交互式学习图神经网络的网站
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了交互式学习图神经网络的网站相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :知乎@聚丙烯酰胺
https://zhuanlan.zhihu.com/p/434132221
推荐一个交互式学习GNN的免费网站!https://distill.pub/2021/gnn-intro/
在这篇博客中,很多图都是交互图,可以由读者自行操作演示。例如下图中GNN层数,维度等等的设置均可以自行选择,展示也会随之变化,非常形象~
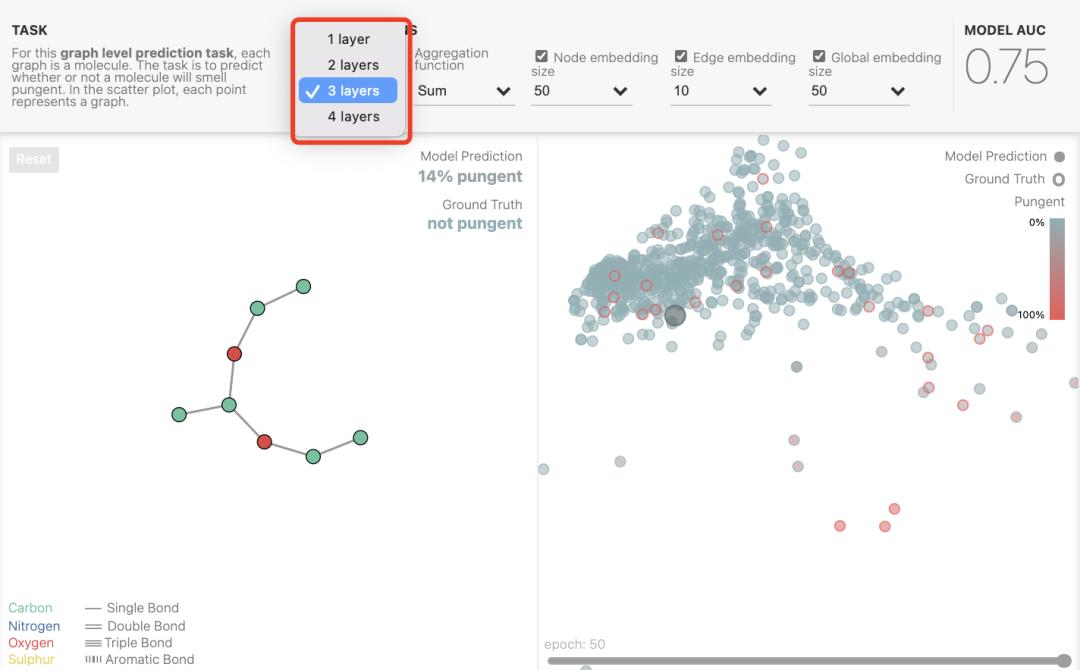
下面这幅图是本文的开篇之图:
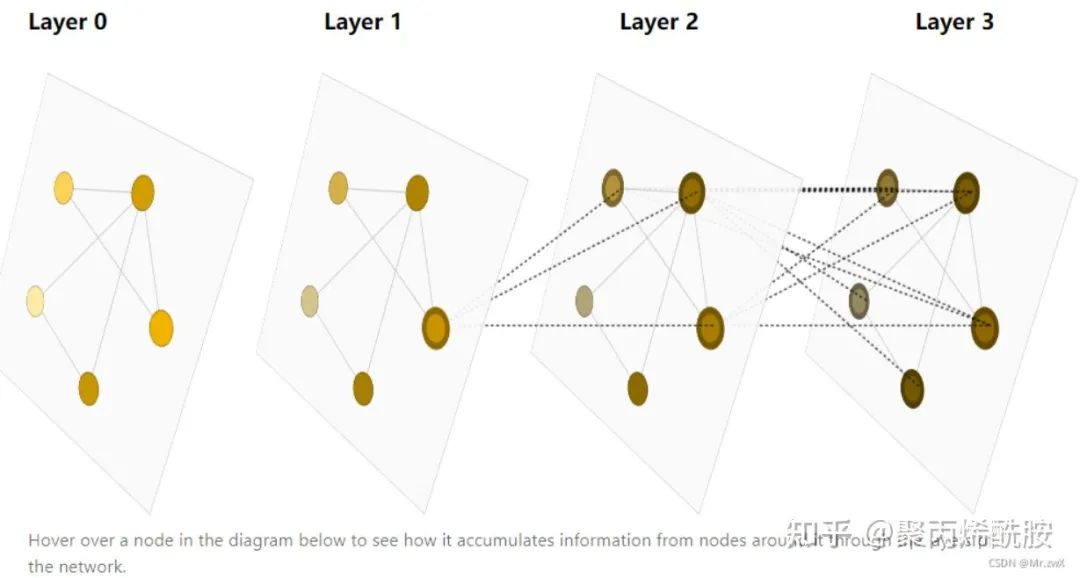 在上图
中,每一层都是一层网络,每一层的节点都受到下一层中自身节点和邻居节点的影响。
如果网络比较深,是可以处理到一幅图中较大范围的节点。
在上图
中,每一层都是一层网络,每一层的节点都受到下一层中自身节点和邻居节点的影响。
如果网络比较深,是可以处理到一幅图中较大范围的节点。
下文是结合上述博客介绍和李沐老师的论文精读总结出来的。第一次看distill的文章,让我实在是很惊喜,李沐老师将在最后的评价部分评价distill的文章。个人认为【GCN作为子图函数近似】这一部分讲到了GNN的核心思想,至少这一部分是我对GNN的理解。
李沐老师论文精读视频:
1 前言
图神经网络在应用上还只是起步阶段,应用领域有药物发现、物理模拟、虚假新闻检测、车流量预测、推荐系统等。这篇文章是探索和解释现代图神经网络,第一部分是什么样的数据能表示成一张图,第二部分是图和别的数据有什么不同,第三部分是构建GNN的模块,第四部分是搭建一个GNN的playground(说明作者非常用心!是花了很多心思在上面,值得我们去玩玩)。
2 什么是图?
首先建立一个图。图表示的是一系列实体(节点)之间的关系(边)。
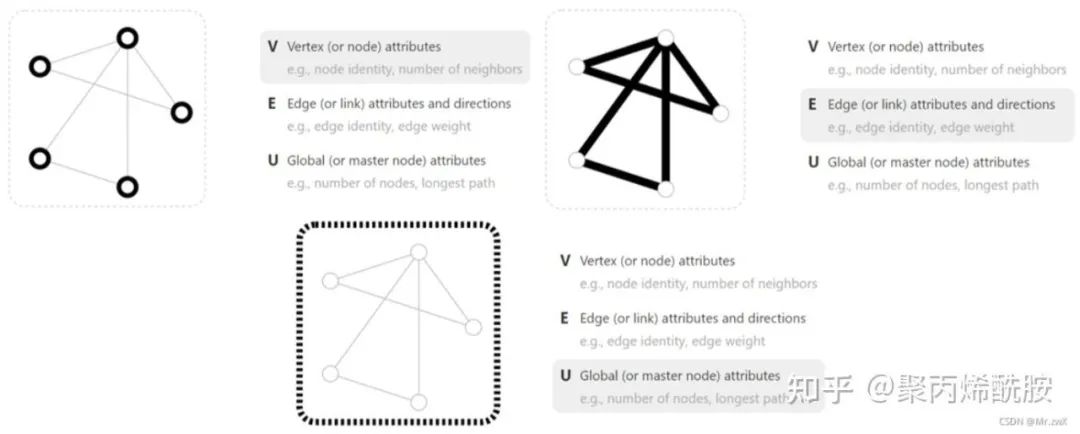
V:节点信息(节点标识、节点邻居数)
E:节点信息(边标识、边权重)
U:全局信息(节点数、最长路径)
(这篇博客的重点是如上的交互图,文字更多的是描述交互图想表达的意思)
为了深入表示每个节点、边和整个图,我们可以用如下的存储方式:
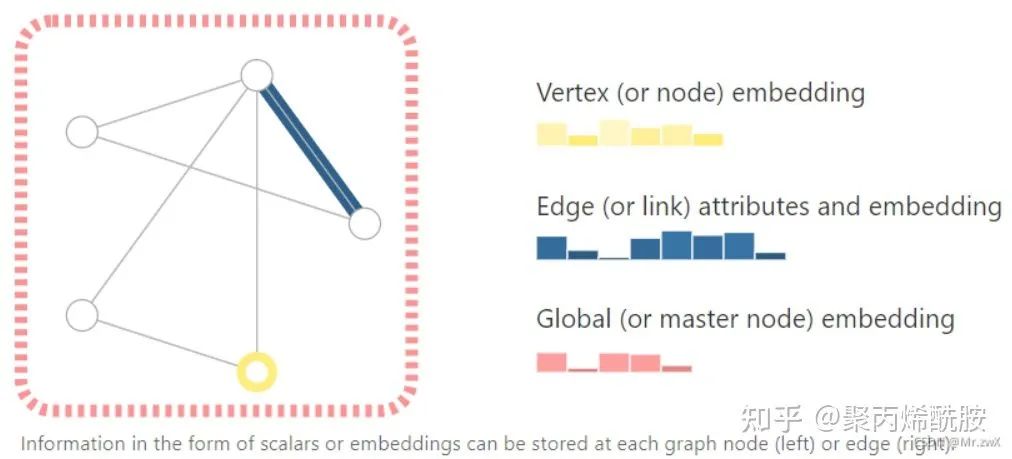 把节点信息、边信息和全局信息做embedding,通俗地说就是把这些信息存储为向量的形式。
所以
图神经的核心步骤就是,怎么样把我们想要的信息表示成向量,以及向量是否能通过数据学习到。
把节点信息、边信息和全局信息做embedding,通俗地说就是把这些信息存储为向量的形式。
所以
图神经的核心步骤就是,怎么样把我们想要的信息表示成向量,以及向量是否能通过数据学习到。
我们把图的边分为无向边和有向边,比如朋友关系无方向,而b站上的关注可能是单向的。
以下是几种图表示的例子:
images as graphs(将图片表示为图)
通常把图片表示为三维tensor,如224x224x3(学过CNN的同学就知道这里的三通道是指RGB三种颜色)。实际上我们可以把每个像素作为一个点,存在邻接关系则形成一条边。
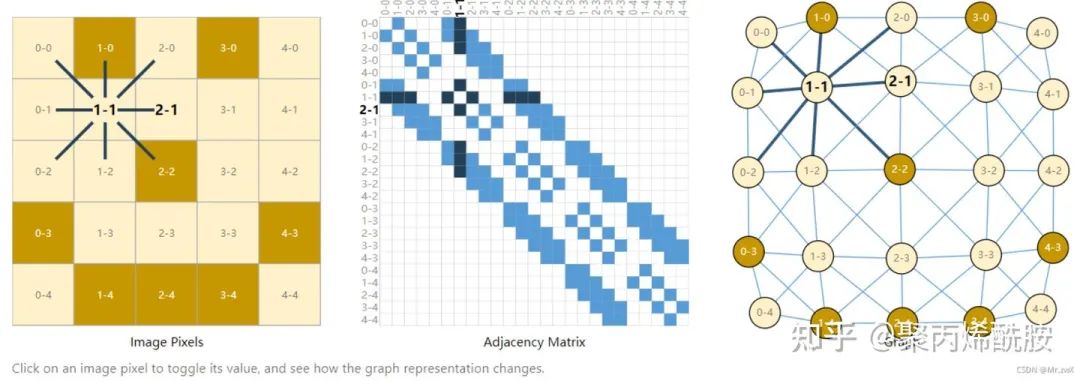
中间的就是邻接矩阵,相邻则是1,不相邻则是0,一般会是非常大的稀疏矩阵。
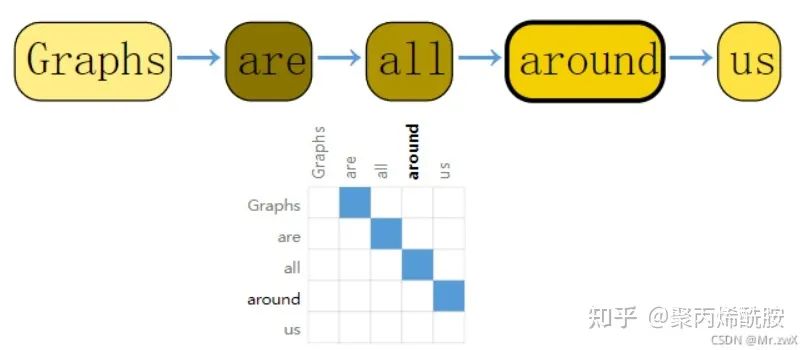
text as graphs(将文本表示为图)
文本是一个序列,把词表示为顶点,词与词存在有向边。
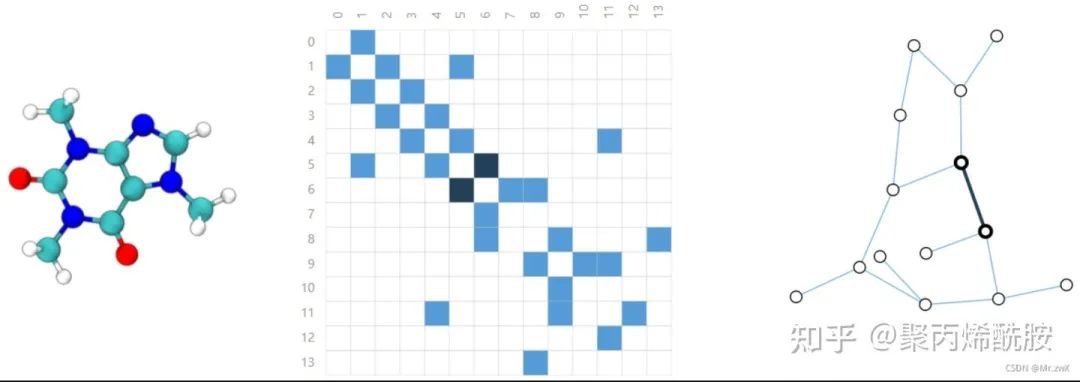
Molecules as graphs(将分子结构图表示为图)
上面其实是图能在CV和NLP中做的事儿,实际上不局限于此,图可以应用在生活的各个领域。

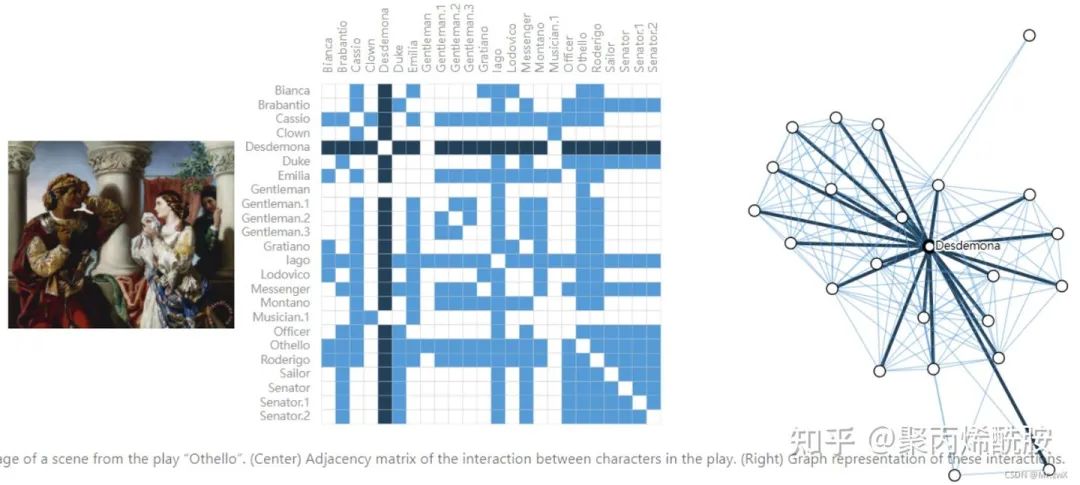
Social networks as graphs(将社交网络表示为图)
Othello:奥赛德剧中出现人物的社交网络情况,有边代表两个人同时出现过。
Karate:空手道俱乐部数据集,大概意思是存在两个老师带队的团体。
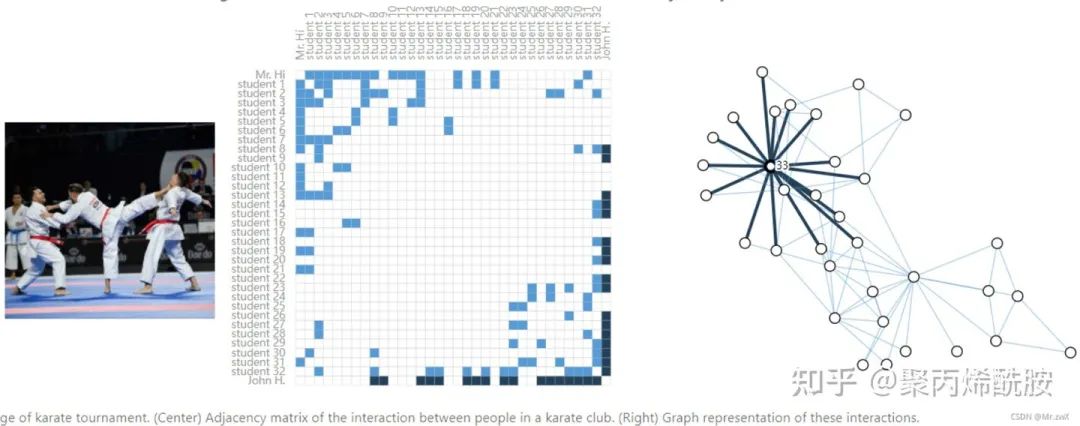
Citation networks as graph(将引用网络表示为图)
文章之间的引用,会生成一条边,但是往往都是有向边,因为是新文章引用旧文章,双向引用就不太现实了。
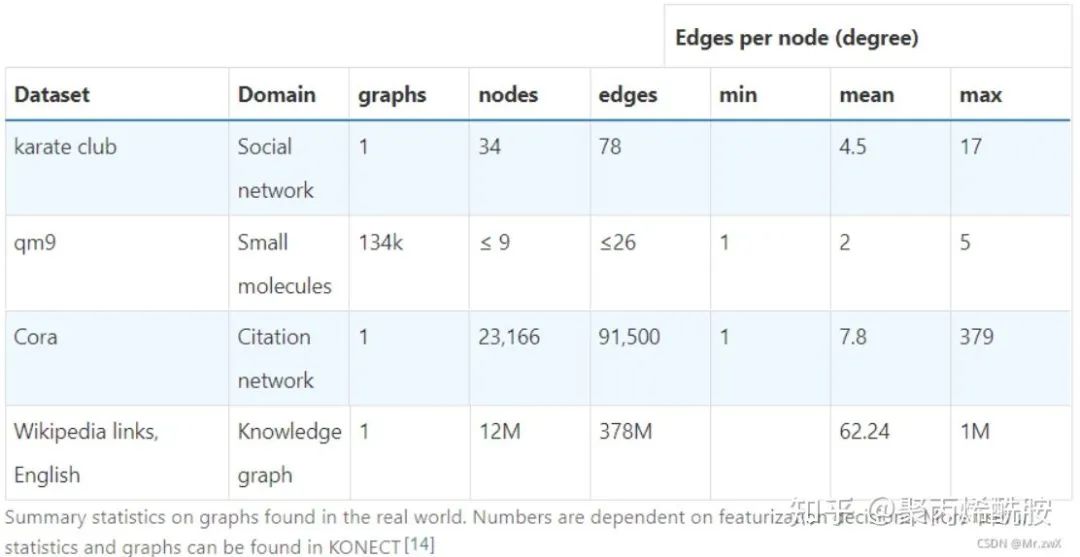
下面是真实世界的数据集,需要注意的是:qm9数据集中包含134k张小图,每个图仅仅9个节点以内,Cora数据集为有向图,Wikipedia links节点数和边数非常大,最大的节点指向了100万个文章(网页),可能是一张大的索引页。
图级别(Graph-level task)
给定一张图,对该图进行分类。
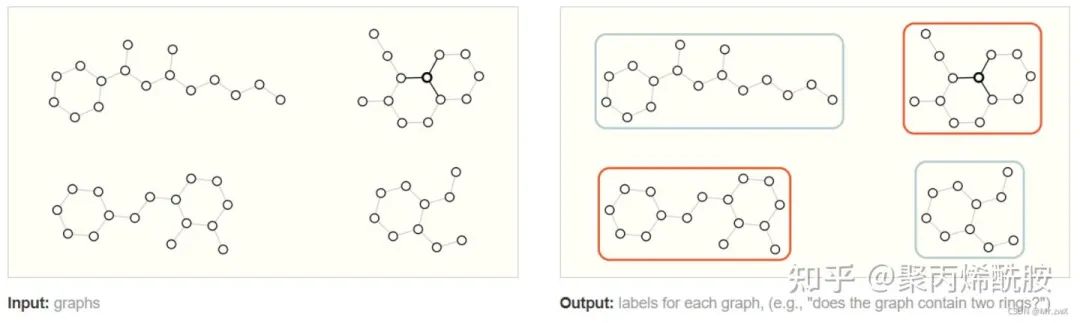
如上图,预测出哪些分子是具有两个环的。这个例子比较简单,可以用图的遍历来完成,当图非常复杂的时候,图神经网络可以发挥巨大作用。
节点级别(Node-level task)
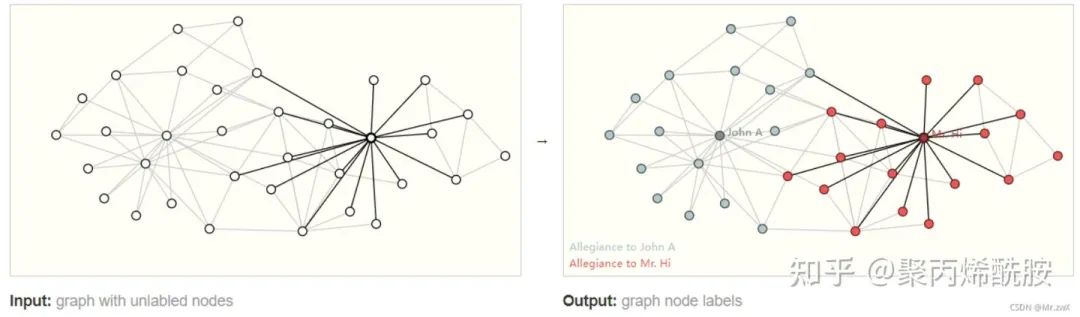
上图是空手道俱乐部数据集,将学员分类到两个老师的队伍中。
边级别(Edge-level task)
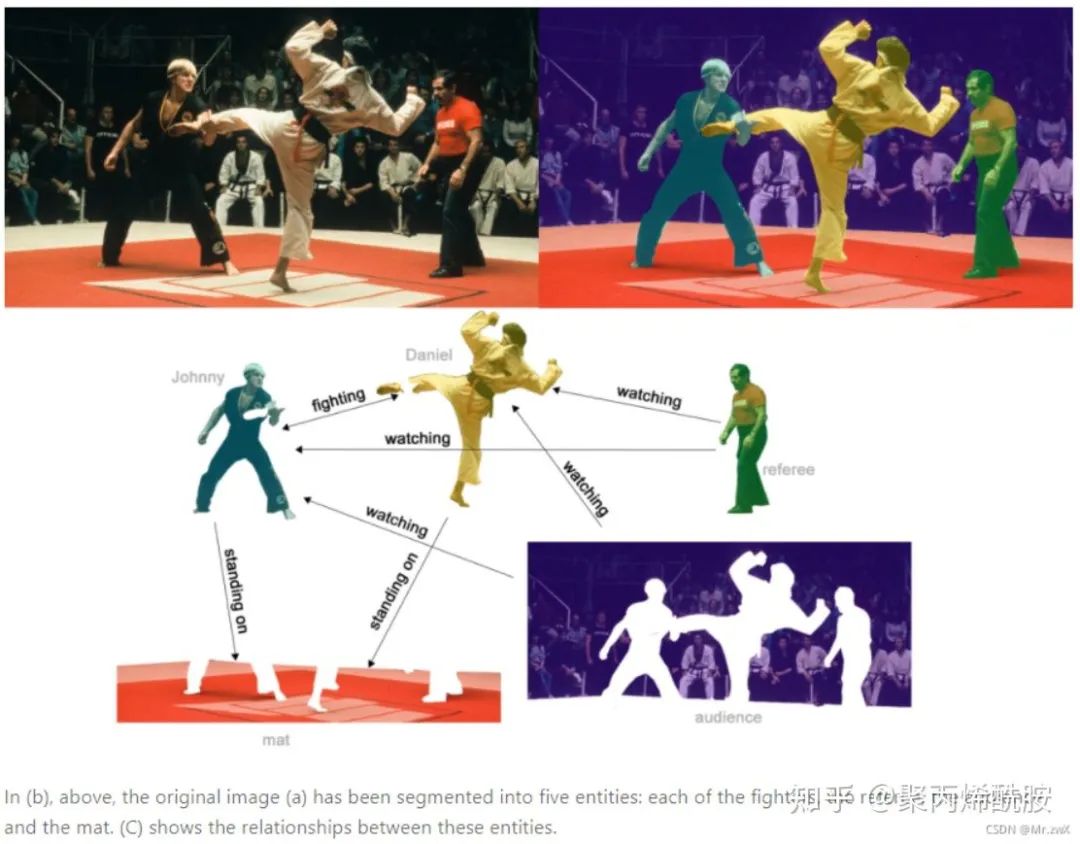
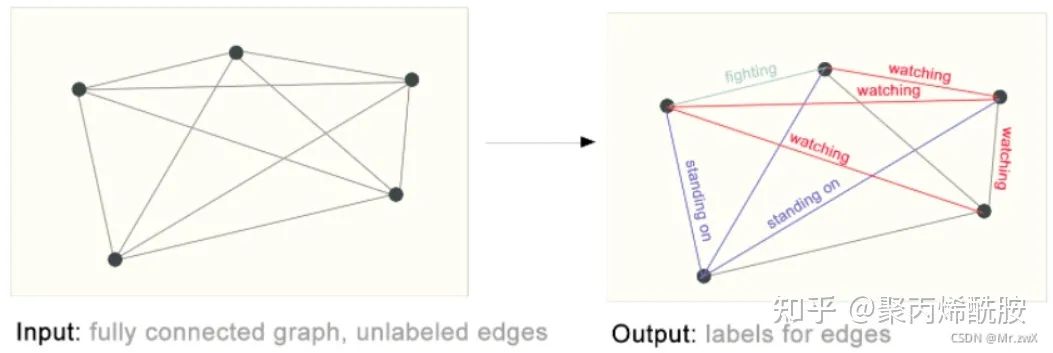
边的预测(链路预测)的例子是通过语义分割把人物、背景拿出来,然后分析实体间的关系(属性)。比如黄衣服的人在踢绿衣服的人,他们都站在地毯上。
需要的是节点、边、全局信息、连接性四种类型的信息来做预测。
连接性是用邻接矩阵来存储,如果图非常大,比如Wikipedia,则存储不下来。由于是邻接矩阵很稀疏,所以用稀疏矩阵来存储会更好,而稀疏矩阵在GPU上训练一直是个技术难题。
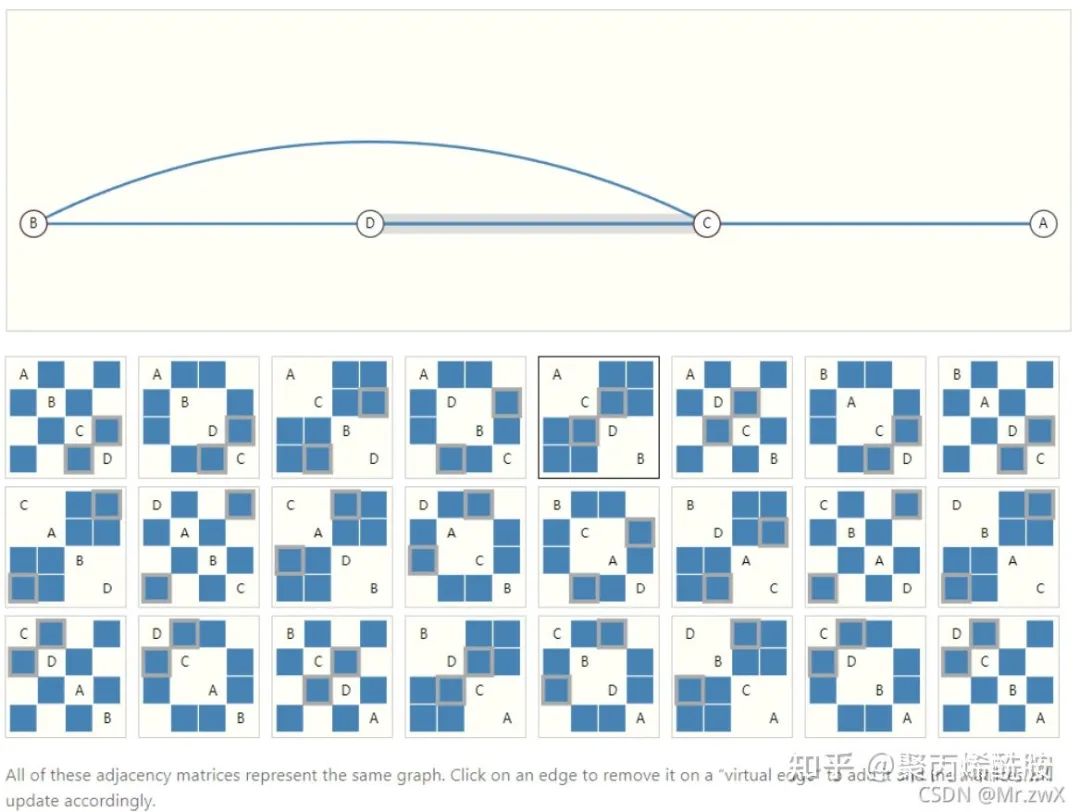
邻接矩阵任意交换行列,会导致邻接矩阵改变,他们其实节点关系不变,文章给出了下面这个例子(动态图)表示不同样子的邻接矩阵都形成了连接性相同的图,而他们都是异构的。
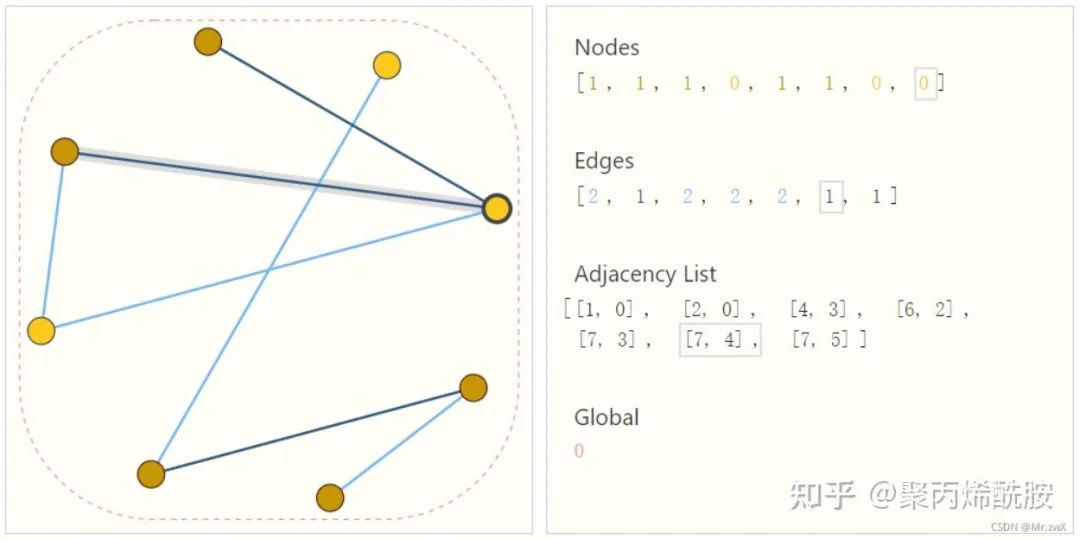
上图中的节点、边和全局信息都可以用向量表示,而不一定只是标量。这个adjacency list能够用节点id把边的连接关系表示出来。
3 图神经网络
介绍完图的背景后,现在开始介绍图神经网络(GNNs)。
什么是GNNs?是对图上所有属性进行可以优化的变换,变换能保持图的对称信息(节点重新排序后,结果不变)。message passing neural network是一种GNNs的框架,当然GNN是可以用别的方式构建。
GNNs是“graph-in, graph-out”(即进出模型都是graph的数据结构),他会对节点、边的信息进行变换,但是图连接性是不变的。
首先,对节点向量、边向量、全局向量分别构建一个MLP(多层感知机),MLP的输入输出的大小相同。
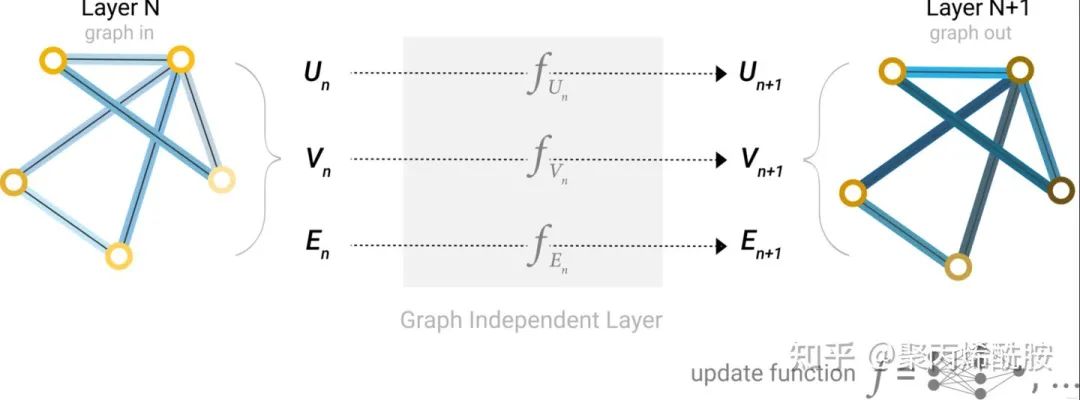
三个MLP组成GNN的一层,一个图经过MLP后仍然是一个图。对于顶点、边、全局向量分别找到对应的MLP,作为其更新函数(update function)。可以看到,输出后图的属性变化了,但是图的结构没有改变,符合我们的需求。MLP对每个向量独自作用,不会影响的连接性。堆叠了多层上述的模型后得到了GNN,现在来到最后一层,对节点进行预测。
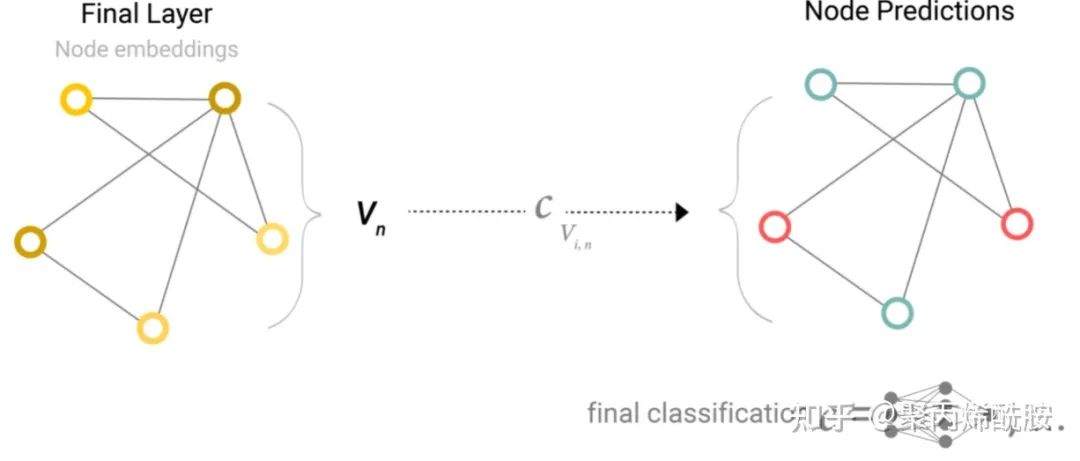
上图可以看到,经过GNN的最后一层,得到的也是一个图,然后在图后面接一个全连接层(分类的话神经元数量则是类别数,再套一个softmax,回归的话神经元数量则是1),所有节点共享一个全连接层。
考虑另一种情况,如果说某个节点是没有自己的属性(向量)的,应该怎么做?这里介绍到pooling的方法。
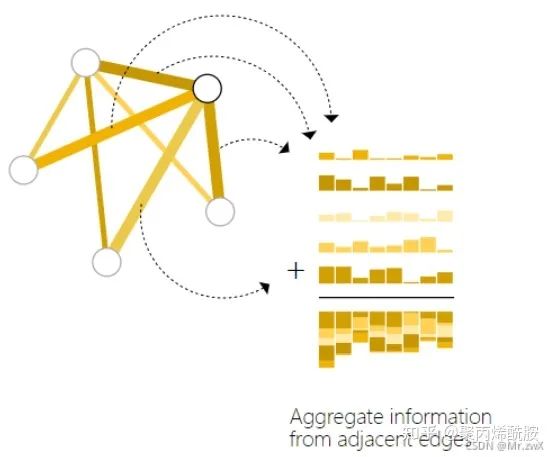
做法就是把节点相连的边向量拿出来,全局向量拿出来,然后将这些向量相加求和,最后经过一个节点共享的输出层得到节点预测结果。
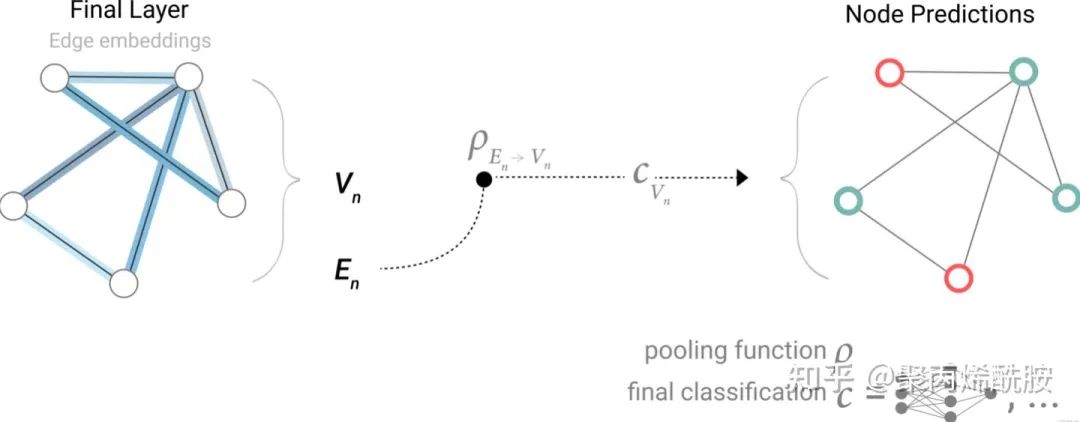
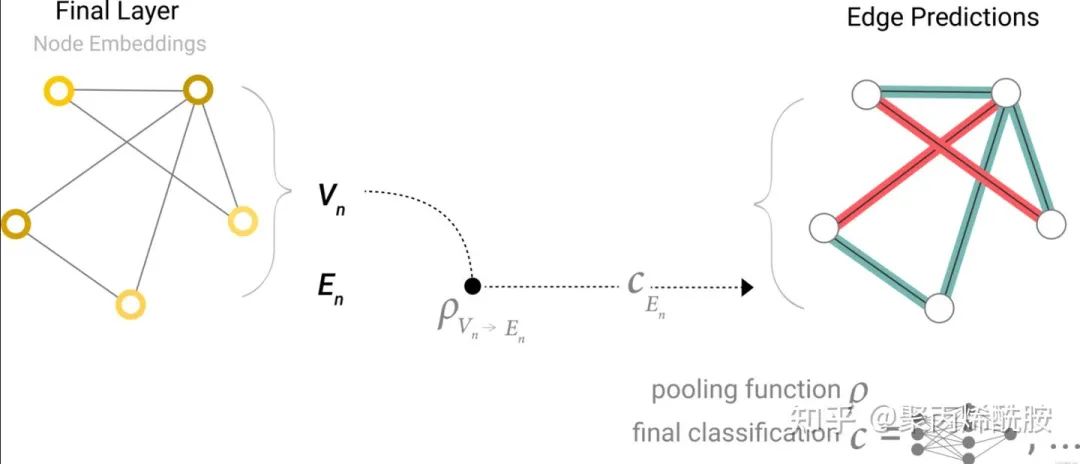
那如果没有全局向量,只有节点向量呢?就把全部的节点向量汇聚起来,经过最后的输出层得到全局的输出。
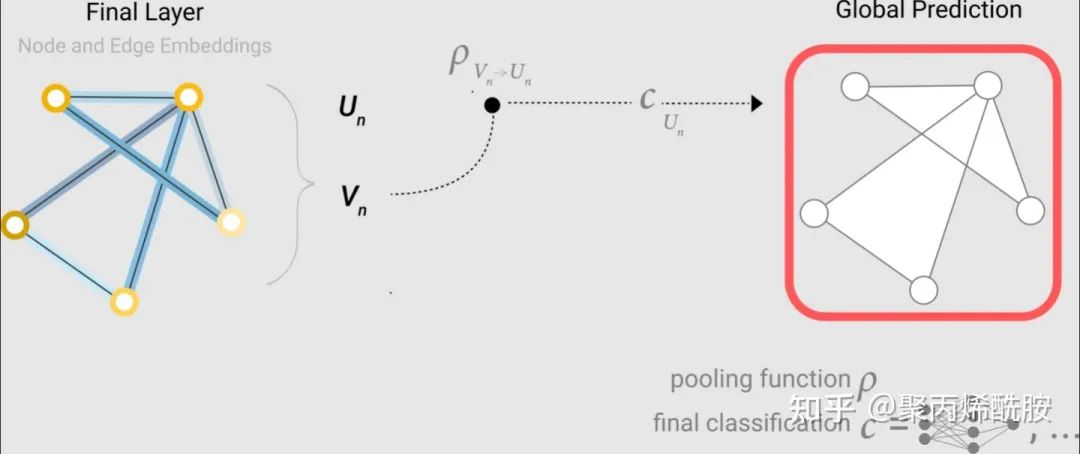
所以,不管缺哪类属性,我们都可以通过汇聚这个操作,得到最终的输出值。下图则是GNN流程的描述。
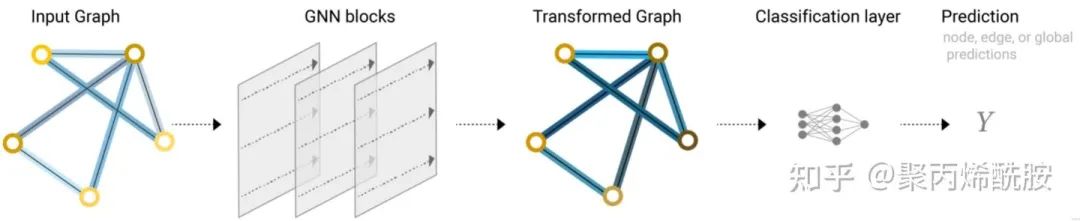
如上模型的局限性是很明显的,并没有用到图的结构,仅仅是点、边向量分别做MLP的过程。
信息传递(passing message between parts of the graph)
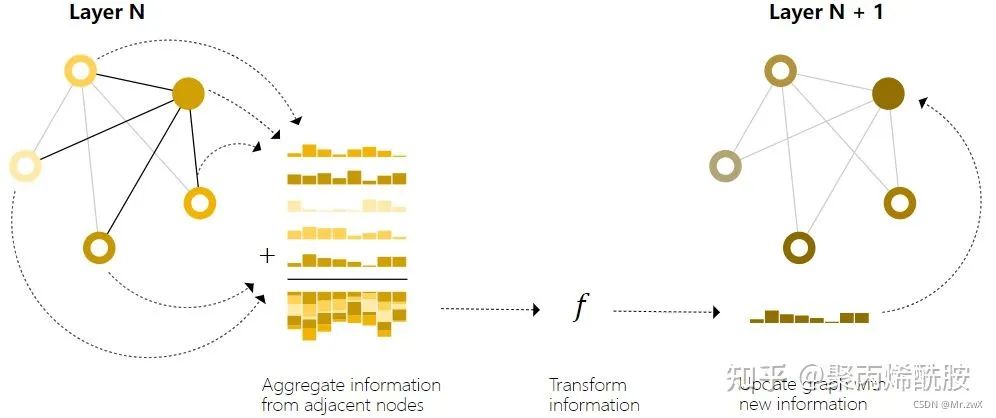
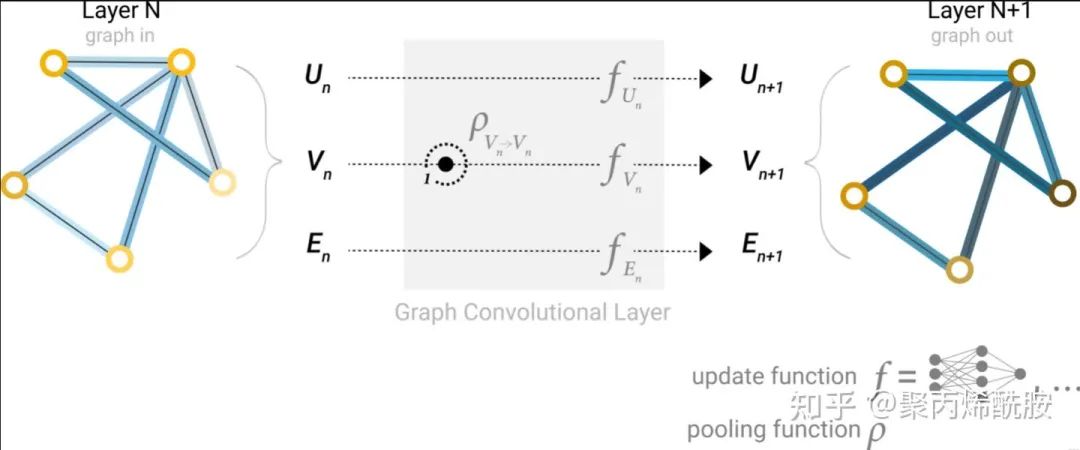
在更新某个节点的向量时,会将自己的向量和邻居节点的向量进行聚合操作,然后再传入MLP更新节点的向量。作者说这个过程和标准卷积相似,但其实不完全是。下图则是GCN的架构涉及,通过聚集邻居节点来更新节点的表达。
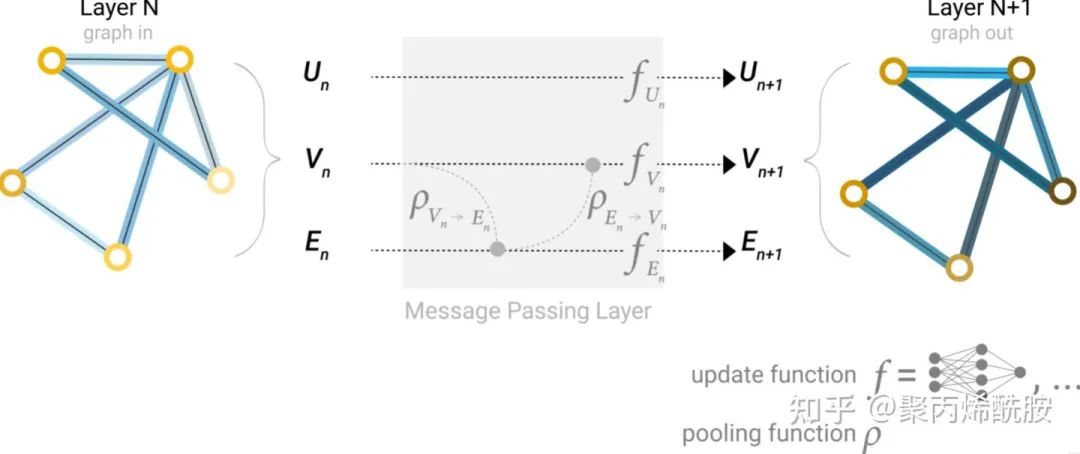
学习边的表示(Learning edge representations)
下图是信息传递层的原理,从节点到边、边到节点的传递。
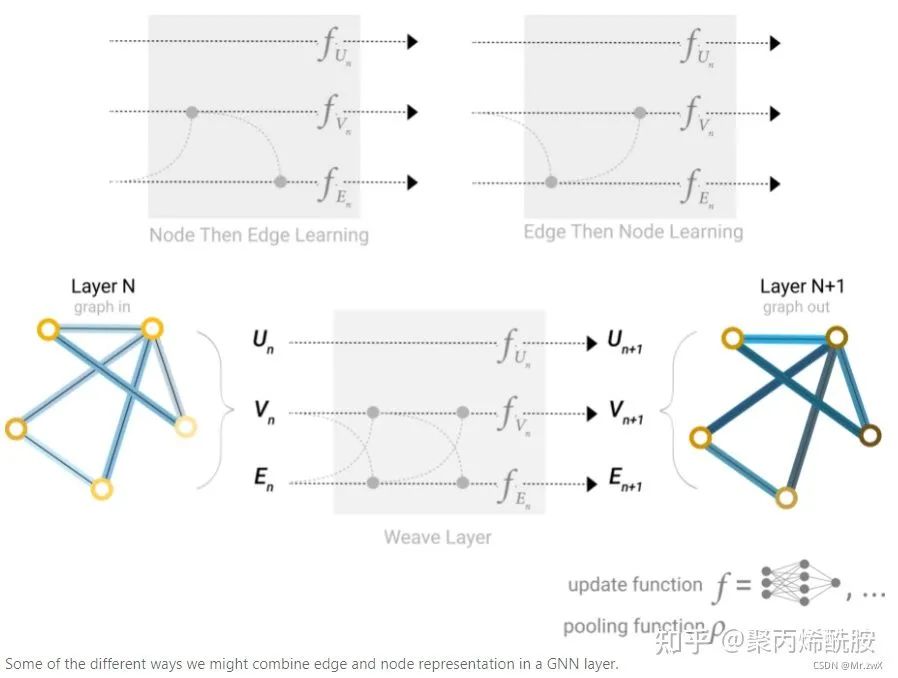
下面是两种不同的聚集方式:先从节点到边/先从边到节点。现在对于哪种做法更好还没有定论,作者提出可以交替进行(下图种的weave layer),只是向量会更宽一些。
添加全局表示(Adding global representations)
如果说图很大,或者连接不够紧密,那聚合就需要走很远很远的路。这里介绍了一种解决方案:master node or context vector,这是一个虚拟的、抽象的点,与所有的节点和边相连。
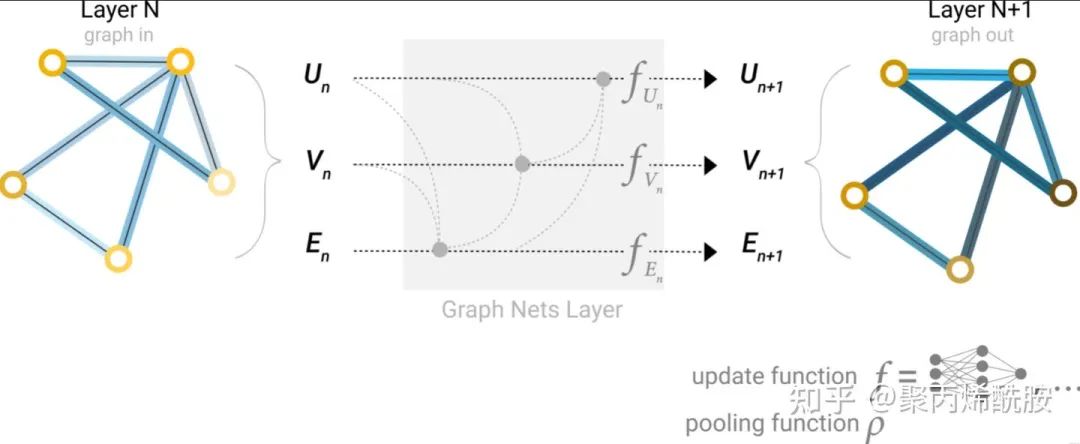
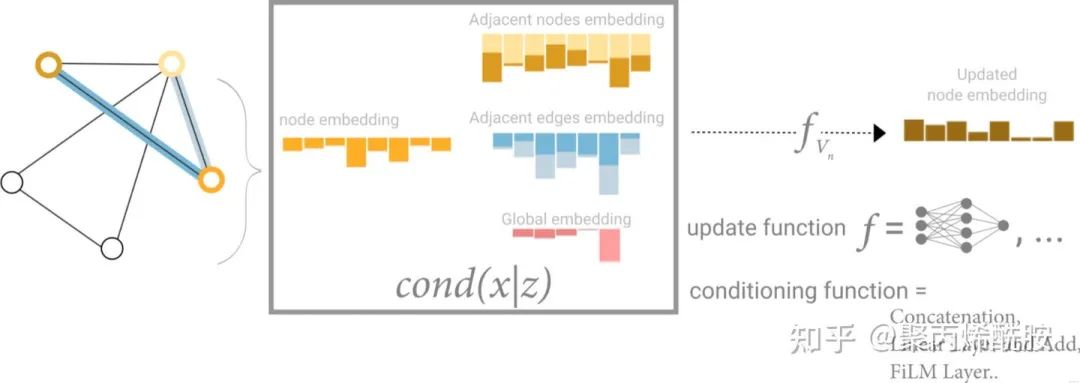
作者说这个其实可以认为是featurize-wise attention mechanism(特征级的注意力机制),因为将相近的节点聚集了过来。现在我们就知道了基于消息传递的图神经网络是怎么样工作的。
4 实验
在这篇文章中,作者非常费心将GNN嵌入到javascript中,搭建了这样一个playground,给出分子结构的数据集,通过调节超参数,得到训练效果和结果可视化。分子结构是可以自定义的,非常值得玩一玩。
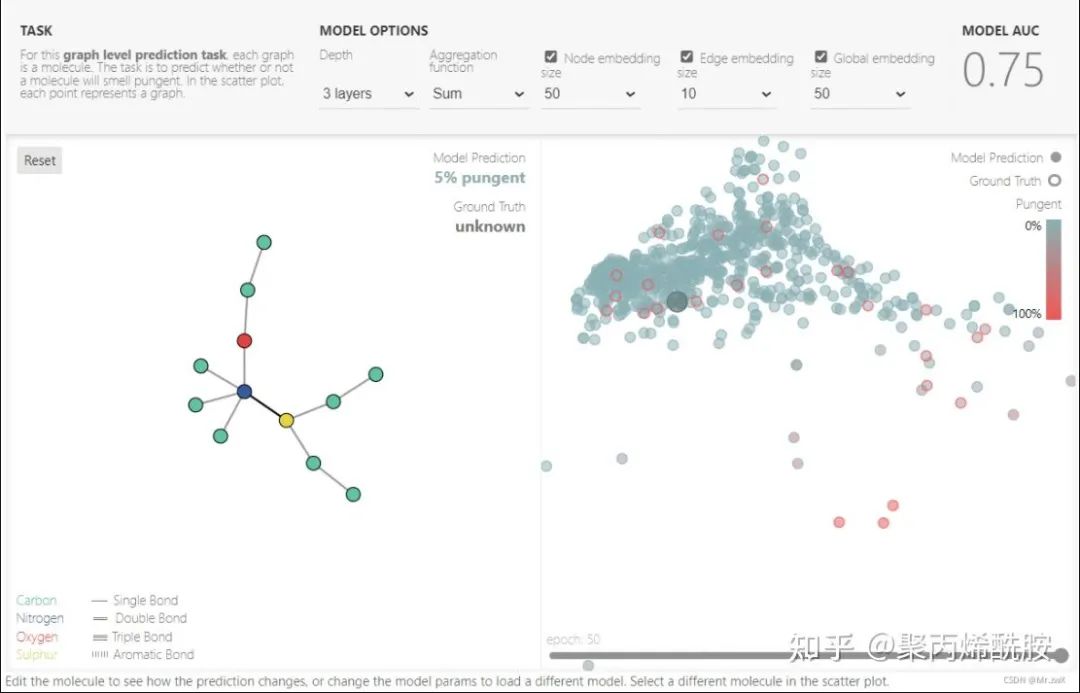
下面是超参数对效果的影响:
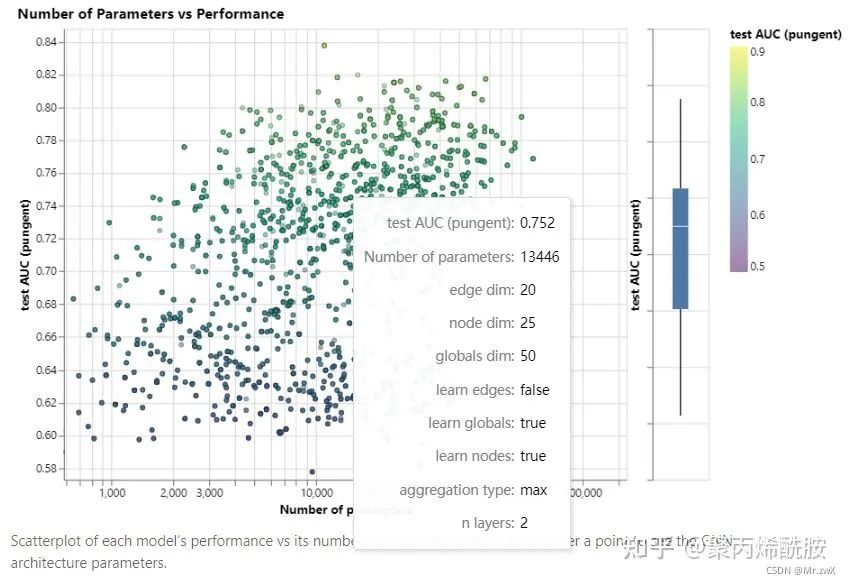
点边和全局向量长度对效果的影响:
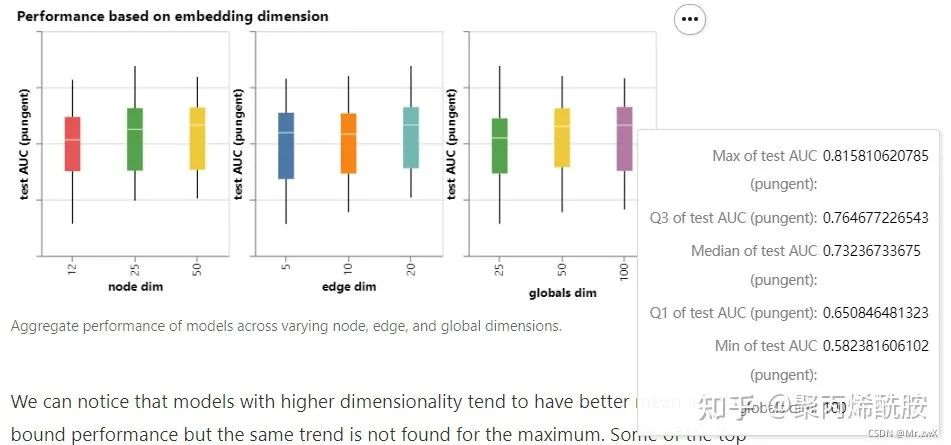
不同层数对效果的影响:
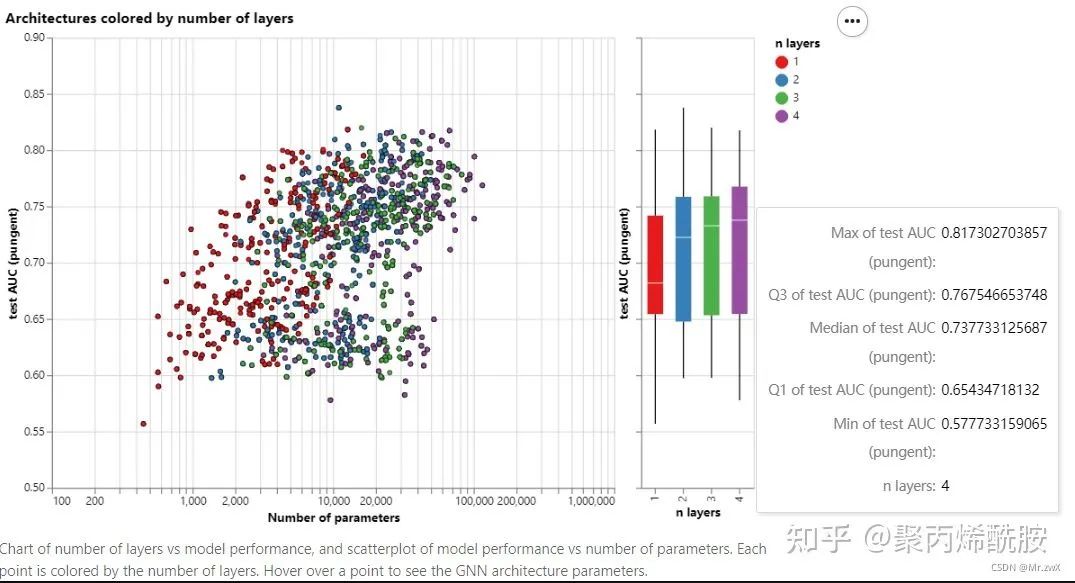
聚合方式对效果的影响:
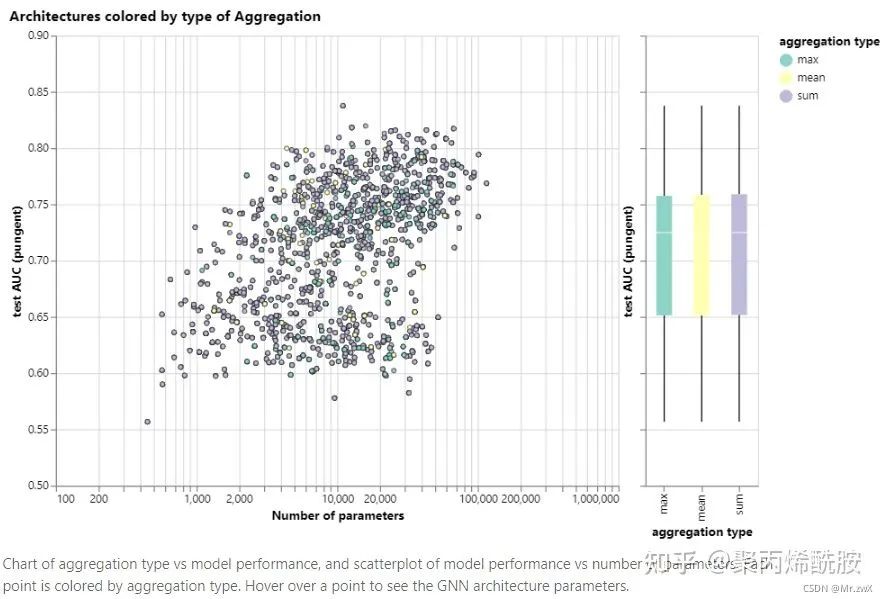
在哪些属性之间传递信息对效果的影响:
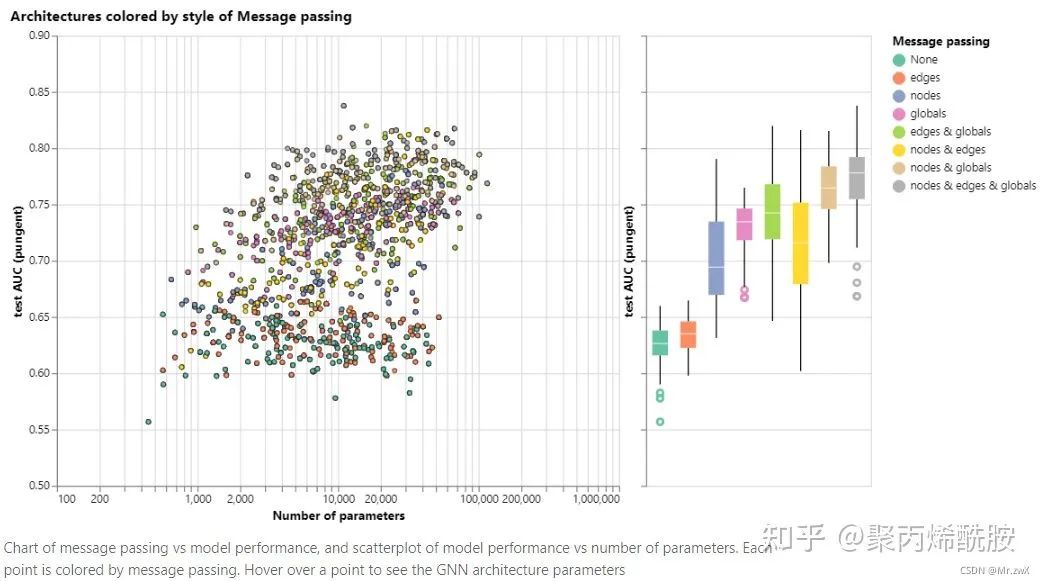
5 图相关的技术
multigraph和分层图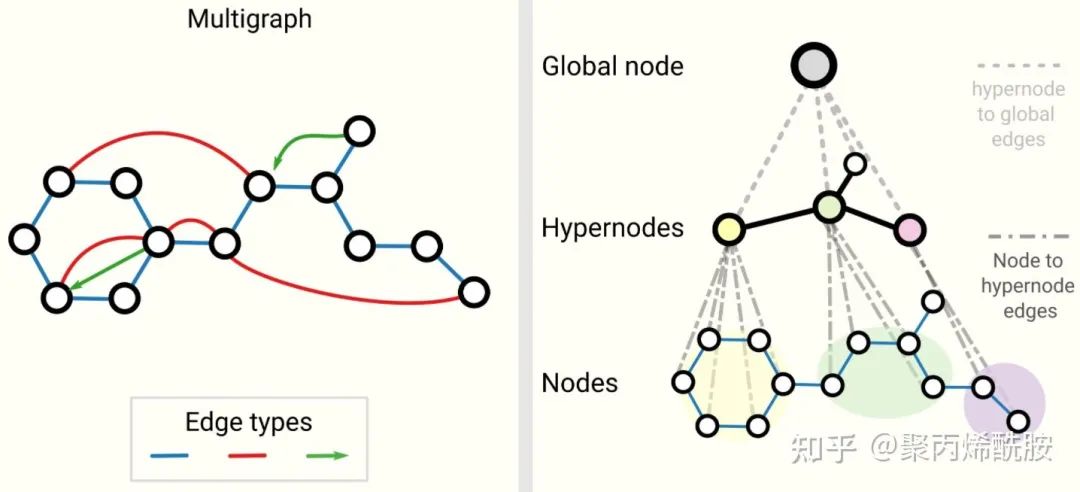
图采样和batch
图采样介绍了随机采样、随机游走、随机游走+邻居采样、扩散采样。
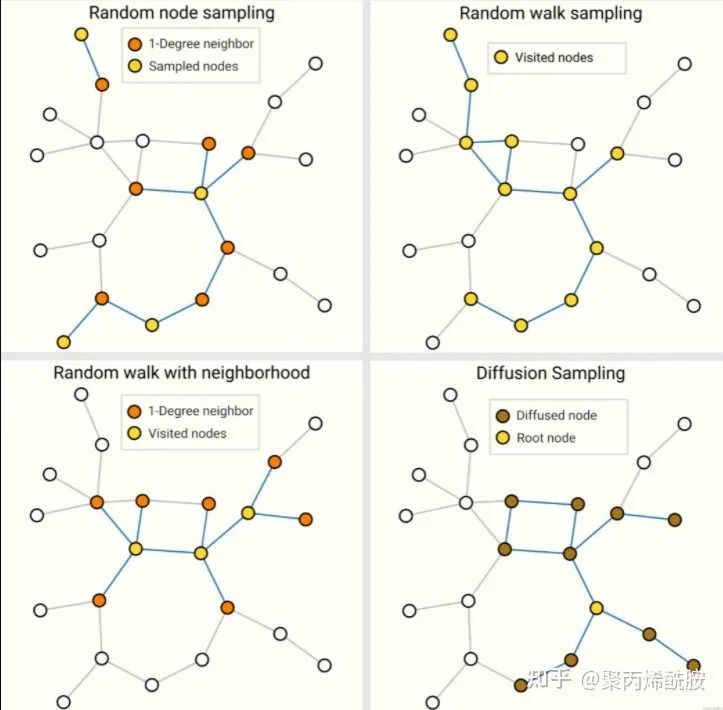
batch就是采用和其他神经网络一样的做法,把大图切成小样本进行一些运算,但是每个节点邻居数不同,如何合并为一个规则的tensor是具有挑战性的问题。
Inductive biases
CNN的假设是空间变换的不变性,RNN的假设是时序的连续性。对于GNN来说,假设是保持图的对称性(变换排列顺序,训练结果不变)。
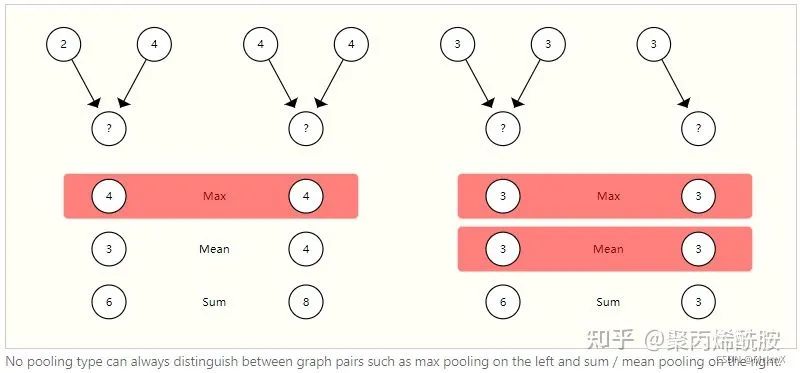
对比聚合操作
sum max mean没有一种是非常理想的,不能一概而论,举了如下的例子:
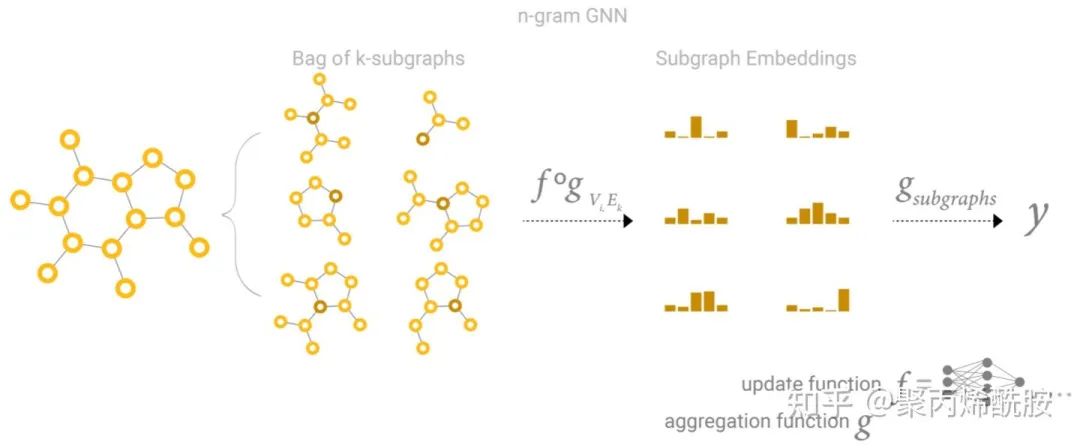
GCN作为子图函数近似(个人认为这一部分是GNN的核心思想!!!)
GCN如果是k层,每一层都往前看一个邻居,那么最后一个节点看到的是一个子图,这个子图大小是k,和节点的距离是k。这里我理解的就是,GCN有多少层,就看到了多少阶的邻居。
所以,GCN实际上是有N个子图,每个子图都是从原节点出发,往前走k步。
边和图对偶
点和边做对偶,把边变成点,点变成边,邻接关系保持不变。
图卷积和矩阵乘法,矩阵乘法和图游走
核心就是做图卷积等价于拿邻接矩阵做矩阵乘法。
PageRank就是在很大的图上做随机游走,实际上就是把邻接矩阵拿出来,不断和向量做乘法。
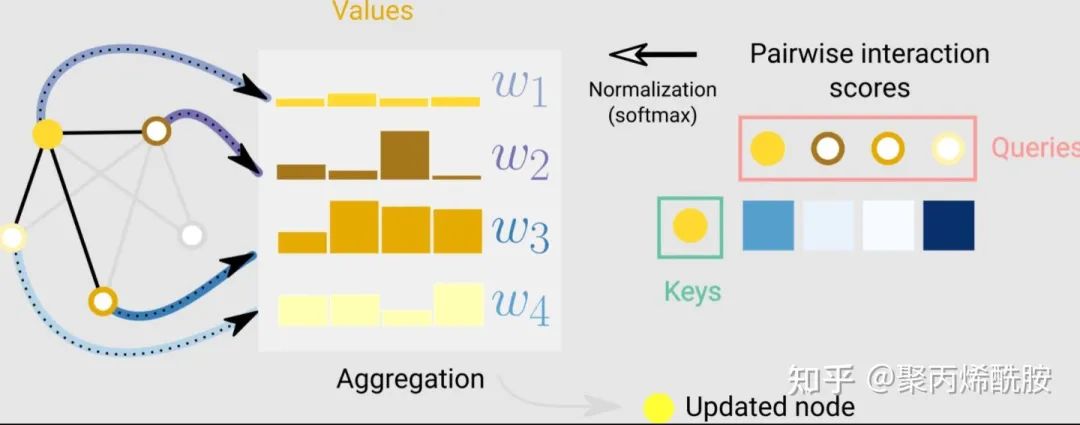
图注意力网络(GAT)
在GCN中,将邻居节点汇聚到某个节点上,实际上是没有加权的。其实图神经网络中也可以像CNN中的卷积核一样,在3x3窗口中带有基于空间位置的不同的权重。图上不需要空间位置,只需要通过注意力机制计算两个节点向量的关系强弱,按计算出来的权重来聚合。
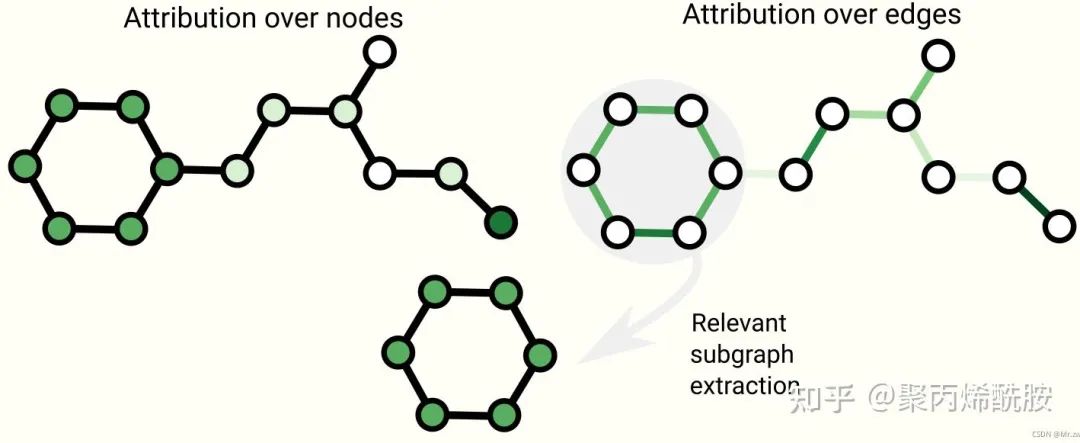
图的可解释性
神经网络到底学到了什么东西,可以抓取子图来看学到了什么。
生成模型
我们之前的模型是不改变图结构的,这里通过生成模型可以对图的拓扑结构进行有效建模。
6 对文章和GNN的评论
对于文章
从头到尾读下来非常流畅!先介绍什么是图,在图中我们对顶点、边、全局都用向量表示,以及现实中的数据如何表示为图,如何对图做预测,算法用到图上有什么挑战。然后开始介绍图神经网络,首先定义了GNN是对属性做变换而不改变其结构,从最简单的例子开始讲解,用三个MLP做属性向量的变换,用全连接层做输出从而实现预测。如果有缺失向量怎么办,那就做聚合操作,把边、节点、全局属性利用上,也可以完成我们的预测工作。最后介绍真正意义的GNN,每一层通过汇聚操作把信息传递过来,从每个顶点看到邻居节点的信息,在每一层能充分汇聚到图中的信息。然后是实验部分,作者搭建了playground供读者玩,跑出了不同的超参数对模型效果的影响,最后对GNN的相关技术进行了展开。
文章写得是非常精美的,文中存在大量的交互图,文字围绕图展开。这么多的交互图既是缺点也是优点,用JavaScript写如此多的交互图是非常耗时间的事情,作者尽可能用图来代替大量的公式和代码,更直观易懂。本文的缺点就是,文章的宽度的展开,很多地方让读者一知半解,了解不到其中细节,导致懂GNN的人能感受到GNN的强大,不懂GNN的人仍然不知道其核心在哪里。
对于GNN
图是非常强大,几乎所有数据都能表示成图,但是图上做优化很难,涉及到CPU和GPU的训练也是一个挑战,同时图神经网络对超参数非常敏感。近些年图神经网络在学术界迅速发展,实际上工业落地的并不多,GNN的发展还需要时间的沉淀。
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于交互式学习图神经网络的网站的主要内容,如果未能解决你的问题,请参考以下文章