然后在<configuration>和</configuration>中间加入以下配置文件:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>6.配置yarn框架运行环境:
vi yarn-env.sh
然后在文件末尾输入:
export JAVA_HOME=/usr/java/jdk1.8.0_141vi yarn-site.xml
然后在<configuration>和</configuration>中间加入以下配置文件:
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.shuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>6.指定主节点和从节点,写入对应文件
在master上执行:
vi master
在文件写入:
master退出master文件后:
vi slave
将文件写成为:
Slave1
Slave2 首先要分发文件:
scp -r /usr/hadoop slave1:/usr/
scp -r /usr/hadoop slave2:/usr/
scp -r /etc/profile slave1:/etc
scp -r /etc/profile slave2:/etc在slave1、slave2上执行:
source /etc/profile
在master上执行:
hadoop namenode -format
出现0则表述初始化成功,如下图:
在master上启动集群:
start-all.sh 出现如下进程则显示正确:
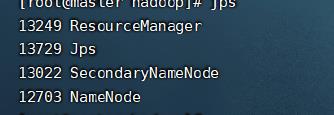
三、Zookeeper 搭建
在master上执行:
1.安装 Zookeeper 软件包
mkdir -p /usr/zookeeper
tar -zxvf zookeeper-3.4.9.tar.gz -C /usr/zookeeper/
cd /usr/zookeeper/zookeeper-3.4.9/conf2.修改配置文件
在master上执行:
vi /etc/profile
在文件末端追加:
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.9/
export PATH=$PATH:$ZOOKEEPER_HOME/bin
退出文件后:
source /etc/profile
修改zookeeper配置文件:
cp zoo_sample.cfg zoo.cfg
mkdir /usr/zookeeper/zookeeper-3.4.9/zkdata
mkdir /usr/zookeeper/zookeeper-3.4.9/zkdatalog
vi zoo.cfg然后找到如图所示的位置:

修改成为如下图:

代码如下:
dataDir=/usr/zookeeper/zookeeper-3.4.9/zkdata
dataLogDir=/usr/zookeeper/zookeeper-3.4.9/zkdatalog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
保存退出文件后;
cd /usr/zookeeper/zookeeper-3.4.9/zkdata
分发文件:
scp -r /usr/zookeeper slave1:/usr/
scp -r /usr/zookeeper slave2:/usr/
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/
echo 1 >> myid在slave1上执行:
source /etc/profile
echo 2 >> /usr/zookeeper/zookeeper-3.4.9/zkdata/myid在slave2上执行:
source /etc/profile
echo 3 >> /usr/zookeeper/zookeeper-3.4.9/zkdata/myid在三台机子上执行
zkServer.sh start
zookeeper关系如下图所示:
| master | slave1 | slave2 |
| follower | leader | follower |
具体情况如下图:

以上是关于第四届大数据竞赛-线上选拔赛 -----Hadoop集群配置的主要内容,如果未能解决你的问题,请参考以下文章