深入浅出Java复用类从字节码角度看toString调用机制对象代理组合与继承转型final初始化
Posted Roninaxious
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出Java复用类从字节码角度看toString调用机制对象代理组合与继承转型final初始化相关的知识,希望对你有一定的参考价值。
这个世界上有10种人:一种是懂二进制的,一种是不懂二进制的
你觉得类是在什么时候被加载的?【访问static域时,为什么?看完9就明白了】
文章目录
1、深入理解Java中toString方法的调用机制
每一个非基本类型的对象都有一个toString()方法,当编译器需要一个String对象而你却只有一个对象时,便会调用toString()方法。
观看以下代码分析toString()方法的调用机制
class Emp
private String s = "hello";
@Override
public String toString()
System.out.println("调用了toString方法");
return s;
public static void main(String[] args)
Emp p = new Emp();
System.out.println("Emp="+p);
结果如下所示:

分析结果如下:
"Emp="+p
1.1.关于Java代码层面的toString的调用机制
对于这行代码,编译器会将得知你想要将一个String对象(“Emp”)同p对象相加。由于只能将一个String对象和另外一个String对象相加,因此编译器将会告诉你:"我将要调用toString()方法,将p对象转换为一个String!"之后便可以将两个String对象连接到一起并将其传入到System.out.println().
1.2.从字节码角度剖析toString观察toString方法的调用
相信看到这你还是会有疑问,我怎么知道底层自动调用了toString()方法了呢?让我从字节码角度进行剖析 ,对上述代码进行反解析
0 new #4 <com/zsh/javase/base/Emp>
3 dup
4 invokespecial #5 <com/zsh/javase/base/Emp. : ()V>
7 astore_1
8 getstatic #6 <java/lang/System.out : Ljava/io/PrintStream;>
11 aload_1
12 invokedynamic #7 <makeConcatWithConstants, BootstrapMethods #0>
17 invokevirtual #8 <java/io/PrintStream.println : (Ljava/lang/String;)V>
20 return
下面这一行表明调用了toString()方法(toString底层就是new了一个String对象)

一般来说系统了解过JVM才会看得懂这些字节码指令,如果你刚接触Java,你只需要记住.java编译成.class文件时,底层自动调用了toString()方法即可。
new //代表创建一个Emp对象,并将引用压入栈顶
dup //复制栈顶的引用,并将其压入栈顶(此时你可能会有疑问,new指令之后栈顶已经有了一个地址,为什么还需要复制一份;其实一份是虚拟机要自动调用< init>方法做初始化使用的,另一份是给程序员使用的(对对象中的变量做赋值等操作,弹栈就没了)
1.3.为什么如果没有重写toString()方法就会打印类似的地址呢?

当然会调用它的父类Object中的toString方法,看下面父类Object中toString方法的源码会发现,它的返回刚好是类的全限定名+@+对象的哈希码
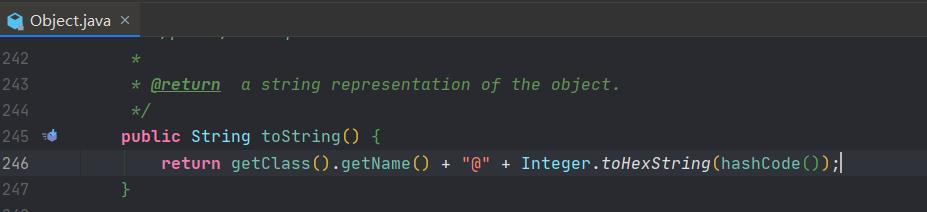
2、深入字节码探究基类与导出类的构造初始化
基 类 : 父 类 基类:父类 基类:父类
导 出 类 : 子 类 导出类:子类 导出类:子类
2.1.如何理解继承中基类与导出类之间的关系
我们都知道在Java中“一切皆对象”,从现实生活中举例:比如“车”和“跑车🚓”,它们之间有什么特征联系呢?
1."车“是一个宽泛的概念,“跑车”则是一个相对狭小的概念
2."车"拥有的特征而“跑车”一般都会拥有
所以当你创建了一个导出类对象时,该对象隐含了一个基类的子对象,这个子对象与你使用基类创建的对象的一致的。(只不过后者来自外部,而前者包装在导出类对象的内部)
2.2.如何理解基类与导出类的构造器初始化
观看以下代码分析结果
public class ExtendTest
public static void main(String[] args)
Son son = new Son();
class Parent
public Parent()
System.out.println("Parent..");
class Son extends Parent
public Son()
System.out.println("Son");
结果:
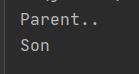
从这我们可以发现,这个构建过程是从基类开始向下扩散的,所以基类在导出类访问它之前就已经完成了初始化,即使你不为它创建构造器,编译器会自动地为你生成一个默认地构造器。
如果你要想要调用基类中有参的构造器就需要使用“super”关键字,如下面这样:
public class ExtendTest
public static void main(String[] args)
Son son = new Son(11);
class Parent
public Parent(int i)
System.out.println("Parent有参构造..");
class Son extends Parent
public Son(int i)
super(11);
System.out.println("Son有参构造..");
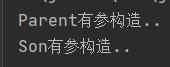
2.3.从字节码角度解读基类与导出类的构造初始化
class Parent
public Parent()
对上述代码进行反编译之后得到字节码指令如下
0 aload_0
1 invokespecial #1 <java/lang/Object.< init> : ()V>
4 return
可以看出加载时它调用了基类Object的< init>空参方法。
3、为什么有时要对对象进行代理(Delegation)?
其实主要原因有以下:
1.保证单一职责
2.拥有更多的控制力
3.1、解析第一种原因
需要使每个类的功能尽可能的单一(单一职责),这样对某个类进行修改时才能保证几乎不影响其他类;比如有一个User类对象,我想要对该对象进行权限判断,如果直接在User类中进行添加方法判断是不是显得很混乱(一旦这样的类关联很多,对一个类进行修改就会出现牵一发而动全身)
public class DelegationExample
/**
* 测试Java中的代理(Delegation)
* 模拟如下场景:
* <p>一个账户类,现要对该账户做权限判断,增加一个代理类</p>
* 为什么要使用代理? 原因如下
* 需要使每个类的功能尽可能的单一(单一职责),这样对某个类进行修改时才能保证几乎不影响其他类
* @param args
*/
public static void main(String[] args)
User user = new User("zsh");
UserDelegation delegation = new UserDelegation();
delegation.setUser(user);
delegation.judge();
class User
private String name;
User(String name)
this.name = name;
public String getName()
return name;
public void setName(String name)
this.name = name;
class UserDelegation
private User user;
public void setUser(User user)
this.user = user;
public void judge()
if (user.getName().equals("zsh"))
System.out.println("拥有该权限!");
else
System.out.println("无相应权限!");

3.2、解析第二种原因
基类中的方法全部暴露给了子类,看以下方法
class SpaceControl
void up(int vel);
void down(int vel);
void left(int vel);
void right(int vel);
void forward(int vel);
void back(int vel);
class SpaceShip extends SpaceControl
private String spaceName;
public SpaceShip(String spaceName)
this.spaceName = spaceName;
public static void main(String[] args)
SpaceShip spaceShip = new SpaceShip("飞船一号");
spaceShip.up(100);
spaceShip.down(100);
spaceShip.left(100);
//...
所以我们可以使用代理类只暴露部分方法给外部,然后也可也扩展一些操作。
class SpaceDelegation
private String name;
private SpaceControl control = new SpaceControl();
public SpaceDelegation(String name)
this.name = name;
public void up(int vel)
control.up(vel);
public void down(int vel)
if (vel < 0)
System.out.println("输入错误");
return;
control.down(vel);
public static void main(String[] args)
SpaceDelegation delegation = new SpaceDelegation("飞船一号");
delegation.up(100);
当然也可也添加判断,例如上述代码在down方法中对vel值做了校验处理
4、为什么我们要手动清理一些对象?
5、如何理解组合与继承
组合与继承都是实现了在新的类中嵌套一个对象,只不过组合是显示地这么做,而继承是隐式地这么做;你或许想知道我如何在二者之间做选择
组合技术通常在新类中使用现有类的功能,这样一来新的类就是一个新的接口;而继承则是延申出来的一个接口,本质上是对基类的扩展(具体化)
说白了组合就是组装,嵌套的对象只是它的零件,比如”车子“和”轮胎“,你能说”轮胎“继承与”车子“嘛,那肯定不可以,所以肯定是使用组合技术。
再比如”车子“和”跑车“,你能说”车子“组装了”跑车“嘛!那肯定瞎扯嘛!
6、浅析向上转型
分析以下代码
class Instrument
public void play()
static void tune(Instrument i)
i.play();
class Wind extends Instrument
public static void main(String[] args)
Wind wind = new Wind();
Instrument.tune(wind);
在此例中,tune()方法可以接受Instrument的引用,然而我们却传入了Wind的引用。是不是很奇怪,其实你如果能够想到导出类至少包含基类中所含有的方法(导出类中隐含了一个基类对象),那么就会很好理解,这样的动作称之为向上转型。
Tinking in Java:在向上转型的过程中,唯一可能发生的事情就是丢失一些方法,而不是获取一些方法。这也就是为什么编译器在”未明确表示转型“,仍然能够向上转型的原因(注意如果基类定义方法为private,那表示是基类私有的)
7、再临final关键字
顾名思义,它的含义是”这是无法改变的“
7.1.使用final修饰数据什么含义、什么作用?
使用final修饰数据,相当于向编译器告知”这一块数据是恒定不变的“。
当使用final修饰基本数据类型时,它表示是一个永不改变的常量;编译器会将它代入到任何使用到它的计算式中(也就是直接替换为该常量值,因为你不能改变)
分析如下代码
class Test
private final int NUM = 1;
private int a = 2;
public static void main(String[] args)
Test test = new Test();
int b = test.NUM;
int c = test.a;
进行反编译查看字节码指令
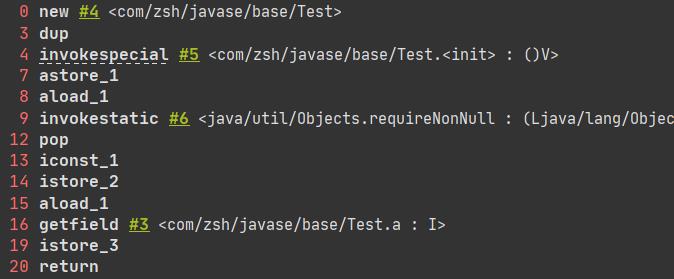
找到执行int b = test.NUM的指令
iconst_1 : 将常量压入操作数栈中。
istore_2:弹出操作数栈栈顶元素,将其保存到局部变量表为2的位置。
找寻int c = test.a的指令
aload_1:将局部变量表1号位置上的引用test加载到操作数栈中
getfield #3 : 获取对象的实例域a
istore_3:弹出操作数栈栈顶元素,将其保存到局部变量表为3的位置
可以看出编译器对final修饰的数据做了优化,可以直接代入计算式执行,不用再去根据引用去寻找。
当final修饰引用类型时,表示该引用一旦被初始化指向一个对象,就无法再指向另外一个对象。需要注意的是对象的内容是可以修改的(Thinking in Java:Java并未提供任何使对象恒定不变的途径)

同样的也适用于数组,数组也是对象
7.2.使用final修饰数据初始化的时机
必须在域的定义处或者构造器中对final修饰的变量进行赋值,这也是final域在使用前总是被初始化的原因所在。
class FinalKey
private final int NUM = 1;
private final String OB;
public FinalKey()
OB = "ob";
7.3.final参数
如果将参数定义为final类型,这样意味着你无法修改基本类型的参数、无法将引用类型的参数指向另外一个对象。
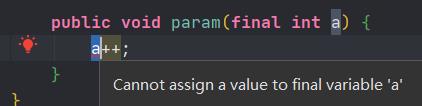
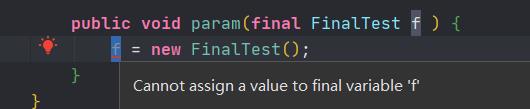
7.4.使用final修饰方法的含义、扩展内容
被我们熟知的就是将方法锁定,不能被重写。
另外一个作用是效率,在早期Java中,如果使用final修饰了方法,那么编译器将针对该方法的所有调用都转为内嵌调用(将整段代码插入调用处)。这将消除调用开销,但是如果代码膨胀,那么这样不会有任何性能提高。
在如今的HoSpot虚拟机中可以探测到这些情况,因此不需要再使用final进行优化了。
总结:所以说只有明确禁止覆盖时,才将方法设置为final(另外类中的所有private方法都隐式地指定为final的,所以对private方法添加final关键字,没有任何意义;
看下面的奇怪例子:
class TypeParent
private void method()
class TypeSon extends TypeParent
private void method()
上述不是已经说明private隐式地指定为final,那为什么上面这个例子还能覆盖呢?其实这不是覆盖,只是在子类中新定义了一个方法,与基类中的方法没有任何联系。
7.5.使用final修饰类的隐含意义
这个使用final修饰类,表示“永远不需要做任何变动或者处于安全考虑”,比如String类”
另外final类的域或者方法都会隐式地指定为final,所以在final类中为域或方法添加final没有任何意义。
8、在继承中静态、非静态、构造函数的初始化顺序
以下会涉及JVM的相关知识,如果不了解,记住即可!
类的加载过程中,分为三个阶段
- 🌹1.loading阶段
生成大Class对象,将静态存储结构转换为方法区运行时的数据结构
- 🌹2.linking阶段
(1)验证:校验字节码文件信息是否符合虚拟机要求(防止篡改)
(2)准备:为类变量分配内存空间并初始化为默认值[0或者null],这里不包含用final修饰的static,因为final在编译的时候会分配了,准备阶段会显式初始化
(3)解析:符号引用抓换位直接引用
- 🌹3.initization阶段
执行类构造器< Clinit>的过程,注意这是类构造器,不是对象构造器< init>
这个Clinit方法不需要进行定义,它是javac编译器自动收集类变量的赋值动作和静态代码块合并而来的(总结一句话:执行类变量和静态代码块的赋值语句)
所以在类加载阶段的初始化顺序为:
父类的静态属性默认初始化->子类的静态属性默认初始化->父类的静态属性显示初始化->子类的静态属性显示初始化(注意static final一块修饰的变量在准备阶段会进行显示初始化操作)
最后就是对象层面的变量的初始化
父类成员变量初始化->子类成员变量初始化->父类构造器->子类构造器
累了,不想写了
9、你觉得类是在什么时候被加载的?
构造器也是static方法,尽管没有显示出来。所以类是在任何static成员被访问时加载的。
以上是关于深入浅出Java复用类从字节码角度看toString调用机制对象代理组合与继承转型final初始化的主要内容,如果未能解决你的问题,请参考以下文章