Comparison of Big Data OLAP DB : ClickHouse, Druid, and Pinot
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Comparison of Big Data OLAP DB : ClickHouse, Druid, and Pinot相关的知识,希望对你有一定的参考价值。
In this post I want to compare ClickHouse, Druid, and Pinot, the three open source data stores that run analytical queries over big volumes of data with interactive latencies.
Warning: this post is pretty big, you may want to read just the “Summary” section in the end.
Sources of Information
I learned the implementation details of ClickHouse from Alexey Zatelepin, one of the core developers. The best material available in English is the last four sections of this documentation page, but it’s pretty scarce.
I’m a committer to Druid, but I don’t have a vested interest in this system (in fact, I’m probably going to stop being involved in it’s development soon), so readers could expect me to be fairly objective about Druid.
Everything that I write in this post about Pinot is based on the Architecture page in Pinot’s wiki and the other wiki pages in the “Design Docs” section, that were last updated in June 2017, more than half a year ago.
This post was also reviewed Alexey Zatelepin and Vitaliy Lyudvichenko (developers of ClickHouse), Gian Merlino (PMC member and the most active developer of Druid), Kishore Gopalakrishna (architect of Pinot) and Jean-François Im (developer of Pinot). Thanks to the reviewers.
Similarities between the Systems
Coupled Data and Compute
All ClickHouse, Druid and Pinot are fundamentally similar because they store data and do query processing on the same nodes, departing from the decoupled BigQuery architecture. Recently I’ve described some inherent issues with the coupled architecture in the case of Druid (1, 2). There is no open source equivalent to BigQuery at the moment (except, maybe, Drill?) I’ve explored approaches to building such an open source system in this blog post.
Differences from Big Data SQL Systems: Indexes and Static Data Distribution
The subject systems run queries faster than the Big Data processing systems from the SQL-on-Hadoop family: Hive, Impala, Presto and Spark, even when the latter access the data stored in columnar format, such as Parquet or Kudu. This is because ClickHouse, Druid and Pinot
Have their own format for storing data with indexes, and tightly integrated with their query processing engines. SQL-on-Hadoop systems are generally agnostic of the data format and therefore less “intrusive” in Big Data backends.
Have data distributed relatively “statically” between the nodes, and the distributed query execution takes advantage of this knowledge. On the flip side, ClickHouse, Druid and Pinot don’t support queries that require movements of large amounts of data between the nodes, e. g. joins between two large tables.
No Point Updates and Deletes
From the other side of the database spectrum, ClickHouse, Druid and Pinot don’t support point updates and deletes, as opposed to the columnar systems like Kudu, InfluxDB and Vertica(?). This gives ClickHouse, Druid and Pinot the ability to make more efficient columnar compression and more aggressive indexes, that means higher resource efficiency and faster queries.
ClickHouse developers at Yandex aim to support updates and deletes in the future, but I’m not sure, would it be true point queries or updates and deletes of ranges of data.
Big Data Style Ingestion
All ClickHouse, Druid and Pinot support streaming data ingestion from Kafka. Druid and Pinot support Lambda-style streaming and batch ingestion of the same data. ClickHouse supports batch inserts directly, so it doesn’t need a separate batch ingestion system as in Druid and Pinot. This is discussed in more details below in this post.
Proven at Large Scale
All three systems are proven at large scale: there is a ClickHouse cluster at Yandex.Metrica of approximately ten thousands CPU cores. Metamarkets runs a Druid cluster of similar size. A single Pinot cluster at LinkedIn has “thousands of machines”.
Immature
All the subject systems are very immature by the enterprise database standards. (However, probably not more immature than an average open source Big Data system, but that’s a different story.) ClickHouse, Druid and Pinot lack obvious optimizations and features all over the place, and riddled with bugs (here I cannot be 100% sure about ClickHouse and Pinot, but there are no reasons to think that they are any better than Druid).
This brings us to the next important section —
On Performance Comparisons and Choice of the System
I regularly see on the web how do people compare and choose big data systems — they take a sample of their data, somehow ingest it in the evaluated system, and then immediately try to measure efficiency — how much memory or disk space did it take and how fast could the queries complete, while having little understanding of the internals of the evaluated system. Then, using only such performance information and also sometimes the lists of features that they need and the compared systems currently have, they make a choice, or, worse, decide to write their own, “better” system from scratch.
I think this approach is wrong, at least in the case of Open Source Big Data OLAP systems. The problem of crafting a generic Big Data OLAP system that would work efficiently across the majority of use cases and features (and the power set of their combinations!) is really, really huge — I would estimate that it takes at least 100 man-years to build such a system.
ClickHouse, Druid and Pinot are currently optimized only for the specific use cases that their developers care about, and have almost exclusively only the features that their developers need. If you are going to deploy a big cluster of either one of those systems and care about efficiency, I guarantee that your use case is going to hit it’s unique bottlenecks, that the developers of the subject OLAP systems didn’t encounter before or don’t care about. Let alone that the aforementioned approach “throw data into the system that you know little about and measure efficiency” has a very big chance of suffering from some major bottlenecks that could be fixed by just changing some configurations, or data schema, or making queries differently.
CloudFlare: ClickHouse vs. Druid
One example that illustrates the problem described above is Marek Vavruša’s post about Cloudflare’s choice between ClickHouse and Druid. They needed 4 ClickHouse servers (than scaled to 9), and estimated that similar Druid deployment would need “hundreds of nodes”. Although Marek admits that was an unfair comparison, because Druid lacks “primary key sorting”, he probably didn’t realize that it’s possible to achieve pretty much the same effect in Druid just by setting the right order of dimensions in the “ingestion spec” and simple data preparation: truncate Druid’s __time column value to some coarse granularity, e. g. one hour, and optionally add another long-typed column “precise_time”, if finer time boundaries are needed for some queries. It’s a hack, but allowing Druid to actually sort data by some dimension before __time would also be quite easy to implement.
I don’t challenge their ultimate decision to choose ClickHouse, because on the scale of about ten nodes, and for their use case, I also think that ClickHouse is a better choice than Druid (I’m explaining this below in this post). But their conclusion that ClickHouse is at least an order of magnitude more efficient (in terms of infrastructure costs) than Druid is a complete fallacy. In fact, among the three systems discussed here, Druid offers the most to enable really cheap installations, see the section “Tiering of Query Processing Nodes in Druid” below.
When choosing a Big Data OLAP system, don’t compare how optimal they currently are for your use case. They are all very suboptimal, at the moment. Compare how fast your organization could make those systems to move in the direction of being more optimal for your use case.
Because of their fundamental architectural similarity, ClickHouse, Druid and Pinot have approximately the same “limit” of efficiency and performance optimization. There is no “magic pill” that allows any of those systems be significantly faster than the others. Don’t be deluded by the fact that in their current state, the systems perform very differently in certain benchmarks. E. g. currently Druid doesn’t support “primary key sorting” well, unlike ClickHouse (see above), while ClickHouse doesn’t support inverted indexes, unlike Druid, that gives those systems the edge in specific workloads. The missing optimizations could be implemented in the chosen system with not so big amount of efforts, if you have an intention and ability to do this.
Either your organization should have engineers who are able to read, understand and modify the source code of the chosen system, and have capacity to do that. Note that ClickHouse is written in C++, Druid and Pinot — in Java.
Or, your organization should sign a contract with a company that provides support of the chosen system. There is Altinity for ClickHouse, Imply and Hortonworks for Druid. There are no such companies for Pinot at the moment.
Other development considerations:
ClickHouse developers at Yandex stated that they spend 50% of their time building features that they need internally at the company, and 50% of time — the features with the most “community votes”. However, to be able to benefit from this, the features that you need in ClickHouse should match the features that most other people in the community need.
Druid developers from Imply are motivated to build widely applicable features in order to maximize their future business.
Druid’s development process is very similar to the Apache model, for several years it’s been developed by several companies with quite different priorities and without dominance of either one of those companies. ClickHouse and Pinot are currently far from that state, they are developed almost exclusively at Yandex and LinkedIn, respectively. Contributions into Druid have the least chance of being declined or revoked later, because they misalign with the goals of the primary developer. Druid doesn’t have a “primary” developer company.
Druid commits to support “developer API”, that allows to contribute custom column types, aggregation algorithms, “deep storage” options, etc. and maintain them separate from the codebase of the core Druid. Druid developers document this API and track it’s compatibility with the prior versions. However, this API is not matured yet and is broken pretty much in every Druid release. As far as I know, ClickHouse and Pinot don’t maintain similar APIs.
According to Github, Pinot has the most people who work on it, seems that at least 10 man-years were invested in Pinot in the last year. This figure is probably 6 for ClickHouse and about 7 for Druid. It means that in theory, Pinot is being improved the fastest among the subject systems.
Architectures of Druid and Pinot are almost identical to each other, while ClickHouse stands a little apart from them. I will first compare the architecture of ClickHouse with “generic” Druid/Pinot architecture, and then discuss smaller differences between Druid and Pinot.
Differences between ClickHouse and Druid/Pinot
Data Management: Druid and Pinot
In Druid and Pinot, all data in each “table” (whatever it is called in the terminology of those systems) is partitioned into the specified amount of parts. By the time dimension, data is also usually divided with the specified interval. Then those parts of the data are “sealed” individually into self-contained entities called “segments”. Each segment includes table metadata, compressed columnar data and indexes.
Segments are persisted in “deep storage” (e. g. HDFS) and could be loaded on query processing nodes, but the latter are not responsible for durability of the segments, so query processing nodes could be replaced relatively freely. Segments are not rigidly attached to some nodes, they could be loaded more or less on any nodes. A special dedicated server (called “Coordinator” in Druid and “Controller” in Pinot, but I’m going to generically refer to it as “master” below) is responsible for assigning the segments to the nodes, and moving segments between the nodes, if needed. (It doesn’t contradict what I pointed above in this post that all three subject systems, including Druid and Pinot, have “static” data distribution between the nodes, because segment loads and movements in Druid (and Pinot, I suppose) are expensive operations and not done for each particular query, and usually happen only every several minutes, or hours, or days.)
Metadata about segments is persisted in ZooKeeper, directly in Druid, and via Helix framework in Pinot. In Druid metadata is also persisted in an SQL database, it’s explained in more details in the section “Differences between Druid and Pinot” below in this post.
Data Management: ClickHouse
ClickHouse doesn’t have “segments”, containing data strictly falling into specific time ranges. There is no “deep storage” for data, nodes in ClickHouse cluster are also responsible for both query processing and persistence/durability of the data, stored on them. So no HDFS setup or cloud data storage like Amazon S3 is needed.
ClickHouse has partitioned tables, consisting of specific sets of nodes. There is no “central authority” or metadata server. All nodes, between which some table is partitioned, have full, identical copies of the table metadata, including addresses of all other nodes, on which partitions of this table are stored.
Metadata of partitioned table includes “weights” of nodes for distribution of the newly written data, e. g. 40% of data should go to the node A, 30% to the node B and 30% to the node C. It should normally be just equal distribution among the nodes. “Skew”, as in example above, is only required when a new node is added to the partitioned table, in order to fill the new node faster with some data. Updates of those “weights” should be done manually by ClickHouse cluster administrators, or an automated system should be built on top of ClickHouse.
Data Management: Comparison
The approach to data management is simpler in ClickHouse than in Druid and Pinot: no “deep storage” is required, just one type of nodes, no special dedicated server for data management is required. But the approach of ClickHouse becomes somewhat problematic, when any table of data grows so large that it needs to be partitioned between dozens of nodes or more: query amplification factor becomes as large as the partitioning factor, even for queries, that cover small interval of data:

In the example that is given in the picture above, the table data is distributed between three nodes in Druid or Pinot, but a query for a little interval of data will usually hit just two nodes (unless that interval crosses a segment interval boundary). In ClickHouse, any queries will need to hit three nodes, if the table is partitioned between three nodes. In this example it doesn’t seem like a dramatic difference, but imagine that the number of nodes is 100, while the partitioning factor could still be e. g. 10 in Druid or Pinot.
To mitigate this problem, the largest ClickHouse cluster at Yandex (of hundreds of nodes) is in fact split into many “subclusters” of a few dozens of nodes each. This ClickHouse cluster is used to power website analytics, and each point of data has “website ID” dimension. There is strict assignment of each website ID to a specific subcluster, where all data for that website ID go. There is some business logic layer on top of that ClickHouse cluster to manage such data separation on both data ingestion and querying sides. Thankfully in their use case, little queries need to hit data across multiple website IDs, and such queries are coming not from customers of the service, so they don’t have strict real-time SLA.
Another drawback of the ClickHouse’s approach is that when a cluster grows rapidly, data is not rebalanced automatically without humans manually changing “node weights” in a partitioned table.
Tiering of Query Processing Nodes in Druid
Data management with segments is “simple to reason about”. Segments could be moved between the nodes relatively easily. Those two factors helped Druid to implement “tiering” of query processing nodes: old data is automatically moved to servers with relatively larger disks, but less memory and CPU, that allows to significantly reduce costs of running a large Druid cluster, at the expense of slowing queries to older data.
This feature allows Metamarkets to save hundreds of thousands dollars of Druid infrastructure spend per month, versus it had a “flat” cluster.
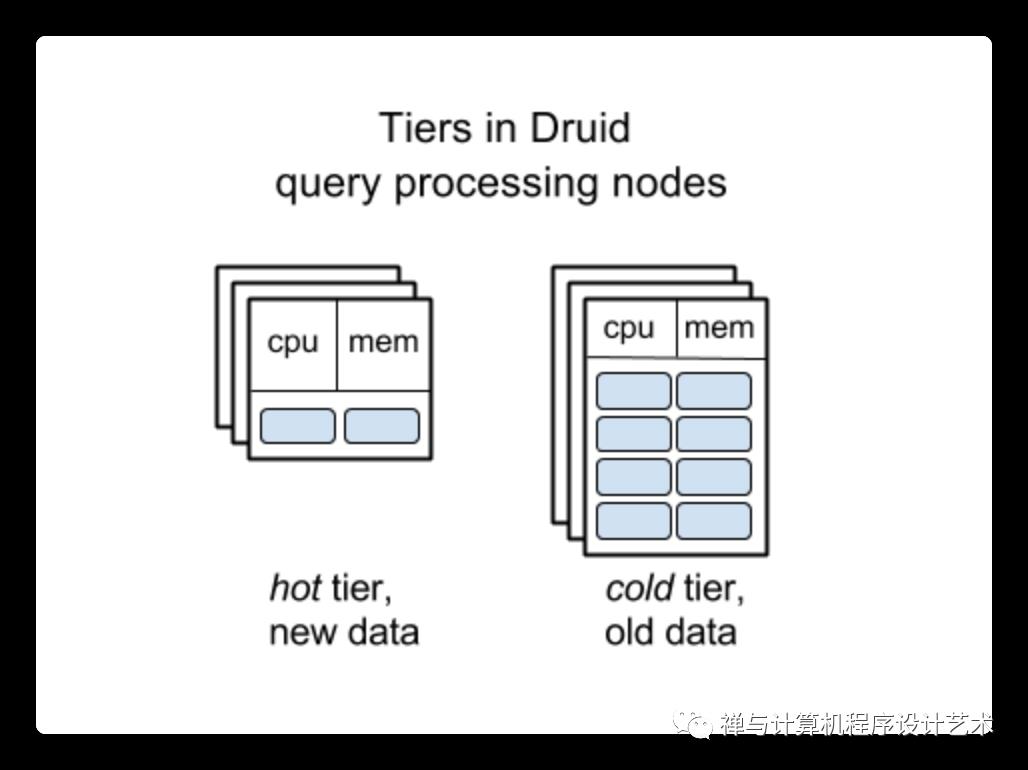
As far as I know, ClickHouse and Pinot don’t have similar features yet, all nodes in their clusters are supposed to be the same.
Since the architecture of Pinot is very similar to Druid’s, I think it would be not very hard to introduce a similar feature in Pinot. It might be harder to do this in ClickHouse, because the concept of segments is really helpful for the implementation of such feature, but still possible though.
Data Replication: Druid and Pinot
The unit of replication in Druid and Pinot is a single segment. Segments are replicated in both “deep storage” layer (e. g. three replicas in HDFS, or it is done transparently inside the cloud blob storage, such as Amazon S3), and in the query processing layer: typically in both Druid and Pinot, each segments is loaded on two different nodes. The “master” server monitors the replication levels of each segment and loads a segment on some server, if the replication factor falls below the specified level, e. g. if some node becomes unresponsive.
Data Replication: ClickHouse
The unit of replication in ClickHouse is a table partition on a server, i. e. all data from some table, stored on a server. Similar to partitioning, replication in ClickHouse is “static and specific” rather than “cloud style”, i. e. several servers know that they are replicas of each other (for some specific table; for a different table, replication configuration may be different). Replication provides both durability and query availability. When a disk on some node is corrupted, the data is not lost, because it is stored on some other node too. When some node is temporarily down, queries could be routed to the replica.
In the largest ClickHouse cluster at Yandex, there are two equal sets of nodes in different data centers, and they are paired. In each pair the nodes are replicas of each other (i. e. the replication factor of two is used) and located in different data centers.
ClickHouse depends on ZooKeeper for replication management, but otherwise ZooKeeper is not needed. It means that ZooKeeper is not needed for a single-node ClickHouse deployment.
Data Ingestion: Druid and Pinot
In Druid and Pinot, query processing nodes are specialized to load segments and serve queries to the data in segments, but not to accumulate new data and produce new segments.
When a table could be updated with delay of an hour or more, segments are created using batch processing engines, such as Hadoop or Spark. Both Druid and Pinot have “first class” out-of-the-box support for Hadoop. There is a third-party plugin for Druid indexing in Spark, but it’s unsupported at the moment. As far as I know, Pinot doesn’t have even such level of support for Spark, i. e. you should contribute it yourself: understand Pinot interfaces and code, write some Java or Scala code. But it shouldn’t be very hard to do. (Update: Ananth PackkilDurai from Slack is contributing support for Spark in Pinot now.)
When a table should be updated in real time, both Druid and Pinot introduce a concept of “real time nodes”, which do three things: accept new data from Kafka (Druid supports other sources too), serve queries to the recent data, and create segments in background, later pushing them to the “deep storage”.
Data Ingestion: ClickHouse
The fact that ClickHouse doesn’t need to prepare “segments” containing strictly all data, falling into specific time intervals, allows for simpler data ingestion architecture. ClickHouse doesn’t need a batch processing engine like Hadoop, nor “realtime” nodes. Regular ClickHouse nodes, the same that store the data and serve queries to it, directly accept batch data writes.
If a table is partitioned, the node that accepts a batch write (e. g. 10k rows) distributes the data according to the “weights” of all nodes in the partitioned table itself (see section “Data management: ClickHouse” above).
Rows written in a single batch form a small “set”. Set is immediately converted into columnar format. There is a background process on each ClickHouse node, that merges row sets into larger ones. Documentation of ClickHouse heavily refers to this principle as “MergeTree” and highlights it’s similarity with log-structured merge trees, although IMO it’s a little confusing because data is not organized in trees, it’s in a flat columnar format.
Data Ingestion: Comparison
Data ingestion in Druid and Pinot is “heavy”: it consists of several different services, and it’s management is a burden.
Data ingestion in ClickHouse is much simpler (at the expense of more complicated historical data management — see above), although there is one caveat: you should be able to “batch” data in front of ClickHouse itself. Automatic ingestion and batching of data from Kafka is available out-of-the-box, but if you have a different source of real-time data, ranging from queueing infrastructure alternative to Kafka and stream processing engines to simple HTTP endpoints, you need to create an intermediate batching service, or contribute code to ClickHouse directly.
Query Execution
Druid and Pinot have dedicated layer of nodes called “brokers”, which accept all queries to the system. They determine to which “historical” query processing nodes subqueries should be issued, based on the mapping from segments to nodes, on which the segments are loaded. Brokers keep this mapping information in memory. Broker nodes send downstream subqueries to query processing nodes, and when the results of those subqueries come back, broker merges them and returns the final combined result to the user.
I can only speculate why the decision to extract another one type of nodes was made when Druid and Pinot were designed. But now it seems essential, because with the total number of segments in clusters going beyond ten millions, segment to node mapping information takes gigabytes of memory. It’s too wasteful to allocate so much memory on all query processing nodes. So, this is another drawback, imposed by Druid’s and Pinot’s “segmented” data management architecture.
In ClickHouse dedicating a separate set of nodes for “query brokering” is usually not needed. There is a special ephemeral “distributed” table type in ClickHouse, that could be set up on any node, and queries to this table do everything for what “broker” nodes are responsible in Druid and Pinot. Usually such ephemeral tables are set up on each node that participates the partitioned table, so, in practice, every node could be the “entry point” for a query to a ClickHouse cluster. This node will issue necessary subqueries to other partitions, process it’s part of the query itself, and merge it with partial results from other partitions.
When a node (either one of processing nodes in ClickHouse, or a “broker” node in Druid and Pinot) issues subqueries to other nodes, and a single or a few subqueries fail for whatever reason, ClickHouse and Pinot handle this situation properly: they merge the results of all succeeded subqueries and still return partial result to the user. Druid notoriously lacks this feature at the moment: if any subquery fails, the whole query fails as well.
ClickHouse vs. Druid or Pinot: Conclusions
“Segmented” approach to data management in Druid and Pinot versus simpler data management in ClickHouse define many other aspects of the systems. However, importantly, this difference has little or no implications on the potential compression efficiency (albeit the compression story in all three systems is sad at the moment), or query processing speed.
ClickHouse resembles traditional RDMBS, e. g. PostgreSQL. In particular, ClickHouse could be deployed just on a single server. If the projected size of the deployment is small, e. g. not bigger than in the order of 100 CPU cores for query processing and 1 TB of data, I would say that ClickHouse has significant advantage over Druid and Pinot, due to it’s simplicity and not requiring additional types of nodes, such as “master”, “real-time ingestion nodes”, “brokers”. On this field, ClickHouse competes rather with InfluxDB, than with Druid or Pinot.
Druid and Pinot resemble Big Data systems such as HBase. Not by their performance characteristics, but by dependency on ZooKeeper, dependency on persistent replicated storage (such as HDFS), focus on resilience to failures of single nodes, and autonomous work and data management not requiring regular human attention.
For a wide range of applications, neither ClickHouse nor Druid or Pinot are obvious winners. First and foremost, I recommend to take into account, the source code of which system your are able to understand, fix bugs, add features, etc. The section “On Performance Comparisons and Choice of the System” discusses this more.
Secondly, you could look at the table below. Each cell in this table describes a property of some application, that makes either ClickHouse or Druid/Pinot probably a better choice. Rows are not ordered by their importance. The relative importance of each row is different for different applications, but if your application is described by many properties from one column in the table and by no or a few properties from another, it’s likely that you should choose the corresponding system from the column header.
Note: neither of the properties above means that you must use the corresponding system(s), or must avoid the other system(s). For example, if you cluster is projected to be big, it doesn’t mean that you should only consider Druid or Pinot, but never ClickHouse. It rather means that Druid or Pinot become more likely better solutions, but other properties could outweigh and ClickHouse could be ultimately a more optimal choice even for large clusters, in some applications.
Differences between Druid and Pinot
As I noted several times above, Druid and Pinot have very similar architectures. There are several pretty big features, that are present in one system and absent in another, and areas, where one system has advanced significantly farther than another. But all such things that I’m going to mention could be replicated in another system with reasonable amount of efforts.
There is just one difference between Druid and Pinot, that is probably too big to be eliminated in foreseeable future — it’s the implementation of segment management in the “master” node. Also developers of the both systems probably wouldn’t want to do that anyway, because the approach of both has it’s pros and cons, it’s not that one is totally better than another.
Segment Management in Druid
The “master” node in Druid (and neither in Pinot) is not responsible for persistence of the metadata of the data segments in the cluster, and the current mapping between segments and query processing nodes, on which the segments are loaded. This information is persisted in ZooKeeper. However Druid additionally persists this information in an SQL database, that should be provided to set up a Druid cluster. I cannot say why this decision was originally made, but currently it provides the following benefits:
Less data is stored in ZooKeeper. Only minimal information about the mapping from the segment id to the list of query processing nodes on which the segment is loaded is kept in ZooKeeper. The remaining extended metadata, such as size of the segment, list of dimensions and metrics in it’s data, etc. is stored only in the SQL database.
When segments of data are evicted from the cluster because they become too old (this is a commonplace feature of timeseries databases, all ClickHouse, Druid and Pinot have it), they are offloaded from the query processing nodes and metadata about them is removed from ZooKeeper, but not from the “deep storage” and the SQL database. As long as they are not removed manually from those places, it allows to “revive” really old data quickly, in case the data is needed for some reporting or investigation.
Unlikely it was an intention originally, but now there are plans in Druid to make dependency on ZooKeeper optional. Currently ZooKeeper is used for three different things: segment management, service discovery, and property store, e. g. for realtime data ingestion management. Service discovery and property store functionality could be provided by Consul. Segment management could be implemented with HTTP announcements and commands, and it’s partially enabled by the fact that the persistence function of ZooKeeper is “backed up” by SQL database.
The downside of having SQL database as a dependency is greater operational burden, especially if some SQL database is not set up in the organization yet. Druid supports mysql and PostgreSQL, there is a community extension for Microsoft SQL Server. Also, when Druid is deployed in the cloud, convenient managed RDBMS services could be used, such as Amazon RDS.
Segment Management in Pinot
Unlike Druid, which implements all segment management logic itself, and relies only on Curator for communication with ZooKeeper, Pinot delegates a big share of segment and cluster management logic to Helix framework. On the one hand, I can imagine that it gives Pinot developers a leverage to focus on other parts of their system. Helix probably has fewer bugs than the logic implemented inside Druid, because it was tested under different conditions, and because probably more time was put into Helix development.
On the other hand, Helix probably constrains Pinot with it’s “framework bounds”. Helix, and consequently Pinot, are probably going to depend on ZooKeeper forever.
Now I’m going to enumerate more shallow differences between Druid and Pinot. By “shallow” here I mean that there is a clear path to replicate those features in the system that lacks them, if anybody wants.
“Predicate pushdown” in Pinot
If during ingestion data is partitioned in Kafka by some dimension keys, Pinot produces segments that carry the information about this partitioning and then when a query with a predicate on this dimension is done, a broker node filters segments upfront, so that sometimes much fewer segments and consequently query processing nodes need to be hit.
This feature is important for performance in some applications.
Currently Druid supports key-based partitioning, if segments are created in Hadoop, but not yet when segments are created during realtime ingestion. Druid doesn’t currently implement “predicate pushdown” on brokers.
“Pluggable” Druid and Opinionated Pinot
Because Druid was used and developed by many organizations, over time it gained support of several exchangeable options for almost every dedicated part or “service”:
HDFS, or Cassandra, or Amazon S3, or Google Cloud Storage, or Azure Blob Storage, etc. as “deep storage”;
Kafka, or RabbitMQ, Samza, or Flink, or Spark, Storm, etc. (via tranquility) as real-time data ingestion source;
Druid itself, or Graphite, or Ambari, or StatsD, or Kafka as a sink for telemetry of Druid cluster (metrics).
Since Pinot was developed almost exclusively at LinkedIn and to meet LinkedIn’s needs to date, currently it often doesn’t provide user much choice: HDFS or Amazon S3 must be used as deep storage, only Kafka for real-time data ingestion. But if somebody needs that, I can imagine that it’s not hard to introduce support of multiple pluggable options for any service in Pinot. Maybe it’s going to change soon since Uber and Slack have started to use Pinot.
Data Format and Query Execution Engine are Optimized Better in Pinot
Namely, the following features of Pinot’s segment format are currently lacking in Druid:
Compression of indexed columns with bit granularity, byte granularity in Druid.
Inverted index is optional for each column, in Druid it’s obligatory, that’s not needed sometimes and consumes a lot of space. The difference in space consumption between Druid and Pinot observed by Uber could probably be attributed to this.
Min and max values in numeric columns are recorded per segment.
Out-of-the-box support for data sorting. In Druid it could be achieved only manually and in a hackish way, as explained in the section “CloudFlare: ClickHouse vs. Druid” above. Data sorting means better compression, so this feature of Pinot is another probable reason of the difference in space consumption (and query performance!) between Druid and Pinot observed by Uber.
Some more optimized format is used for multi-value columns than in Druid.
All those things could be implemented in Druid, though. And although Pinot’s format is substantially better optimized that Druid’s at the moment, it is also pretty far from from being really optimal. For example, Pinot (as well as Druid) uses only general-purpose compression such as Zstd, and not yet implemented any of the compression ideas from the Gorilla paper.
Regarding query execution, it’s unfortunate that Uber mainly used count (*) queries to compare performance of Druid with Pinot (1, 2), because it’s just a dumb linear scan in Druid at the moment, although it’s really easy to replace it with a proper O(1) implementation. It’s an illustration of meaninglessness of “black box” comparisons, covered in the section “On Performance Comparisons and Choice of the System” above in this post.
I think that the difference in GROUP BY query performance, observed by Uber, should be attributed to the lack of data sorting in Druid’s segments, as noted above in this section.
Druid Has a Smarter Segment Assignment (Balancing) Algorithm
Pinot’s algorithm is to assign segment to query processing nodes which have least total segments loaded at the moment. Druid’s algorithm is much more sophisticated, it takes each segment’s table and time into account, and applies a complex formula to calculate the final score, by which query processing nodes are ranked to choose the best one to assign a new segment. This algorithm brought 30–40% query speed improvements in production at Metamarkets. Yet at Metamarkets we are still not happy with this algorithm, see the section “Huge variance in performance of historical nodes” in this post.
I don’t know how LinkedIn is fine with so simple segment balancing algorithm in Pinot, but probably huge gains are awaiting them around the corner, if they take time to improve their algorithm.
Pinot is More Fault Tolerant on the Query Execution Path
As I already mentioned in the “Query Execution” section above, when a “broker” node makes subqueries to other nodes, and some subqueries fail, Pinot merges the results of all succeeded subqueries and still returns partial result to the user.
Druid doesn’t implement this feature at the moment.
Tiering of Query Processing Nodes in Druid
See the same-titled section above in this post. Druid allows to extract “tiers” of query processing nodes for older and newer data, and nodes for older data has much lower “CPU, RAM resources / number of loaded segments” ratio, allowing to trade smaller infrastructure expenses for inferior query performance when accessing old data.
As far as I know, Pinot doesn’t currently have a similar feature.
Summary
ClickHouse, Druid and Pinot have fundamentally similar architecture, and their own niche between general-purpose Big Data processing frameworks such as Impala, Presto, Spark, and columnar databases with proper support for unique primary keys, point updates and deletes, such as InfluxDB.
Due to their architectural similarity, ClickHouse, Druid and Pinot have approximately the same “optimization limit”. But as of now, all three systems are immature and very far from that limit. Substantial efficiency improvements to either of those systems (when applied to a specific use case) are possible in a matter of a few engineer-months of work. I don’t recommend to compare performance of the subject systems at all, choose the one which source code you are able to understand and modify, or in which you want to invest.
Among those three systems, ClickHouse stands a little apart from Druid and Pinot, while the latter two are almost identical, they are pretty much two independently developed implementations of exactly the same system.
ClickHouse more resembles “traditional” databases like PostgreSQL. A single-node installation of ClickHouse is possible. On small scale (less than 1 TB of memory, less than 100 CPU cores) ClickHouse is much more interesting than Druid or Pinot, if you still want to compare with them, because ClickHouse is simpler and has less moving parts and services. I would say that it competes with InfluxDB or Prometheus on this scale, rather than with Druid or Pinot.
Druid and Pinot more resemble other Big Data systems in the Hadoop ecosystem. They retain “self-driving” properties even on very large scale (more than 500 nodes), while ClickHouse requires a lot of attention of professional SREs. Also, Druid and Pinot are in the better position to optimize for infrastructure costs of large clusters, and better suited for the cloud environments, than ClickHouse.
The only sustainable difference between Druid and Pinot is that Pinot depends on Helix framework and going to continue to depend on ZooKeeper, while Druid could move away from the dependency on ZooKeeper. On the other hand, Druid installations are going to continue to depend on the presence of some SQL database.
Currently Pinot is optimized better than Druid. (But please read again above — “I don’t recommend to compare performance of the subject systems at all”, and corresponding sections in the post.)
以上是关于Comparison of Big Data OLAP DB : ClickHouse, Druid, and Pinot的主要内容,如果未能解决你的问题,请参考以下文章
A Summary of Big Data Management
SSDB - A fast NoSQL database for storing big list of data
Comparison of video container formats