微博评论采集
Posted 八爪鱼大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微博评论采集相关的知识,希望对你有一定的参考价值。
采集场景
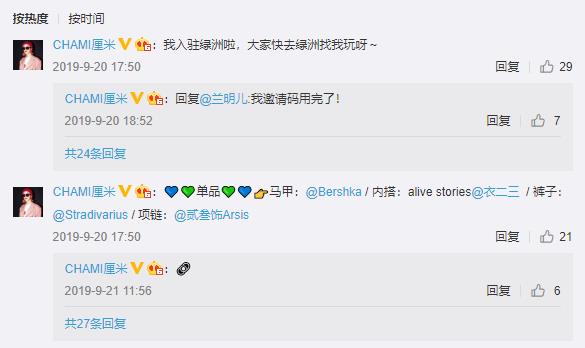
在微博主页(https://weibo.com/)登录后,打开微博博文链接,采集博文链接的评论数据。实例网址:https://weibo.com/1977661791/I7PgktlCh 。
采集字段
博主用户名、发布时间、博文、分享数、评论数、点赞数、评论、评论用户名、评论时间。
采集结果
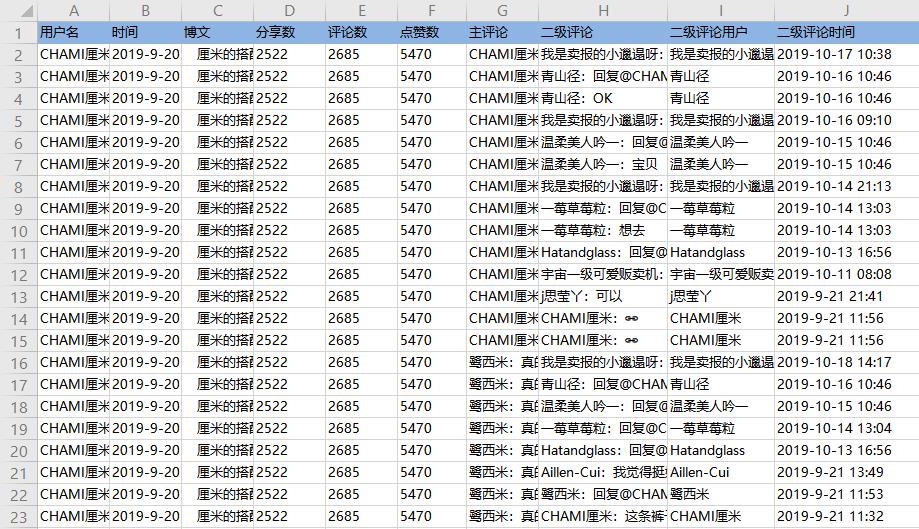
采集结果可导出为Excel、CSV、html、数据库等多种格式。导出为Excel示例:
教程说明
本篇更新时间:2020/05/18 八爪鱼版本:V8.1.12
如果因网页改版造成网址或步骤无效,无法收集到目标数据,请联系官方客服,我们将及时修正。
采集步骤
步骤一:打开网页
步骤二、使用账号密码登录微博
步骤三、创建【循环-打开网页】,批量打开多个博文网址
步骤四、设置滚动
步骤五、提取微博字段 步骤
步骤六、创建循环翻页,以采集多页评论
步骤七、创建【循环点击】,展开评论下的回复
步骤八、创建【循环列表】,提取评论列表数据
步骤九、启动采集
以下为具体步骤:
步骤一、打开网页
在首页【输入框】中,输入微博主页网址 https://weibo.com/,点击【开始采集】,八爪鱼自动打开网址。
特别说明:
a. 打开网页后,如果开始【自动识别】,请点击【不再自动识别】或【取消识别】将其关掉。因为本文不适合使用【自动识别】。
b. 【自动识别】适用于自动识别网页上的列表、滚动和翻页,识别成功后直接启动采集即可获取数据。详情点击查看 【自动识别】教程
步骤二、使用账号密码登录微博
要采集微博评论数据,首先需要登录。如果没有登录,采集过程中容易跳出登录提示,影响正常采集。
在八爪鱼中的登录步骤:
1、选中用户名输入框,在操作提示框中点击【输入文本】,输入账号。
2、选中密码输入框,在操作提示框中点击【输入文本】,输入密码。
3、选中【登录】按钮,在操作提示框中,点击【单击该按钮】。
等待一会后,成功登陆微博。
特别说明:
a. 一般情况下,微博输入账号密码即可登录。如果登录时出现验证码,八爪鱼也可解决,点击查看 处理需要登录的网页(含登录时有验证码)
b. 如果账号密码输错, 进入【输入文本】设置页面,更改成正确的即可。更改后再执行一次【点击元素】,即可完成登录。
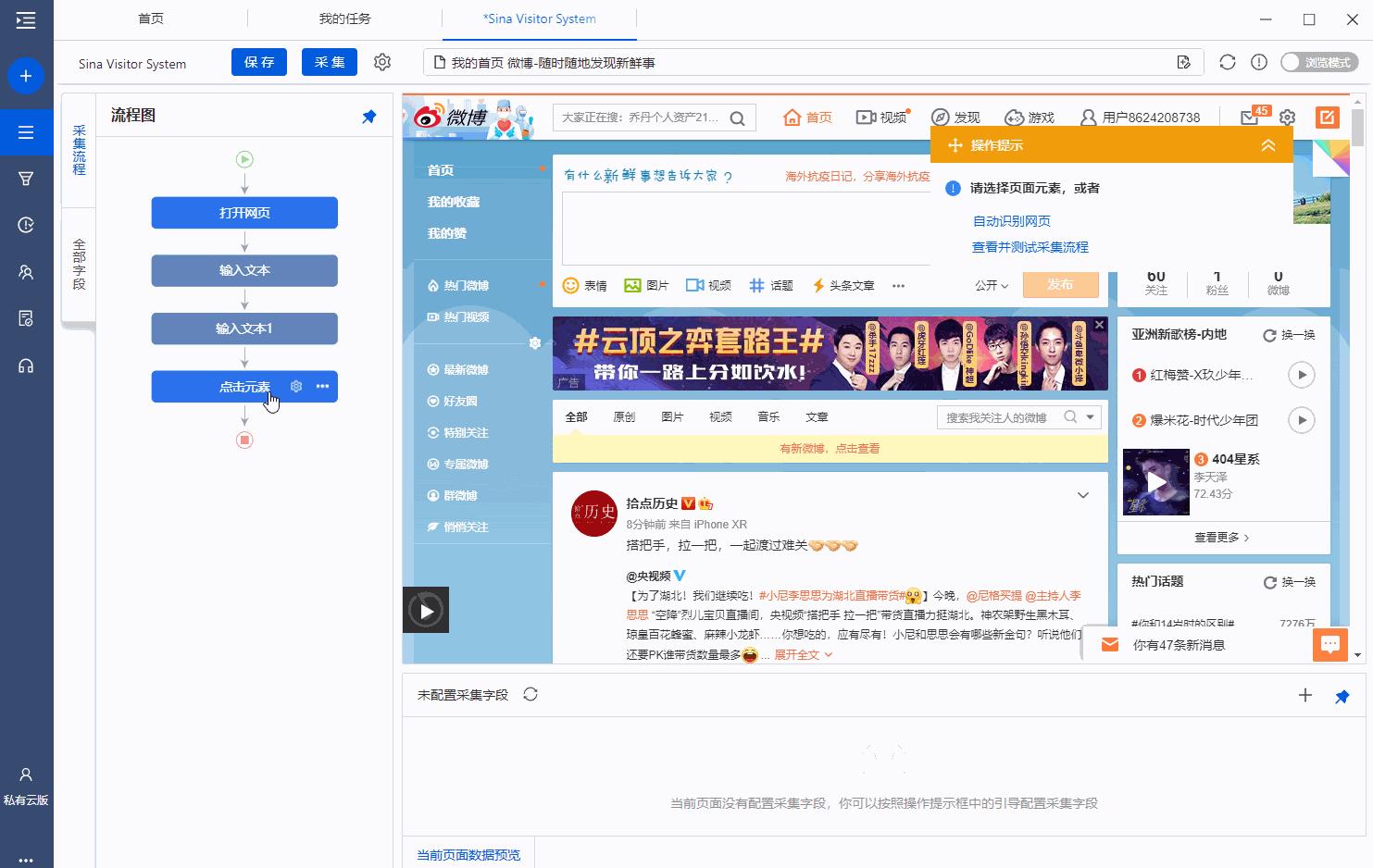
步骤三、创建【循环-打开网页】,批量打开多个博文网址
创建【循环-打开网页】,批量打开多个博文网址,实现自动采集多个博文网址下的评论。
在【点击元素】步骤后,添加一个【循环】。
进入【循环】设置页面。选择循环方式为【网址列表】,点击 按钮,将我们准备好的网址(可同时输入多个网址,一行一个即可)后保存。
步骤四、设置滚动
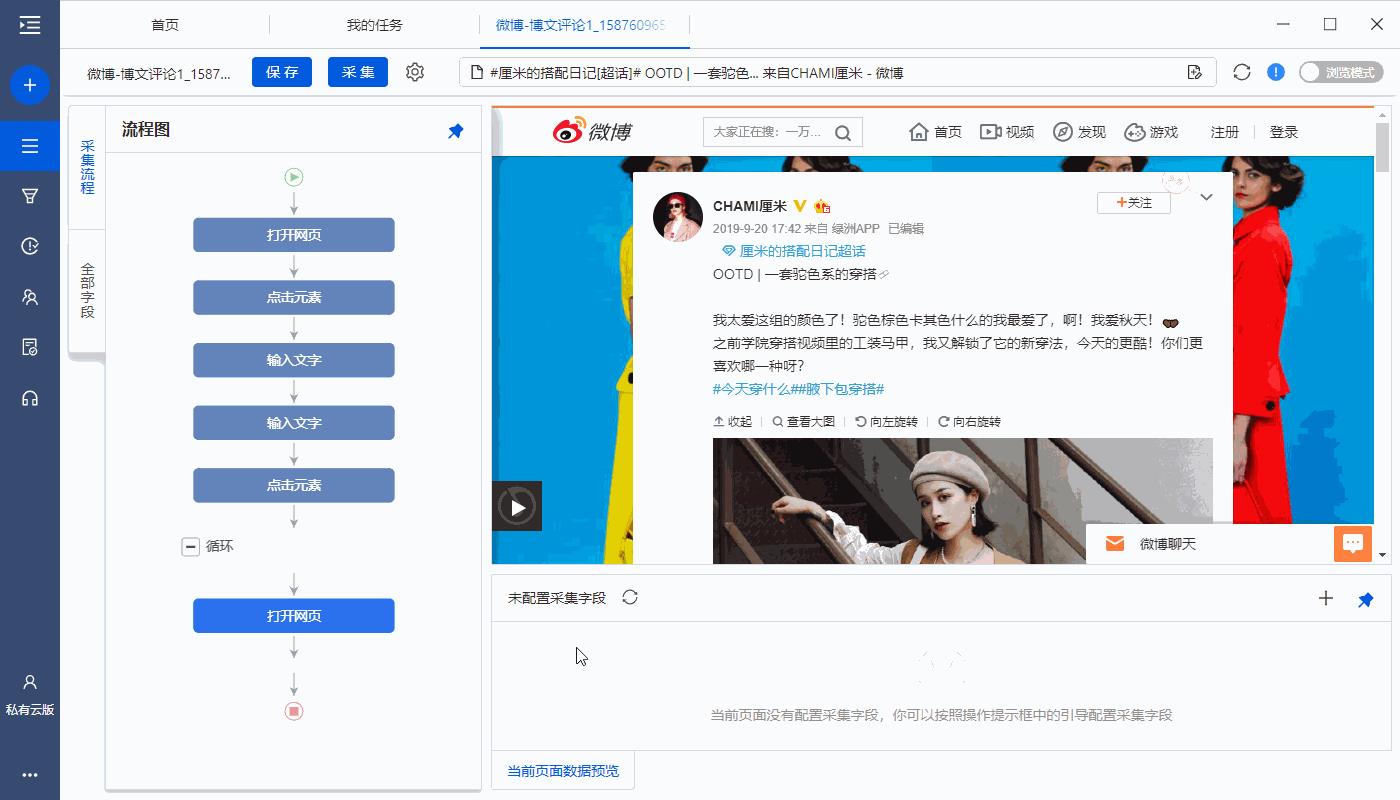
打开微博主页后,默认只显示一部分评论列表。向下滚动页面3次,才会出现【查看更多】按钮,点击此按钮可查看更多评论。在八爪鱼中也需设置滚动。
进入【打开网页】设置页面,点开【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【滚动到底部】,【滚动次数】为3次,【每次间隔】2秒 并保存。
特别说明:
a. 设置中的滚动次数和时间间隔,请根据采集需求和网页加载情况进行设置,并非是一成不变的,具体请点击查看处理滚动加载数据的网页教程
步骤五、提取微博字段
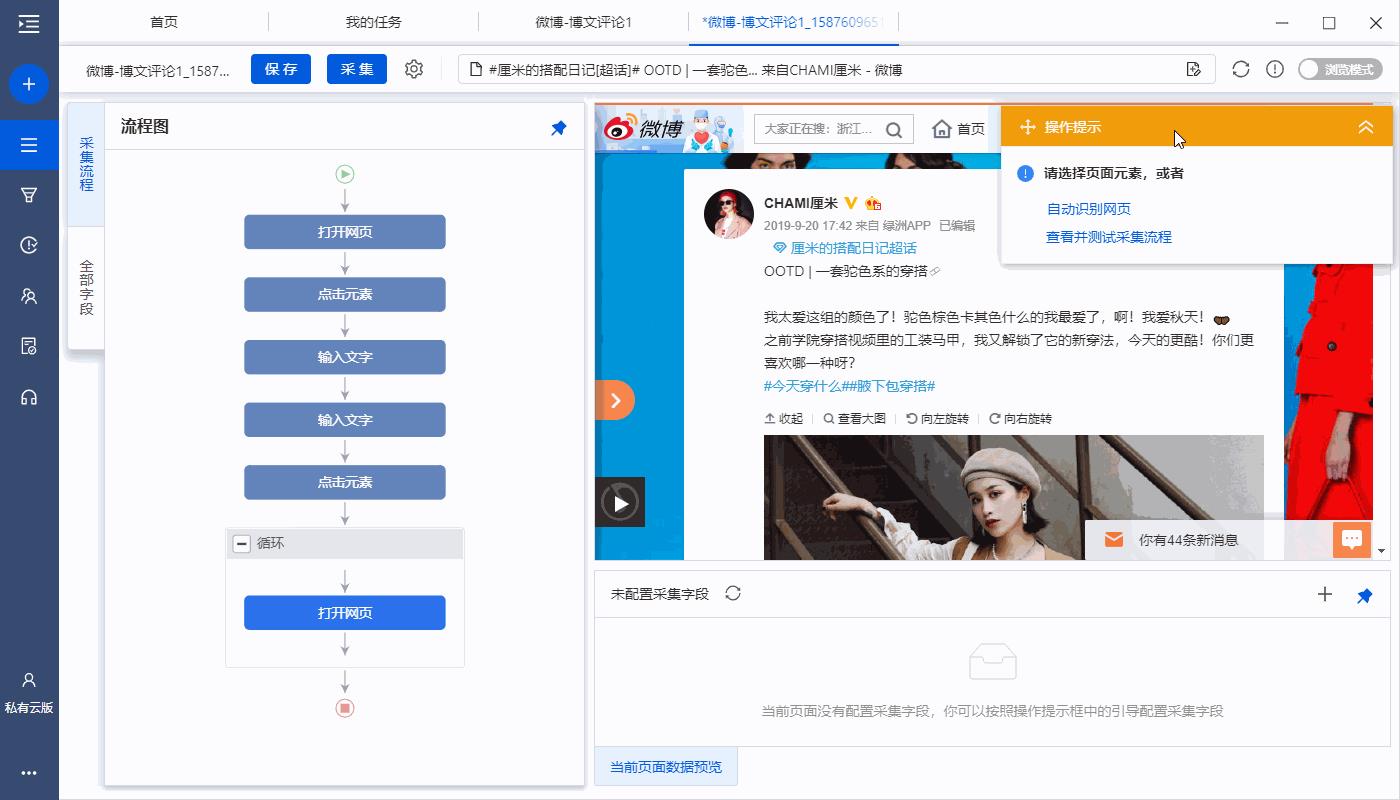
选中网页中的目标字段,在操作提示框中点击【采集该元素的文本】。
所有文本类的字段都可这样提取,示例中提取了 用户名、发布时间、博文详情、评论数、点赞数 。
步骤六、创建循环翻页,以采集多页评论
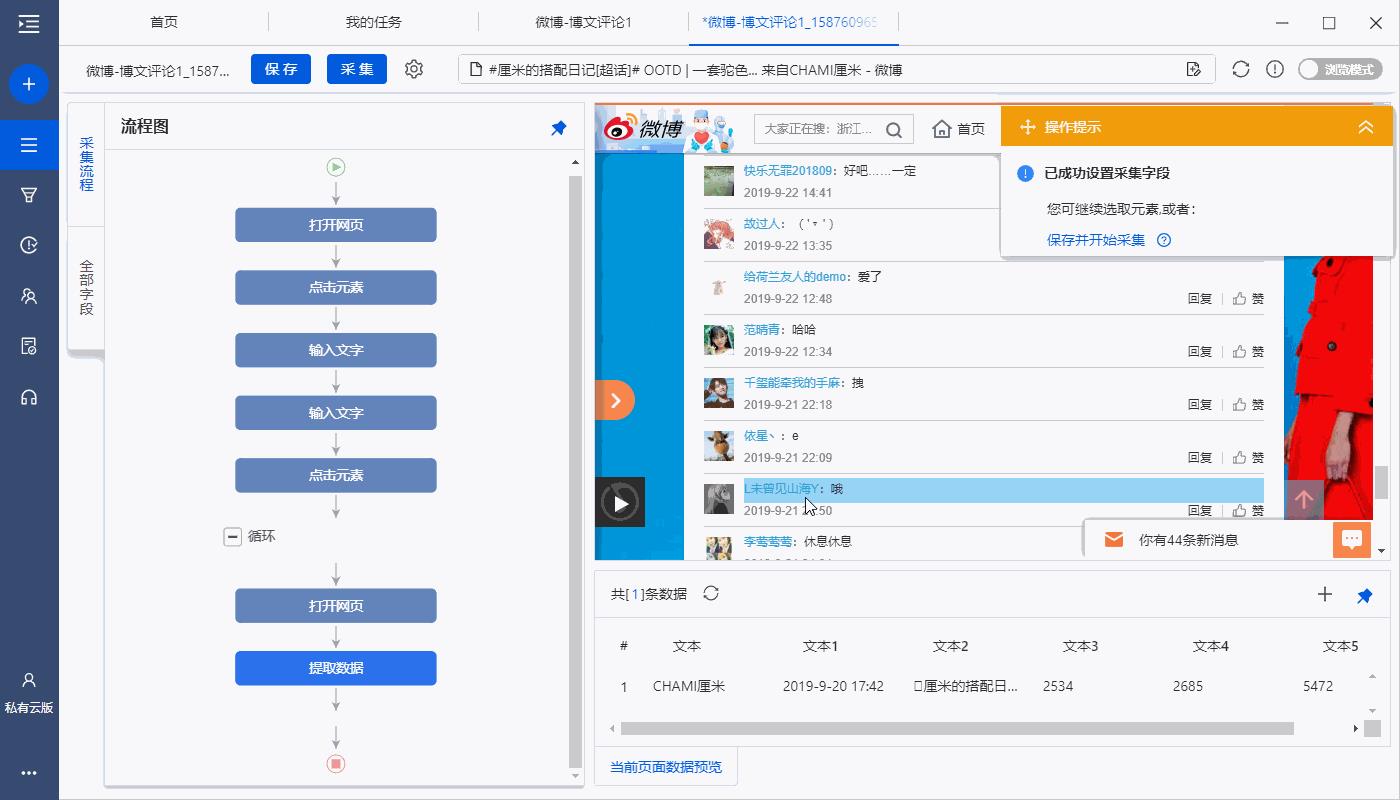
1、创建循环翻页
找到并选中网页里的【查看更多】按钮,在操作提示上单击【循环点击单个元素】,创建【循环翻页】。
特别说明:
a. 创建【循环翻页】后,采集数据时八爪鱼就会自动点击【查看更多】按钮翻页,以加载更多微博评论。
2、设置翻页次数
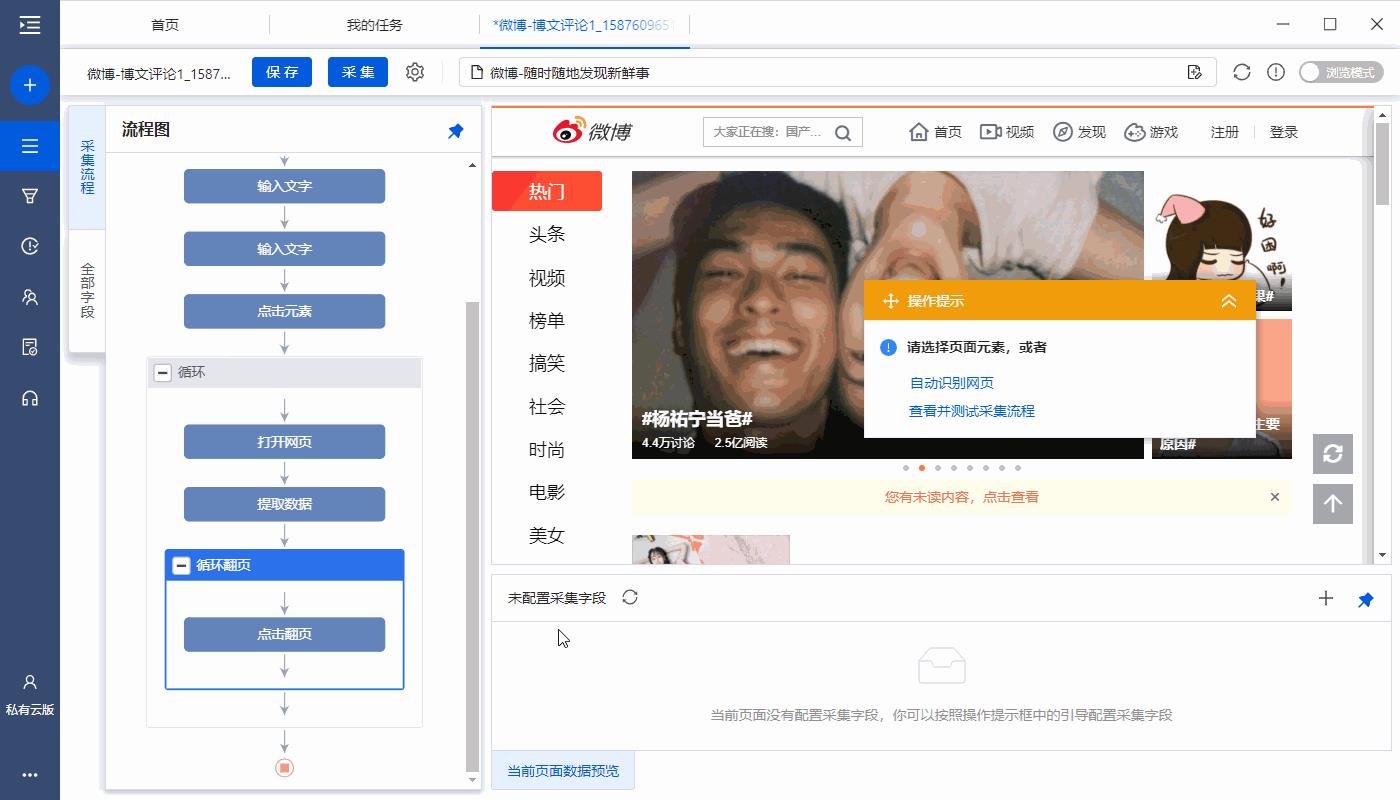
针对这类通过【查看更多】进行翻页的网页,需设置一个合适的翻页次数。
进入【循环翻页】设置页面,点开【退出循环设置】,勾选【循环执行次数等于】10次。
特别说明:
a. 为什么通过【查看更多】进行翻页的网页,需设置一个合适的翻页次数?通过一定次数的【查看更多】翻页后,页面上展示出非常多的评论列表。这些列表同在一个页面,采集的时候都会被定为到。如果同时定位的列表过多,速度会慢,影响数据的正常采集。设置一个合理的翻页次数,可以控制同时定位到的列表,保障数据采集正常进行。
步骤七、创建【循环点击】,展开评论下的回复
微博的评论分为主评论和其回复。示例中,我们点击【共X条回复】展开评论下的回复。
如果主评论下的回复过多,需点击多次【共X条回复】,才能展开全部回复。示例中只考虑点击1次【共X条回复】的情况。
1、创建【循环点击】
① 在网页中选中第一个【共X条回复】按钮
② 在操作提示框中,点击【选中全部】
③ 继续选择【循环点击每个链接】
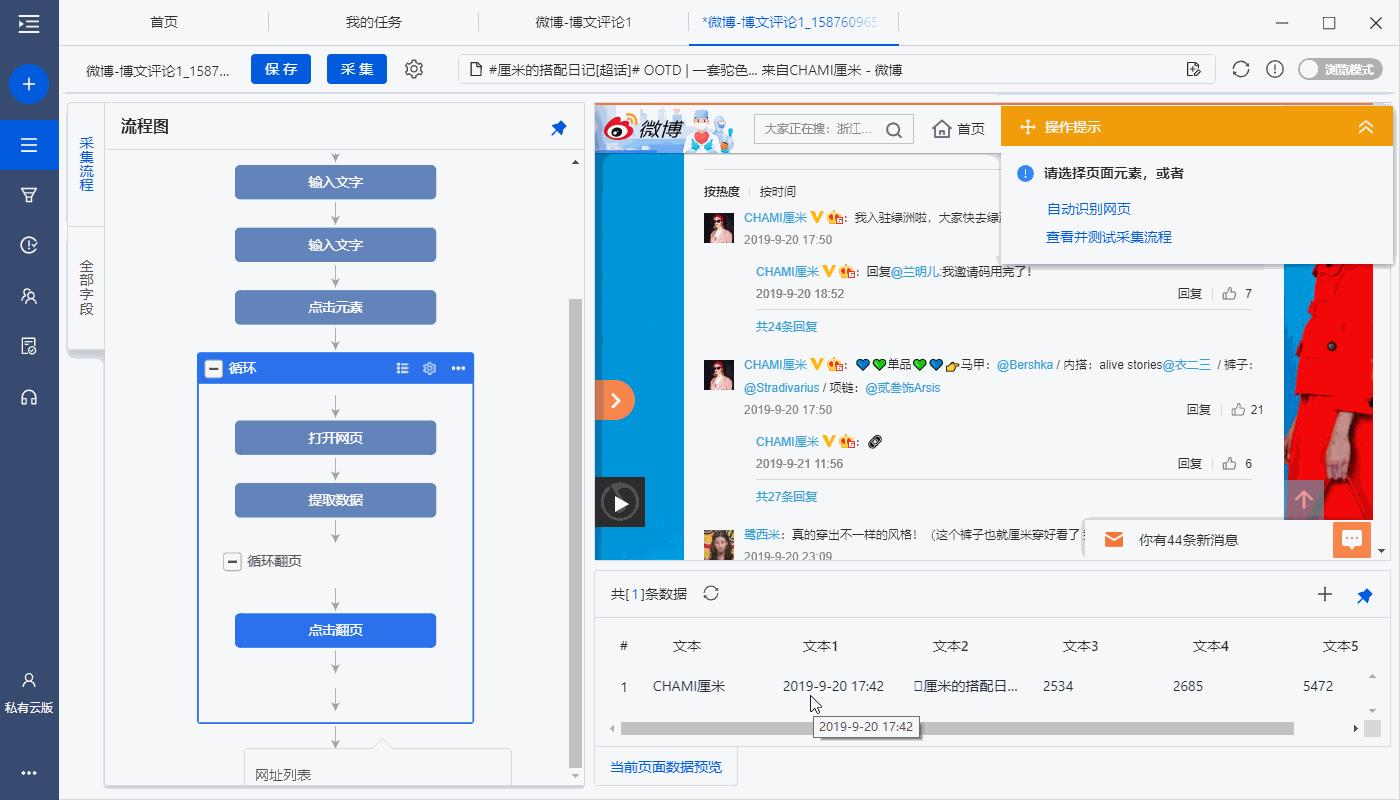
2、调整流程结构
我们需要的采集逻辑为:先点击【查看更多】进行翻页 → 点击【共X条回复】展开主评论下的回复。
但自动生成的采集流程不是这样的,需手动调整:选中【循环列表-点击元素1】整个步骤,将其拖入到【循环翻页】后。
特别说明:
a. 流程十分灵活,可根据需求调整各个步骤的位置。
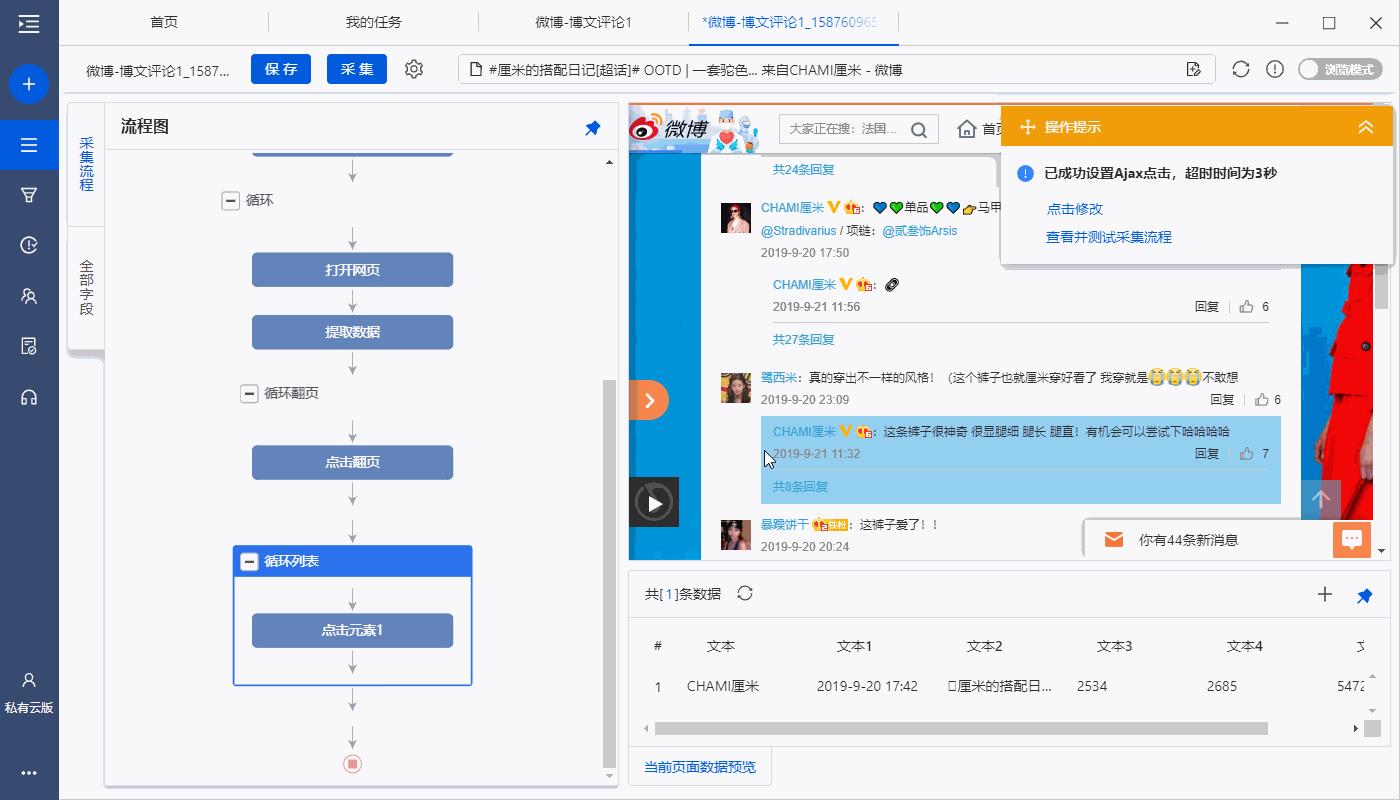
3、修改【循环点击】XPath
一条博文下,【共X条回复】的个数是不确定的。默认生成的【循环点击】XPath,无法精准定位到每一个【共X条回复】,需手动修改。
进入【循环列表】设置页面,选择【循环方式】为【不固定元素列表】,修改XPath为://div[@class=“WB_text”]/a[@suda-uatrack] ,然后保存。
特别说明:
a. 这里需要一定的XPath知识。点击查看 XPath学习与实例教程 。
步骤八、创建【循环列表】,提取评论列表数据
1、建立【循环列表】
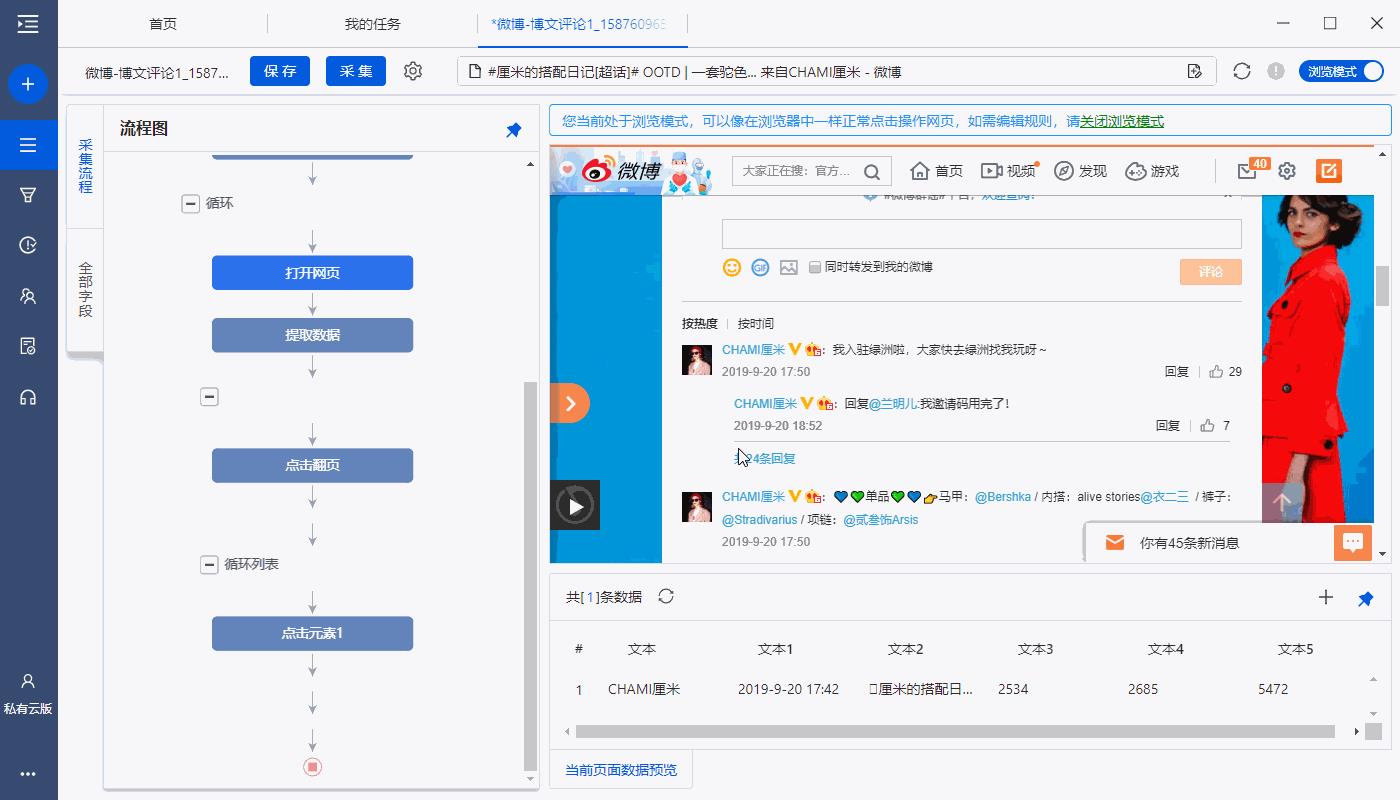
通过以下连续4步,采集所有评论列表数据:
1、选中页面上1个评论列表(注意一定要选中整个列表,包含所有所需字段)
2、在黄色操作提示框中,点击【选中子元素】
3、点击【选择全部】
4、点击【采集数据】
特别说明:
a. 经过以上连续4步,【循环-提取数据】创建完成。【循环】中的项,对应着页面上所有评论列表,【提取数据】中的字段,对应着每个评论列表中的字段。启动采集以后,八爪鱼就会按照循环中的顺序依次提取每个列表中的字段。
b. 为何通过以上4步,可建立【循环-提取数据】?详情点击查看 列表数据采集教程 。
2、编辑字段
进入【提取数据】设置页面,可删除多余字段,修改字段名,移动字段顺序等。
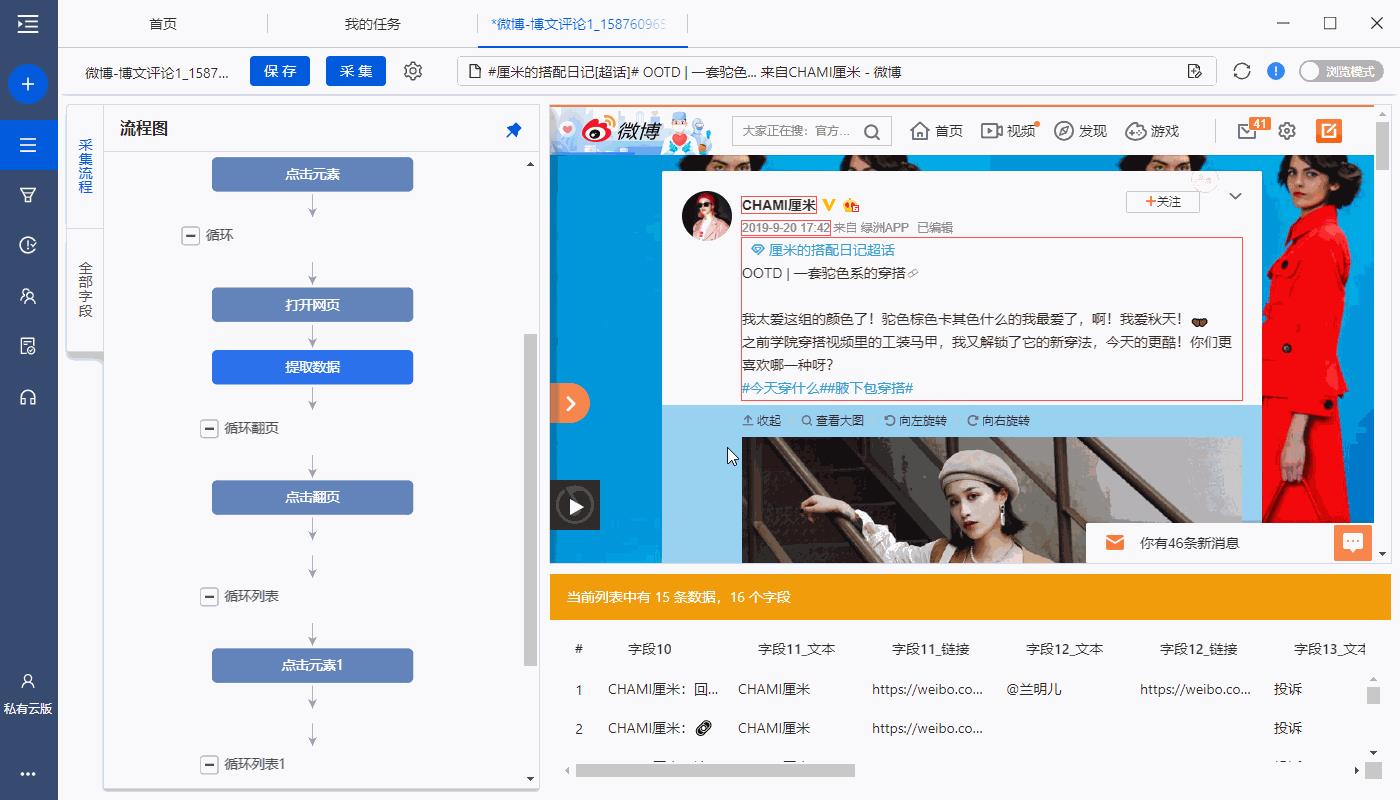
3、增加【主评论】字段
以上操作是采集的评论回复。增加一个【主评论】字段,将主评论与评论回复数据一一对应起来。
进入【提取数据】设置页面,点击【+】按钮,选择【添加固定字段】,点击保存。
点击【自定义字段】后的 按钮,勾选【相对于当前循环里的XPath】,输入XPath://…/…/…/…/preceding-sibling::div[@class=“WB_text”][1] ,然后保存。
点击【自定义字段】后的【…】按钮,选择【自定义抓取方式】,选择【抓取文本】。
修改字段名为【主评论】。
点击【应用】保存以上所有设置。
步骤九、启动采集
1、单击【采集】并【启动本地采集】。启动后八爪鱼开始自动采集数据。
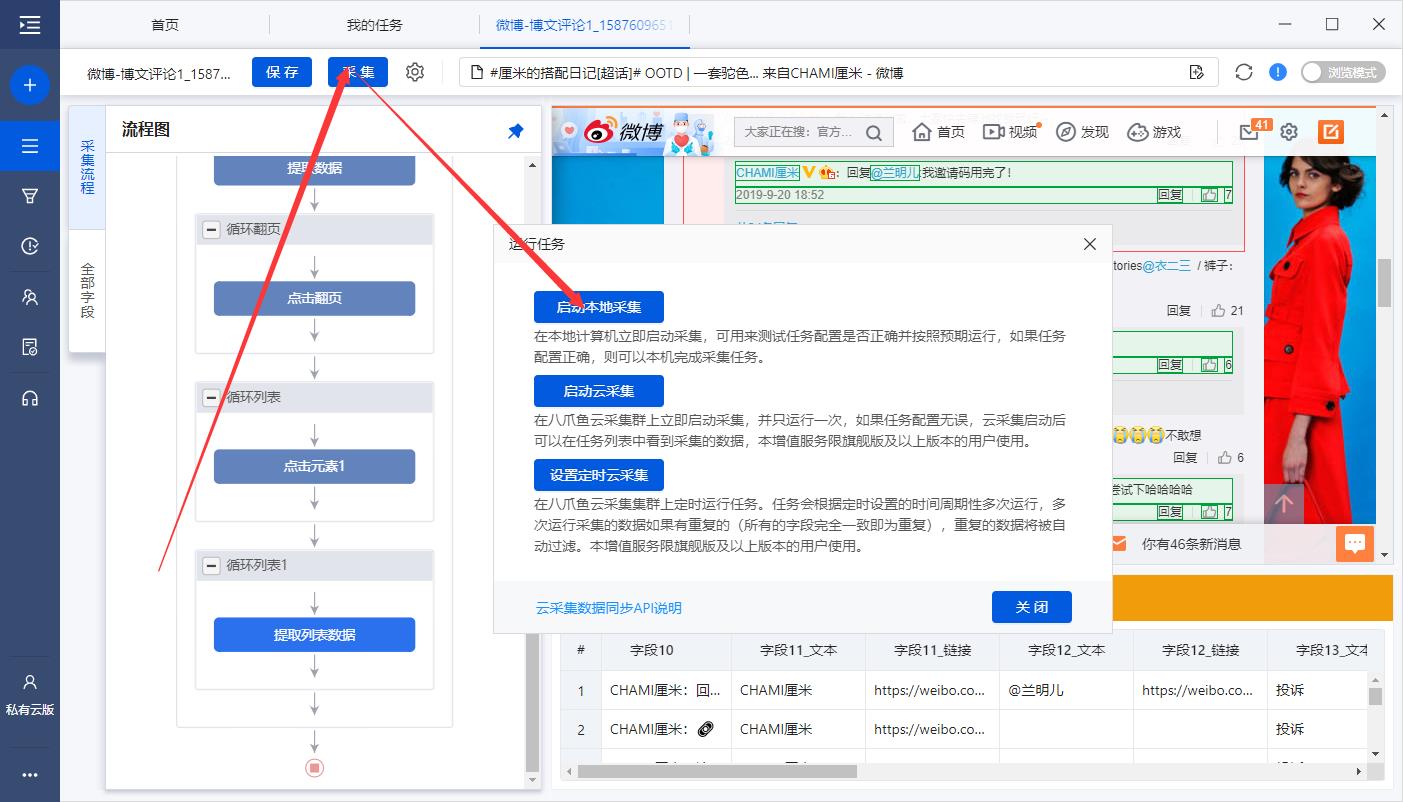
特别说明:
a.【本地采集】是使用自己的电脑进行采集,【云采集】是使用八爪鱼提供的云服务器采集,点击查看本地采集与云采集详解。
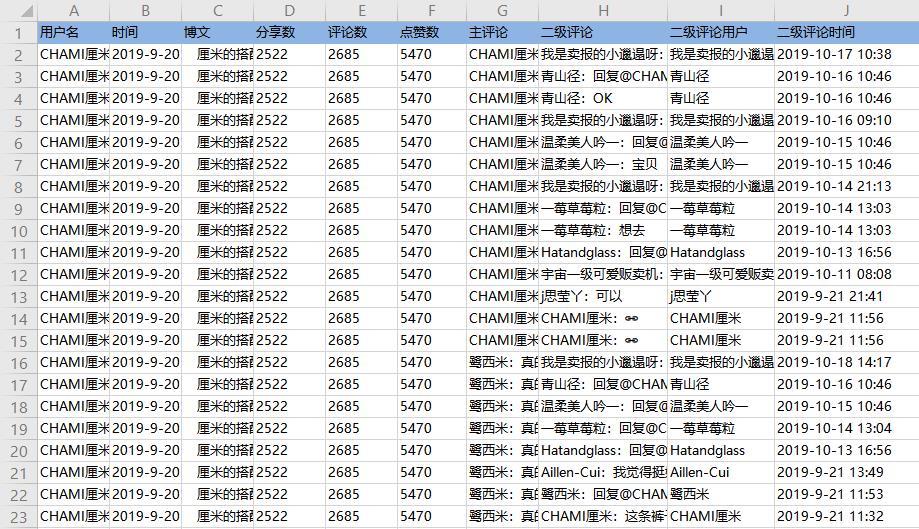
2、采集完成后,选择合适的导出方式导出数据。支持导出为Excel、CSV、HTML、数据库等。这里导出为Excel。数据示例:
以上是关于微博评论采集的主要内容,如果未能解决你的问题,请参考以下文章