爬虫开源工具GoPUP的介绍与使用
Posted 肉丸不肉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫开源工具GoPUP的介绍与使用相关的知识,希望对你有一定的参考价值。
- 老师今天中午找我做一个任务: 爬虫+将爬到的数据可视化。
- 老师指定我用 GoPUP 来获取数据,用 ECharts 来可视化成图表。
一、 介绍
-
GoPUP是GitHub中的一个开源工具,GoPUP项目所采集的数据皆来自公开的数据源,不涉及任何个人隐私数据和非公开数据。同时开发者指出本项目提供的数据接口及相关数据仅用于学术研究。
-
项目地址为:https://github.com/justinzm/gopup。
-
此项目的核心思想:将各种数据接口做整合
二、使用方法(建议先浏览一遍文档)
使用方法很简单:先pip安装,再去文档中查找待爬取的数据仓库(接口API、相关属性等),最后获取数据。
我使用的数据仓库为:百度搜索指数。所以详细介绍这个仓库的使用,其他仓库使用也很简单,直接看文档中的接口API即可。
具体需求为:爬取百度指数中 近十年 “铝” 这个关键词的搜索指数。
- 安装gopup:pip install gopup
- 在Anaconda Spyder 中输入爬虫代码:
import gopup as gp
cookie = 'BIDUPSID=31645A2D6B3E345D912F2D409B9F4473; PSTM=1617162454; BAIDUID=DD10994257CC1714887A6C499DC79B61:FG=1; BDUSS=RtdTVPSEhIeEFpcEVYRW1WZGQxMTFvMElYWEplQ0JuZnlRdUkzNWQwNlNzcEpnRVFBQUFBJCQAAAAAAAAAAAEAAAC0jBTozvvGqLXEv7zR0MK3AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJIla2CSJWtgd2; BDUSS_BFESS=RtdTVPSEhIeEFpcEVYRW1WZGQxMTFvMElYWEplQ0JuZnlRdUkzNWQwNlNzcEpnRVFBQUFBJCQAAAAAAAAAAAEAAAC0jBTozvvGqLXEv7zR0MK3AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJIla2CSJWtgd2; __yjs_duid=1_9e86b656b728c483c287648975d6b5221620119153430; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=33986_33813_31254_33848_33607_26350_22159; bdindexid=e30hju1f6dnf4ucu9as6b93hr6; Hm_lvt_d101ea4d2a5c67dab98251f0b5de24dc=1620711200,1620711701; BAIDUID_BFESS=8888642A7676253E5BD332123959953C:FG=1; Hm_lpvt_d101ea4d2a5c67dab98251f0b5de24dc=1620712626; ab_sr=1.0.0_NGJlYzUzYzRlYjc1NjlkYjhmNTE3ZDBkMWY0ZjYxNWI5YmZkOTY5MTM1OGNiMDU2YWNiNmIxODM3YzI5NjliNDA1ODk0NTYzOWQyZGY4NjY3MjU2YjcxMTQ4MWRjZDhj; __yjs_st=2_OGM2YWI3Y2IzMmZlZTg1YjY5MDA4M2UwYzlhYzlhNzRkYmJlMGMwZmE4ZmM3ZmY3MGI5Nzc4YzIxN2QwNWVjYTRhNWIxNjMxMTM5MzljMWI0OWNjYjMzYWM1N2UxYWFlYjk3ZmExMTllMzQ1ZmU3MGZiNjg1OWZkMDdhYWM5ZTA2ZTZhOGExNDNkYTBhOWQ2YzY4ZGMyNWNmYjIzZTg4MDFmYzZiNzFkODVhNDZkZGNjNjQ2MzUwMzJhZWY5MDgzYWU2ZjIyNmQ1ZmY1NThmMTRmYzgyNTZmMjBkNDFkOTg5MjQ3YzQ5Yjk1NzdkMWJjNWQxYjkxMDgxNjNiY2MxNV83XzA0NjhlNjNk; RT="sl=4&ss=kojm9zge&tt=3ln&bcn=https://fclog.baidu.com/log/weirwood?type=perf&z=1&dm=baidu.com&si=7facxkq2f6w&ld=6b9o&ul=6g0q"'
index_df = gp.baidu_search_index(word="铝", start_date='2020-05-10', end_date='2021-05-10', cookie=cookie)
print(index_df)
其中cookie的值为:在网页端登录百度指数后的 cookie 数据。具体获取方式如下:
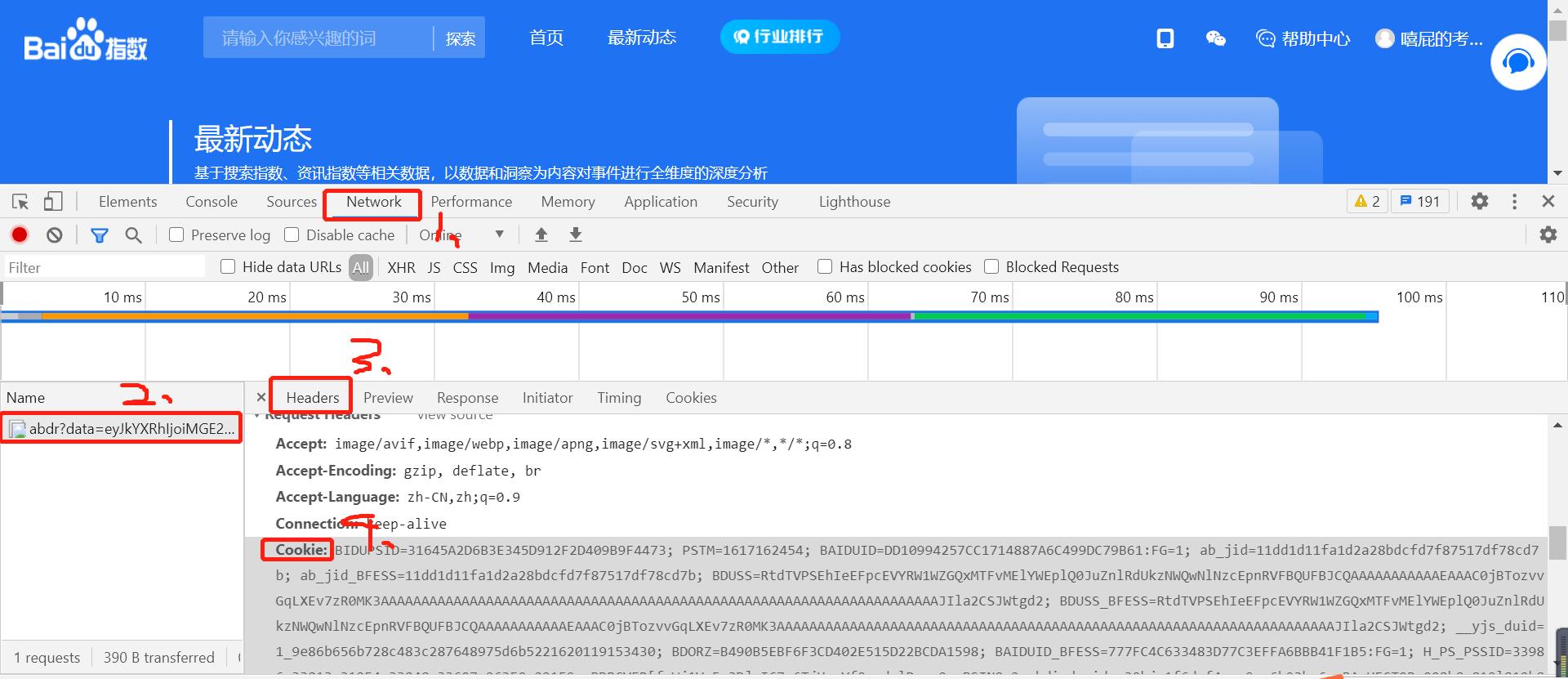
三、使用时遇到的问题与解决方法
1. 直接复制文档里面的代码后,再将登录百度指数网站后得到的cookie复制过去时,报 语法错误。
问题分析与解决:
先看一下文档里给出百度搜索指数的代码:
import gopup as gp
cookie = "此处输入您在网页端登录百度指数后的 cookie 数据"
index_df = gp.baidu_search_index(word="口罩", start_date='2020-01-01', end_date='2020-03-01', cookie=cookie)
print(index_df)
直接复制这个就会报错。因为从百度指数网站获得的cokkie里面包含双引号,所以此处应该是单引号。
正确的应该为:
import gopup as gp
cookie = '此处输入您在网页端登录百度指数后的 cookie 数据'
index_df = gp.baidu_search_index(word="口罩", start_date='2020-01-01', end_date='2020-03-01', cookie=cookie)
print(index_df)
2. 爬出的数据在spyder中显示不全。要将省略号的内容都显示出来。
如下图的问题:

问题分析与解决:
gopup爬到返回的数据类型为dataframe类型,对于这种类型的数据 循环遍历 输出要用 迭代器。
详情请看这篇博客:https://blog.csdn.net/fisherming/article/details/105419315
总结就是用 iterrows迭代器:
# 每一行返回一个2元素的元组
# 元组的第一个元素是该行的索引值
# 第二个元素是一个Series对象,该Series对象的值为剩余的行值
index_df = gp.baidu_search_index(word="铝", start_date='2020-05-10', end_date='2021-05-10', cookie=cookie)
for item in index_df.iterrows():
print(item[0])
# 能获得 dataframe的第一列,在这里就是 时间。
for item in index_df.iterrows():
print(item[1][0])
# 能获得 dataframe的第二列,在这里就是 搜索值。

四、优缺点:
- 优点:三行代码即可获得爬到的数据。
- 缺点:
- 不能单独指定爬取的粒度,比如我想要爬取百度指数中每一年的搜索值,而并非每天的(但是百度指数就是每天的)。所以只能原网站数据提供啥,我们爬到啥。
以上是关于爬虫开源工具GoPUP的介绍与使用的主要内容,如果未能解决你的问题,请参考以下文章