大数据数据倾斜问题及策略
Posted smallumbrella
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据数据倾斜问题及策略相关的知识,希望对你有一定的参考价值。
前言
数据倾斜是大数据开发中经常会遇到的问题,而且基本是面试中的必问考点,在面试中以及实际开发中,几乎天天面临的都是这个问题。本文是小鹏人工爬虫来的,希望能帮自己和我的读者们理解它!

正文
Hadoop中的数据倾斜
概述
在MapReduce编程模型中十分常见,用通俗易懂的话来说,数据倾斜无非就是大量的相同key被partition分配到一个分区里,造成了‘一个人累死,其他人闲死’的情况,这种情况是我们不能接受的,这也违背了并行计算的初衷,首先一个节点要承受着巨大的压力,而其他节点计算完毕后要一直等待这个忙碌的节点,也拖累了整体的计算时间,可以说效率是十分低下的。
现象
Hadoop能够进行对海量数据进行批处理的核心,在于它的分布式思想,也就是多台服务器(节点)组成集群,进行分布式的数据处理。
举个例子,假如要处理一个10亿数据的表格,我的集群由10个节点组成,一台服务器处理这10亿数据需要10个小时,现在我将10亿条数据平均的分配到不同的节点上,每台节点负责处理1亿条数据,那么原本需要10个小时完成的工作,现在只需要1个小时即可。
而以上只是理想情况,实际上分配到每台节点的数据量并不是均匀的,当大量的数据分配到某一个节点时(假设5亿条),那么原本只需要1小时完成的工作,变成了其中9个节点不到1小时就完成了工作,而分配到了5亿数据的节点,花了5个小时才完成,而它的完成才意味着整个工作的结束。
从最终结果来看,就是这个处理10亿数据的任务,集群花了5个小时才最终得出结果。大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢,这种情况就是发生了数据倾斜。
这里如果详细的看日志或者和监控界面的话会发现:
1. 有一个多几个reduce卡住
2. 各种container报错OOM
3. 读写的数据量极大,至少远远超过其它正常的reduce
4. 伴随着数据倾斜,会出现任务被kill等各种诡异的表现。
发生的原因
正常的数据分布理论上都是倾斜的,就是我们所说的20-80原理:80%的财富集中在20%的人手中, 80%的用户只使用20%的功能 , 20%的用户贡献了80%的访问量 , 不同的数据字段可能的数据倾斜一般有两种情况:
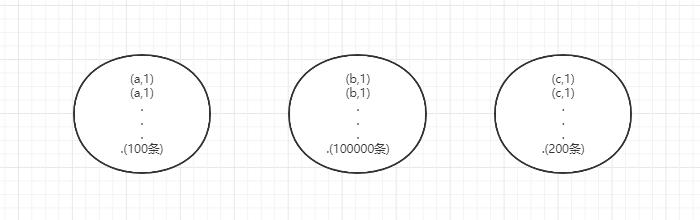
- 唯一值(key)非常少,极少数值有非常多的记录值(唯一值少于几千)
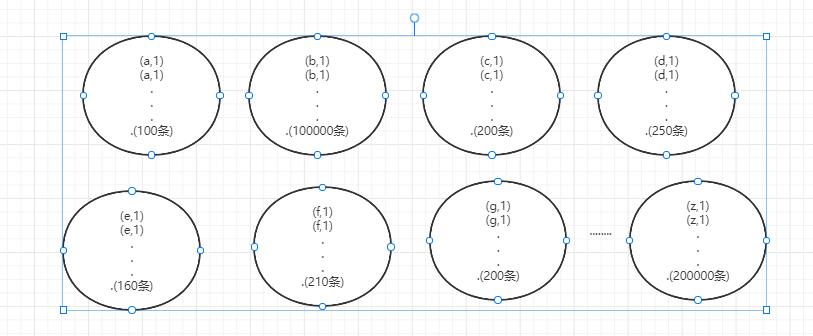
- 唯一值(key)比较多,这个字段的某些值有远远多于其他值的记录数,但是它的占比也小于百分之一或千分之一
可以理解为:
- 数据频率倾斜——某一个区域的数据量要远远大于其他区域。
- 数据大小倾斜——部分记录的大小远远大于平均值。
第①种情况:
第②种情况:
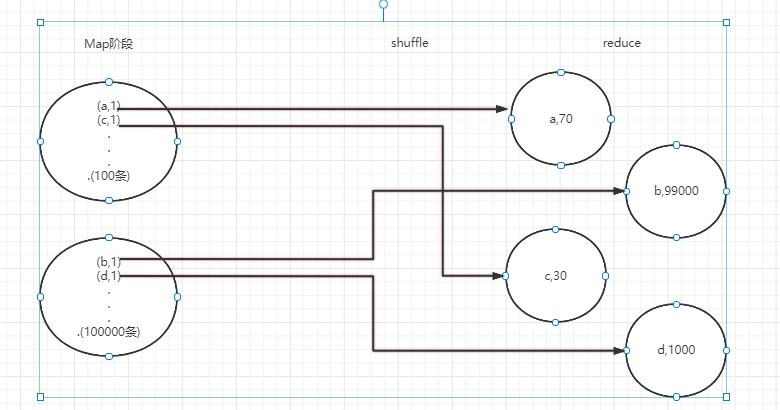
无论是MR还是Spark任务进行计算的时候,都会触发Shuffle动作,一旦触发,所有相同key的值就会拉到一个或几个节点上,就容易发生单个节点处理数据量爆增的情况。
Shuffle的中文含义是“洗牌”,通过下面这张图,你能了解到它对数据进行了什么样的处理。
导致数据倾斜发生,往往是以下几种情况
- key分布不均匀
1、某些key的数量过于集中,存在大量相同值的数据
2、存在大量异常值或空值。
- 业务数据本身的特性
例如某个分公司或某个城市订单量大幅提升几十倍甚至几百倍,对该城市的订单统计聚合时,容易发生数据倾斜。
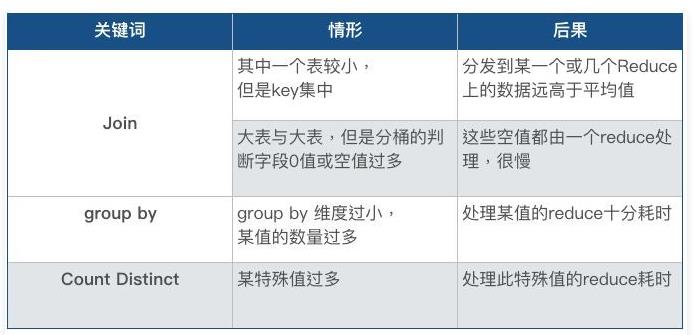
- 某些SQL语句本身就有数据倾斜
两个表中关联字段存在大量空值,或是关联字段的数据不统一,例如在A表中值是大写,B表中值是小写等情况。具体看下图:
大佬们的策略
- 首先要了解数据分布,自己动手解决数据倾斜问题是个不错的选择;
- 增加jvm(Java Virtual Machine:Java虚拟机)内存,这适用于情况①,这种情况下,往往只能通过硬件的手段来进行调优,增加jvm内存可以显著的提高运行效率;
- 增加reduce的个数,这适用于情况②,这种情况下最容易造成的结果就是大量相同key被partition到一个分区,从而一个reduce执行了大量的工作,通过增加reduce个数减少单个reduceTask工作量;
- 重新设计key,有一种方案是在map阶段时给key加上一个随机数,有了随机数的key就不会被大量的分配到同一节点,待到reduce后再把随机数去掉即可,比如情况1①中的a特别多,那么我们给a前加上0-100的随机数前缀,可以使他们分成一百份;
- 使用combiner合并。combiner是在map阶段,reduce之前的一个中间阶段,在这个阶段可以选择性的把大量的相同key数据先进行一个合并,可以看做是local reduce,然后再交给reduce来处理,减轻了map端向reduce端发送的数据量(减轻了网络带宽),也减轻了map端和reduce端中间的shuffle阶段的数据拉取数量(本地化磁盘IO速率);
- 设置合理的map reduce的task数,能有效提升性能。(比如,10w+级别的计算,用160个reduce,那是相当的浪费,1个足够);
- 数据量较大的情况下,慎用count(distinct),count(distinct)容易产生倾斜问题;
- hive.groupby.skewindata=true 有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
结言
哇这就是大佬吗?爱了爱了!合格的大数据开发工程师从解决数据倾斜开始吧,冲冲冲!
附上参考博文链接:https://zhuanlan.zhihu.com/p/332368318

以上是关于大数据数据倾斜问题及策略的主要内容,如果未能解决你的问题,请参考以下文章