机器翻译自动评价之BLEU详解-BLEU: a Method for Automatic Evaluation of Machine Translation
Posted 琥珀彩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器翻译自动评价之BLEU详解-BLEU: a Method for Automatic Evaluation of Machine Translation相关的知识,希望对你有一定的参考价值。
摘要翻译
对机器翻译进行人工评价是广泛的,但价格昂贵。人工评价可能要数月才能完成,并且要用不能够被重复使用的人工劳动。在此提出了一种快速、便宜且语言独立的自动机器翻译评价方法,它和人工评价高度相关,并且每次运行的边际成本很低。当需要快速或频繁的评估时,我们把这种方法作为有相关技术的人工评价的自动化替代。
一、本文针对什么问题开展研究,研究的意义如何;
人工评价机器翻译质量要衡量翻译的许多方面,包括充分性、通顺性和精确性。
对机器翻译进行人工评价存在许多问题,如:①耗时长,可能需要数周甚至数月时间才能完成;②价格昂贵;③在机器翻译系统开发时需要开发人员随时监控日常变化对系统的影响。
机器翻译的进步来自于评估后作出改进,因此,针对以上存在的问题,提出了一种快速的、廉价的、与语言无关的自动机器翻译评估方法,这种方法与人类评估紧密联系,每次的运行的边际成本低。在需要快速或频繁的评估时,这种方法可以替代人工评价。
二、本文提出了什么方法解决该问题;
本文提出了BLEU——一种自动评价翻译文本的方法来解决该问题。BLEU的中心思想是和专业人工翻译越接近就越好。根据一个度量的数值来衡量机器翻译与一个或多个参考人工翻译的接近程度来判断机器翻译的质量。因此,机器翻译评价体系需要两个要素, 一个“翻译接近度”数值指标和一个高质量的人工参考翻译语料库。
此处提到的接近度是仿造在语音识别领域使用非常成功的单词错误率,允许单词选择和单词顺序有合理范围内的差异。主要思想是使用与参考翻译匹配的可变长度短语的加权平均值。
- 基准BLEU指标
例1:
候选翻译1: It is a guide to action which ensures that the military always obeys the commands of the party.
候选翻译2: It is to insure the troops forever hearing the activity guidebook that party direct.
参考翻译1: It is a guide to action that ensures that the military will forever heed Party commands.
参考翻译2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
参考翻译3: It is the practical guide for the army always to heed the directions of the party.
对照三个参考翻译,相比起候选翻译2,候选翻译1出现了更多与参考翻译相同的词或者短语。并且相比之下,候选翻译2表现出的匹配少得多,范围也更小。故比较得出:候选翻译1的质量优于候选翻译2。
以上是基准BLEU指标的例子。总结:在基准BLEU指标中,将候选翻译的n-gram词与参考翻译的n-gram词进行比较,然后计算匹配的数量(计算匹配数时不考虑位置因素),匹配越多,候选翻译越好,为了简单起见,首先会关注计算unigram匹配数。
2.改进的n-gram精度
如果精度的计算仅是用在任何参考翻译中出现的候选翻译中的单词数量除以候选翻译中的单词总数,这样评判机器翻译的质量会出现某些句子翻译不合理,但是评价得分高的问题,因此改进的n-gram精度采用的方法为:收集所有候选n-gram计数和其相对应的最大匹配值,候选技术被其相应的最大匹配值截断、求和并除以候选翻译n-gram的总数。用公式表示为:


3.文本块的改进的n-gram精度
基本评价单位为句子,逐句匹配,为所有候选句子添加截断的n-gram计数,最后除以测试语料库中的候选n-gram数量,得到整个测试语料库的改进精度分数pn。
计算公式为:

4.组合改进后的n-gram精度
由于改进的n-gram精度随n的增加呈指数衰减,所以使用改进的精度的对数的加权平均值来解决指数衰减这一问题。BLEU使用具有均匀权重的平均对数,相当于使用改进的n-gram精度的几何平均值,通过实验可以得到与人工评判的最大n-gram的n为4。
5.句长
候选翻译不应过长或过短,如果单词出现的次数是合理的则奖励,如果单词出现的次数比再任何参考翻译中相应单词的次数都多则惩罚。
句子简短惩罚(Brevity Penalty):
引入句子简短惩罚是为了让高分候选翻译与参考翻译的长度、单词选择和单词顺序都匹配。其中,与候选翻译长度最接近的参考翻译的长度称为“最佳匹配长度”(best match length)。当候选翻译的长度和任一参考翻译的长度相同,此时惩罚值为1.0。例:某候选翻译长度为12,三个参考翻译的长度分别为12、15和17,则12为最佳匹配长度,且惩罚为1。在包含多个句子的文本块上,如果逐句计算简短惩罚然后取平均值,该文本框受到的惩罚会比较严苛,因此在文本块上的简短惩罚是对语料库中的每个候选句子的最佳匹配长度求和来计算测试语料库的有效参考长度r,选择简短惩罚为衰减指数r/c,其中c为候选翻译语料库的总长度,一次达到允许句子级别的一些自由。
6.BLEU计算公式

三、如何设计实验验证所提方法的效果,在什么语料上,采用什么评价指标,与什么相关解决方法对比?实验分析针对什么特殊情况进行描述,意义表现在什么方面?
- 仅用改进n-gram精度的评级系统实验一
实验目的:验证改进 n-gram精度能够区分非常好的翻译和糟糕的翻译。
实验内容:计算一个(好的)人工翻译和一个(差的)机器翻译系统所翻译的改进精度。
实验所用语料:127句源语言,每句源语言句子对应4个参考翻译。
实验结果:
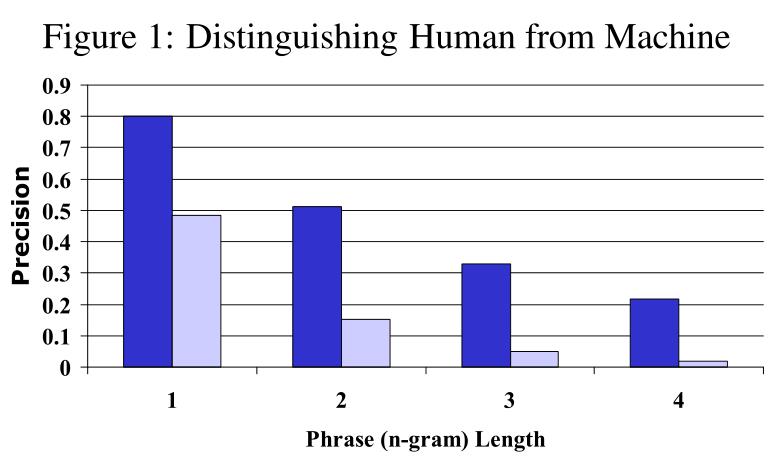
实验结果分析:能够很好区分人(高精度)和机器(低精度),当从unigram精度到4-gram精度时,差异更加明显。
2.仅用改进n-gram精度的评级系统实验二
实验内容:用改进n-gram精度的评级系统评价两个人类和三个商业翻译机器,对五个候选翻译进行评分。(H1、H2分别为人类1和人类2,S1,S2,S3为三个商业翻译机器)
实验所用语料:127句源语言,每句源语言句子对应2个专业参考人类翻译。
实验结果:
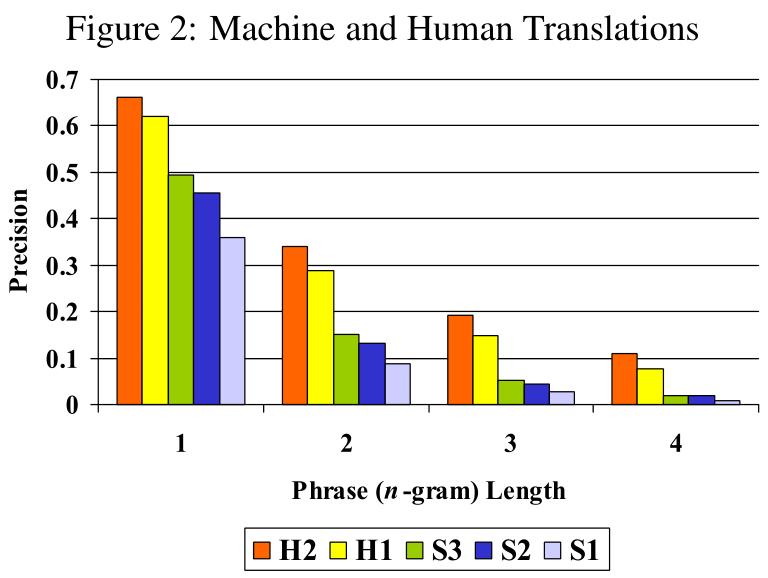
实验结果分析:从评分可以看出,机器翻译与人类翻译有较大差距,且机器翻译中s3始终优于s2始终优于s1。且用改进n-gram精度的评级系统评价出的优良顺序与人类评价得到的优良顺序相同。
3.验证BLEU评价可靠性的实验
实验目的:验证BLEU评价为有效的,证实BLEU评价具有普适性。
实验内容:用BLEU在500个句子上得到结果,再将测试语料库(此处为之前测试过的500个句子)分为20个块,分别计算每个块上的BLEU度量值,再依据这些度量值计算均值、方差和配对t-statistic。
实验所用语料:500个句子(40篇一般新闻故事)
实验结果:

实验结果分析:两组结果对于每个系统都是接近的,并且仅受小的有限块大小效应的影响。在参考翻译的选择上,随机选择4个参考翻译中的一个作为40个故事中每个故事的单一参考来模拟单一参考测试语料库,以此确保一定程度上的风格变化,在此基础上系统仍保持与多个参考翻译相同的排名顺序。该结果表明:对于不是来自同一个机器翻译的翻译内容可以使用单个参考翻译的大型测试语料库。
4.人工评价
在人工评价实验中,有两组人工评判人员,第一组为单语组,由10名母语为英语的人组成。 第二组为双语组,由10名为过去几年住在美国的以中文为母语的人组成。 这些人工评判人员皆不是专业翻译。 这些人员在500个语句的测试语料库中随机抽取的中文语句中评判5个标准系统。 实验将每个源句与其5个翻译中的每一个进行配对,总共250对中文源和英语翻译。 在网页中随机排序这些翻译对,以分散每个源句的五个翻译。 所有人工评价人员都使用同一个网页,并以相同的顺序查看句子对。 他们将每个翻译评分从1(非常差)到5(非常好)。 单语组只根据翻译的可读性和流畅性做出判断。
(1)单语组成对判断
实验内容:单语组评估人员评估结果,显示两个连续系统的得分和平均值的95%置信区间之间的平均差异。
实验结果:

实验结果分析:S2优于S1,S3优于S2和S1,H1明显优于S3,H2优于H1(H1的母语既不是英语也不是中文,H2的母语是英文),人工翻译人员之间的差异在95%以上是显著的。
(2)双语组成对判断
实验结果:
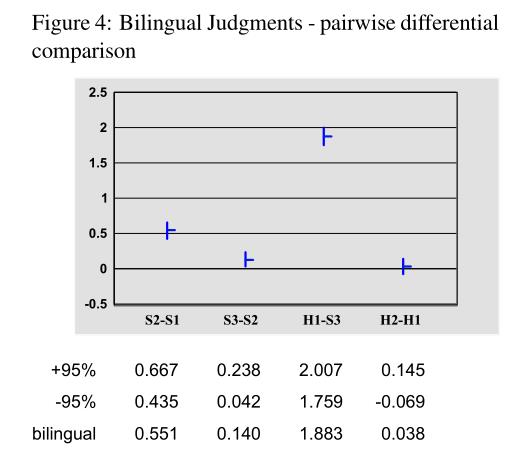
实验结果分析:双语组评估结果的成对差异比较可以看出他们判断人类翻译更接近(95%的置信度无法区分),表明双语者倾向于更多地关注翻译的充分性而不是流利性。
5.BLEU与人类评估相比较
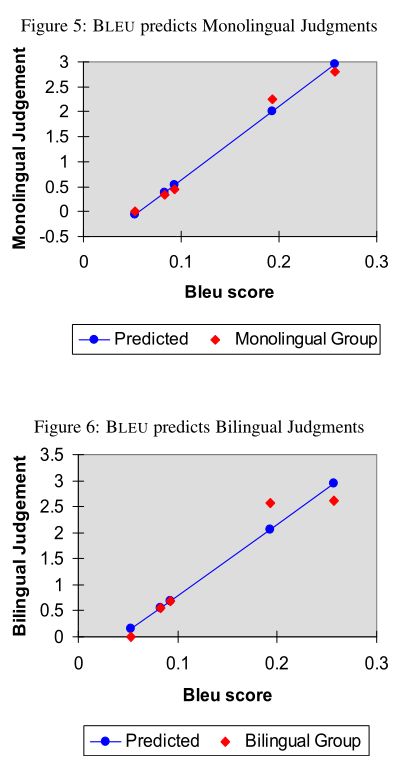
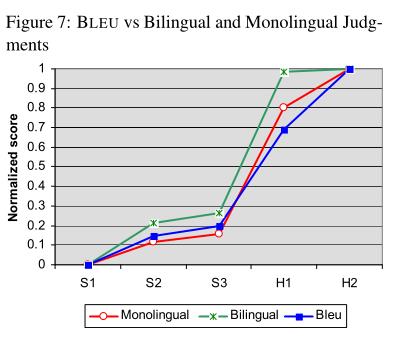
实验结果分析:蓝色为BLEU预测,红色点为人工评估结果。结果显示无论是与单语组人工评价比较还是和双语组人工评价相比,BLEU和人工评价结果均高度相似。三者综合比较可以看出,BLEU与单语组高度相关。另外,BLEU对S2和S3之间的小差异和S3和H1之间的大差异均较为准确。该数据也能看出机器翻译和人工翻译仍有较大差距。
四、前人对该问题如何解决,与它们相比,本文方法的创新点表现在什么地方;
前人用人工来评价翻译质量,与人工评价相比,BLEU最大的优点为在对于摘要评估或者自然语言生成相关任务的评估能够节省大量人力、时间的同时有较高的准确度。同时,BLEU在计算翻译准确度时使用简短惩罚来衡量句长带来的对评估结果的影响,考虑翻译的充分性、流畅性等在人工评估时也会考虑到的因素。
五、你认为本文有哪些不足,还有什么问题没有解决,或者没有清楚的解决,下一步可以针对什么问题进行研究?
1、召回率的问题:BLEU参考多个参考翻译,对于同一个源词,每个参考翻译可以使用不同的单词来翻译它,但是召回该单词的所有选择会导致翻译不好。在某些情况下,召回了更多单词(评价出的精度更高)的候选翻译可能并没有那么好。解决方案为参考翻译以发现同义词(相同概念的词)并计算,而非仅仅是单词的召回。
2、对于不同权重的词(如某些词在翻译中很重要,某些词相对没那么重要),BLEU给的权重是相同的,因此存在一些问题,如:BLEU评分相同的两个候选翻译在实际中存在其中一个参考翻译少了重点单词,而另一个参考翻译仅是少了普通单词,但由于BLEU本身计算方式问题,两者得分却是相同的。
3、与问题1类似的问题,BLEU在评价时并不考虑句子的实质意义,如果某候选翻译的某个单词在意义上完全没问题,但是该单词并没有出现在任何参考翻译中,此时,该翻译仍被视作无效的。然后语言本身就存在许多同义词,参考翻译无法完全涵盖所有同义词。
六、你认为本文的优点在什么地方,有新意?结构组织好?实验设计好?语言表达流畅、清晰、富有逻辑?有哪些好的表达或值得学习的地方需要记录下来经常翻看学习。
本文的优点为设计一种量化的方法来对翻译内容进行评估,大大提高评估效率,使用也极为便利,解决了前文提过的人工评价的缺点。
笔记:
- candidate translations 候选翻译
- phrase 短语
- notion 概念
- formalize 使形式化为…
- Intuitively 直观的
- Implausible 难以置信的
- adequacy 充分性
- fluency 流畅性
- corpus 语料库、文本集
- terminology术语
- It appears that …… 看来……
- To this end, 为此
- Proficiency 精通
- average logarithm 平均对数
- recall 召回率
- align 匹配
- syntax 语法
- penalize 惩罚
- best match length 最佳匹配长度
- finite 有限的
- monolingual 单语的
- bilingual 双语的
- pairwise 成对的
- Acknowledgments 鸣谢
- large gap 巨大的差距
- adapted to 适用于
- extent 范围
- In contrast 相比之下
- Identified 被识别的
- Cornerstone 基础
- Position-independent 与位置无关的
- General phenomenon 普遍现象
- Geometric mean 几何平均值
- To some extent 在某种程度上
- Uniform weight 统一的权重
- Human evaluations can take months to finish and involve human labor that can not be reused.We propose a method of automatic machine translation evaluation that is quick,inexpensive, and language-independent,that correlates highly with human evaluation, and that has little marginal cost per run.
译:人工评估可能需要几个月的时间才能完成,而且涉及到不能重复使用的人工劳动。我们提出了一种快速、廉价、语言独立的自动机器翻译评价方法,它与人类评价高度相关,而且每次运行的边际成本很小。(前者方法缺点+提出的方法概述与主要优点)
37.To judge the quality of a machine translation, one measures its closeness to one or more reference human translations accord-ing to a numerical metric. Thus, our MT evaluation system requires two ingredients.
译:为了判断机器翻译的质量,我们要根据一个数值度量来衡量它与一个或多个参考人工翻译的接近程度。因此,我们的机器翻译评价体系需要两个要素。
38、Figure 3 shows the mean difference between the scores of two consecutive systems and the 95% confidence interval about the mean. We see that S2 is quite a bit better than S1 (by a mean opinion score difference of 0.326 on the 5-point scale), while S3 is judged a little better (by 0.114).
译文:图3显示了两个连续系统的得分和平均值的95%置信区间之间的平均差异。 我们看到S2比S1好一点(通过5分制的平均意见得分差异为0.326),而S3被判断为更好(0.114)。
关于BLEU计算方法的补充:基于BLEU有一些变种算法,如BLEU+1方法,对所有的n元文法的匹配数目和出现次数加1,目的是衡量单个句子翻译质量的评测时,避免因某一元文法的匹配数目为0而导致BLEU公式中匹配率乘积为0,造成BLEU指标计算溢出的问题。
以上是关于机器翻译自动评价之BLEU详解-BLEU: a Method for Automatic Evaluation of Machine Translation的主要内容,如果未能解决你的问题,请参考以下文章