清空购物车的同时也不妨入手一台CaussDB(for MySQL)
Posted 虫链Java Library
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清空购物车的同时也不妨入手一台CaussDB(for MySQL)相关的知识,希望对你有一定的参考价值。
是什么让你了解了华为云?
-
现在云数据库已经成为一种我们人人都耳熟能详的词汇,博主从事Java开发行业也有些年头了,对目前的云产品也都有所了解,国内的云产品也一直是炒得厉害,各大互联网公司都在宣传。
-
结合各中小企业目前项目的的需求和实际考察。我们发现无论是正在创业路上抑或是准备创业,在企业初期,预算不足是常态,进行周密的成本控制往往是排在第一位的。
今天谨代表一家初创业公司讨论一下那些年我们上云之路的故事也给诸位创业者一些有益的参考。
-
我们企业初期一直使用传统的mysql和redis数据库,程序运行久了数据渐渐多了,有次夜里加班到12点,需要临时上版本发现MySQL内存严重不足,主从复制的库紧急扩容时出现了各种让人头疼的问题,即便扩容完了,日后维护起来也特别麻烦。听别的公司朋友推荐云数据库用起来多好多方便,于是就找领导沟通置换数据库,当时搜索了一下当前比较有规模的云服务公司,最终确定了华为云。
-
在和几家客服进行简单的沟通发现,华为云的客服在服务态度,响应速度,专业性上要强于其他几家(主要是大半夜也真的有人在啊)。当然对于各家的活(主)动(要)产(价)品(位)也做了一定的了解,不仅仅因为价格便宜,后续通过几个维度给大家细致的讲解一下从传统数据库到华为云GaussDB究竟提升了哪些性能。
数据库的概念
数据库是什么呢?维基百科上是这样定义的 🎈
- 所谓
数据库系以一定方式储存在一起、能予多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。一个数据库由多个表空间(Tablespace)构成。
这句话怎么理解呢?简单来说:数据库就是一个存储结构化数据的仓库
- 其实我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
聊到关系型数据库了,我们就不得不提一下关系型数据库与非关系型数据库的区别了
- 关系型数据库指采用了关系模型来组织数据的数据库。关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
- 非关系型数据库以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,不局限于固定的结构,可以减少一些时间和空间的开销。
了解完传统数据库我们再来了解一下云数据库(重点)
- 云数据库是部署和虚拟化在与计算环境中的数据库,是在云计算的大背景在发展起来的一种新型的共享基础架构的方法,他极大地增强了数据库的存储能力,消除了人员、硬件、软件的重复配置,让软、硬件升级变得更加容易。具有高可扩展性、高可用性,采用多租形式和支持资源的有效分发等特点。
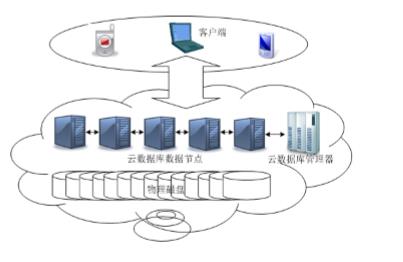
- 云数据库并非一种全新的数据库技术,而只是以服务的方式提供数据库功能。云数据库并没有自己专属的数据模型,云数据库所采用的数据模型可以是关系型数据库所使用的的关系模式,也可以是NoSQL数据库所采用的非关系模型。
什么是华为云GaussDB?
这时有小伙伴要问了,市面上有许多形形色色的云数据库服务,在这为何给大家推荐华为云 Gaussdb呢 ❓
- 下面根据我的步伐来了解一下华为云产品的魅力吧 ❗
GaussDB是华为自研数据库品牌,基于统一架构,支持关系型与非关系型数据库引擎,满足政企全场景的数据智能管理需求,开启数据库极速与融合时代,加速政企智能升级。
在整体架构设计上,底层是分布式存储,中间是每个DB特有的数据结构,最外层则是各个生态的接口,体现了多模的设计理念。
汇聚全球资源,全球7个区域、2000+数据库/数据仓库/大数据的高级内核引擎、算法、性能等专家与专业人才,持续战略投入10多年。在金融政企市场,GaussDB本地部署(Huawei Cloud Stack方案)取得国产数据库第一的市场份额。
在泛互联网市场,公有云增速第一,在1500+金融政企与泛互联网大客户取得规模商用。与100+伙伴建立合作关系,共享市场机会;并积极投入高校合作和开发者生态,累计赋能15万以上开发者。
___GaussDB数据库不是指某个特定的产品,而是一系列产品的统称而是一系列产品的统称 ❗
- 关系型数据库
| 产品名称 | 适用场景 |
|---|---|
| 云数据库 GaussDB(for openGauss) | 应用于金融、电信、政府等行业关键核心系统,高性能场景 |
| 云云数据库 GaussDB(for MySQL) | 中大型企业生产系统(高性能,大数据容量),例如金融、互联网等 |
| 云数据库 RDS for MySQL | 开源MySQL业务上云,享受云数据库的安全、弹性、高可用,降低企业TCO |
| 云数据库RDS for PostgreSQL | 开源PostgreSQL业务上云,享受云数据库的安全、弹性、高可用,降低企业TCO |
| 云数据库RDS for SQL Server | 企业用户微软生态上云,支持高可靠数据业务需求 |
- 非关系型数据库
| 产品名称 | 适用场景 |
|---|---|
| 云数据库 GaussDB(for Mongo) | 应用于游戏(装备、道具)、泛互联场景 |
| 云数据库 GaussDB(for Cassandra) | 泛互联网日志数据存储(并发写入量大,存储容量高)、工业互联网数据存储(写入规模大、存储容量大) |
| 云数据库 GaussDB(for Influx) | 工业互联网时序数据、用户银行流水数据、物联网数据存储(时序) |
| 云数据库 GaussDB(for Redis) | Key-Value存储模式,可用户互联网场景 |
| 文档数据库服务 DDS | 兼容MongoDB协议,应用于游戏(装备、道具)、泛互联网场景 |
- 数据库生态工具与中间件
| 产品名称 | 适用场景 |
|---|---|
| 数据复制服务 DRS | 用于数据库在线迁移和数据库实时同步 |
| 数据管理服务 DAS | 数据库一站式开发,DBA智能运维,企业流程审批,享受便捷、智能、安全、高效的数据库管理手段 |
| 数据管理服务 DAS | 工业互联网时序数据、用户银行流水数据、物联网数据存储(时序) |
| 数据库和应用迁移 UGO | 异构数据库迁移,数据库对象DDL的SQL转化和应用SQL转化 |
| 文档数据库服务 DDS | 兼容MongoDB协议,应用于游戏(装备、道具)、泛互联网场景 |
可以看到,GaussDB数据库已经被打造成多类型数据库的内核平台。
何为一台优秀的数据库?
数据库已经成为我们日常开发重要组成的一部分了,那何为一台优秀的数据库呢❓
CaussDB是这样定义的 😁
场景1:数据写满了急需扩容
-
随着企业规模扩张,更大的算力需求、更多的存储容量需求是必然的。例如在游戏开服、11.11大促抢购高峰期间,数据量爆发性增长,此时需要对数据库进行扩容,而且在不少的业务场景下,扩容的速度甚至要求达到
用户0感知的级别。 -
开源Redis由于资源以节点为单位,扩容只能计算、存储一起扩,资源浪费是一方面,还不得不做数据跨节点拷贝,耗时长。而且不少用户在扩容时,还可能面临着时间无法评估的尴尬。
场景2:点宕机导致数据长时间不可用,业务受损
- 单机数据库一旦宕机,全量数据不可用,只能等待数据库重启,导致业务受损严重。传统分布式数据库一旦部分数据分片故障,会导致一段时间内部分数据无法访问,依然对业务产生不小影响。
场景3:高峰期间,数据库写入拥塞
- 业务高峰是每一个企业关注的关键场景之一。开源Redis集群虽然比简单的主+备更能应付并发访问,但面对大量写入,依然会力不从心。一是因为它的节点是单线程做命令处理的工作,容易发生请求阻塞。二是由于备节点只读,因此它的集群中仅半数节点可写,抗写能力不足。
面对以上问题,以企业级Redis。GaussDB(for Redis)为例
- 它不仅存算分离数据库不仅拥有秒级扩容的优势,还能满足用户
算力不足扩节点、容量不足扩容量的要求。 - 由于存储池有
共享的性质,当部分计算层节点故障时,其他健康节点可以立刻接管“本不属于自己”的数据,让业务只感受到秒级抖动,即可继续访问全量数据。另外GaussDB(for Redis)抗写能力极强,能从容应对企业最关心的业务高峰。首先,它采用了多线程做命令处理的设计,单点不易发生请求阻塞。其次,在存算分离的架构优势下,实例中并不存在主备关系,全部节点都可写,吞吐能力强。
了解完 GaussDB(for Redis) 我们再来着重介绍下CaussDB(for MySQL) 👏
CaussDB(for MySQL)
- GaussDB(for MySQL) 是华为自研的最新一代企业级库数据库,完全兼容MySQL,基于华为最新一代DFV存储,采用计算存储分离架构,它将特定计算任务(备份与恢复逻辑)下推到DFV,以便更高效,快速地实现备份、恢复,而上层计算节点专注于业务逻辑处理。在这种模式之下,用户可以通过本地访问数据并直接与第三方存储系统交互,为其提供更高性能、更高可用、更多算力支持。👍
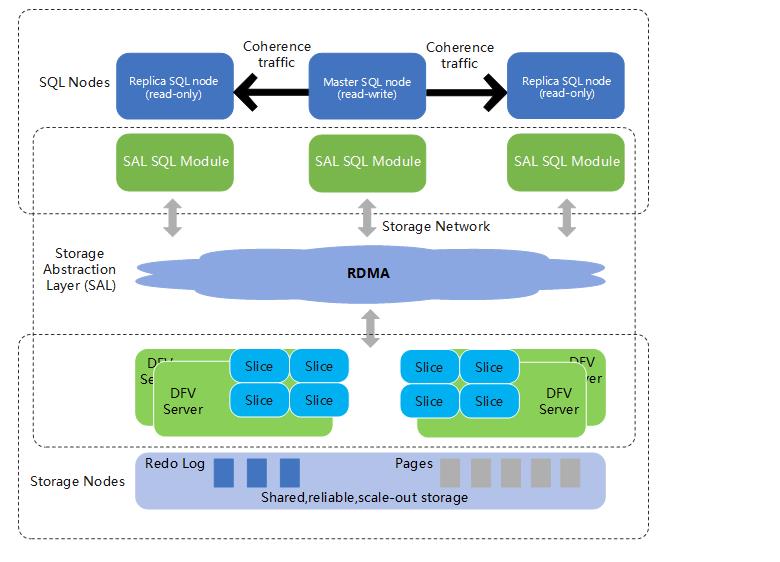
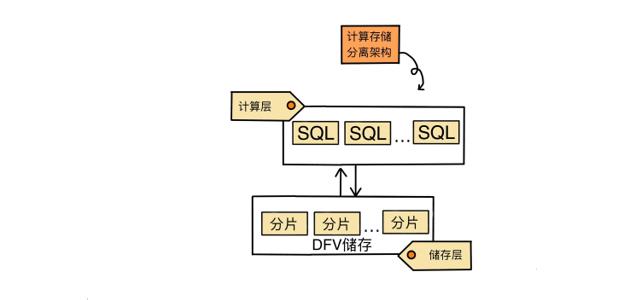
整体架构
- 如下图所示云数据库 GaussDB(for MySQL)整体架构自下向上分为三层。
-
存储层:基于华为DFV存储,提供分布式、强一致和高性能的存储能力,此层来保障数据的可靠性以及横向扩展能力。DFV(Data Function Virtual)是华为提供的一套通过存储和计算分离的方式,构建以数据为中心的全栈数据服务架构的解决方案。
-
存储抽象层:将原始数据库基于表文件的操作抽象为对应分布式存储,向下对接DFV,向上提供高效调度的数据库存储语义,是数据库高性能的核心。
-
SQL解析层:复用MySQL8.0代码,来保证与开源的100%兼容,用户业务从MySQL上迁移不用修改任何代码, 从其他数据库迁移也能使用MySQL生态的语法、工具,降低开发、学习成本。基于原生MySQL,在100%兼容的前提下进行大量内核优化,以及开源加固,开源生态,商用能力。
六大核心优势
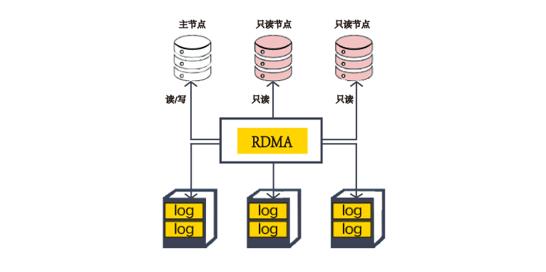
- 性能强悍:采用计算与存储分离,日志即数据架构,RDMA网络,性能达到开源数据库的7倍。
- 海量存储:基于华为自研DFV分布式存储,容量高达128TB,支持Serverless根据数据容量自动伸缩,存储自动分片,无需分库分表。

- 数据可靠:基于分布式架构的,可弹性扩展的虚拟块存储服务;具有高数据可靠性,高I/O吞吐能力。
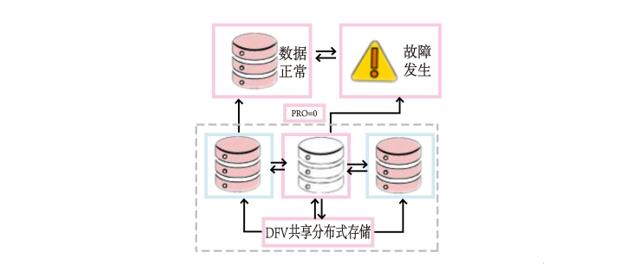
- 高效备份:采用Log Stream技术,分钟级快速备份和恢复TB级数据,最大支持732天备份保存,支持备份保留期限内任意时间点恢复数据。
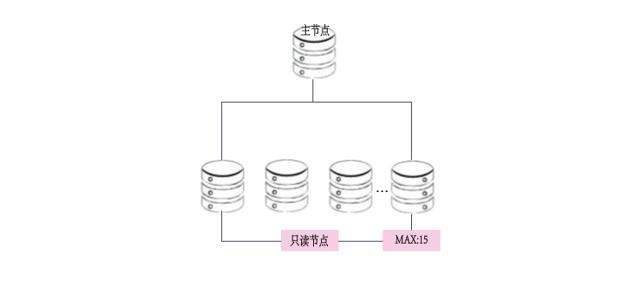
- 弹性易用:1写15读,分钟级添加只读实例,规格升降级。
- 高兼容性:完全兼容MySQL,无需分库分表,应用无需改造即可轻松迁移上云。
核心技术
并行执行
- 并行执行采用数据并行的并行模式,将需要执行的数据表划分为独立的数据块,然后启动不同的worker工作线程在划分的数据块上并行执行,最后leader线程通过消息队列汇总worker线程产生的部分结果。并行执行支持并行扫描、聚合计算、order by排序、join计算等。

32核256GB测试100G数据量的TPCH查询语句,16线程并发下性能提升8倍。
NDP(Near Data Processing)
- 云数据库 GaussDB(for MySQL)发布计算下推框架。针对数据密集型查询,将提取列,条件过滤,聚合运算等操作向下推送给GaussDB(for MySQL)的分布式存储层的多个节点并行执行。通过计算下推,提升并行处理能力,减少网络流量和计算节点的压力,提升查询处理执行效率。

NDP可与并行查询功能进行融合,达成全流程并行执行。
对比说明
- 1写15读、128TB海量存储、数据0丢失+故障闪恢复,不管从性能、扩展性、容量、可靠性和可用性都远远优于开源MySQL社区版。
| 方向 | 传统MySQL | GaussDB(for MySQL) |
|---|---|---|
| 性能 | 15W QPS | 百万级 QPS |
| 扩展性 | 1写3读 | 1写15读 |
| 容量 | 2T | 128T |
| 可用性可靠性 | 可用性可靠性难以兼顾 | 数据0丢失+故障闪修复 |
最后我想告诉大家
- 了解完了CaussDB我想告诉大家一款好的数据库产品不仅可以让我们放心的把数据托管进去,还可以提高日常开发效率,使大家专注业务逻辑编码,免去数据库的日常维护等工作,说了这么多你是否心动了呢?眼下正值双11,作为程序员的我们在给女友清空购物车的同时,不妨也入手一台优秀的华为云数据库吧!活动期间福利多多 😊
小伙伴们快来点击后方链接挑选自已心意的产品吧 👉 https://t.csdnimg.cn/uZVZ
以上是关于清空购物车的同时也不妨入手一台CaussDB(for MySQL)的主要内容,如果未能解决你的问题,请参考以下文章