数据分析走进数据分析 4 正则表达式
Posted 我是小白呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析走进数据分析 4 正则表达式相关的知识,希望对你有一定的参考价值。
概述
数据分析 (Data Analyze) 可以在工作中的各个方面帮助我们. 本专栏为量化交易专栏下的子专栏, 主要讲解一些数据分析的基础知识.

正则表达式
正则表达式 (Regular Expression) 是一种用来匹配字符串的强有力的工具. 可以帮助我们提取我们想要的信息.
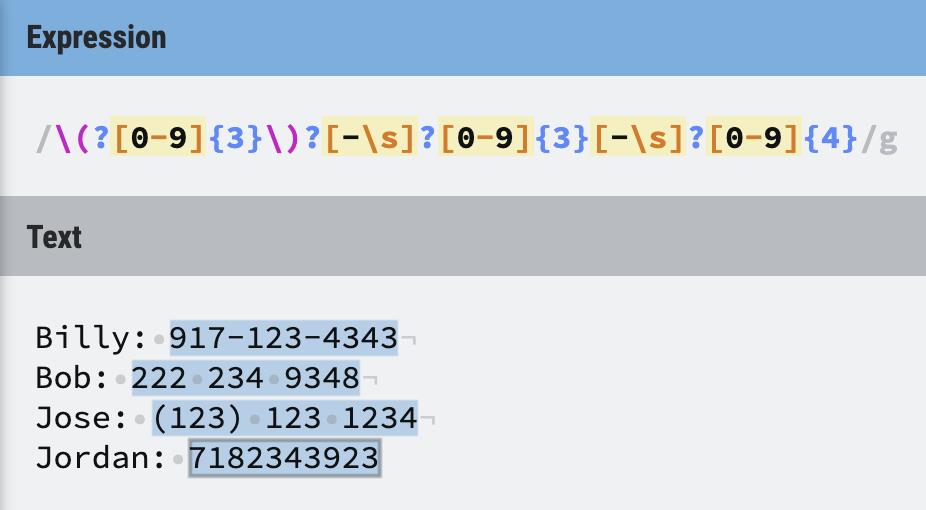
字符
| 字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置 |
| ( ) | 标记一个子表达的开始和结束位置 |
| * | 匹配前面的子表达 0 次或多次 |
| + | 匹配前面的子表达式 1 次或多次 |
| . | 匹配除换行符\\n之外的任何单字符 |
| ? | 匹配前面的子表达式 0 次或 1 次 |
| ^ | 匹配输入字符串的开始位置 |
| | | 指明两项之间的一个选择 |
限定符
| 字符 | 描述 |
|---|---|
| n | n 是一个非负整数, 匹配确定的 n 次 |
| n, | n 是一个非负整数, 至少匹配 n 次 |
| n,m | n 和 m 均是非负整数 |
实战
re是 Python 中使用正则表达式的一个库.
导入:
import re

电话号码匹配
例子:
import re
# 内容(电话)
content = "02187888822 05114405222 02584533622 xxxxxa"
# 正则表达式
pattern = r"[0-9]11,"
# 匹配
match = re.findall(pattern, content)
print(match)
输出结果:
['02187888822', '05114405222', '02584533622']
匹配股票代码

匹配沪深:
import re
# 内容(股票代码)
content = "601101.XSHE 600661.XSHE 600071.XSHE 601666.XSHE"
# 正则表达式
pattern = r"[0-9]6.XSHE"
# 匹配
match = re.findall(pattern, content)
print(match)
输出结果:
['601101.XSHE', '600661.XSHE', '600071.XSHE', '601666.XSHE']
匹配上证:
import re
# 内容(股票代码)
content = "601888.XSHG 601628.XSHG 600276.XSHG 600519.XSHG"
# 正则表达式
pattern = r"[0-9]6.XSHG"
# 匹配
match = re.findall(pattern, content)
print(match)
输出结果:
['601888.XSHG', '601628.XSHG', '600276.XSHG', '600519.XSHG']
以上是关于数据分析走进数据分析 4 正则表达式的主要内容,如果未能解决你的问题,请参考以下文章