PostgreSQL——查询优化——预处理
Posted weixin_47373497
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PostgreSQL——查询优化——预处理相关的知识,希望对你有一定的参考价值。
2021SC@SDUSC
目录
概述
我负责的PostgreSQL代码部分:查询的编译与执行
此篇博客的分析内容:查询优化——预处理
在上两篇博客中,我介绍了查询重写的过程,分析了查询重写过程的主要函数。在查询重写之后,就要进行查询优化了。在DBMS中,用户的查询请求可以采用不同的方案来执行。但是不同的方案之间的查询效率确是不一样的。查询效率这一点大型数据库中即存放了大数据集的数据库中十分关键,并且在分布式数据库中也很关键,会直接关联到用户体验感和功能效率。而本篇博客要介绍的查询优化——负责选择一种代价最小的执行方案。
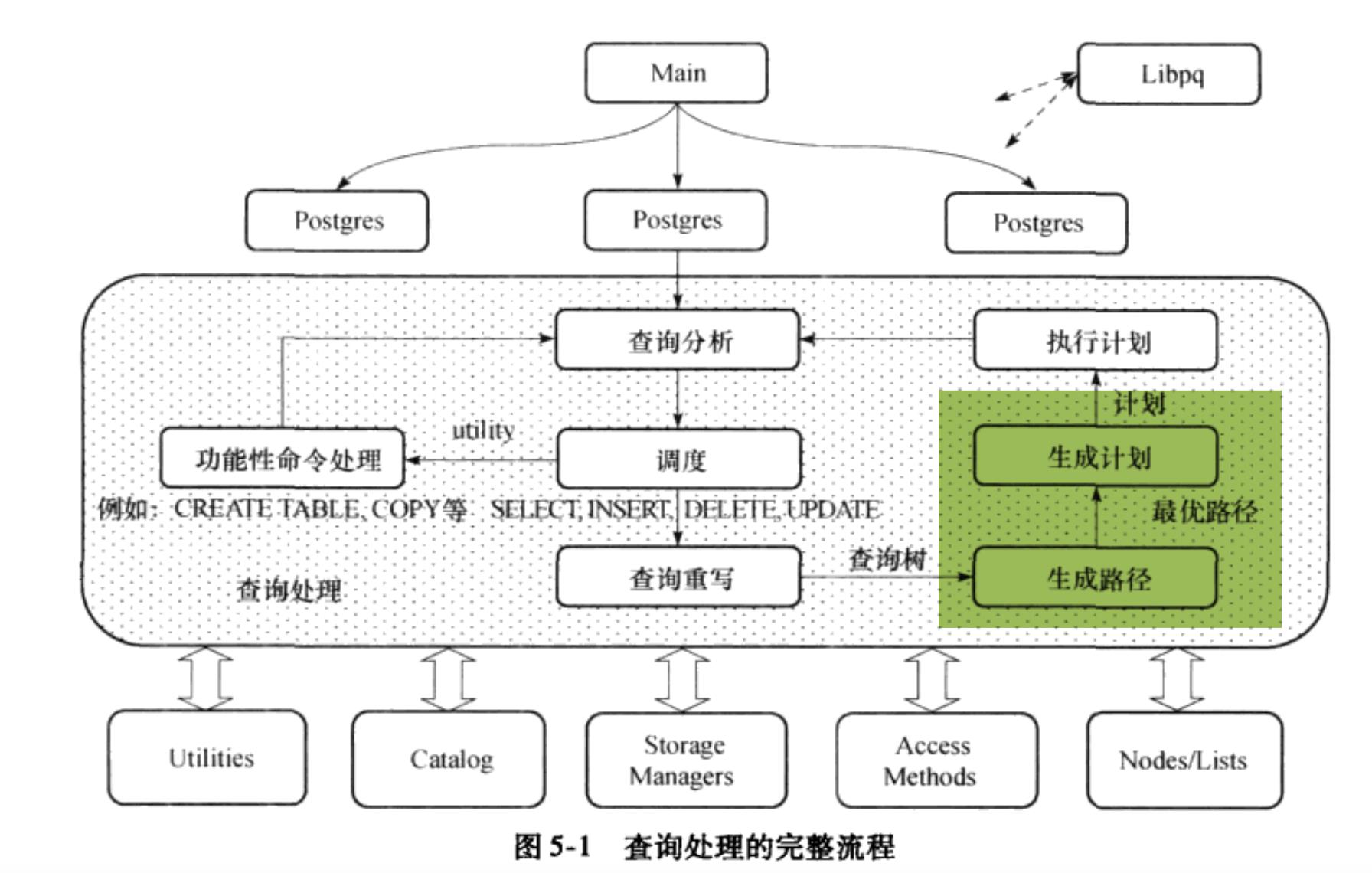
查询优化
查询优化的最终目的是得到可被执行器执行的最优计划。查询优化的核心思想是:尽量先做选择操作,后做连接操作。因为在数据库的查询中,最耗时的是表的join操作,所以先做选择的操作可以尽量减少表连接的数据量。查询优化的整个过程可以分为预处理,生成路径和生成计划三个阶段。预处理实际上是对查询树(Query结构体)的进一步改造。在预处理的过程中,最重要的是提升子链接和提升子查询,推后表连接。在生成路径阶段,接收到改造后的查询树后,采用相应的动态规划算法,生成最优的连接路径和候选的路径连接表。在生成计划阶段用得到的最优路径,先生成基本计划树然后根据查询语句所对应的计划节点形成完整计划树。本篇博客先分析第一部分——预处理阶段
pg_plan_queries函数
查询分析完成后,它的最终产物——查询树链表将被移交给查询优化模块,。查询优化模块的入口函数是pg_plan_queries函数,它负责将查询树链表变成执行计划链表。pg_plan_queries函数通过调用下面介绍的pg_plan_query函数对每一个查询树进行处理,并将生成的返回。
pg_plan_queries(List *querytrees, int cursorOptions, ParamListInfo boundParams)
List *stmt_list = NIL;//初始化PlannedStmt结构体链表
ListCell *query_list;//查询树链表节点的临时变量
foreach(query_list, querytrees)//遍历查询树
Query *query = lfirst_node(Query, query_list);//取得第一个节点
PlannedStmt *stmt;//PlannedStmt结构体
//查询优化模块只会对非UTILITY命令进行处理。
if (query->commandType == CMD_UTILITY)//如果是CMD_UTILITY类型则不进行优化,如果不是才进行优化
//如果是CMD_UTILITY类型则不进行优化
stmt = makeNode(PlannedStmt);
stmt->commandType = CMD_UTILITY;
stmt->canSetTag = query->canSetTag;
stmt->utilityStmt = query->utilityStmt;
stmt->stmt_location = query->stmt_location;
stmt->stmt_len = query->stmt_len;
else//不是CMD_UTILITY类型则调用pg_plan_query函数进行优化
stmt = pg_plan_query(query, cursorOptions, boundParams);
//把处理后的PlannedStmt结构体stmt添加到结构体链表中
stmt_list = lappend(stmt_list, stmt);
//返回PlannedStmt结构体链表
return stmt_list;
pg_plan_queries函数调用的—— pg_plan_query函数
pg_plan_queries函数通过调用pg_plan_query函数对每一个查询树进行处理。
pg_plan_query(Query *querytree, int cursorOptions, ParamListInfo boundParams)
PlannedStmt *plan;//PlannedStmt结构体,最后pg_plan_query函数返回plan
//查询优化模块只会对非UTILITY命令进行处理。
//如果是CMD_UTILITY类型则不进行优化,如果不是才进行优化
if (querytree->commandType == CMD_UTILITY)
return NULL;
//Planner必须有一个快照,以防它调用用户定义的函数。
Assert(ActiveSnapshotSet());
TRACE_POSTGRESQL_QUERY_PLAN_START();
if (log_planner_stats)
ResetUsage();//记录统计数据
//调用优化器 planner函数
plan = planner(querytree, cursorOptions, boundParams);
if (log_planner_stats)
ShowUsage("PLANNER STATISTICS");
//返回PlannedStmt结构体plan
return plan;
pg_plan_queries函数返回的—— PlannedStmt结构体
typedef struct PlannedStmt
NodeTag type; //节点的标识符Tag
CmdType commandType; //计划所对应的命令类型,分别有select|insert|update|delete|utility
uint64 queryId; //查询树id
bool hasModifyingCTE; //WITH语句中是否存在insert|update|delete关键字
bool canSetTag; //是否需要设置命令结果标志
bool transientPlan; //当TransactionXmin改变时是否要重做计划
bool parallelModeNeeded; //是否需要并行
int jitFlags; //使用哪种形式的JIT
struct Plan *planTree; //计划树
List *rtable; //范围表
List *resultRelations; //计划中的结果关系,由结果关系的RTE索引构成
List *rootResultRelations;//INSERT/UPDATE/DELETE命令所影响的关系在rtable中的位置(index)
List *subplans; //子计划,可为空
Bitmapset *rewindPlanIDs; //需要回卷的子计划的索引信息
List *rowMarks; //用于select for update等
List *relationOids; //该计划需要的表的oid
List *invalItems; //计划所依赖的其他对象,用PlanInvalitem结构表示,其中记录了被依赖的对象所属的SysCache的ID以及其对应的系统表元组的TID
List *paramExecTypes; //执行的计划所需的参数类型
Node *utilityStmt; //定义游标时用来记录游标定义语句的分析树
int stmt_location; //SQL语句的起始位置
int stmt_len; //SQL语句的长度
PlannedStmt;
pg_plan_query函数调用的——planner函数
pg_plan_query函数中负责实际生成的是planner函数。
planner(Query *parse, int cursorOptions, ParamListInfo boundParams)
PlannedStmt *result;//PlannedStmt结构体,最后以PlannedStmt结构体形式返回
if (planner_hook)
result = (*planner_hook) (parse, cursorOptions, boundParams);
else
result = standard_planner(parse, cursorOptions, boundParams);//调用standard_planner函数进入标准的查询规划处理,standard_planner函数会返回PlannedStmt 结构体供planner返回结果result
return result;
planner函数通过调用standard_planner函数进入标准的查询优化处理。函数standard_planner负责接受Query查询树及外部传递的参数信息,返回PlannedStmt结构体。(PlannedStmt结构体分析见上)但是由于planner函数又是通过调用不同的函数分别完成计划树的处理,优化,清理。所以,在这里我将主要分析planner函数调用的不同功能的函数。因为我们在这篇分析的是查询优化的预处理阶段,所以先分析subquery_planner函数,因为查询优化的预处理过程是由subquery_planner函数中的部分函数完成的。
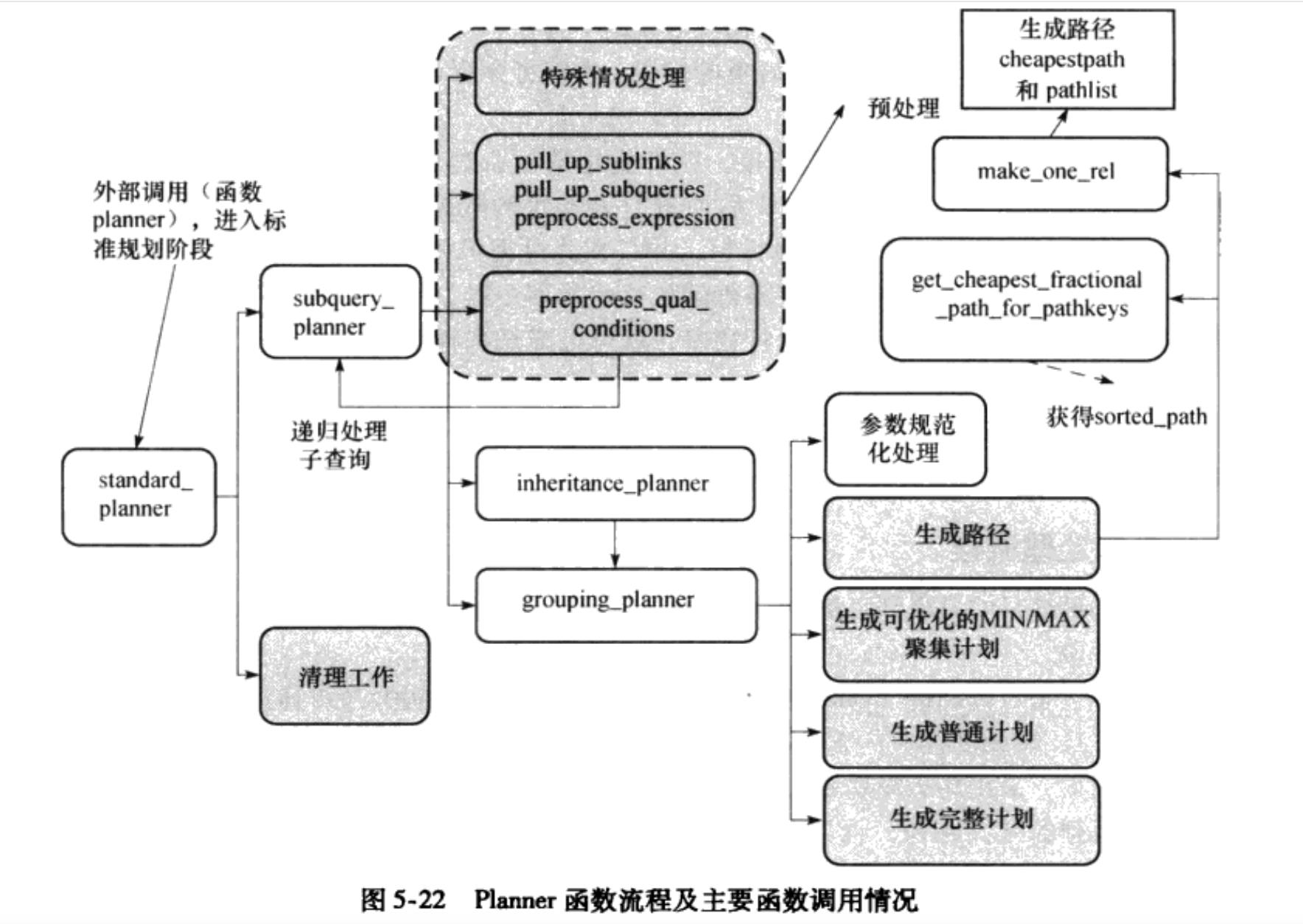
standard_planner函数调用subquery_planner函数的代码:
//standard_planner函数调用subquery_planner函数进行查询优化的预处理阶段
root = subquery_planner(glob, parse, NULL,
false, tuple_fraction);
standard_planner函数调用的——subquery_planner函数
subquery_planner函数接受Query查询树,最后通过PlannedStmt结构体的形式返回Plan计划树。(Plan计划树被封装在PlannedStmt结构体中)subquery_planner函数负责创建计划,可以递归处理子查询。subquery_planner函数的工作分为两个部分:
1:依据消除冗余条件,减少查询层次,简化路径生成的基本思想,调用预处理函数对查询树进行处理
2:调用inheritance_planner 或者grouping_planner进入生成计划流程,此过程不对查询树做出实质性改变
subquery_planner函数执行流程
subquery_planner(PlannerGlobal *glob, Query *parse,
PlannerInfo *parent_root,
bool hasRecursion, double tuple_fraction)
//传入参数分析
//PlannerGlobal *glob:PlannerGlobal 类型的指针,记录做计划期间的全局信息,例如子计划,子计划的范围表等,每条查询语句有且仅有一个该变量。
//Query *parse:Query类型的指针,指向要生成计划的查询树
//PlannerInfo *parent_root:PlannerInfo类型的指针,指向父查询的规划器相关信息(首次调用为空)
// bool hasRecursion:bool类型,如果正在处理的是一个递归的with查询,则hasRecursion为真
//double tuple_fraction:double类型,表示计划扫描元组的比例。
PlannerInfo *root;//返回值
List *newWithCheckOptions;
List *newHaving;//Having子句
bool hasOuterJoins;//是否存在Outer Join
bool hasResultRTEs;
RelOptInfo *final_rel;
ListCell *l;//临时变量
//初始化信息,为该子查询创建一个PlannerInfo结构体,并为结构体赋初始值,最后subquery_planner函数返回root(PlannerInfo类型)
root = makeNode(PlannerInfo);
root->parse = parse;
root->glob = glob;
root->query_level = parent_root ? parent_root->query_level + 1 : 1;
root->parent_root = parent_root;
root->plan_params = NIL;
root->outer_params = NULL;
root->planner_cxt = CurrentMemoryContext;
root->init_plans = NIL;
root->cte_plan_ids = NIL;
root->multiexpr_params = NIL;
root->eq_classes = NIL;
root->append_rel_list = NIL;
root->rowMarks = NIL;
memset(root->upper_rels, 0, sizeof(root->upper_rels));
memset(root->upper_targets, 0, sizeof(root->upper_targets));
root->processed_tlist = NIL;
root->grouping_map = NULL;
root->minmax_aggs = NIL;
root->qual_security_level = 0;
root->inhTargetKind = INHKIND_NONE;
root->hasRecursion = hasRecursion;
//如果hasRecursion为真,则需要为该子查询新建一个worktable变量,并把它的标识符放在PlannerInfo结构体的wt_param_id字段中
if (hasRecursion)
//把worktable变量的标识符放在PlannerInfo结构体的wt_param_id字段中
root->wt_param_id = assign_special_exec_param(root);
else
root->wt_param_id = -1;
root->non_recursive_path = NULL;//不需要递归
if (parse->cteList)//判断查询树是否有with子句
//如果有一个WITH链表,使用查询处理每个链表,并为其构建一个initplan子计划结构。
SS_process_ctes(root);//处理With 语句
replace_empty_jointree(parse);
子链接和子查询的区别:子查询是一条完整的查询语句,而子链接是一条表达式,但是表达式内部也可以包含查询语句。直白点说呢就是:子查询是放在FROM子句里的而子链接则出现在WHERE子句或者HAVING子句中。
在subquery_planner函数里,调用pull_up_sublinks函数处理WHERE子句和JOIN/ON子句中的ANY和EXISTS类型的子链接。
subquery_planner函数调用pull_up_subqueries函数来提升子查询。当子查询仅仅是一个简单的扫描或者连接时,就会把子查询或者子查询的一部分合并到父查询中以进行优化。
1.在范围表中存在子查询。对于简单的子查询,直接调用pull_up_simple_subquery函数进行提升;而对于简单的UNION ALL子查询,调用pull_up_simple_union_all函数进行提升,其他的情况则不处理;
2.在FROM表达式中存在子查询。对于FROM列表中的每个节点都调用pull_up_subqueries递归处理;
3.连接表达式中的子查询。调用pull_up_subqueries函数递归地处理.
//如果原始的查询树有子链接,则调用pull_up_sublinks函数提升子链接
if (parse->hasSubLinks)
pull_up_sublinks(root);
//扫描RTE中的set-returning函数,如果可能,内联它们(生成下一个可能被上拉的子查询)。这里递归问题的处理方式与SubLinks相同。
inline_set_returning_functions(root);
//调用pull_up_subqueries函数提升子查询
pull_up_subqueries(root);
if (parse->setOperations)//判断查询树中有无集合操作
flatten_simple_union_all(root);//扁平化处理UNION ALL
//根据查询树中的相关信息,确定PlannerInfo中的相关信息如:hasJoinRTEs,hasOuterJoins,hasHavingQual
foreach(l, parse->rtable)//对查询树中每一个范围表单独处理
RangeTblEntry *rte = lfirst_node(RangeTblEntry, l);
switch (rte->rtekind)//根据范围表的类型,做不同的处理
case RTE_RELATION://表示RTE类型为普通表
if (rte->inh)//判断是否需要继承
rte->inh = has_subclass(rte->relid);
break;
case RTE_JOIN://表示RTE为链接类型
root->hasJoinRTEs = true;
if (IS_OUTER_JOIN(rte->jointype))//判断是否有外链接
hasOuterJoins = true;
break;
case RTE_RESULT://表示空的from子句
hasResultRTEs = true;//记录from子句为空
break;
default:
break;
if (rte->lateral)//判断是否有级联
root->hasLateralRTEs = true;
//预处理RowMark信息。 需要在子查询上拉(以便所有非继承的RTEs都存在)和继承展开之后完成(以便expand_inherited_tables可以使用这个信息来检查和修改)
preprocess_rowmarks(root);//预处理RowMark信息
//判断是否存在Having表达式
root->hasHavingQual = (parse->havingQual != NULL);
清除hasPseudoConstantQuals标记,该标记可能在distribute_qual_to_rels函数中设置
root->hasPseudoConstantQuals = false;
表达式的预处理工作主要由函数preprocess_expression完成。该函数采用递归扫描的方式处理PlannerInfo结构体里面保存的目标属性、HAVING子句、OFFSET子句、LIMIT子句和连接树jointree。总体来说做了以下这些事
1.调用flatten_join_alias_vars函数,用基本关系变量取代连接别名变量;
2.调用函数eval_const_expression进行常量表达式的简化,也就是直接计算出常量表达式的值。例如:“3+1 <> 4” 这种会直接被替换成“FALSE”;
3.调用canonicalize_qual函数对表达式进行规范化,主要是将表达式转换为最佳析取范式或者合取范式
4.调用函数make_subplan将子链接转换为子计划.
//调用preprocess_expres以上是关于PostgreSQL——查询优化——预处理的主要内容,如果未能解决你的问题,请参考以下文章