甄建勇:五分钟搞定MMU
Posted 宋宝华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了甄建勇:五分钟搞定MMU相关的知识,希望对你有一定的参考价值。
作者简介
甄建勇,高级架构师(某国际大厂),十年以上半导体从业经验。主要研究领域:CPU/GPU/NPU架构与微架构设计。
感兴趣领域:经济学、心理学、哲学。
概 述
爱因斯坦在他的相对论中告诉我们,没有绝对的时间和空间,在一定条件下时间和空间是可以相互转化的,是否我们的世界有一天能够把空间与时间转化回到历史的时期?
唐代诗仙李白也曾有云:“夫天地者,万物之逆旅;光阴者,百代之过客”。是对空间和时间的另外一种表述。
在人们一般的印象中,空间,不会随着之间的变化而变大或变小;时间,也不会因为空间的变化而变慢或变快。时间和空间,看似毫不相关的两个事物,却又时时刻刻联系在一起。其实在计算机领域的很多方面都可以体现时间和空间的关系,比如,芯片面积和处理速度的置换就是其中之一,此外还有CPU中的存储器组织的设计时运用的时间局部性和空间局部性原理,也可以认为是时空互换的经典应用。
冯诺依曼结构与他之前的结构的最大不同就在于在计算机中引入了存储部件,也正是这个存储部件是计算机的设计进入了一个全新时代。也正是由于存储部件在计算机体系结构中的重要地位,无论是过去还是现在,无论是体系结构设计中,还是在操作系统设计中,存储组织的设计与管理一直是研究热点。在前面介绍了CPU的数据通路和控制通路之后,本章,我们将介绍举足轻重的存储器组织。
TLB与cache简介
对于computerarchitecture,除了流水线(pipelining)之外,存储器层次组织(memoryhierarchy)是另外一个重要的部分。软件方面,对linuxkernel的研究中,MMU是篇幅最多,也是最复杂的一部分。硬件方面,TLB和cache这两个词就比较常见了。
这一小节就回忆一下这两个概念吧。
首先,为什么要有memeryhierarchy?
(1)填补core和mainmemory之间的速度鸿沟。
(2)填补SDRAM和mainmemory之间的cost鸿沟。
(3)为了实现VirtualMemory
其次,为什么实现Virtual Memory?
历史上,有两个原因:其一,实现多个程序间高效的共享使用内存, 其二,避免对小内存系统编写程序的难度。现在主要是第一个原因。
最后是memory hierarchy内在原理,是局部性原理(principleof locality)这包括时间局部性(Temporallocality (locality in time))和空间局部性(Spatiallocality (locality in space))。 在介绍TLB 和 cache之前首先要明确几点:
(1)汇编完的程序里用到的内存地址是虚拟地址。也就是说core执行的load/stor指令中的内存地址是虚拟地址。
(2)对于多进程(线程)代码,编译时,操作系统会给每个进程分配不同的虚拟地址空间。
(3)内存是按页(page)来管理和使用的,典型值是4K bytes。
根据冯诺依曼体系结构,一切数据都来自内存。所以就需要访存(memoryaccess)。访问内存需要几步?大体上需要两步:
(1)将虚拟地址转换成物理地址。
(2)读/写这个物理地址的内容。
详细步骤:将虚拟地址转换成物理地址,就需要虚拟地址到物理地址的一个映射表(具体映射方法有直接映射,组相联,全相联)。这个表,就是页表(pagetable),页表由很多项组成,每一项叫一个页表项,由操作系统维护。创建进程的时候生成这个进程执行过程中用到的所有的页表项,其中一部分加载到内存中,另外一部分放在硬盘上,即,交换区(swapspace)。由于访存动作很多,所以虚拟地址到物理地址的转换动作就很多,也就是访问页表的次数很多,所以根据局部性原理,就把一部分页表项放到一个地方,这个地方就是TLB(translation-lookasidebuffer)。
现在,物理地址知道了,那就可以读/写内存对应的这个地址了。由于访存操作很多,所以根据局部性原理,就把经常访问的地址的数据放到一个地方,这样就不用每次都访问内存了,可以直接访问这个地方。这个地方,就是cache。由于TLB里面只有一部分页表项,所以有的就虚拟地址就在TLB里找不到对应的物理地址,这时,对于MIPS来说,会产生一个TLB miss的异常,然后由操作系统从内存中找到对应的页表项,然后将这个页表项放到TLB里面(注意,更新算法),然后让产生TLBmiss异常的那条指令重新执行一遍,这时TLB里已经有那一项了,也就能完成虚拟地址到物理地址的转换了。
如果,操作系统点儿背,内存里也没有对应的页表项,那就只能从硬盘上的swapspace里找了(交换区里肯定有),然后把它放到TLB里,然后让产生TLB miss异常的那条指令重新执行一遍,这时TLB里已经有那一项了,也就能完成虚拟地址到物理地址的转换了。
对于cache,有读,写之分。先说读,如果cache里面有,直接把cache里面的数据返回,即,读操作完成了。由于cache里面只有内存数据的一部分,所以有的数据cache里面没有,这时就只能产生读内存的地址信号,然后从数据线上取数据。然后更新cache(注意,更新算法)。
再说写,如果cache里面有,有两种方式:通写(write-through),写返回(write-back)。由于cache里面只有内存数据的一部分,所以有的数据cache里面没有,这时就只能产生写内存的地址信号,然后把数据放到数据线上。然后更新cache。
数据,可分为指令和普通数据。如果取指令和取普通数据各自使用一套memoryhierarchy,就有了ITLB,DTLB,icache,dcache。这就有点哈佛体系结构的意思了。即core内部采用哈佛体系结构,core外部采用冯-诺依曼体系结构。
下面是整体的流程。
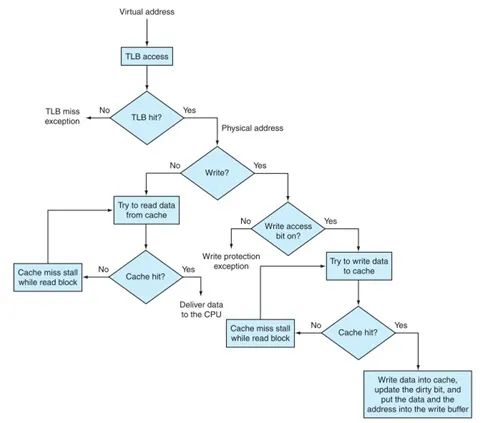
图1 TLB与cache的整体流程
TLB
MMU(memorymanagement unit),无论对于computerarchitecture designer还是OSdesigner,都是至关重要的部分,设计和使用的好坏,对性能影响比较大。
MMU,是硬件和软件配合最密切的部分之一,对于RISCCPU而言,更是这样。
前面,我们对or1200的整体memoryhierarchy做了简单分析,了解了cache的映射方式,替换策略,写策略,以及cache的优化等等背景知识,并对or1200的具体实现做了分析。在现实中,cache往往和MMU紧密合作,完成CPU的访存操作。本小节就来分析一下or1200的MMU模块。
研究一个东西,首先要了解其来龙去脉,MMU也不例外,我们在分析MMU的工作机制之前先介绍一下MMU的产生原因。
当时,主要由两方面的因素导致了MMU的产生:
(1)从安全角度出发,确保多进程程序在执行时相互不影响。
(2)从程序员的角度出发,采用MMU可以让程序员在编程时少受内容容量的限制。
现在而言,第一个原因占主要。
在分析or1200的MMU实现之前,我们有必要先了解MMU的工作机制。
为了更清晰的了解MMU的工作过程,我假设了一个具体的例子,通过这个例子来说明其详细的工作步骤。
比如,我们编写了一个简单的应用层程序:
代码清单 1 一个简单的应用层程序
1. /*demo process, base on OS*/
2. int main()
3.
4. int test;
5. test = 0x12345678;
6.
(1)假设其进程名称为demo。
(2)假设片外SDRAM(内存)大小为32MB。其中内核空间16MB,用户空间16MB。
(3)假设OS的内存管理方式是单级页式管理(还可能是段式,或页段式),虚拟地址和物理地址均为32-bit。
既然ps是8KB,也就是说最多需要的PTE的数量是:pte_num=32MB/8KB=4K。假设每个PTE是4Bytes,那么存放这些PTE一共需要的内存大小是:4Bytes X4K=16KB。
(4)假设OS在执行进程demo之前,给她分配的地址空间大小为6页(page size= 8KB),也就是48K。这48KB是连续的,其起始物理地址第0x801页,也就是19'h801,13'h01。所以其地址空间是0x801页,0x802页,0x803页,0x804页,0x805页,0x806页,共6页。
既然其进程空间是48KB,每页是8K,也就是说OS需要给demo进程生成6个PTE(pagetable entry,页表项)。
(5)假设这6个PTE存放在kernel空间的第0x600个页,即进程demo的PTE存放开始物理地址是0x600000,虚拟地址假设是0x12345000。
(6)假设这进程这6页的地址空间的分配方式是:
代码段,1页;
bss段,1页;
栈,1页;
堆,1页;
数据段,2页。
(7)假设进程demo中的变量test的地址在栈段,并且其页内偏移为0x1。
(8)假设OS给进程demo中变量test分配的虚拟地址为0x2001,物理地址为:0x1006001。
(9)假设TLB的cacheentry数量是64,映射方式是直接映射,也就是说通过VPN进行模运算就可以得到TLB的索引地址。
有了上面的假设,那么MMU是如何工作的呢?
MMU的功能主要是虚实地址转换,PTE的cache(也就是TLB)。其具体过程,如下图所示:
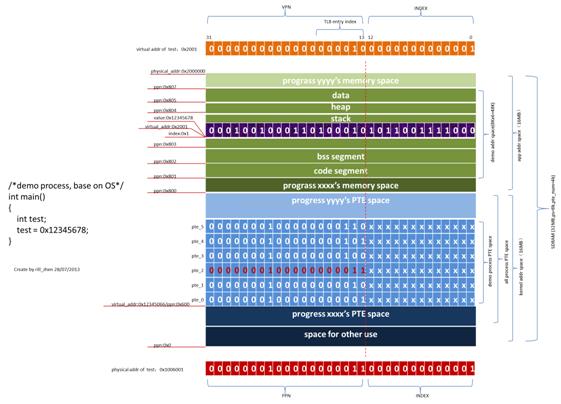
图 2 MMU工作的具体过程
其工作过程如下:
为了实现虚实地址转换,OS为每页创建了一个页表项(PTE,pagetable entry,由PPN域和管理域组成),每个虚拟地址也分成了两部分,分别是VPN和INDEX,通过VPN的低6位(因为TLBcache是64 entry)定位到TLB的偏移量。
如果相应的偏移量处TLB hit,那么就可以直接得到对应的PTE,有了PTE,我们就可以得到PTE中的PPN,PPN和INDEX组合在一起,就是物理地址。
如果相应的偏移量处TLB miss或者页面异常,那么MMU产生一个TLB miss或者page fault异常,交给OS完成异常的处理(TLB的更新,和其它操作)。
对于本演示例子来说,变量test的虚拟地址是0x2001,可见其TLB entry偏移量是0x2,页内偏移量是0x1;VPN是0x2。那么,MMU是如何将这个虚拟地址换换成物理地址的呢?
首先,OS会根据进程demo的进程号(PID,OR也有CID(contextID)保存,DTLBWMR中的CID域),和DMMUCR(DMMU 控制寄存器)中的PTBP(pagetable base pointer),得到进程demo的页表的存放的开始地址(0x600000),然后得到对应的PTE的地址(0x600008)根据TLB的偏移0x2,查看对应的TLB的第2个cacheline,如果匹配,则进一步和MR(machregister)中的VPN比较,如果也匹配,好,恭喜你,TLB hit,并将对应的PTE(pte_2)的PPN(0x803)和INDEX(13'b0_0000_0000_0001)组合成物理地址(0x1006001),传给qmem模块,sb模块,biu模块,经dbus_arbiter,memorycontroller,最终实现读写SDRAM的对应地址。
如果TLB miss(对应的pte_2),那么OS查看异常寄存器,得到具体的异常信息,并最终将pte_2更新到TLB中,重新执行MMU操作,则TLB hit,完成转换过程。
上面的过程,如果用一幅图来展示的话,如下所示:
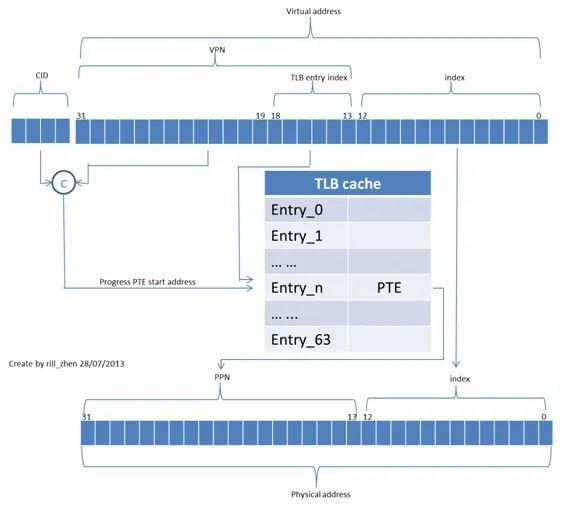
图 3 虚实地址转换
上面介绍的OS的页表是单级的,这样的话,在搜索对应的PTE时需要依次遍历所有的PTE表项,显然比较慢,为了加快搜索速度,linux采用了两级PTE页表。
其基本思想是将所有的PTE进行分组,每一组由一个PTD(PT directory,我自己给起的名字),每个PTD项对应一组PT。
这样,在搜索时,先确定其所在的页表目录,然后只需要遍历本目录中的PTE就可以了。
其操作过程和单级页表相似,如下图所示:
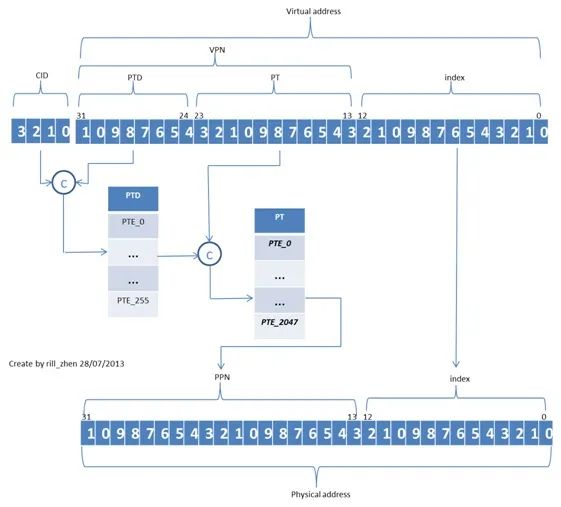
图4 两级页表的虚实地址转换
上面通过一个例子,说明了MMU的工作机制,大体可概括如下:
(1)根据进程ID寄存器(这个寄存器的值是OS在进行进程切换时填进去的)和VPN得到存放对应页表项的PTE的地址,主要使用CID和PTBP得到页表目录或页表的存放的开始地址。并根据VPN得到具体页表项的地址,从而获得对应的页表项(PTE)。
(2)从PTE中得到PPN
(3)PPN与INDEX组合,得到物理地址
(4)从上面的分析,可以看出,CPU对PTE的访问是非常频繁的,为了加快速度,将部分PTE放到cache里面,这个cache就是TLB。TLB 这个cache的映射方式一般采用directmapped,而不是fullyassociative,和setassociative。因为TLB一般都很小,前面章节我们提到如果cache很小的时候才用直接映射,延迟小,电路简单。
(5)上面描述的过程是一帆风顺的情况,实际可不如此,如果出现TLBmiss,如何处理呢?硬件提供OS事先设置的当前进程的页表存放的起始地址,页表项的偏移地址,OS利用这些信息找到对应的PTE,并将PTE中的信息取出来分别存放到匹配寄存器和转换寄存器的对应位置,完成TLB的更新。
从中可以看出,整个处理过程,需要软件硬件的巧妙的,天衣无缝的配合才行,那么具体是怎么处理的呢?我们通过查CPU的手册可知,比如DTLB miss的异常入口地址是0x900,那么基于某个CPU的linux是如何实现的呢?参考head.S中相关代码(soc-design\\linux\\arch\\openrisc\\kernel)。
说到这里,你可能有一个疑问,“你一直说,如果出现TLB miss,OS计算出对应的PTE的地址,然后取出内容,更新TLB”,既然TLB miss之后需要访问内存获得对应的PTE,那么访问这个PTE时,PTE的地址也不在TLB中怎么办呢?!这个你不用担心,原因就是所有的页表项都存放在内存的kseg0段,而这段内存的访问是是不用MMU的。kseg0段除了放这些PTE外,也是存放异常处理程序的地方,你想啊,如果产生了一个异常,假设这个异常的处理入口地址是0x900,这个0x900肯定是物理地址,是不需要MMU的,如果这个0x900也经过MMU处理就乱套了,物理地址转虚拟地址,虚拟地址转物理地址,是一个相向的过程,系统要想正常运行,必须要有一个起源,而物理地址就是起源,虚拟地址只不过是为了达到某种效果而引进的一种手段而已。
其实,对于一些内存地址空间,是不能用MMU的,比如kernel使用的存放PTE的地方,还有就是异常/中断处理程序的入口,这些是不能使用MMU的。原因是如下:
如果PTE的存放地址也使用MMU的话,一但出现TLB miss,kernel需要访问这些PTE,而这些PTE的地址也是经过MMU的,就有可能再次产生TLB miss,这就出现了异常的嵌套,而且嵌套深度是无法确定的。
如果存放异常向量的地址使用MMU,那么一旦出现一个异常之后,PC需要从这个地址取值,但是这个地址经过MMU时,也可能出现TLB miss,也会有异常嵌套的问题。所以,我们平时所说的某个异常入口地址是0x200,这个‘0x200’是物理地址,是不需要虚实转换的。
MMU,cache确实有它的好处,其重要性也是有目共睹,但并不是适用于所有方面,上面所说的内核空间的kseg0段是禁止MMU的,除此之外,kseg1段,MMU和cache都是禁止的。从这个角度来看,无论是什么事情,都要‘有所为有所不为’,不要跟风,不要认为是好东西就可以随便用,要取其长,补己短,该出手时才出手。
代码清单 2 DTLB miss异常入口
1. /* ---[ 0x900: DTLB miss exception ]------------------------------------- */
2. .org 0x900
3. l.j boot_dtlb_miss_handler
4. l.nop
代码清单 3 DTLB miss 异常处理
1. /* ---[ boot dtlb miss handler ]----------------------------------------- */
2.
3. boot_dtlb_miss_handler:
4.
5. /* mask for DTLB_MR register: - (0) sets V (valid) bit,
6. * - (31-12) sets bits belonging to VPN (31-12)
7. */
8. #define DTLB_MR_MASK 0xfffff001
9.
10./* mask for DTLB_TR register: - (2) sets CI (cache inhibit) bit,
11. * - (4) sets A (access) bit,
12. * - (5) sets D (dirty) bit,
13. * - (8) sets SRE (superuser read) bit
14. * - (9) sets SWE (superuser write) bit
15. * - (31-12) sets bits belonging to VPN (31-12)
16. */
17.#define DTLB_TR_MASK 0xfffff332
18.
19./* These are for masking out the VPN/PPN value from the MR/TR registers...
20. * it's not the same as the PFN */
21.#define VPN_MASK 0xfffff000
22.#define PPN_MASK 0xfffff000
23.
24.
25. EXCEPTION_STORE_GPR6
26.
27.#if 0
28. l.mfspr r6,r0,SPR_ESR_BASE //
29. l.andi r6,r6,SPR_SR_SM // are we in kernel mode ?
30. l.sfeqi r6,0 // r6 == 0x1 --> SM
31. l.bf exit_with_no_dtranslation //
32. l.nop
33.#endif
34.
35. /* this could be optimized by moving storing of
36. * non r6 registers here, and jumping r6 restore
37. * if not in supervisor mode
38. */
39.
40. EXCEPTION_STORE_GPR2
41. EXCEPTION_STORE_GPR3
42. EXCEPTION_STORE_GPR4
43. EXCEPTION_STORE_GPR5
44.
45. l.mfspr r4,r0,SPR_EEAR_BASE // get the offending EA
46.
47.immediate_translation:
48. CLEAR_GPR(r6)
49.
50. l.srli r3,r4,0xd // r3 <- r4 / 8192 (sets are relative to page size (8Kb) NOT VPN size (4Kb)
51.
52. l.mfspr r6, r0, SPR_DMMUCFGR
53. l.andi r6, r6, SPR_DMMUCFGR_NTS
54. l.srli r6, r6, SPR_DMMUCFGR_NTS_OFF
55. l.ori r5, r0, 0x1
56. l.sll r5, r5, r6 // r5 = number DMMU sets
57. l.addi r6, r5, -1 // r6 = nsets mask
58. l.and r2, r3, r6 // r2 <- r3 % NSETS_MASK
59.
60. l.or r6,r6,r4 // r6 <- r4
61. l.ori r6,r6,~(VPN_MASK) // r6 <- VPN :VPN .xfff - clear up lo(r6) to 0x**** *fff
62. l.movhi r5,hi(DTLB_MR_MASK) // r5 <- ffff:0000.x000
63. l.ori r5,r5,lo(DTLB_MR_MASK) // r5 <- ffff:1111.x001 - apply DTLB_MR_MASK
64. l.and r5,r5,r6 // r5 <- VPN :VPN .x001 - we have DTLBMR entry
65. l.mtspr r2,r5,SPR_DTLBMR_BASE(0) // set DTLBMR
66.
67. /* set up DTLB with no translation for EA <= 0xbfffffff */
68. LOAD_SYMBOL_2_GPR(r6,0xbfffffff)
69. l.sfgeu r6,r4 // flag if r6 >= r4 (if 0xbfffffff >= EA)
70. l.bf 1f // goto out
71. l.and r3,r4,r4 // delay slot :: 24 <- r4 (if flag==1)
72.
73. tophys(r3,r4) // r3 <- PA
74.1:
75. l.ori r3,r3,~(PPN_MASK) // r3 <- PPN :PPN .xfff - clear up lo(r6) to 0x**** *fff
76. l.movhi r5,hi(DTLB_TR_MASK) // r5 <- ffff:0000.x000
77. l.ori r5,r5,lo(DTLB_TR_MASK) // r5 <- ffff:1111.x330 - apply DTLB_MR_MASK
78. l.and r5,r5,r3 // r5 <- PPN :PPN .x330 - we have DTLBTR entry
79. l.mtspr r2,r5,SPR_DTLBTR_BASE(0) // set DTLBTR
80.
81. EXCEPTION_LOAD_GPR6
82. EXCEPTION_LOAD_GPR5
83. EXCEPTION_LOAD_GPR4
84. EXCEPTION_LOAD_GPR3
85. EXCEPTION_LOAD_GPR2
86.
87. l.rfe // SR <- ESR, PC <- EPC
88.
89.exit_with_no_dtranslation:
90. /* EA out of memory or not in supervisor mode */
91. EXCEPTION_LOAD_GPR6
92. EXCEPTION_LOAD_GPR4
93. l.j _di
精彩回顾
更多精彩尽在"Linux阅码场",扫描下方二维码关注


别忘了分享、点赞或者在看哦~
以上是关于甄建勇:五分钟搞定MMU的主要内容,如果未能解决你的问题,请参考以下文章