爬虫
Posted 肉丸不肉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫相关的知识,希望对你有一定的参考价值。
零、背景知识
- 爬虫,就是一个自动化的程序。
- 爬虫的具体流程:网站托管在服务器上,服务器是24小时运行的。爬虫,首先会模拟请求(好像在浏览器输入网址,然后回车),爬虫可以用一些 Http 库向指定的服务器偷偷摸摸的发起请求,这个时候爬虫可以假装自己是浏览器(添加一些header信息),大多数服务器(但很多服务器建立了反爬虫机制)误以为爬虫就是浏览器,就把数据返回给爬虫了。不同的情况下,服务器返回给我们的数据格式不一样,有HTML、JSON、二进制的数据等,根据不同的情况,我们可以使用不同的方式对他们进行处理。处理完之后就可以保存。
- 学习的模块:
- 抓包
- 数据爬取
- 数据解析
- 数据存储
- 数据分析:可视化
- 爬虫框架:scrapy、
一、在chrome浏览器中进行抓包
- 打开一个网址后,(fn+f12)进入开发者模式。
- 点击“Network” 查看网络请求。
- HTTP 的请求方式:GET, POST, PUT, DELETE, HEAD, OPTIONS, TRACE。最常见的就是 GET 和 POST 请求。
- GET请求:

https://www.baidu.com/s?wd=%E9%83%AD%E8%89%BE%E4%BC%A6&rsv_spt=1&rsv_iqid=0xab72dcc20003b006&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=10&rsv_sug2=0&rsv_btype=i&inputT=2679&rsv_sug4=4107
- GET 请求的参数是以 键值对 的形式出现的。
- “?wd=%E9%83%AD%E8%89%BE%E4%BC%A6” 问号后面的是请求参数。(果真是键值对)
- 所以以后我们在 Python 写 GET 请求的时候,直接在 URL 后面加个 ?然后添加参数值就好了
- POST请求:做一些信息提交的时候,比如登录、注册等
- POST 的参数不会直接放在 URL 上,会以 Form 表单的形式将数据提交给服务器
- POST请求的参数放在request body 里面,POST请求方式还对密码参数加了密
- 请求头Request Header:在做 HTTP 请求的时候,除了提交一些参数之外,我们还要定义一些 HTTP 请求的头部信息。比如 Accept、Host、cookie、User-Agent等等,这些参数通过这些信息,欺骗服务器,告诉它我们是正规请求。比如可以在代码里面设置 cookie 告诉服务器我们就是在这个浏览器请求的会话,User-Agent 告诉服务器我们是浏览器请求的。
- 服务器的响应码:200、404、304…
- 响应头Response Header:是服务器返回,告诉我们数据以什么样的形式展现,告诉我们cookie的设置。
- 响应体:是服务器返回给我们的数据。点击 Response 就可以看到相关的数据了。获取到的数据是不一样的, 有html的,也有 JSON 的图片二进制数据等等。
二、通过 Fiddler 进行手机抓包
- 若想对请求的数据或者响应的数据进行篡改 或者 对手机请求的数据进行抓包:用Fiddler。
- Fiddler 的具体工作原理:一般情况下,通过浏览器来请求服务器的时候,是点对点的。

- 有了Fiddler 之后,Chrome发送请求给服务器的时候,会被 Fiddler 拦截下来,可以在这里修改请求参数。
- 然后 Fiddler 假装自己是浏览器,再发送数据给服务器。
- 此时服务器接收到 Fiddler 的请求,以为是 Chrome 发送的,于是就返回数据了。
- 返回的数据又被 Fiddler 拦截下来了,Fiddler 可以在这个时候,对数据进行修改,然后返回给Chrome。

- 有需要时再去下载使用,看细节即可。
三、Urllib 库
Python 这个内置的 Urllib 库,有4 个模块:request(用它来发起请求)、error(当我们在使用 request 模块遇到错了,可以用它来进行异常处理)、parse(用来解析我们的 URL 地址的,比如解析域名地址啦,URL指定的目录等)、robotparser(解析网站的 robot.txt)。
练习1:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))
返回百度网址的源代码:

request 的 urlopen 方法详情:urllib.request.urlopen(url, data=None, [timeout, ]*)
- 第一个 url 就是我们请求的链接
- 第二个参数 data,是专门给我们 post 请求携带参数的。比如我们在登录的时候,可以把用户名密码封装成 data 传过去,在这里的 data 的值我们可以用 byte 的类型传递。
- 第三个参数 timeout 就是设置请求超时时间
练习2:添加请求头信息(request header),要欺骗服务器说我们是浏览器或者手机请求
request 模块中的 Request 方法:urllib.request.Request(url, data=None, headers=, method=None)
- 除了定义 url 和 data 之外,还可以定义请求头信息。
- urlopen 默认是 Get 请求,当我们传入参数它就为 Post 请求了。
练习三:模拟在某个网站的登录
from urllib import request, parse
import ssl # 使用 ssl 未经验证的上下文,因为待请求的这个网站用的是https
context = ssl._create_unverified_context()
url = 'https://biihu.cc//account/ajax/login_process/'
# 定义请求头
headers =
# 假装自己的浏览器
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
# 请求的参数
dict =
'return_url': 'https://biihu.cc/',
'user_name': 'xxxx',
'password': '11111',
'post_type': 'ajax',
# 把请求的参数转化为byte
data = bytes(parse.urlencode(dict), 'utf-8')
# 封装request
req = request.Request(url, data=data, headers=headers, method='POST')
# 请求
response = request.urlopen(req, context=context)
print(response.read().decode('utf-8'))
四、Reuqests库
Requests 是在 urllib 的基础上搞出来的,通过它我们可以用更少的代码,模拟浏览器操作。
但Requests库不是python的内置库,用之前需要先安装。使用pip命令安装即可。

# 导入 requests 模块
import requests
url = 'https://api.github.com/events'
# get请求
r = requests.get(url)
# post请求
r = requests.post('https://httpbin.org/post', data = 'key':'value')
# 携带请求参数
payload = 'key1': 'value1', 'key2': 'value2'
r = requests.get('https://httpbin.org/get', params=payload)
# 假装自己是浏览器
url = 'https://api.github.com/some/endpoint'
headers = 'user-agent': 'my-app/0.0.1'
r = requests.get(url, headers=headers)
# 其它乱七八糟的 Http 请求
r = requests.put('https://httpbin.org/put', data = 'key':'value')
r = requests.delete('https://httpbin.org/delete')
r = requests.head('https://httpbin.org/get')
r = requests.options('https://httpbin.org/get')
# 导入 requests 模块
import requests
url = 'https://api.github.com/events'
r = requests.get(url)
# 获取服务器响应文本内容
r.text
'''
u'["repository":"open_issues":0,"url":"https://github.com/...
'''
r.encoding
'''
'utf-8'
'''
# 获取字节响应内容
r.content
'''
b'["repository":"open_issues":0,"url":"https://github.com/...
'''
# 获取响应码
r.status_code
'''
200
'''
# 获取响应头
r.headers
'''
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
'''
# 获取 Json 响应内容
r.json()
'''
[u'repository': u'open_issues': 0, u'url': 'https://github.com/...
'''
# 获取 socket 流响应内容
r.raw
'''
<urllib3.response.HTTPResponse object at 0x101194810>
'''
r.raw.read(10)
'''
'\\x1f\\x8b\\x08\\x00\\x00\\x00\\x00\\x00\\x00\\x03'
'''
Post请求:当想要一个键里面添加多个值的时候

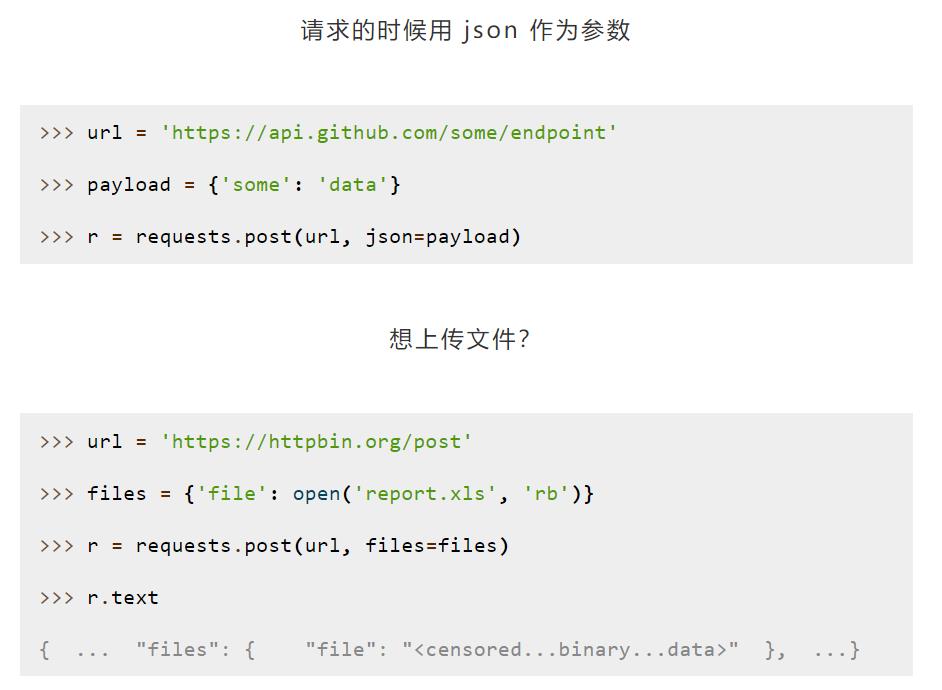


五、正则表达式
通过正则表达式:过滤出我们想要的内容。(在服务器返回给我们的源码之中,仅拿到我们想要的数据即可。)
正则表达式不仅仅适用于 python,很多编程语言,很多地方都会使用到正则。
比如:如何从下面这段字符串中快速检索所有的数字出来呢?
zui12shu234ai45der6en7sh88ixia7898os0huaib
综上,正则表达式就是定义一些特殊的符号,来匹配不同的字符。
1. 各种符号的解释
贼多。记不住。
2. 最常用的匹配


3. 用 python 来进行判断:用python 的re库
使用这个方法:re.match。主要传入两个参数,第一个就是我们的匹配规则,第二个就是需要被过滤的内容。
import re
content = 'Xiaoshuaib has 100 bananas'
# 将我们需要的目标内容用 () 括起来
res = re.match('^Xi.*(\\d+)\\s.*s$', content)
print(res.group(1))
'''
输出0
'''
res = re.match('^Xi.*?(\\d+)\\s.*s$', content)
print(res.group(1))
'''
输出100
'''
- 贪婪匹配 vs. 非贪婪匹配:贪婪匹配是一个数一个数都要去匹配,而非贪婪直接把 100 给匹配出来了。
.*?:匹配任意字符。.代表所有的单个字符,除了 \\n \\r。
表达式 .* 就是单个字符匹配任意次,即贪婪匹配。
表达式 .*? 是满足条件的情况只匹配一次,即最小匹配(非贪婪模式)
当待匹配的字符串有换行时,需要用到re的匹配规则:re.S。
content = '''Xiaoshuaib has 100
bananas'''
res = re.match('^Xi.*?(\\d+)\\s.*s$', content, re.S)
print(res.group(1))
'''
输出100
'''
匹配规则中,不写字符串开头和结尾:re.search:直接去扫描字符串,然后把匹配成功的第一个结果的返回给你。
content = '''Xiaoshuaib has 100
bananas'''
res = re.search('Xi.*?(\\d+)\\s.*s', content, re.S)
print(res.group(1))
'''
输出100
'''
当想获取所有的100数字,用re.findall:获取所有匹配的内容
content = """Xiaoshuaib has 100 bananas;
Xiaoshuaib has 100 bananas;
Xiaoshuaib has 100 bananas;
Xiaoshuaib has 100 bananas;
"""
# 注意此时匹配规则改了
res = re.findall('Xi.*?(\\d+)\\s.*?s', content, re.S)
print(res)
'''
输出['100', '100', '100', '100']
'''
想直接替换匹配的内容,用re.sub:
content = """Xiaoshuaib has 100 bananas;
Xiaoshuaib has 100 bananas;
Xiaoshuaib has 100 bananas;
Xiaoshuaib has 100 bananas;
"""
# 匹配规则变化了
res = re.sub('\\d+', '250', content)
print(res)
'''
输出:
Xiaoshuaib has 250 bananas;
Xiaoshuaib has 250 bananas;
Xiaoshuaib has 250 bananas;
Xiaoshuaib has 250 bananas;
'''
res = re.sub('Xi.*?(\\d+)\\s.*?s', '250', content)
print(res)
'''
输出:
250;
250;
250;
250;
'''
把我们的匹配符封装一下,用re.compile:便于以后复用
content = "Xiaoshuaib has 100 bananas"
pattern = re.compile('Xi.*?(\\d+)\\s.*s', re.S)
res = re.match(pattern, content)
print(res.group(1))
'''
输出:100
'''
六、使用 requests 库和 re 库来写一个爬虫:爬取当当网的前 500 本好五星评书籍
1. 首先要对待爬取的目标网站进行分析。
每页有25条数据,每页的url最后的变量不同。如下图所示:
第一页:

第二页:
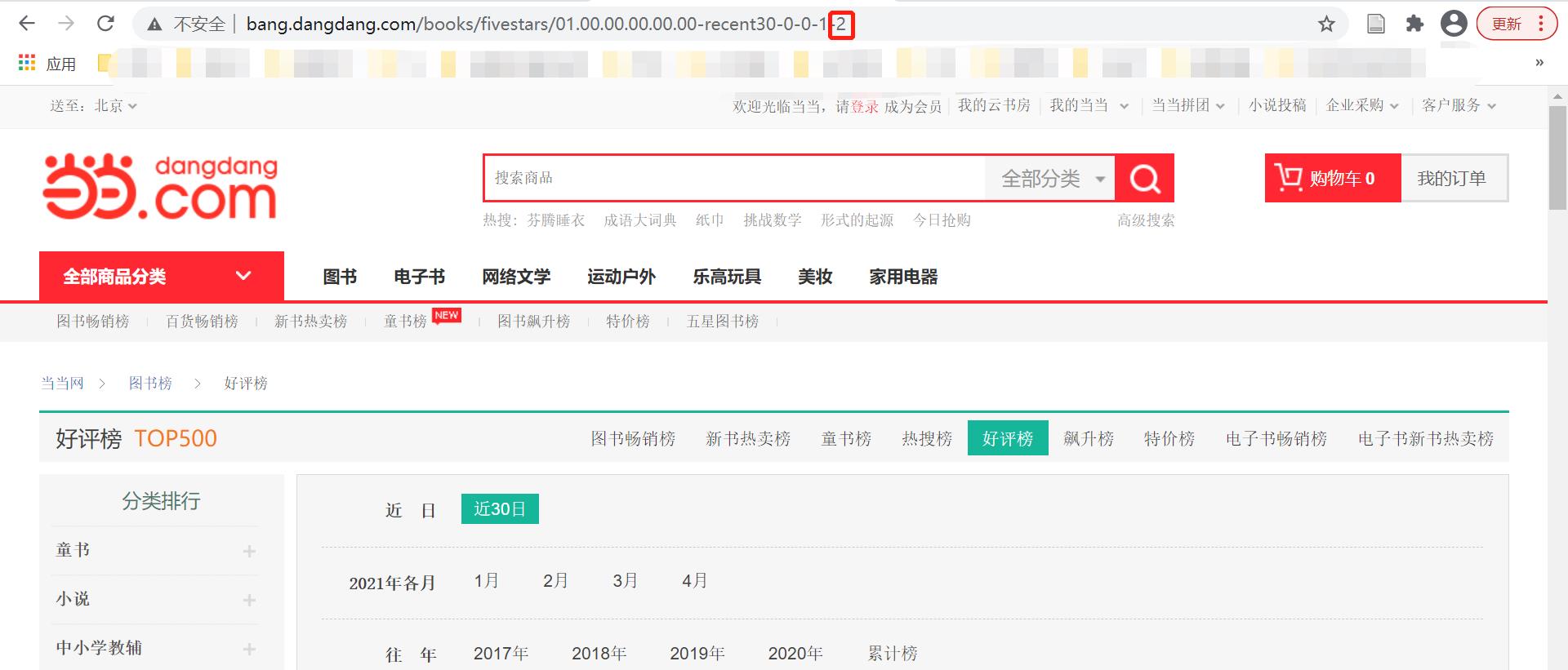
2. 分析要拿到每个项目的哪些关键数据,看在什么标签内(用正则表达式来过滤)


通过服务器返回的源码可以发现,待提取的数据信息被放在了li标签中。
3. 保存在数据库/文件中
主要思路:
- 使用 page 变量来实现翻页
- 我们使用 requests 请求当当网
- 然后将返回的 HTML 进行正则解析
- 保存在数据库/文件中
import json
import re
import requests
def request_dangdang(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
def parser_result(html):
pattern = re.compile('<li>.*?list_num.*?(\\d+).</div>.*?<img src="(.*?)".*?class="name".*?title="(.*?)">.*?class="star">.*?class="tuijian">(.*?)</span>.*?class="publisher_info">.*?target="_blank">(.*?)</a>.*?class="biaosheng">.*?<span>(.*?)</span></div>.*?<p><span\\sclass="price_n">¥(.*?)</span>.*?</li>', re.S)
items = re.findall(pattern, html)
for item in items:
yield
'range': item[0],
'image': item[1],
'title': item[2],
'recommend': item[3],
'author': item[4],
'times': item[5],
'price': item[6]
def write_item_to_file(item):
print('开始写数据 ===> ' + str(item))
with open('book.txt', 'a', encoding='UTF-8') as f:
f.write(json.dumps(item, ensure_ascii=False) + '\\n')
f.close()
def main(page):
url = 'http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-' + str(page)
html = request_dangdang(url)
# 解析过滤我们想要得到的关键信息
items = parser_result(html)
for item in items:
# 把爬到的本书的关键数据都依次存到文件中
write_item_to_file(item)
if __name__ == "__main__":
for i in range(1, 26):
main(i)
七、一个高效的网页解析库:BeautifulSoup(可代替正则表达式来快速的获取我们想要的内容)
1. 安装BeautifulSoup库

2. 安装解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml。


3. 开始使用
一段HTML代码:
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象。
能按照标准的缩进格式的结构输出:
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
print(soup.prettify())
输出:

几个简单的浏览结构化数据的方法:
soup.title
# <title>The Dormouse's story</title>
soup.title.name
# u'title'
soup.title.string
# u'The Dormouse's story'
soup.title.parent.name
# u'head'
soup.p
# <p class="title"><b>The Dormouse's story</b></p>
soup.p['class']
# u'title'
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find(id="link3")
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
从文档中找到所有a标签的链接:
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
从文档中获取所有文字内容:
print(soup.get_text())
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
八、使用 requests库和beayutifulsoup库 来爬取豆瓣最受欢迎的250部电影
1. 首先看不同页数之间的page变量规律
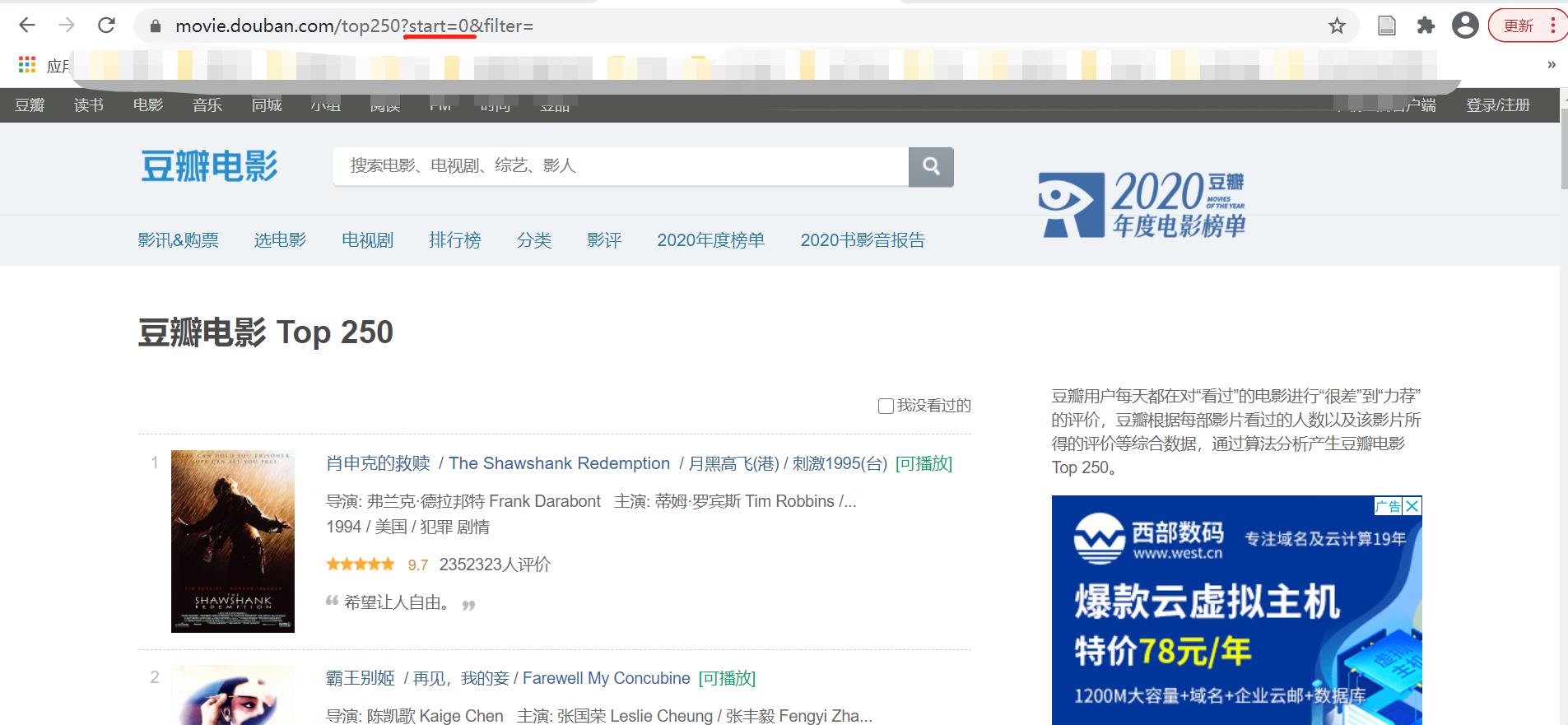
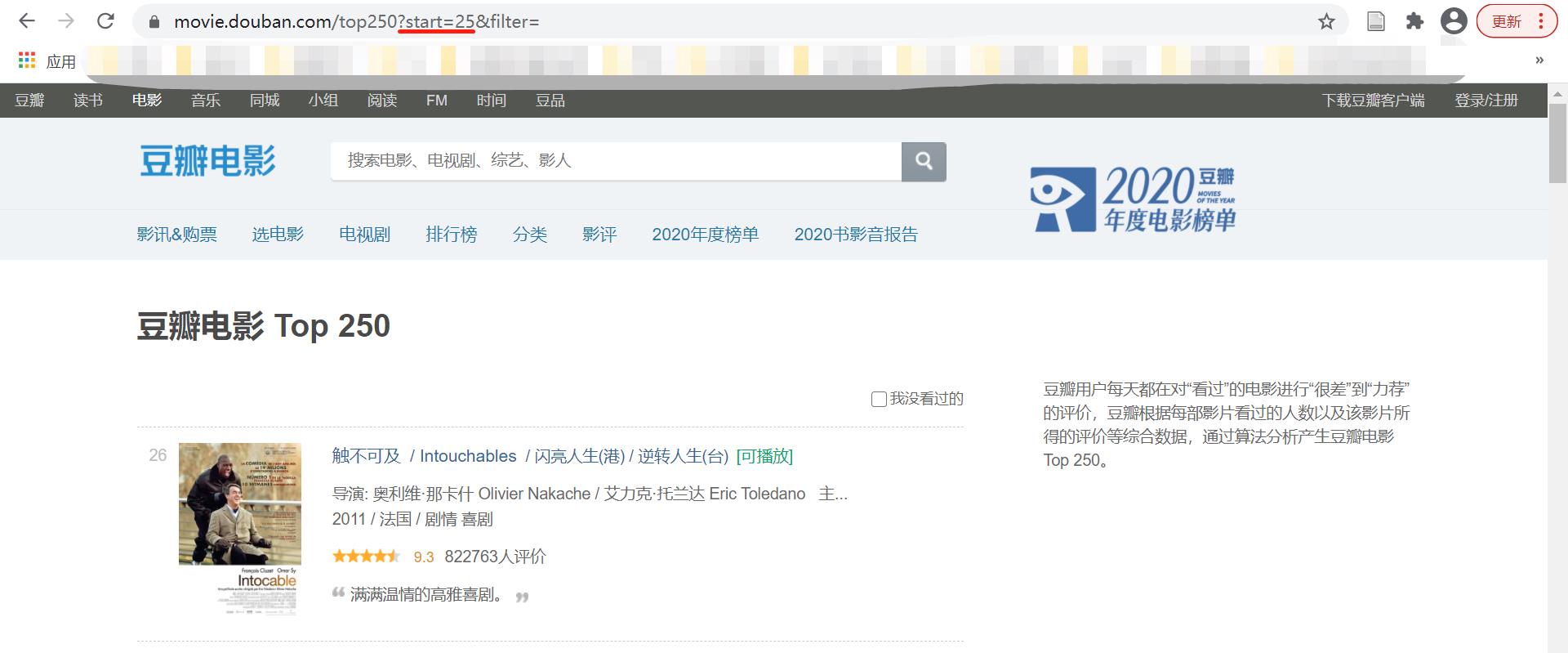

2. 分析想要获取的每个item的关键数据以及源代码标签定位:



3. 主要思路:
- 请求豆瓣的链接获取网页源代码
- 然后使用 BeatifulSoup 拿到我们要的内容
- 最后就把数据存储到 excel 文件中
from bs4 import BeautifulSoup
import requests
# excel的库
import xlwt
def request_douban(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
book = xlwt.Workbook(encoding='UTF-8', style_compression=0)
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True)
sheet.write(0, 0, '名称')
sheet.write(0, 1, '图片')
sheet.write(0, 2, '排名')
sheet.write(0, 3, '评分')
sheet.write(0, 4, '作者')
sheet.write(0, 5, '简介')
def save_to_excel(soup):
items 以上是关于爬虫的主要内容,如果未能解决你的问题,请参考以下文章