MetaSelector:基于用户级自适应模型选择的元学习推荐
Posted 研行笔录
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MetaSelector:基于用户级自适应模型选择的元学习推荐相关的知识,希望对你有一定的参考价值。
文章目录
前言
大家好,小曾哥回来了,时隔两个多月没有更新了,在此深感抱歉。 主要原因是自己的研究方向也遇到瓶颈,实验效果不理想,需要拓宽自己的知识面,因此近期也在不断充电,需要不断的深潜,沉淀!
但是我也不会忘记我的初心,希望能够记录自己在研究生阶段的学习记录,希望与君共勉之!
今天主要给大家分享一篇最近看的文章,是2020年发表在WWW上的论文。
论文题目 MetaSelector: Meta-Learning for Recommendation with User-Level Adaptive Model Selection
原文链接:https://arxiv.org/abs/2001.10378
相信大家会有个疑问,小曾哥,你的方向并不是物品推荐方向吧?
雀氏,这也是我们看论文的惯性思维,不在这个方向的就不看其他方面的内容。这就是我们需要擦亮眼睛的地方,要打破桎梏,我们看到的更多的是寻找A与B的联系!

Abstract
现在小曾哥带你们看看这篇文章讲的什么?
- 主要是提出了一个元学习框架,以促进推荐系统中对用户类型的自适应模型选择。
- 具体内容:在此框架中,将使用来自所有用户的数据来训练推荐系统集合,然后通过元学习对模型选择器进行训练,以使用用户特定的历史数据为每个用户选择最佳的单个模型。
- 实验效果:在两个公共数据集和一个真实世界的生产数据集上进行了广泛的实验,证明了我们提出的框架在AUC和LogLoss方面实现了对单个模型基线和样本级别模型选择器的改进
Background
什么叫元学习?
概念:元学习(Meta-Learing),又称“学会学习“(Learning to learn), 即利用以往的知识经验来指导新任务的学习,使网络具备学会学习的能力。
应用:(1)让Alphago迅速学会下象棋 (2)让一个猫咪图片分类器,迅速具有分类其他物体的能力。
元学习与机器学习的区别
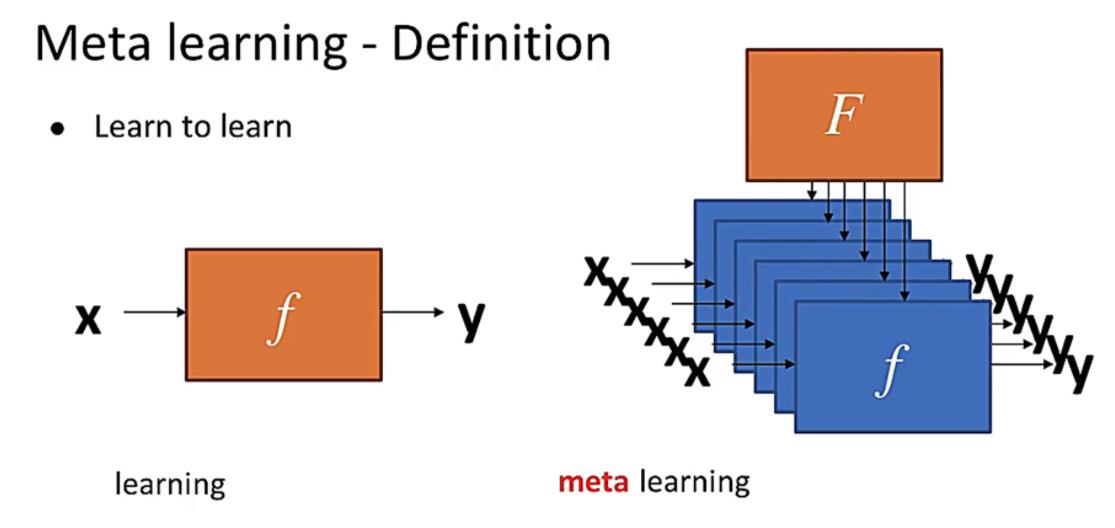

左图所示:机器学习,主要通过输入训练数据(training data),经过人工设计的网络结构或者算法,最终学出来一个f,在测试集中直接输入猫的图片,则f 判别出cat的结果。
机器学习学习某个数据分布X到另一个分布Y的映射
右图所示:元学习,输入的是D_train的任务,希望能够学习出F,不需要人工设计算法等,希望通过多个输入的任务,然后学习出一个算法或者网络参数,最终输出最优函数f,然后根据训练集中的测试集,作用于f来判断猫的标签。
元学习学习的是某个任务集合D到每个任务对应的最优函数f的映射(任务到学习函数的映射)
其中需要注意的是,机器学习的目的是找到一个Function,直接作用于特征和标签,寻找特征与标签之间的关联;元学习是寻找一个大Function,用于寻找新的f,新的f才会对应具体的任务
元学习数据分布

在元学习训练阶段(Meta-training), 训练单位分层级了,第一层训练单位是任务,也就是说,元学习中要准备许多任务来进行学习,第二层训练单位才是每个任务对应的数据。(训练样本中的训练集一般称作support set,训练样本中的测试集一般叫做query set)
推荐系统
概念:随着信息技术和互联网技术的发展,人们从信息匮乏时代步入了信息过载时代,在这种时代背景下,人们越来越难从大量的信息中找到自身感兴趣的信息,信息也越来越难展示给可能对它感兴趣的用户,而推荐系统的任务就是连接用户和信息,创造价值。
显著特征:(1)主动化,通过分析用户和物品的数据,对用户和物品进行建模,从而主动为用户推荐他们感兴趣的信息。(2)个性化
常用方法:基于用户的协同过滤,给用户推荐和他兴趣相似的用户感兴趣的物品。
普遍问题:由于用户之间的数据分布不均,因此没有一个的最佳模型可以为每个用户提供最佳推荐结果。这意味着不同用户之间的推荐质量差异很大,并且某些用户可能收到的推荐不令人满意。
Contributions:
- 讨论了推荐系统的模型选择问题,其动机是观察到不同用户在公共数据集和生产数据集上的不同模型的性能差异。
- 提出了一种新的模型选择框架–MetaSelector,该框架引入元学习的思想,在混合推荐系统中构建了一个用户级的模型选择模块,该模型选择模块涉及两个或多个推荐模型的组合,该框架可以端到端地训练,不需要手动定义元特征。据我们所知,这是第一个从基于优化的元学习角度研究推荐模型选择问题的工作。
- 在公共和私有生产数据集上进行了广泛的实验,结果表明,元选择器可以提高单一模型基线和样本级选择器的性能,显示了元选择器在实际推荐系统中的潜力。
Method
MetaSelector framework
- Mete-Learning 任务定义为学习预测用户选择偏好的模型
- MetaSelector学习从多个任务中进行模型选择,其中一个任务由一个用户的数据组成
- 给定推荐请求作为输入,MetaSelector在推荐模型上输出概率分布
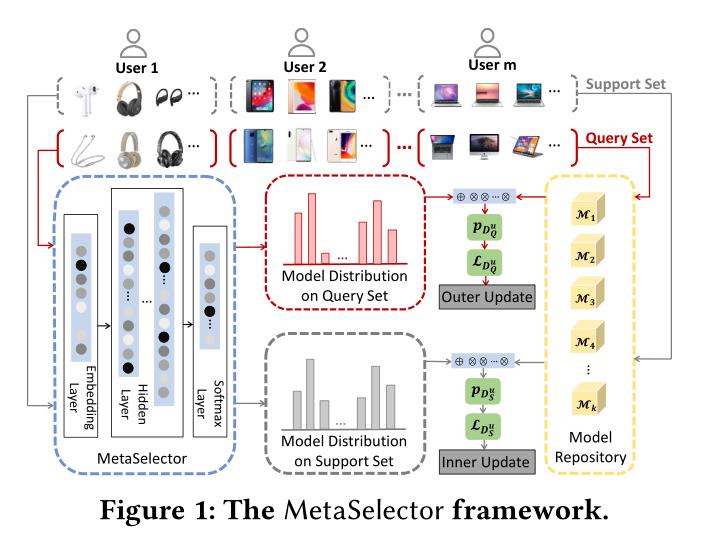
MetaSelector包含两个主要模块:基本模型模块和模型选择模块
基本模型模块
基本模型M是指参数化推荐模型,例如LR或DeepFM;具有参数θ的模型M用M(·;θ)表示,这样,给定特征x时,该模型输出M(x;θ)作为真实标签y的预测。
模型选择模块
该模块包含一个在基本模型模块之上运行的模型选择器S,模型选择器S将数据特征x和基础模型M(x;θ)的输出作为输入=(M(x;θ1),M(x;θ2),…,M(x;θK)) θ=(θ1,θ2,…θK),并输出基本模型的分布。
MetaSelector 框架主要内容:首先将用户数据集分为Support set (x,y)和 Query set(x,y),作为特征X输入,经过Embedding layer 、Hidden layer、归一化后(可以将这个过程看成是多层感知机MLP),输出每个特征在K个模型的概率分布λ,然后再根据与基本模型M(x;θk)相乘,得到模型的概率P,计算loss损失来更新参数θ和φ
训练MetaSelector
MetaSelector与以前的模型选择方法区分开的关键因素是,我们使用元学习来学习模型选择器S, 用MAM联合学习模型选择器和基础模型

下面就来当一回“庖丁”,带着大家一起来解析这头牛(算法1)
Episodic Meta-training
元训练过程以轮次来进行, 在每轮中,从大量训练人群中抽取一批用户作为任务(第5行)。 对于每个用户u,从Du采样一个支持集DuS和一个查询集DuQ,它们分别被视为对应于用户u的任务中的“训练”集和“测试”集(第7行),对应于每个任务Task来说执行内循环(8-18),在内循环结束后进入外循环,得到θu和φu的损失函数来更新选择器中的初始化参数φ和基础模型的参数θ(第20行)
Inner task Adaptation
下面我们就来单独分析内循环过程(第8-18行),首先给定当前固定的参数θ和φ,MetaSelector首先迭代支持集DuS以在基本模型上生成每项分布λ(第9行)然后得到最终预测p(x;θ,φ)是输出M(x;θ)的凸组合(第10行),计算在DuS中的数据点的损失 L D S u ( θ , φ ) \\mathcalL_D_S^u(\\theta, \\varphi) LDSu(θ,φ),对基础模型和模型选择器的参数执行梯度更新步骤,从而得出适用于特定任务的一组新参数θu和φu(第13行),同理使用更新后的基本模型参数和模型选择器(第14-18行),以与计算训练损失类似的方式,在查询集上计算出测试损失 L D S u ( θ , φ ) \\mathcalL_D_S^u(\\theta, \\varphi) LDSu(θ,φ)
需要注意的是:内循环的路径从(θ,φ)到(θu,φu),可以将测试损失LDQu(θu,φu)表示为θ和φ的函数,并传递到外循环以更新θ和φ
Jointly Meta-training θ and φ
θ和φ在外部循环(第20行)中一起更新,分别用作基础模型和模型选择器的初始化,更新参数以适应每个用户(第13行)。元训练的目标可以表示为: min θ , φ E u ∈ U [ L D Q u ( ( θ , φ ) − α ∇ θ , φ L D S u ( θ , φ ) ) ] \\min _\\theta, \\varphi \\mathbbE_u \\in U\\left[\\mathcalL_D_Q^u\\left((\\theta, \\varphi)-\\alpha \\nabla_\\theta, \\varphi \\mathcalL_D_S^u(\\theta, \\varphi)\\right)\\right] θ,φminEu∈U[LDQu((θ,φ)−α∇θ,φLDSu(θ,φ))]
Learning Inner Learning Rate α
内部学习率α在正常模型训练过程中通常是一个超参数,也可以通过将损失函数也视为α的函数,在元学习方法中进行学习。结果表明,每组参数学习的内部学习率α(与θ长度相同的向量)相对于MAML在回归和图像分类方面取得了一致的提高。 可以对算法1进行相应的修改:在第13行中,内部更新步骤变为:
(
θ
u
,
φ
u
)
←
(
θ
,
φ
)
−
α
∘
∇
θ
,
φ
L
D
S
u
(
θ
,
φ
)
\\left(\\theta^u, \\varphi^u\\right) \\leftarrow(\\theta, \\varphi)-\\alpha \\circ \\nabla_\\theta, \\varphi \\mathcalL_D_S^u(\\theta, \\varphi)
(θu,φu)←(θ,φ)−α∘∇θ,φLDSu(θ,φ)
其中◦表示Hadamard积。 考虑θu,φu作为α的函数,第20行的外部更新步骤变为:
(
θ
,
φ
,
α
)
←
(
θ
,
φ
,
α
)
−
β
⋅
1
m
∑
u
∈
U
t
∇
θ
,
φ
,
α
L
D
Q
u
(
θ
u
,
φ
u
)
(\\theta, \\varphi, \\alpha) \\leftarrow(\\theta, \\varphi, \\alpha)-\\beta \\cdot \\frac1m \\sum_u \\in U_t \\nabla_\\theta, \\varphi, \\alpha \\mathcalL_D_Q^u\\left(\\theta^u, \\varphi^u\\right)
(θ,φ,α)←(θ,φ,α)−β⋅m1u∈Ut∑∇θ,φ,αLDQu(θu,φu)
Simplifying
论文为MetaSelector提出了元训练的简化版本,其中不需要针对基本模型进行任务内调整。基本模型在元训练之前被预先训练,然后被固定,只训练模型选择器。
Experiment
数据集
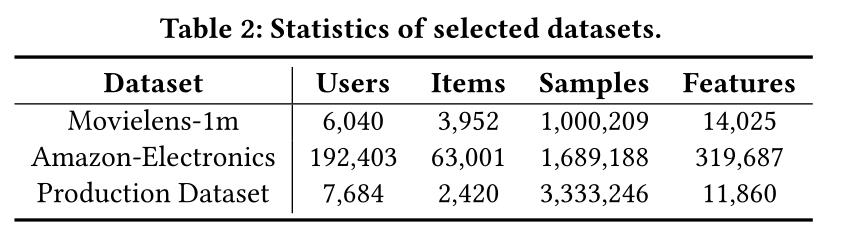
- Movielens-1m:包含来自6040个用户的100万个电影评分,每个用户至少具有20个分级。我们将5星和4星评级作为正面反馈,并用1标记,其余标记用0标记。
- Amazon-Electronics:包含来自亚马逊的用户评论和元数据,已被广泛用于产品推荐。我们从集合中选择一个名为Amazon-Electronics的子集,并将其成形为二进制分类问题,例如Movielens-1m。我们保留至少5个评分的用户。
- Production Dataset:为了证明我们提出的方法在实际应用中的有效性以及用户上的自然数据分布,我们还根据工业推荐任务在大型生产数据集上评估了我们的方法。我们的目标是根据用户的历史行为来预测用户点击推荐的移动服务的可能性。 在此数据集中,每个用户至少有203条历史记录。
baseline
单一模型:LR、FM、DeepFM
样本级选择器和用户级选择器:这两种方法用作MetaSelector竞争者。 他们旨在预测每个样本和每个用户的模型概率分布。
评价指标 & 实验结果
除了AUC和logloss,文章使用 RelaImpr 作为评价指标,来衡量模型的相对提升情况,对于随机的情况auc为0.5,所以可以得到RelaImpr的公式:
RelaImpr
=
(
A
U
C
(
to be compared
)
−
0.5
A
U
C
(
single best model
)
−
0.5
−
1
)
×
100
%
.
\\text RelaImpr =\\left(\\fracA U C(\\text to be compared )-0.5A U C(\\text single best \\text model )-0.5-1\\right) \\times 100 \\% \\text .
RelaImpr =(AUC( single best model )−0.5AUC( to be compared )−0.5−1)×100%.
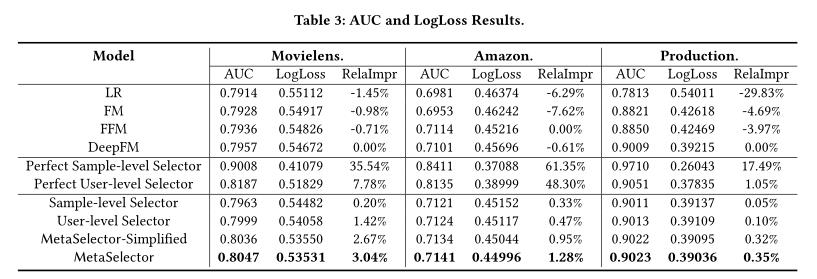
相信很多人有个疑惑?MetaSelector的效果在最后四行效果是比较好的,而对应的中间两行完美样本级选择器和完美用户级选择器则偏低。
为了探索模型选择方法的潜力和局限性,我们通过两个完美的模型选择器来计算上限,(1)完美样本级选择器,为每个样本选择最佳模型;(2)完美用户级选择器,为每个用户选择最佳模型。
1、比较样本级选择器和用户级选择器,我们发现完美的样本级模型选择器将比完美的用户级选择器获得更大的改进。
2、在实际的选择器性能表现中,用户级选择器实现了更高的AUC和更低的Logoss,而不是样本级选择器。这一发现意味着,样本之间的差异可能过于微妙,以至于选择器无法很好地拟合。相比之下,不同用户的潜在特征差异很大,这使得Meta Selector工作得很好。
为什么MetaSelector效果比较好?换句话说,MetaSelector在哪些方面帮助了模型选择?
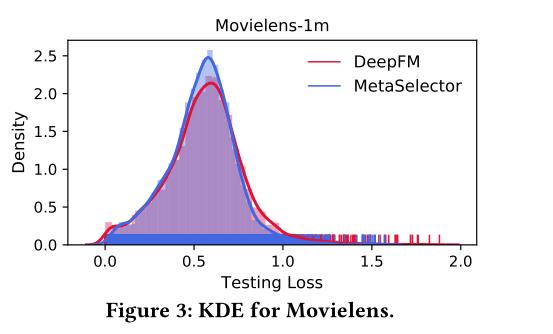
图3显示了MetaSelector和DeepFM的核密度估计,这是一个强大的单一模型基线。我们观察到,MetaSelector不仅可以降低平均LogLoss,而且可以以更低的方差获得更集中的损失分布。这表明MetaSelector鼓励在用户之间更公平地分配损失,并且能够对不同类型的用户进行建模。
Conclusions
这篇文章主要是利用MAML的思想对推荐系统中模型选择场景进行建模,一种新颖的框架MetaSelector,该框架引入了元学习,从而在涉及两个或多个推荐模型的混合推荐系统中制定了用户级模型选择模块。
这个思路值得我们借鉴,将现有的方法来解决目前所遇到的问题,也是一种别样的创新,因此拓宽知识面还是很有必要,大家一起共勉,跟着小曾哥,带你们一起沉淀,充电!
以上是关于MetaSelector:基于用户级自适应模型选择的元学习推荐的主要内容,如果未能解决你的问题,请参考以下文章
python绘制自适应的误差图和系数图(基于logistic模型和lasso正则化)
怎么让div的宽度不变,高度自适应内容的高度,新手求举例,谢谢