72 java.lang.NoClassDefFoundError: org/codehaus/janino/InternalCompilerException
Posted 蓝风9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了72 java.lang.NoClassDefFoundError: org/codehaus/janino/InternalCompilerException相关的知识,希望对你有一定的参考价值。
前言
呵呵 最近因为有一次 包版本的升级, 因此 项目在一些场景下面会出现一个异常
主要的改动是 原来的 janino 的版本是 3.0.9, 然后使用了 spring-boot-starter-parent 里面的 janino 的配置的版本 3.1.2, 呵呵 出现问题之后 把他版本改回去 之后就没问题了
然后当时测试的时候 测试环境 和我这里 都会出现问题, 但是 在我们同事的机器上面却"没有问题", 这个也是 当时让我有些疑惑的地方, 呵呵 这里一起来看看
所以 这里 来看一下这个问题
java.lang.NoClassDefFoundError: org/codehaus/janino/InternalCompilerException异常信息
呵呵 最开始异常信息没有完全打印出来, 只知道存在异常, 然后一步一部的调试 才能看到这的异常是 "java.lang.NoClassDefFoundError: org/codehaus/janino/InternalCompilerException"
但是 后来我招到了一个更加容易看到异常的触发的场景, 呵呵
异常信息如下, 这里可以很轻松的看到 异常是来自于 spark-sql 里面
Caused by: java.lang.NoClassDefFoundError: org/codehaus/janino/InternalCompilerException
at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$.org$apache$spark$sql$catalyst$expressions$codegen$CodeGenerator$$doCompile(CodeGenerator.scala:1371)
at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$$anon$1.load(CodeGenerator.scala:1467)
at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$$anon$1.load(CodeGenerator.scala:1464)
at org.sparkproject.guava.cache.LocalCache$LoadingValueReference.loadFuture(LocalCache.java:3599)
at org.sparkproject.guava.cache.LocalCache$Segment.loadSync(LocalCache.java:2379)
at org.sparkproject.guava.cache.LocalCache$Segment.lockedGetOrLoad(LocalCache.java:2342)
at org.sparkproject.guava.cache.LocalCache$Segment.get(LocalCache.java:2257)
at org.sparkproject.guava.cache.LocalCache.get(LocalCache.java:4000)
at org.sparkproject.guava.cache.LocalCache.getOrLoad(LocalCache.java:4004)
at org.sparkproject.guava.cache.LocalCache$LocalLoadingCache.get(LocalCache.java:4874)
at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$.compile(CodeGenerator.scala:1318)
at org.apache.spark.sql.execution.WholeStageCodegenExec.liftedTree1$1(WholeStageCodegenExec.scala:695)
at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:694)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:175)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:213)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:210)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:171)
at org.apache.spark.sql.execution.DeserializeToObjectExec.doExecute(objects.scala:96)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:175)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:213)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:210)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:171)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:122)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:121)
at org.apache.spark.sql.Dataset.rdd$lzycompute(Dataset.scala:3198)
at org.apache.spark.sql.Dataset.rdd(Dataset.scala:3196)
at org.apache.spark.sql.Dataset.toJavaRDD(Dataset.scala:3208)
at com.hello.world.spark.SparkTemplate.readSqlByDataFrame(SparkTemplate.java:89)
... 39 more
Caused by: java.lang.ClassNotFoundException: org.codehaus.janino.InternalCompilerException
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 159 more
断点异常代码
真正出现异常的地方就是这里, updateAndGetCompilationStats
我们可以搜索一下 InternalCompilerException 可以发现使用 InternalCompilerException 只有在 这里的 catch 里面, 呵呵
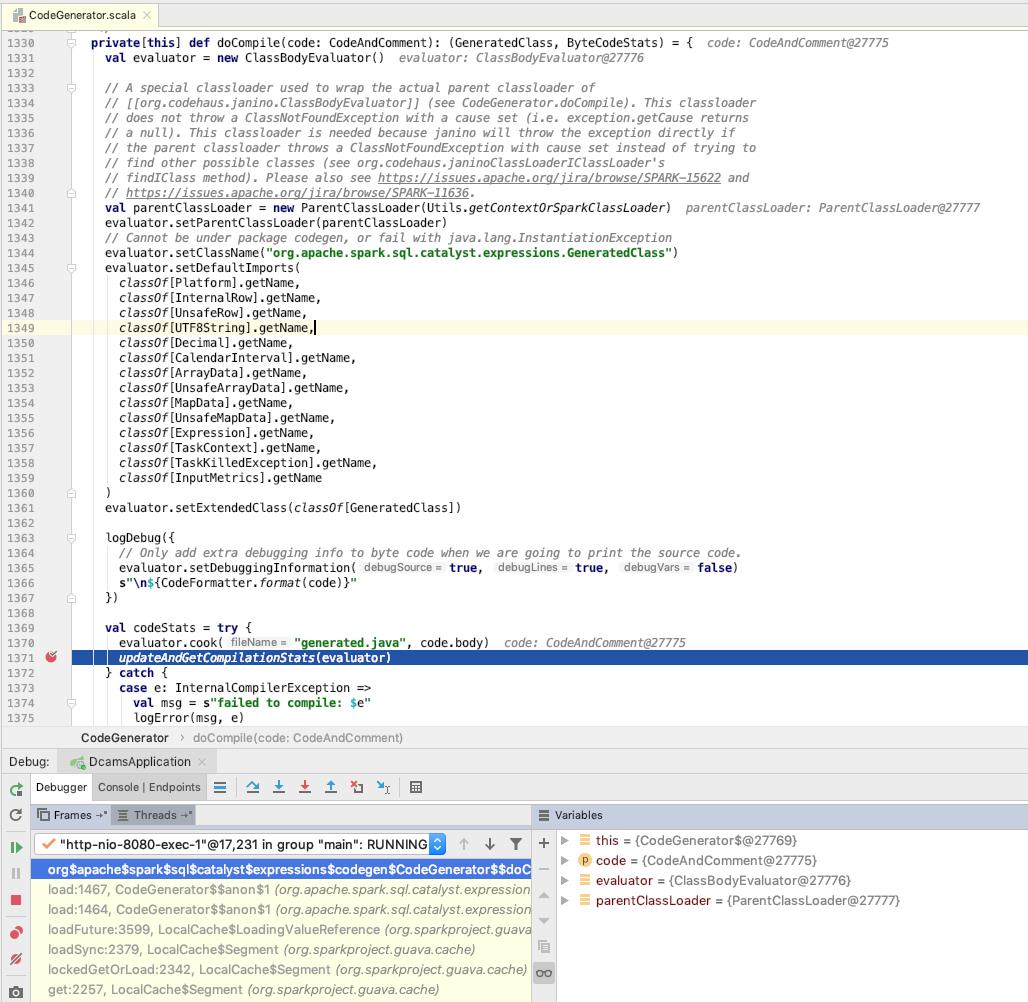
这里使用的 InternalCompilerException 的导入如下, 呵呵, 但是在 3.1.2 里面 发生了较大的包层级的改动
import org.codehaus.janino.ByteArrayClassLoader, ClassBodyEvaluator, InternalCompilerException, SimpleCompiler3.1.2 中 InternalCompilerException 的包层级大致如下, 呵呵 显然和上面的 import 是对不上的, 因此 抛出了 NoClassDefFoundError

所以这个地方, 发生异常的最直观的原因是 spring-boot 里面引入的 janino 的版本是 3.1.2, spark-sql 里面引入的 janino 的版本是 3.0.16
然后 两个版本 存在一个包结构的重构, 导致 不兼容
为什么会使用 InternalCompilerException
如果是 跑的正常的话, 这里应该是 不会进入 catch 里面的, 那么是 updateAndGetCompilationStats 里面发生了异常 导致了加载 InternalCompilerException, 进而导致了 NoClassDefFoundError 呢
从日志里面是 看不出任何东西的, 呵呵, 所以 这个时候 就只能依靠调试了
一个很简单的方法, 既然 updateAndGetCompilationStats 里面抛出了异常, 那么 eval 一下, 就行了, 就能看出 updateAndGetCompilationStats 里面的问题了
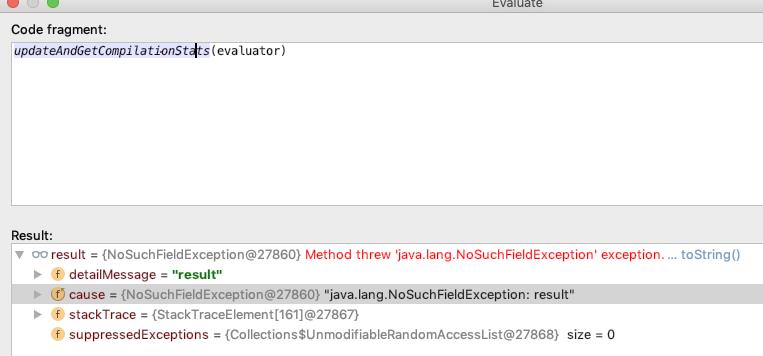
根据上面的额 result 的信息, 我们可以定位到如下代码
val resultField = classOf[SimpleCompiler].getDeclaredField("result")然后看了一下这个 SimpleCompiler, 在 3.1.2 的版本里面确实是 没有 result 这个字段的, 但是在 3.0.9/16 的版本里面是有的
所以 这个问题的最终的结论 还是 janino 的 3.0.x 和 3.1.x 版本的 包呵呵 层级改变太大, 类结构存在差异导致的
其他信息
这里编译的是一个运行时生成的 迭代器的代码, 这里的 21 个字段是来自于业务查询, 查询了 21 个字段, 这里是要将数据从 inputs 里面解析数据, 然后封装 InternalRow, 然后 append 到 BufferedRowIterator. currentRows 里面
generated.class
public Object generate(Object[] references)
return new GeneratedIteratorForCodegenStage1(references);
/*wsc_codegenStageId*/
final class GeneratedIteratorForCodegenStage1 extends org.apache.spark.sql.execution.BufferedRowIterator
private Object[] references;
private scala.collection.Iterator[] inputs;
private scala.collection.Iterator scan_input_0;
private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] scan_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[1];
public GeneratedIteratorForCodegenStage1(Object[] references)
this.references = references;
public void init(int index, scala.collection.Iterator[] inputs)
partitionIndex = index;
this.inputs = inputs;
scan_input_0 = inputs[0];
scan_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(21, 608);
protected void processNext() throws java.io.IOException
while ( scan_input_0.hasNext())
InternalRow scan_row_0 = (InternalRow) scan_input_0.next();
((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(1);
boolean scan_isNull_0 = scan_row_0.isNullAt(0);
UTF8String scan_value_0 = scan_isNull_0 ?
null : (scan_row_0.getUTF8String(0));
boolean scan_isNull_1 = scan_row_0.isNullAt(1);
UTF8String scan_value_1 = scan_isNull_1 ?
null : (scan_row_0.getUTF8String(1));
boolean scan_isNull_2 = scan_row_0.isNullAt(2);
UTF8String scan_value_2 = scan_isNull_2 ?
null : (scan_row_0.getUTF8String(2));
boolean scan_isNull_3 = scan_row_0.isNullAt(3);
UTF8String scan_value_3 = scan_isNull_3 ?
null : (scan_row_0.getUTF8String(3));
boolean scan_isNull_4 = scan_row_0.isNullAt(4);
UTF8String scan_value_4 = scan_isNull_4 ?
null : (scan_row_0.getUTF8String(4));
boolean scan_isNull_5 = scan_row_0.isNullAt(5);
UTF8String scan_value_5 = scan_isNull_5 ?
null : (scan_row_0.getUTF8String(5));
boolean scan_isNull_6 = scan_row_0.isNullAt(6);
UTF8String scan_value_6 = scan_isNull_6 ?
null : (scan_row_0.getUTF8String(6));
boolean scan_isNull_7 = scan_row_0.isNullAt(7);
UTF8String scan_value_7 = scan_isNull_7 ?
null : (scan_row_0.getUTF8String(7));
boolean scan_isNull_8 = scan_row_0.isNullAt(8);
UTF8String scan_value_8 = scan_isNull_8 ?
null : (scan_row_0.getUTF8String(8));
boolean scan_isNull_9 = scan_row_0.isNullAt(9);
UTF8String scan_value_9 = scan_isNull_9 ?
null : (scan_row_0.getUTF8String(9));
boolean scan_isNull_10 = scan_row_0.isNullAt(10);
long scan_value_10 = scan_isNull_10 ?
-1L : (scan_row_0.getLong(10));
boolean scan_isNull_11 = scan_row_0.isNullAt(11);
UTF8String scan_value_11 = scan_isNull_11 ?
null : (scan_row_0.getUTF8String(11));
boolean scan_isNull_12 = scan_row_0.isNullAt(12);
UTF8String scan_value_12 = scan_isNull_12 ?
null : (scan_row_0.getUTF8String(12));
boolean scan_isNull_13 = scan_row_0.isNullAt(13);
UTF8String scan_value_13 = scan_isNull_13 ?
null : (scan_row_0.getUTF8String(13));
boolean scan_isNull_14 = scan_row_0.isNullAt(14);
UTF8String scan_value_14 = scan_isNull_14 ?
null : (scan_row_0.getUTF8String(14));
boolean scan_isNull_15 = scan_row_0.isNullAt(15);
UTF8String scan_value_15 = scan_isNull_15 ?
null : (scan_row_0.getUTF8String(15));
boolean scan_isNull_16 = scan_row_0.isNullAt(16);
UTF8String scan_value_16 = scan_isNull_16 ?
null : (scan_row_0.getUTF8String(16));
boolean scan_isNull_17 = scan_row_0.isNullAt(17);
UTF8String scan_value_17 = scan_isNull_17 ?
null : (scan_row_0.getUTF8String(17));
boolean scan_isNull_18 = scan_row_0.isNullAt(18);
Decimal scan_value_18 = scan_isNull_18 ?
null : (scan_row_0.getDecimal(18, 20, 2));
boolean scan_isNull_19 = scan_row_0.isNullAt(19);
int scan_value_19 = scan_isNull_19 ?
-1 : (scan_row_0.getInt(19));
boolean scan_isNull_20 = scan_row_0.isNullAt(20);
Decimal scan_value_20 = scan_isNull_20 ?
null : (scan_row_0.getDecimal(20, 20, 2));
scan_mutableStateArray_0[0].reset();
scan_mutableStateArray_0[0].zeroOutNullBytes();
if (scan_isNull_0)
scan_mutableStateArray_0[0].setNullAt(0);
else
scan_mutableStateArray_0[0].write(0, scan_value_0);
if (scan_isNull_1)
scan_mutableStateArray_0[0].setNullAt(1);
else
scan_mutableStateArray_0[0].write(1, scan_value_1);
if (scan_isNull_2)
scan_mutableStateArray_0[0].setNullAt(2);
else
scan_mutableStateArray_0[0].write(2, scan_value_2);
if (scan_isNull_3)
scan_mutableStateArray_0[0].setNullAt(3);
else
scan_mutableStateArray_0[0].write(3, scan_value_3);
if (scan_isNull_4)
scan_mutableStateArray_0[0].setNullAt(4);
else
scan_mutableStateArray_0[0].write(4, scan_value_4);
if (scan_isNull_5)
scan_mutableStateArray_0[0].setNullAt(5);
else
scan_mutableStateArray_0[0].write(5, scan_value_5);
if (scan_isNull_6)
scan_mutableStateArray_0[0].setNullAt(6);
else
scan_mutableStateArray_0[0].write(6, scan_value_6);
if (scan_isNull_7)
scan_mutableStateArray_0[0].setNullAt(7);
else
scan_mutableStateArray_0[0].write(7, scan_value_7);
if (scan_isNull_8)
scan_mutableStateArray_0[0].setNullAt(8);
else
scan_mutableStateArray_0[0].write(8, scan_value_8);
if (scan_isNull_9)
scan_mutableStateArray_0[0].setNullAt(9);
else
scan_mutableStateArray_0[0].write(9, scan_value_9);
if (scan_isNull_10)
scan_mutableStateArray_0[0].setNullAt(10);
else
scan_mutableStateArray_0[0].write(10, scan_value_10);
if (scan_isNull_11)
scan_mutableStateArray_0[0].setNullAt(11);
else
scan_mutableStateArray_0[0].write(11, scan_value_11);
if (scan_isNull_12)
scan_mutableStateArray_0[0].setNullAt(12);
else
scan_mutableStateArray_0[0].write(12, scan_value_12);
if (scan_isNull_13)
scan_mutableStateArray_0[0].setNullAt(13);
else
scan_mutableStateArray_0[0].write(13, scan_value_13);
if (scan_isNull_14)
scan_mutableStateArray_0[0].setNullAt(14);
else
scan_mutableStateArray_0[0].write(14, scan_value_14);
if (scan_isNull_15)
scan_mutableStateArray_0[0].setNullAt(15);
else
scan_mutableStateArray_0[0].write(15, scan_value_15);
if (scan_isNull_16)
scan_mutableStateArray_0[0].setNullAt(16);
else
scan_mutableStateArray_0[0].write(16, scan_value_16);
if (scan_isNull_17)
scan_mutableStateArray_0[0].setNullAt(17);
else
scan_mutableStateArray_0[0].write(17, scan_value_17);
if (scan_isNull_18)
scan_mutableStateArray_0[0].write(18, (Decimal) null, 20, 2);
else
scan_mutableStateArray_0[0].write(18, scan_value_18, 20, 2);
if (scan_isNull_19)
scan_mutableStateArray_0[0].setNullAt(19);
else
scan_mutableStateArray_0[0].write(19, scan_value_19);
if (scan_isNull_20)
scan_mutableStateArray_0[0].write(20, (Decimal) null, 20, 2);
else
scan_mutableStateArray_0[0].write(20, scan_value_20, 20, 2);
append((scan_mutableStateArray_0[0].getRow()));
if (shouldStop()) return;
关于这个异常 我当时还有一个想法是在 字节码层面上看一下 反射获取 result 之后是那一条字节码触发了 NoClassDefFoundError, 现在想想 这个应该是在 vm 里面处理的吧
所以当时使用 jdb 启动了一下项目, 然后 打上了相关断点来看一下, 呵呵 我擦 妈的这里抛出 NoClassDefFoundError 又是在 CodegenContext.addMutableState 里面了, 而且都是稳定出现在这里的
呵呵 不知道 jdb 启动 和 idea 里面启动有什么区别
http-nio-8080-exec-1[1] where
[1] java.lang.NoClassDefFoundError.<init> (NoClassDefFoundError.java:59)
[2] org.apache.spark.sql.catalyst.expressions.codegen.CodegenContext.addMutableState (CodeGenerator.scala:275)
[3] org.apache.spark.sql.execution.InputRDDCodegen.doProduce (WholeStageCodegenExec.scala:458)
[4] org.apache.spark.sql.execution.InputRDDCodegen.doProduce$ (WholeStageCodegenExec.scala:456)
[5] org.apache.spark.sql.execution.RowDataSourceScanExec.doProduce (DataSourceScanExec.scala:99)
[6] org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1 (WholeStageCodegenExec.scala:95)
[7] org.apache.spark.sql.execution.CodegenSupport$$Lambda$2594.2036268758.apply (null)
[8] org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1 (SparkPlan.scala:213)
[9] org.apache.spark.sql.execution.SparkPlan$$Lambda$2511.393376500.apply (null)
[10] org.apache.spark.rdd.RDDOperationScope$.withScope (RDDOperationScope.scala:151)
[11] org.apache.spark.sql.execution.SparkPlan.executeQuery (SparkPlan.scala:210)
[12] org.apache.spark.sql.execution.CodegenSupport.produce (WholeStageCodegenExec.scala:90)
[13] org.apache.spark.sql.execution.CodegenSupport.produce$ (WholeStageCodegenExec.scala:90)
[14] org.apache.spark.sql.execution.RowDataSourceScanExec.produce (DataSourceScanExec.scala:99)
[15] org.apache.spark.sql.execution.WholeStageCodegenExec.doCodeGen (WholeStageCodegenExec.scala:632)
[16] org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute (WholeStageCodegenExec.scala:692)
另外一点就是为什么 我们同事的电脑上没有"问题" ?
呵呵呵 主要是因为没打日志, 其实 也是有这个问题的 !
完
以上是关于72 java.lang.NoClassDefFoundError: org/codehaus/janino/InternalCompilerException的主要内容,如果未能解决你的问题,请参考以下文章