MySQL03 Checkpoint机制
Posted 代码被吃掉了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL03 Checkpoint机制相关的知识,希望对你有一定的参考价值。
Checkpoint机制
一、思维导图
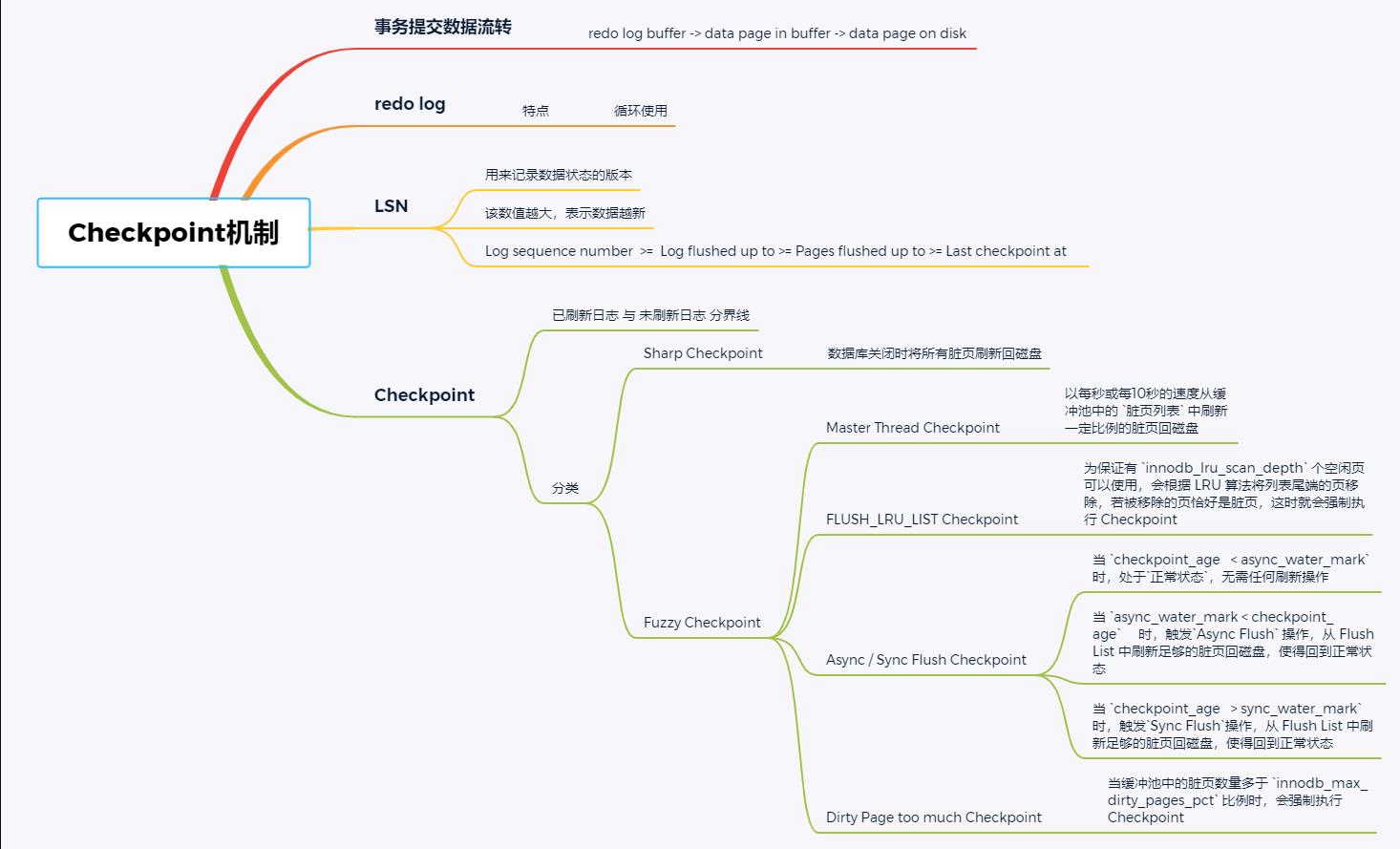
二、笔记
1. 脏页的产生与处理
缓冲池是用于平衡 CPU 和磁盘之间的速度差的,故,当页的操作也是在缓冲池中进行的,当一个DML语句发生后,例如 Update 或 Delete 语句改变了页中的数据记录,此时,页中的数据记录与磁盘上面的数据记录出现了不一致,为了保持这种一致性,数据库需要将新版本的数据页刷新至磁盘上。
思考问题:
- 如果每一次数据页都发生了改变都进行一次磁盘的读写,这样会导致大量的磁盘IO,给数据库造成极大的压力,导致数据库性能变差,怎么办?
- 如果在将数据页写入磁盘的过程中,数据库异常关闭,导致内存中的数据页丢失,那么数据就无法被恢复了,怎么办?
为了避免以上两种情况的出现,InnoDB 采取 Write Ahead Log 策略
2. Write Ahead Log 策略
Write Ahead Log 策略:即当事务提交的时候,先将改动写入重做日志(redo log)中,再修改页数据,再以一定的频率将脏页刷新至磁盘上。
由于改动被记录在日志中,所以有效的避免了数据丢失的问题,redo log是事务特性ACID中D(持久性)的实现方式
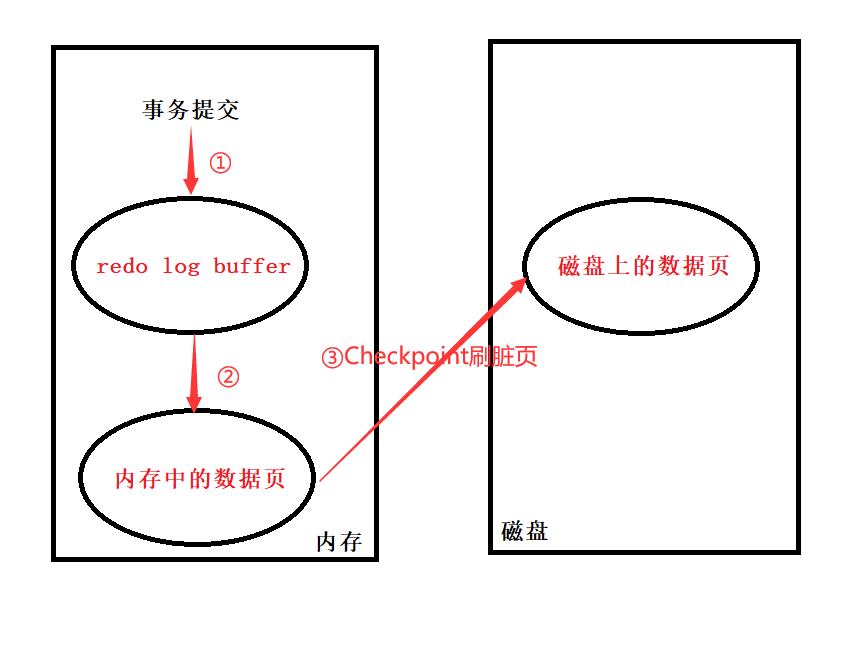
思考问题:
- 当出现宕机的时候,我们应该从重做日志的哪个地方进行恢复嘞?直接将所有的重做日志恢复一遍嘛?
显然将所有重做日志都恢复一遍这样是不可取的,如果重做日志内容非常的多,这要就会导致数据库的恢复时间过长,InnoDB中有一个名为 checkpoint的技术来解决该问题
3. Checkpoint
checkpoint标志着redo log最新写入位置.
-
当数据库发生宕机时,数据库并不需要重新把所有的
redo log做一遍,因为checkpoint之前的页都已经刷新回磁盘了,只需要将checkpoint之后的重做日志进行恢复即可,这样大大缩短了数据库恢复时间。 -
当数据库中的缓冲池不够用时,根据
LRU算法会置换最近最少使用的页,若该页是脏页,则会强制执行checkpoint,将脏页刷新至磁盘中
重做日志被设计成可以循环使用的,并不是让其无限增大,新的日志会覆盖以往不再需要的日志,不再需要是指数据库宕机恢复不需要的那部分日志,如果没有不再需要的日志用来覆盖,那么必须强制执行产生Checkpoint,将缓冲池中的页至少刷新到当前重做日志的位置,以这样的方式产生一部分不再需要的日志以供覆盖。
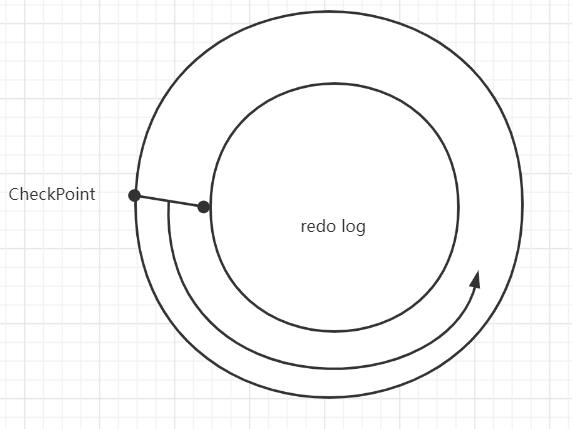
4. Log Sequence Number
4.1 LSN概念
对于 InnoDB 存储引擎而言,是通过 LSN ( Log Sequence Number ) 来标记数据状态的版本的,LSN是一个8字节的数字
- 每个页有LSN,重做日志有LSN,Checkpoint也有LSN
mysql [(none)]> show engine innodb status\\G;
---
LOG
---
Log sequence number 4093975
Log flushed up to 4093975
Pages flushed up to 4093975
Last checkpoint at 4093966
0 pending log flushes, 0 pending chkp writes
12 log i/o's done, 0.00 log i/o's/second
Log sequence number:指当前缓冲区上的 redo log buffer 中的 LSN
Log flushed up to:指刷磁盘上的 redo log file 中的 LSN
Pages flushed up to:指已经刷到磁盘数据页上的 LSN
Last checkpoint at:上一次检查点的 LSN
4.2 LSN 变化解析
- 事务提交 LSN 变化顺序
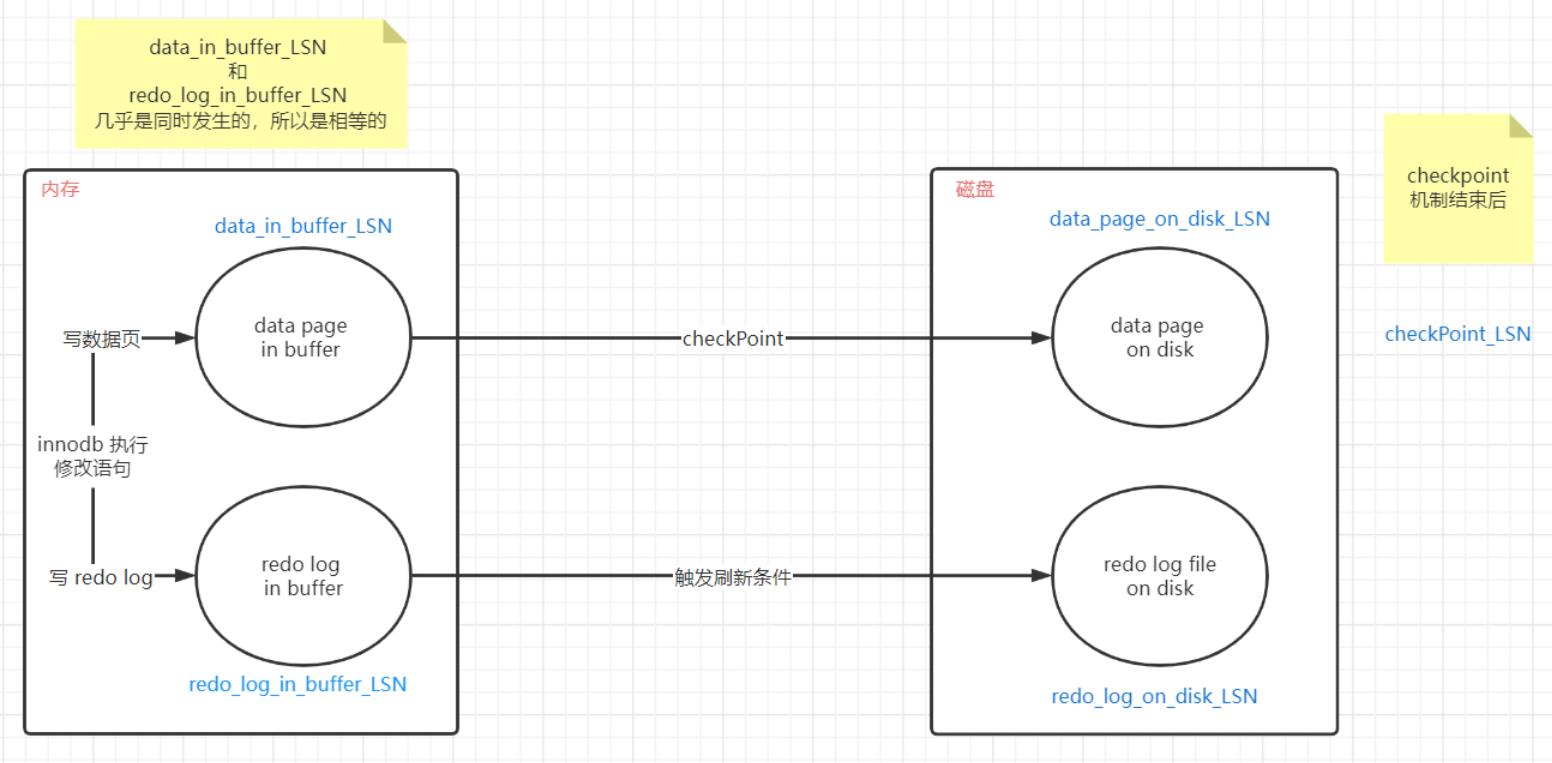
- 详解事务执行过程中的 LSN 流转变化

事务起始点:所有的 LSN 都初始化为 1
①:经过一个 update 语句,同时更新 data_page_in_buffer_lsn 和 redo_log_in_buffer_lsn 两个LSN 为 2
②:经过一个 delete 语句,并且此时距离事务起始点经过了一秒触发
重做日志刷盘操作,同时更新 data_page_in_buffer_lsn 和 redo_log_in_buffer_lsn 和 redo_log_on_disk_lsn 三个LSN为3③:经过一个 update 语句,同时更新 data_page_in_buffer_lsn 和 redo_log_in_buffer_lsn 两个LSN 为 4
④:此时出现 Checkpoint 机制,将所有 LSN 都更新至最新状态 4
⑤:此时距离事务起始点经过了两秒触发
重做日志刷盘操作,由于刚刚经过Checkpoint刷盘,所有LSN都是最新状态,故无需做出任何改变⑥:经过一个 insert 语句,同时更新 data_page_in_buffer_lsn 和 redo_log_in_buffer_lsn 两个LSN 为 5
⑦:此节点事务提交结束,
事务提交动作,会触发日志刷盘操作,但是不会触发数据刷盘操作,故更新 redo_log_on_disk_lsn 为 5⑧:此时出现 Checkpoint 机制,将所有 LSN 都更新至最新状态 5
5. Checkpoint分类
5.1 Sharp Checkpoint
Sharp Checkpoint发生在数据库关闭时将所有的脏页都刷新回磁盘- 由参数
innodb_fast_shutdown控制
MySQL [(none)]> show variables like 'innodb_fast_shutdown'\\G;
*************************** 1. row ***************************
Variable_name: innodb_fast_shutdown
Value: 1
由于Sharp Checkpoint 是将所有的脏页都刷新至磁盘中,所以如果在数据库运行时也使用该种机制,会导致数据库性能手打影响,故在数据库运行时使用 Fuzzy Checkpoint 机制进行脏页的刷新
5.2 Fuzzy Checkpoint
Fuzzy Checkpoint 是数据库在运行时,在一定的触发条件下,刷新一定的比例的脏页进磁盘中,并且刷新的过程是异步的。
有以下四种情况的 Fuzzy Checkpoint :
- Master Thread Checkpoint
在 Master Thread 执行的 Loop 中,以每秒或每10秒的速度从缓冲池中的 脏页列表 中刷新一定比例的脏页回磁盘,这个过程是异步的,并不会阻塞用户查询线程。
- FLUSH_LRU_LIST Checkpoint
InnoDB 需要保证差不多有 innodb_lru_scan_depth 个空闲页可以使用,在 MySQL 5.6 版本之后,在 Page Cleaner 线程(并不会阻塞用户的查询线程哦)中会进行 LRU 列表空闲页数量检查,若不够 innodb_lru_scan_depth 个空闲页,那么 InnoDB 存储引擎会根据 LRU 算法将列表尾端的页移除,若被移除的页恰好是脏页,这时就会强制执行 Checkpoint
MySQL [(none)]> show variables like 'innodb_lru_scan_depth'\\G;
*************************** 1. row ***************************
Variable_name: innodb_lru_scan_depth
Value: 1024
- Async / Sync Flush Checkpoint
该种 Checkpoint 出现在重做日志不够用的情况下,这时需要强制将一些脏页列表中的脏页刷新回磁盘中。
若将已经写入到重做日志的 LSN 标记为 redo_lsn,将已经刷新会磁盘最新页的 LSN 标记为 checkpoint_lsn
则定义: checkpoint_age = redo_lsn - checkpoint_lsn
再定义:
async_water_mark = 75% * total_redo_log_file_size
sync_water_mark = 90% * total_redo_log_file_size
查看重做日志总大小
MySQL [(none)]> SELECT @@innodb_log_file_size/1024/1024;
+----------------------------------+
| @@innodb_log_file_size/1024/1024 |
+----------------------------------+
| 48.00000000 |
+----------------------------------+
1 row in set (0.00 sec)
- 当
checkpoint_age < async_water_mark时,处于正常状态,无需任何刷新操作- 当
async_water_mark < checkpoint_age时,触发Async Flush操作,从 Flush List 中刷新足够的脏页回磁盘,使得回到正常状态- 当
checkpoint_age > sync_water_mark时,触发Sync Flush操作,从 Flush List 中刷新足够的脏页回磁盘,使得回到正常状态

使用Async / Sync Flush Checkpoint是为了保证重做日志文件的循环可用性
- Dirty Page too much Checkpoint
当缓冲池中的脏页数量多于 innodb_max_dirty_pages_pct 比例时,会强制执行 Checkpoint,刷新一部分脏页进磁盘中
MySQL [(none)]> show variables like 'innodb_max_dirty_pages_pct'\\G;
*************************** 1. row ***************************
Variable_name: innodb_max_dirty_pages_pct
Value: 75.000000
以上是关于MySQL03 Checkpoint机制的主要内容,如果未能解决你的问题,请参考以下文章