linux-0.11 文件系统介绍
Posted 流楚丶格念
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux-0.11 文件系统介绍相关的知识,希望对你有一定的参考价值。
文章目录
1.简介
文件系统是数据的组织方式,也就是将它们组织的符合一定的格式或者规律,就命名为文件系统了,并不神秘。
linux-0.11 将文件系统分成几个部分,分别为:
超级块,i-node节点位图,块位图,数据块。
2.基础知识
先看整个系统的流程框架:
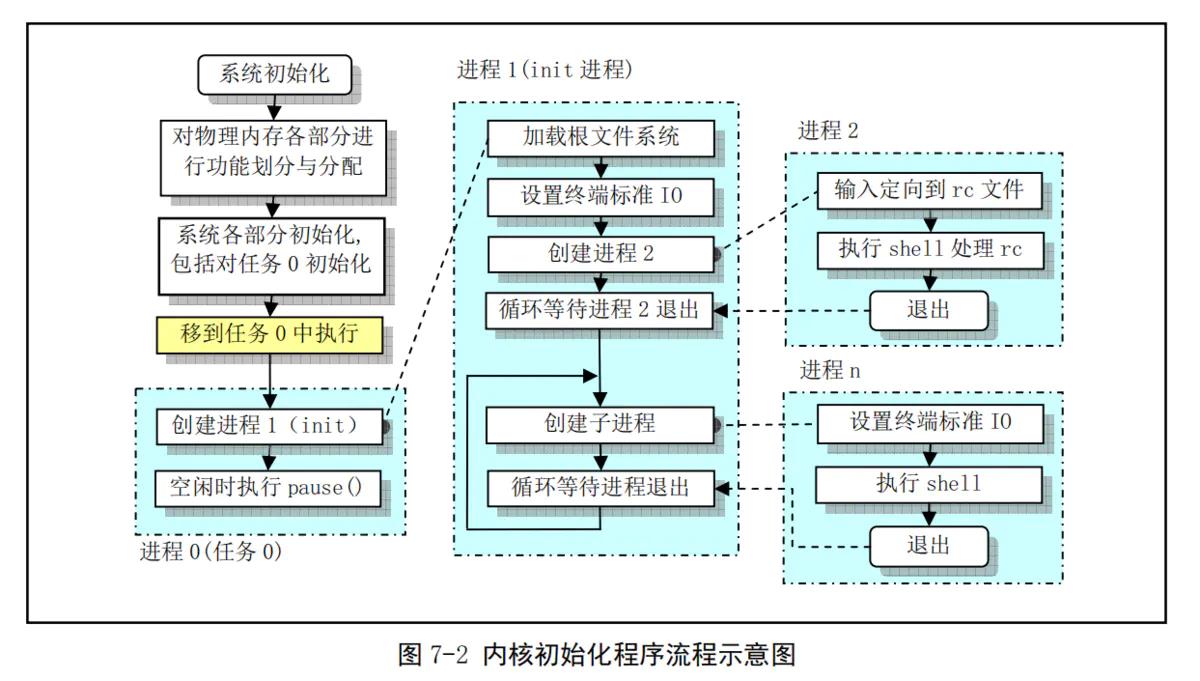
系统执行流程框架
2.1 文件系统结构
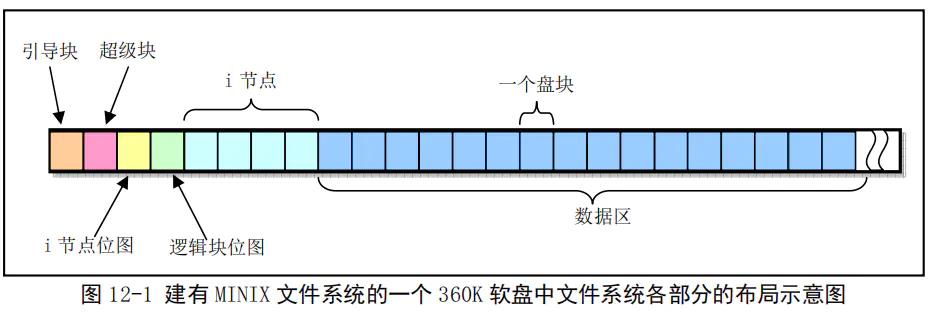
文件系统包含引导块、超级块、i-node位图、逻辑块位图、i节点与数据区等。
2.2 i-node节点
根据文件名获取文件内容步骤:
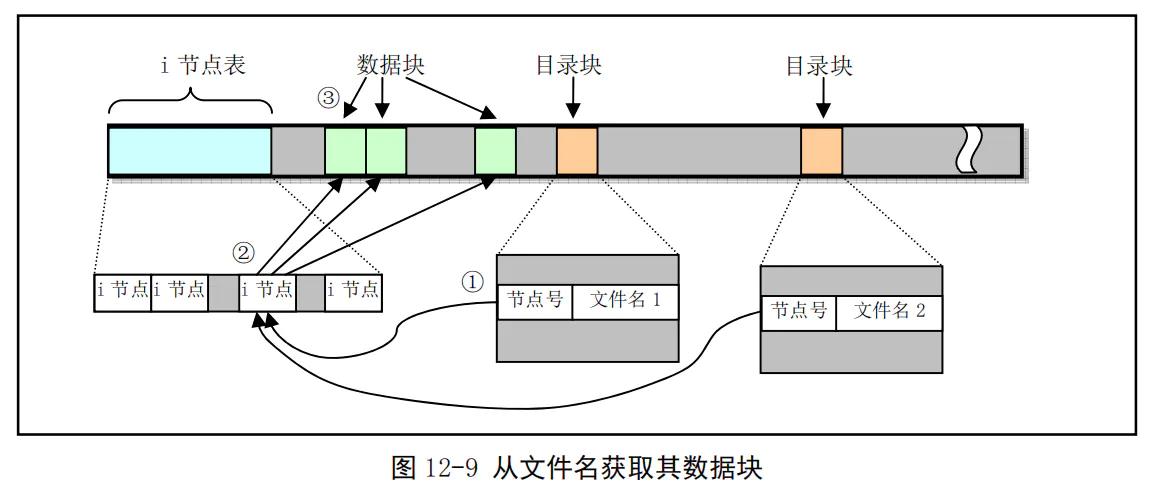
我来简单说一下寻找文件的步骤:
a.寻找hello.txt文件
由于根目录i节点是确定的,通过这个节点信息可以知道i_size,也就是目录数目,也知道i_zone[9],也就是存放的目录的块的块位置,那么就可以定位到要找的位置,然后就可以通过文件名获取到i节点了,根据i节点也就能定位到hello.txt内容了。
b.寻找/mnt/hello.txt文件
根据上面的步骤,先找到mnt目录的节点,然后找到其目录,获取到大小i_size,如果文件系统是干净的,i_size值应该为3,然后就可以按照上面的a步骤获取到hello.txt了。
2.3 高速缓冲区
先看一下高速缓冲的布局图:
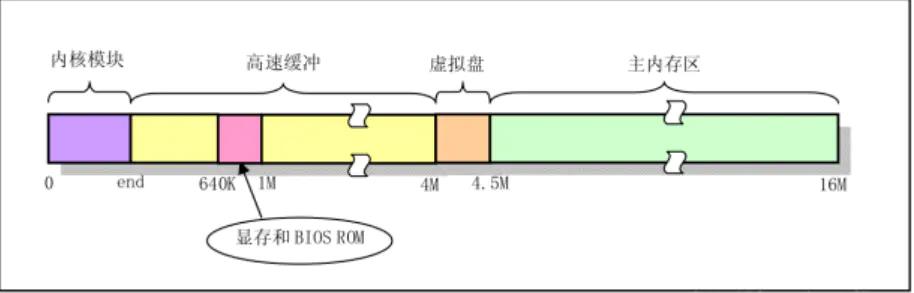
缓冲区结构图:
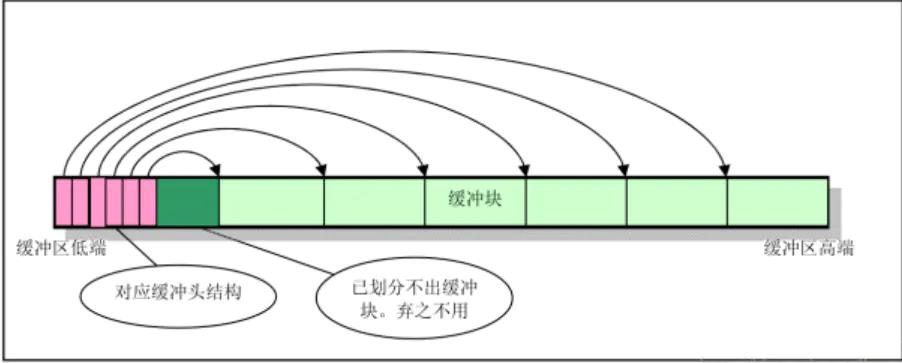
缓冲区链表结构:
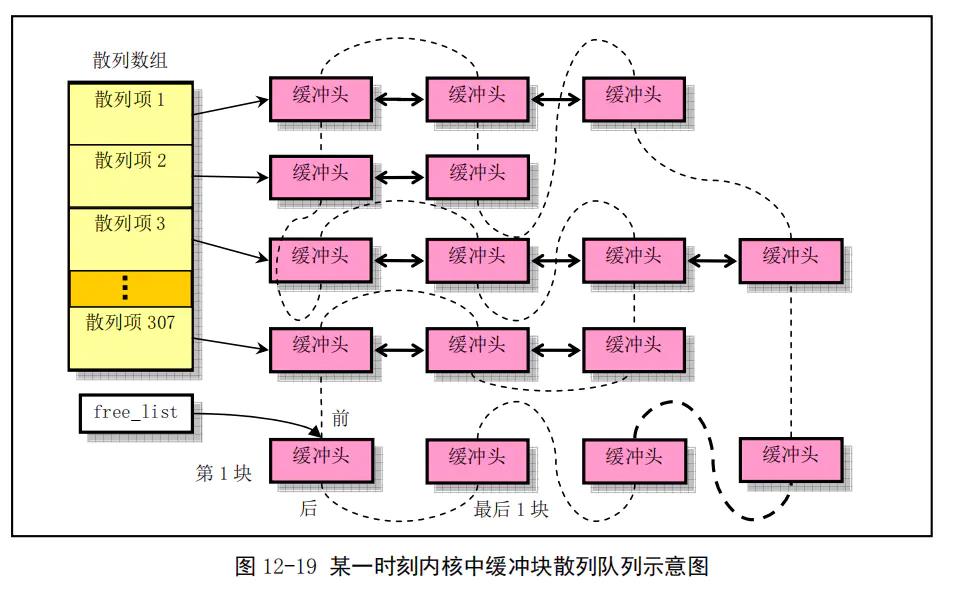
根据上图,可以从内核中找到在hash数组中找到某一个缓冲头的代码:
static struct buffer_head * find_buffer(int dev, int block)
struct buffer_head * tmp;
for (tmp = hash(dev,block) ; tmp != NULL ; tmp = tmp->b_next)
if (tmp->b_dev==dev && tmp->b_blocknr==block)
return tmp;
return NULL;
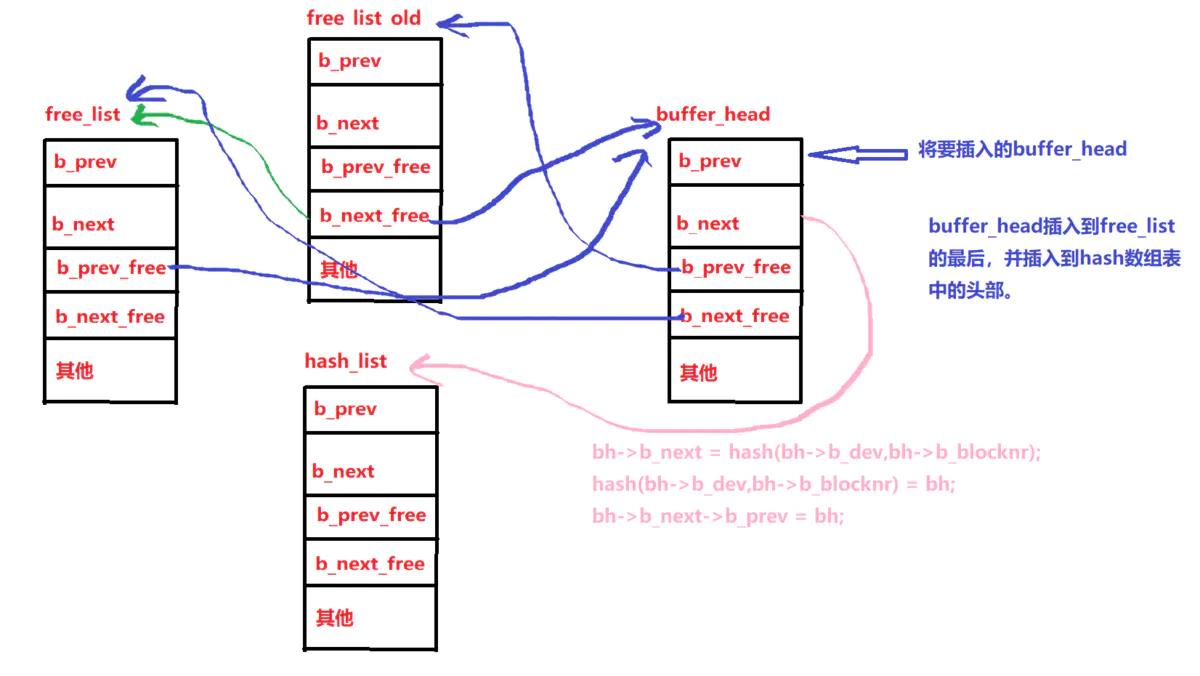
然后是将得到的块插入到free_list和hash表中的示意图:
3.内核重要函数分析
3.1 内核同步函数
3.1.1 wake_up()与sleep_on()
sleep_on()函数是用来等待资源是否可用,如果可用,则该函数退出,否则一直阻塞,最终是阻塞在函数schedule()中。
现在来分析3个进程task1,task2,task3阻塞在同一个资源的情况。
我列出具体工作情况:
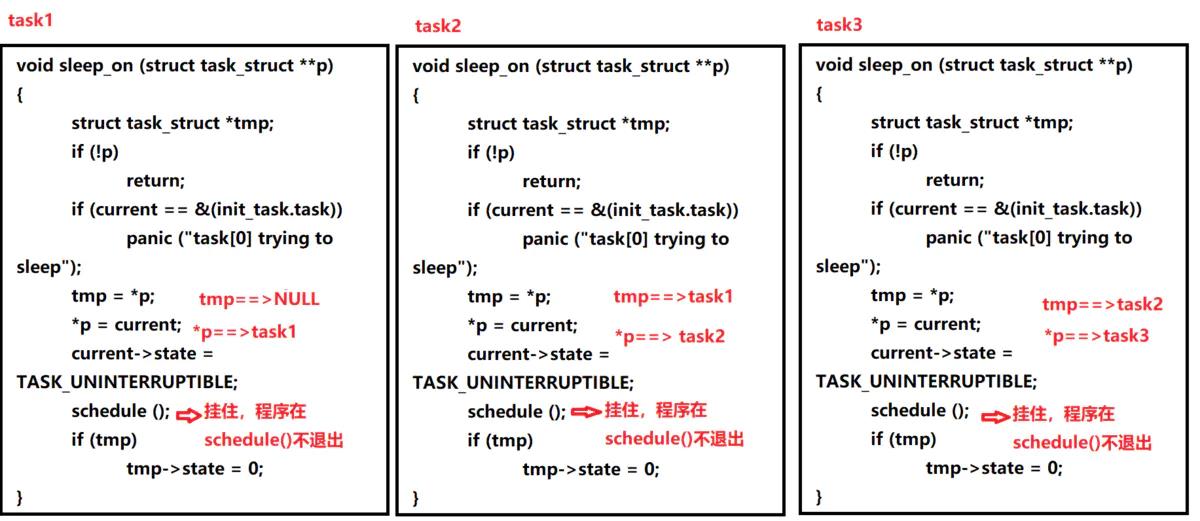
task1在第一次使用资源的时候,tmp=NULL,而当前任务状态为TASK_UNINTERRUPTIBLE,所以schedule()函数不退出。而task2则由于task1,tmp=task1,同样task2也被挂住,task3任务也跟task2一样。最终,3个任务由于同一个资源不可用,而全部挂起。
而一旦wake_up()被调用:
void wake_up (struct task_struct **p)
if (p && *p)
(**p).state = 0;
*p = NULL;
则首先task3的schedule()函数返回,同时task2的任务状态变为可执行,所以task2的schedule()也返回,也导致task1的任务状态变为可执行,所以最后task1也返回。
3.1.2 锁lock_buffer()和unlock_buffer()
有关锁,只需要注意一件事情就好:
cli ();是清中断许可,sti ();开中断。它们针对的是本进程的EFLAGS寄存器,所以说如果调度到其他进程中,其他进程的EFLAGS是使能的,则它可以接受中断,并能进入中断服务函数的。
展开说一点,从A进程调度到B进程,A进程是关闭中断的,B进程是开启中断的,则在调度到B并执行B之前会加载相应的寄存器,所以EFLAGS被更新,从而是可以被中断的。
3.2 任务调度函数schedule()
看网上都说任务调度函数比较难,但是我看了一下,其实懂一些嵌入式,基本上理解起来不难,只是这个函数比较有技巧。
void schedule (void)
int i, next, c;
struct task_struct **p;
for (p = &LAST_TASK; p > &FIRST_TASK; --p)
if (*p)
if ((*p)->alarm && (*p)->alarm < jiffies)
(*p)->signal |= (1 << (SIGALRM - 1));
(*p)->alarm = 0;
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state == TASK_INTERRUPTIBLE)
(*p)->state = TASK_RUNNING;
while (1)
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i)
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
if (c)
break;
for (p = &LAST_TASK; p > &FIRST_TASK; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
switch_to (next);
调度函数分为2个部分,第一个部分是检查是否有相应的信号,另一个部分则是真正的调度算法。
先说第一个部分。如果设置了定时器值并且系统运行超过了定时值,则需要置位信号位图的SIGALRM值,如果任务可中断,并且设置了除_BLOCKABLE和(*p)->blocked的值,则说明任务可以进入执行态。
再说第二个部分。它主要是说任务需要在运行态,才能进行调度。否则就在内核任务0执行。
3.3 复制页表函数copy_page_tables()
这个函数据说也比较复杂。
先看这个函数的参数:
from--->线性地址(逻辑地址)
to--->线性地址(逻辑地址)
size--->页目录数,总共1024个页目录数,但是有效的只有4个。
from和to都需要是4MB对齐。
先来简单回顾一下物理地址是怎么来的。

从from和to的限制要求,可以知道需要拷贝的是按照页目录来拷贝,因为一个页目录项就能指向4096B的页表大小,相当于1024个页表项*4096B=4MB大小。
要注意几项事情:
- 线性地址中的页目录项的值占10位,所以指向页目录项(找到页表的地址)是CR3+线性地址表
的页目录值*4。 - 复制页表需要按照页目录来复制,具体项数则由size来指定。
- 页目录地址值必定是4B对齐。
- size具体含义其实也是页目录个数。
再来看指向页目录地址的值,也就是页表地址的构成:

由于一个页目录能指向4MB对齐的物理地址,所以指向页表的地址中,其实有12位是用不上的,所以用其他的含义位代替了。
p--用于指明表项对地址转换是否有效。p=1,表示有效。p=0,表示无效。
r/w--读写标志。r/w=1,表示页面可被读、写或执行。r/w=0,表示页面只读或可执行。
u/s--用户/超级用户标志。u/s=1,表示运行在任何特权级上的程序都可以访问该页面。u/s=0,
页面只能被运行在超级用户特权级上的程序访问。
在复制页表时,目的页表对地址转换是不能有效的,有效则说明被其他程序或数据占用了。
经过上面的说明,具体到代码中,应该这个函数就很容易明白了。
有一个特殊情况是:
从进程0创建进程1,而进程0属于内核进程,在640KB以下,所以在该函数中有想应的判断语句。
3.4 复制进程信息 copy_process()
该函数是用来复制进程的关键信息,主要是设置结构体task_struct。并且复制页表信息。
该函数中有两个2个很重要的函数,分别为:copy_mem()和copy_page_tables()
3.5 execve()
看这个函数则需要先理解代码与数据的布局:
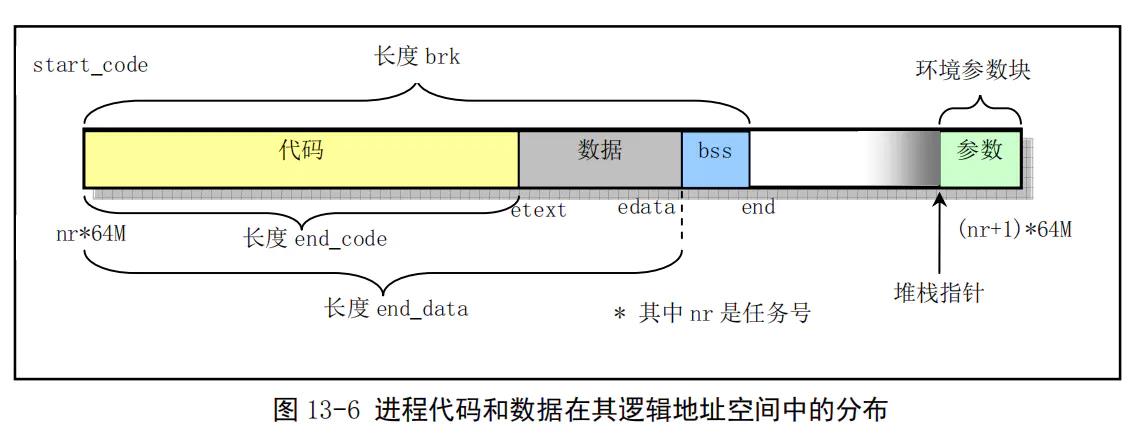
4.基本概念
4.1 进程组,会话
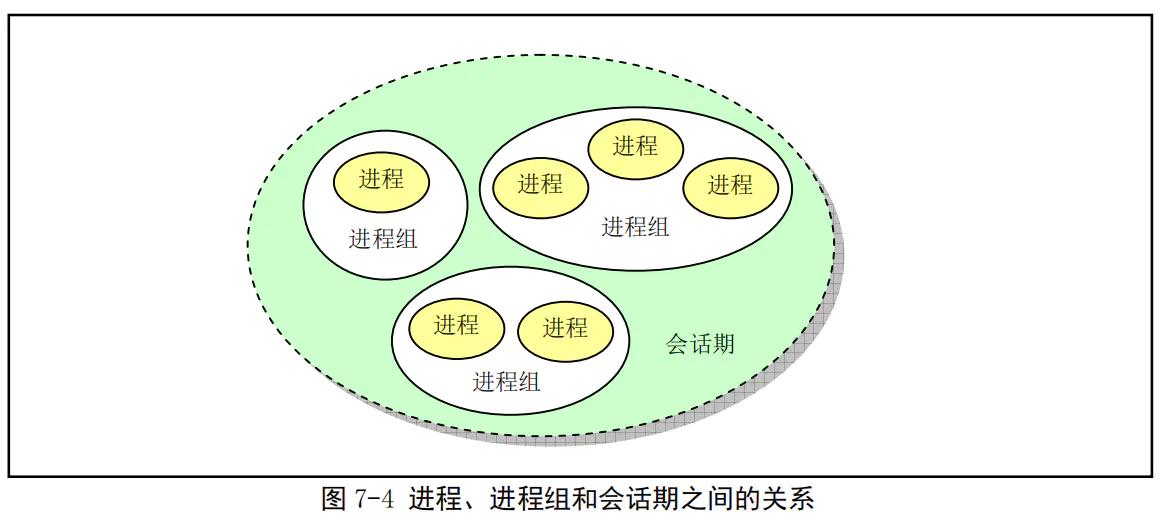
通过这张图,同时说1个例子,则上面的概念就比较好理解了。
$ cat test.txt | grep for
上面这个例子展示的就是一个进程组。
5.实际场景与内核分析
作为内核的编写者,都是以实际应用场景出发并编码。作为分析者,则只能通过读内核之后,反着去分析作者为什么这么写,这样才会更好的理解内核,也不至于看着一堆代码头痛。
所以,下面的内容是从应用场景来分析内核代码。
5.1 打开文件
其实前面已经说过打开文件、找到文件的步骤,现在再通过代码的分析大致讲解一下:
sys_open()
--->open_namei()
--->dir_namei()
--->get_dir()
--->find_entry()
--->iget()
以上是关于linux-0.11 文件系统介绍的主要内容,如果未能解决你的问题,请参考以下文章