差分隐私?联邦学习?安全多方计算?它们之间是什么关系?
Posted 粥粥粥少女的拧发条鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了差分隐私?联邦学习?安全多方计算?它们之间是什么关系?相关的知识,希望对你有一定的参考价值。
写在前面的话
本文纯属个人笔记,仅供参考。
隐私计算
什么是隐私计算?
隐私计算(Privacy-preserving computation)是指在保证数据提供方不泄露原始数据的前提下,对数据进行分析计算的一系列信息技术,保障数据在流通与融合过程中的“可用不可见”。
简单来说就是一个技术体系,其目的是实现数据可用不可见。下面是隐私计算流程图。
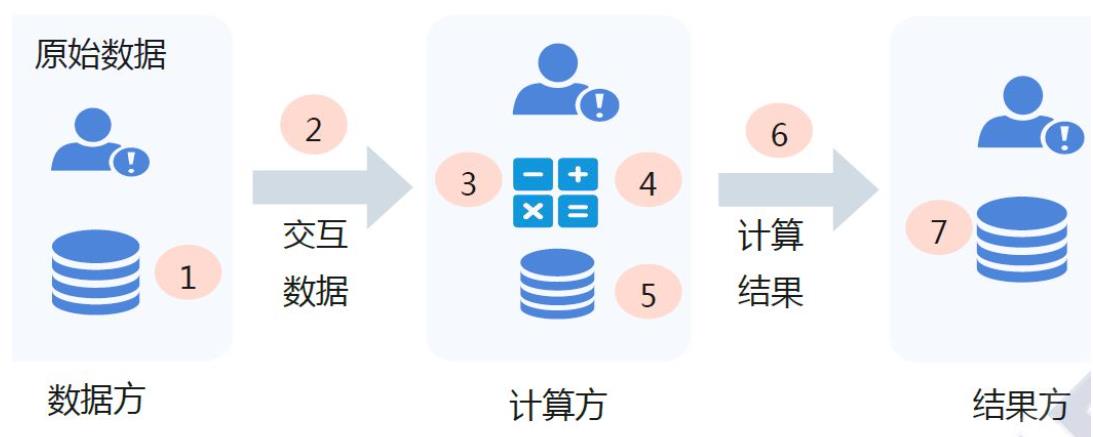
数据方:提供数据的组织或个人。
计算方:提供算力的组织或个人。
结果方:接收计算结果的组织或个人。
隐私保护计算的目标是在完成计算任务的基础上,实现数据计算过程和数据计算结果的隐私保护。数据计算过程的隐私保护指参与方在整个计算过程中难以得到除计算结果以外的额外信息,数据计算结果的隐私保护指参与方难以基于计算结果逆推原始输入数据和隐私信息。
隐私计算发展趋势
1、多方安全计算:基于密码学的隐私计算技术;
2、联邦学习:人工智能与隐私保护技术融合衍生的技术;
3、可信执行技术(TEE):代表的基于可信硬件的隐私计算技术。
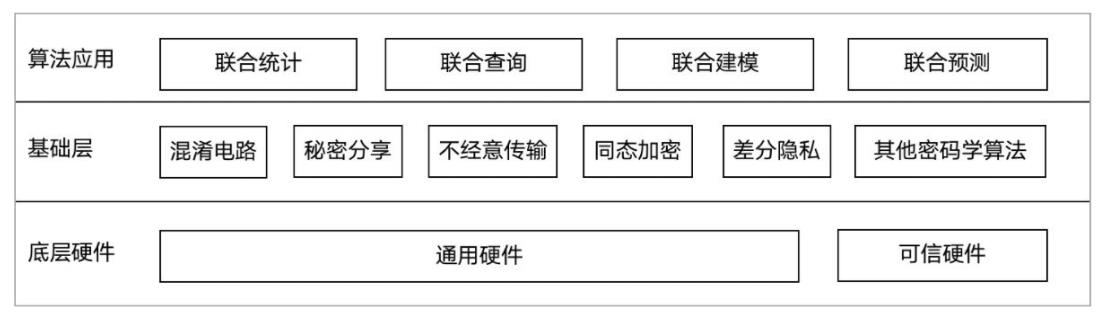
隐私计算的技术
混淆电路、秘密分享、不经意传输等作为底层密码学技术,同态加密、零知识证明、差分隐私等作为辅助技术的相对成熟的技术体系。
隐私计算体系结构
底层硬件角度:
1、多方安全计算与联邦学习通常从软件层面设计安全框架,以通用硬件作为底层基础架构。
2、可信执行环境则是以可信硬件为底层技术实现的隐私计算方案。
算法构造角度:
1、多方安全计算技术基于各类基础密码学工具设计不同的安全协议。
2、联邦学习除可将多方安全计算协议作为其隐私保护的技术支撑外,基于噪声扰动的差分隐私技术也广泛应用于联邦学习框架中
3、可信执行环境通常与一些密码学算法、安全协议相结合为多方数据提供保护隐私的安全计算。
算法应用角度:
1、联邦学习技术方案主要应用于联合建模和预测场景中。
2、多方安全计算和可信执行环境则可作为更加通用的技术方案,可设计用于联合统计、联合查询、联合建模及联合预测等诸多场景。
安全多方计算
注:安全多方计算可以去看看《阿里巴巴集团安全总监洪澄:安全多方计算技术及其在阿里巴巴的应用》有助于理解安全多方计算。
优点:
1、基于密码学安全,其安全性有严格密码理论证明。
2、同时计算准确度高。
3、支持可编程通用计算。
缺点:
1、密码学操作产生计算性能问题,运算时延以及参与方数量增加也会导致应用无法落地等相关问题。
2、传统安全问题无法解决,如访问控制、传输安全等。
3、不同技术间的加密数据不能互通造成的新的数据孤岛问题。
联邦学习
优点:
1、解决训练阶段数据特征单一的问题,从而获得一个性能更好的、优于利用自己本身数据集所训练出的模型
2、算力成本压力小。
缺点:
1、安全问题,当神经网络的模型较大时不会从头开始编码,而是用开源的基础模型,存在病毒植入的安全问题。以及传输的梯度和权重可能被逆推泄露信息。参与方不一定可行。
2、通信效率问题。分布式参与节点计算能力不一致、网络连接状态不稳定、数据通信非独立分布等现实因素。
可行执行环境
优点:
1、通用和高效的优势(支持通用计算框架和应用,计算性能高)。
2、可单独用于隐私计算,也可以与其他技术结合在一起来保护隐私(对于安全可信云计算、大规模数据保密协作、隐私保护的深度学习等涉及大数据、高性能、通用隐私计算的场景,是重要的技术手段)。
缺点:
1、TEE 信任链跟CPU 厂商绑定,目前硬件技术被掌握在英特尔、高通、ARM等少数外国核心供应商中,从而影响到机密计算技术的可信度。
2、实现在理论上存在侧信道攻击的可能性,因为TEE与其它非可信执行环境空间共享了大量的系统资源。
差分隐私
优点:
1、严格的数据理论,能够实现数据资源的最大利用
2、在多方安全计算中,采用可计算的差分隐私能大大降低多方安全计算的计算复杂度和通讯量。
缺点:
1、噪声回对模型可用性和准确性造成一定程度影响(对于准确度要求较高的场景如人脸识别、金融风险计量,目前无法大规模应用该项技术)。
2、差分隐私保护目标是计算结果而不是计算过程(以机器学习建模为例,差分隐私可以在建模结果上加入噪声,保证攻击者难以从建模结果反推出样本信息,但差分隐私依然需要计算方显式的访问训练数据,因此没有保护建模过程,因此与前面三种方案有根本不同)。
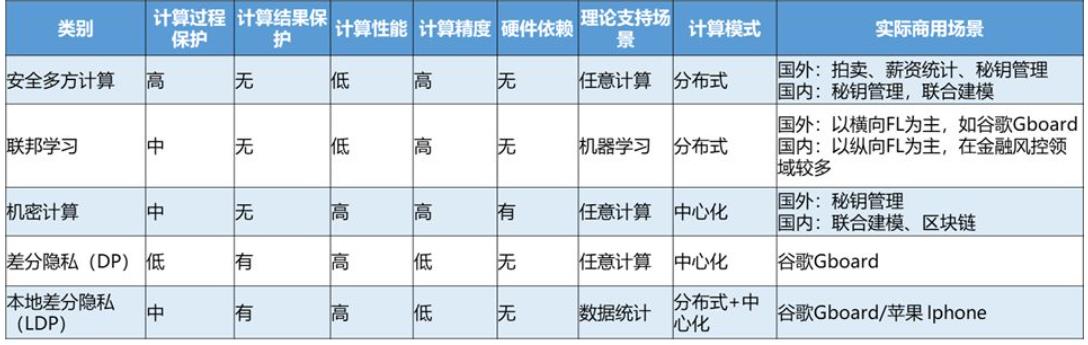
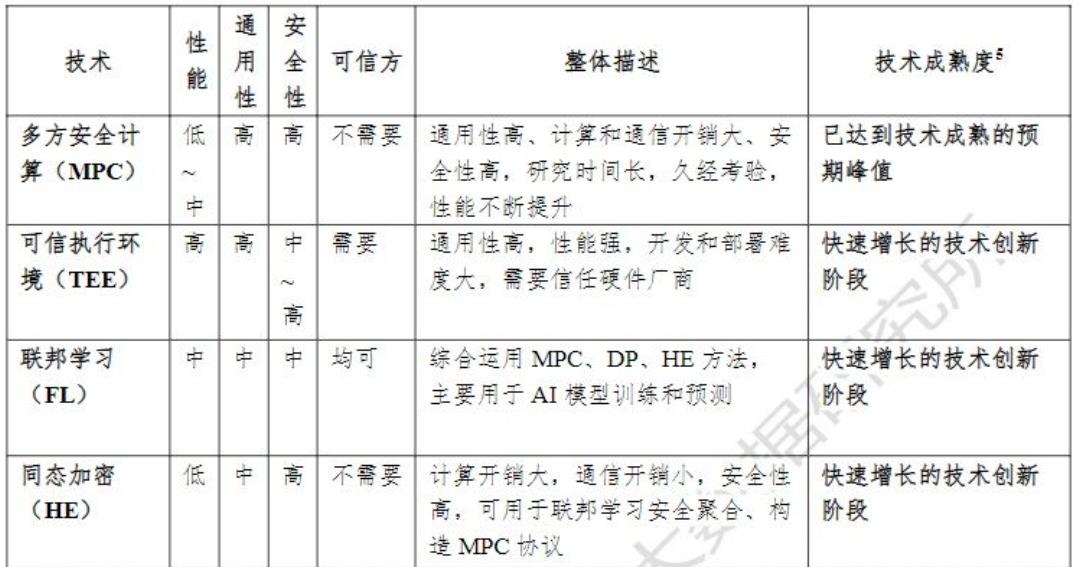
比较

应用场景
联合营销:跨行业数据融合重构用户画像
联合风控:引入外部数据优化金融风控模型
智慧医疗:数据互通发挥医学数据价值
电子政务:促进政务数据安全共享开放
发展趋势
国外
从隐私计算本身的发展历程来看,国外企业布局隐私计算较早。早在2008年第一家专攻多方安全计算解决方案的技术厂商Partisia就已在丹麦成立,为商务合同、加密拍卖等场景提供安全方案科技巨头中,微软从2011年开始深入研究多方安全计算、谷歌在全球率先提出联邦学习的概念、Intel打造SGX成为绝大部分可信执行环境实现方案的底座,均已成为各条技术路线主要的领路人。其他如IBM致力于将同态加密与云服务结合,帮助用户数据安全上云;Facebook则是专攻基于隐私计算的机器学习。创业公司中,Sharemind、Privitar致力于搭建自研的多方安全计算平台;Duality基于密码学开发的SecurePlus平台在新冠疫情中支撑了医学机构进行病毒基因分析。此外,AI公司Zama、区块链公司Enigma等均在推进多方安全计算、同态加密等方向的技术研发。但从总体的应用场景来看,目前国外隐私计算项目中的很大一部分都是面向区块链和加密虚拟货币的场景。如美国的Unbound Tech和丹麦的Sepior均集中于将多方安全计算应用于分布式密钥管理领域。
国内
跟国外相比,我国企业开始布局隐私计算的时间要更晚,大致在2016年之后才开始出现独立的隐私计算商业项目,但国内产业化发展的速度较快。伴随着各行业企业对合规数据流通的需求日益强烈,越来越多的行业客户开始愿意进行尝试,整体行业从概念验证到全面实施趋势明显。根据调研,目前超过81%的隐私计算产品进入了试点部署或实施阶段。
1)从技术路线上看,多方安全计算的复杂度高、开发难度大,龙头企业多致力于此,力图打造以多方安全计算为底座的数据流通基础设施,26%的企业布局了这类技术方案
2)可信执行环境对于硬件的局限及国外芯片的强依赖,使得其在国内的产品选型相对较少,提供此类方案的企业占比约为21%,较集中于互联网大厂和部分初创企业,但目前已出现一些技术企业与芯片企业在国产化硬件研发上的合作探索;
3)对于联邦学习,由于机器学习类应用需求的突出,且有较成熟的开源社区为基础,开发难度相对轻松,因而,运营商、金融科技公司等自营业务需求方大多专注在基于联邦学习的隐私计算产品化中,提供联邦学习方案的企业数量占比约为52%。此外,由于各类技术方案各有优势,面对用户的不同应用需求,21%的企业提供多种技术方案供用户选择。——《隐私计算白皮书》
发展展望
可用性提升:
1、算法优化(算法加速,减低子模块耦合度,流程重新编排,减少节点通信次数实现通信加速,底层语言实现代码加速)。
2、硬件加速。
多元技术融合:
1、联邦学习与多方安全计算融合能够满足对等网络无可信第三方的联合建模应用需求。
2、联邦学习与差分隐私融合能够增强对梯度参数的保护程度,进一步防止中间梯度信息泄露。
3、联邦学习与可信执行环境融合能够提升隐私数据或模型的安全等级等。
4、隐私计算与区块链等其他领域技术的融合拓展应用边界。
应用落地:
1、完善的隐私计算相关标准有助于产品规范。
2、成熟的检测和验证手段有助于产品落地应用。
多方生态融合:
1、法规体系需加速完善。
2、应用体系需进一步加强。
3、开源协同加速隐私计算技术迭代,技术开源。
总结
回到本博客的标题,差分隐私与其他隐私计算的联系是什么?
1、差分隐私是隐私计算中技术的一种,与同态加密,数据脱敏,混淆电路等算法同级别。每种技术侧重点不同,前面也提到了,差分隐私更关注结果,对于隐私计算的过程没有保护。
2、安全多方计算,联邦学习都可以用差分隐私,它们相当于是隐私计算的一个子集,差分隐私是这个子集中的一个元素,或者说是子集的子集。
3、安全多方计算在我看来更像是一个协议,可被用于联邦学习中。联邦学习更像是一个隐私计算的框架,可用其他技术,包括TEE。在隐私计算体系结构中我感觉算法应用基本都是描述联邦学习的。
补充
差分隐私来自于密码学的安全语义:

即对于任意等长的消息m,只要这个m属于消息空间(就是说用这个加密算法可以加密m),那么用加密密钥k加密后,加密结果“看起来都一样”,没法看出来这是从m,还是从其他什么消息加密得来的。
差分隐私用随机化的方法实现了这个安全语义,更直白的说是用了加噪的方法。不管是随机响应还是拉普拉斯机制都对原始结果进行扰动,可以理解为密码学中的加密。只是差分隐私没有解密的方法,或者说是没有解密成明文的方法,但是可以通过概率估计的方法满足需求。
以上是关于差分隐私?联邦学习?安全多方计算?它们之间是什么关系?的主要内容,如果未能解决你的问题,请参考以下文章