文字识别(输入为自然场景中的图像)
Posted 肉丸不肉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文字识别(输入为自然场景中的图像)相关的知识,希望对你有一定的参考价值。
- 大老板给我定的方向是文字识别。所以在回所之前先把基础知识看一下,相当于综述~
- 我的方向与目前的文字识别区别在于,目前的文字识别输入主要是自然场景中的图像,从图像进行文字检测再继而文字识别;而我要做的输入是通过手写笔在特殊笔记本上书写后采集到的坐标点。但是还是先从目前的文字识别入手吧~
- 在这个过程中目的有两个。首先是了解文字识别的步骤与经典算法,其次是学会使用深度学习框架。
参考文献:
- OCR文字识别用的是什么算法?
- 文字识别方法整理
- 一文读懂CRNN+CTC文字识别
- 场景文字检测—CTPN原理与实现
- 完全解析RNN, Seq2Seq, Attention注意力机制
- 【AI实战】手把手教你文字识别(识别篇:LSTM+CTC, CRNN, chineseocr方法)
一、了解OCR
1. 单独文字识别:把OCR过程类比到模式识别过程
OCR是模式识别的一个领域,所以整体过程也就是模式识别的过程。
- 预处理:对包含文字的图像进行处理以便后续进行特征提取、学习。这个过程的主要目的是减少图像中的无用信息,以便方便后面的处理。在这个步骤通常有:灰度化(如果是彩色图像)、降噪、二值化、字符切分以及归一化这些子步骤。经过二值化后,图像只剩下两种颜色,即黑和白,其中一个是图像背景,另一个颜色就是要识别的文字了。降噪在这个阶段非常重要,降噪算法的好坏对特征提取的影响很大。字符切分则是将图像中的文字分割成单个文字——识别的时候是一个字一个字识别的。如果文字行有倾斜的话往往还要进行倾斜校正。归一化则是将单个的文字图像规整到同样的尺寸,在同一个规格下,才能应用统一的算法。
- 特征提取和降维:特征是用来识别文字的关键信息,每个不同的文字都能通过特征来和其他文字进行区分。对于数字和英文字母来说,这个特征提取是比较容易的,因为数字只有10个,英文字母只有52个,都是小字符集。对于汉字来说,特征提取比较困难,因为首先汉字是大字符集,国标中光是最常用的第一级汉字就有3755个;第二个汉字结构复杂,形近字多。在确定了使用何种特征后,视情况而定,还有可能要进行特征降维,这种情况就是如果特征的维数太高(特征一般用一个向量表示,维数即该向量的分量数),分类器的效率会受到很大的影响,为了提高识别速率,往往就要进行降维,这个过程也很重要,既要降低维数吧,又得使得减少维数后的特征向量还保留了足够的信息量(以区分不同的文字)。
- 分类器设计、训练和实际识别:分类器是用来进行识别的,就是对于第二步,你对一个文字图像,提取出特征给,丢给分类器,分类器就对其进行分类,告诉你这个特征该识别成哪个文字。在进行实际识别前,往往还要对分类器进行训练,这是一个监督学习的案例。成熟的分类器也很多,什么svm,kn,神经网络etc。
- 后处理:后处理是用来对分类结果进行优化的。第一个,分类器的分类有时候不一定是完全正确的(实际上也做不到完全正确),比如对汉字的识别,由于汉字中形近字的存在,很容易将一个字识别成其形近字。后处理中可以去解决这个问题,比如通过语言模型来进行校正——如果分类器将“在哪里”识别成“存哪里”,通过语言模型会发现“存哪里”是错误的,然后进行校正。第二个,OCR的识别图像往往是有大量文字的,而且这些文字存在排版、字体大小等复杂情况,后处理中可以尝试去对识别结果进行格式化,比如按照图像中的排版排列什么的,举个栗子,一张图像,其左半部分的文字和右半部分的文字毫无关系,而在字符切分过程中,往往是按行切分的,那么识别结果中左半部分的第一行后面会跟着右半部分的第一行诸如此类。
2. 传统文字识别:文字检测、文字识别
General OCR一般包含两步:
- detection --> 找到包含文字的区域(proposals)
- classification --> 识别区域(proposals)中的文字

文本检测(Text Detection):定位图片中的文本区域,而Detection定位精度直接影响后续Recognition结果。

目前已经有很多文字检测方法,包括:EAST/CTPN/SegLink/PixelLink/TextBoxes/TextBoxes++/TextSnake/MSR/…
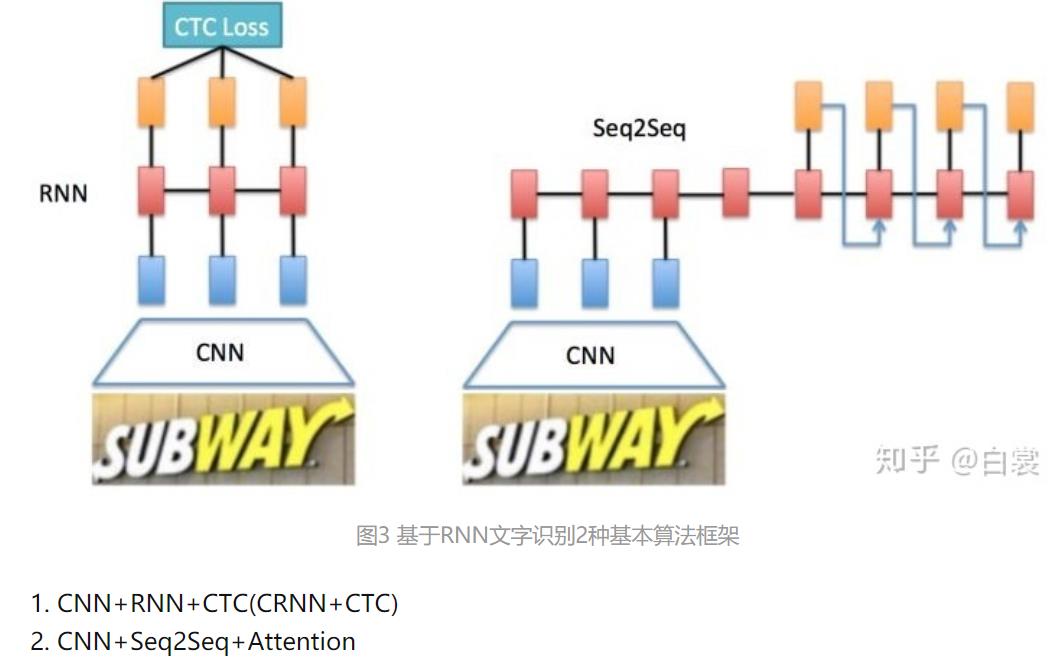
文字识别(Text Recognition):识别水平文本行,一般用CRNN或Seq2Seq两种方法。
- CRNN:CNN+RNN+CTC
- CNN+Seq2Seq+Attention
3. 端到端的文字识别
在之前介绍的算法中,文字检测和文字识别是分为两个网络分别完成的,所以希望将OCR中的Detection+ Recognition合并成一个End2End网络。
二、文本检测算法:CTPN
CTPN是在ECCV 2016提出的一种文字检测算法。CTPN结合CNN与双向LSTM深度网络,能有效的检测出复杂场景的横向分布的文字,效果如图1,是目前比较好的文字检测算法。CTPN是从Faster RCNN改进而来。

Q:什么是LSTM?
为了实现对不定长文字的识别,就需要有一种能力更强的模型,该模型具有一定的记忆能力,能够按时序依次处理任意长度的信息,这种模型就是“循环神经网络”(Recurrent Neural Networks,简称RNN)。
LSTM(Long Short Term Memory,长短期记忆网络)是一种特殊结构的RNN(循环神经网络),用于解决RNN的长期依赖问题,也即随着输入RNN网络的信息的时间间隔不断增大,普通RNN就会出现“梯度消失”或“梯度爆炸”的现象,这就是RNN的长期依赖问题,而引入LSTM即可以解决这个问题。LSTM单元由**输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)**组成。

三、文本识别算法:CRNN+CTC
CRNN+CTC = CNN + RNN+ LSTM + CTC
- 首先CNN提取图像卷积特征
- 然后LSTM进一步提取图像卷积特征中的序列特征
- 最后引入CTC解决训练时字符无法对齐的问题
基于RNN文字识别2种基本算法框架:
Q:什么是CTC?
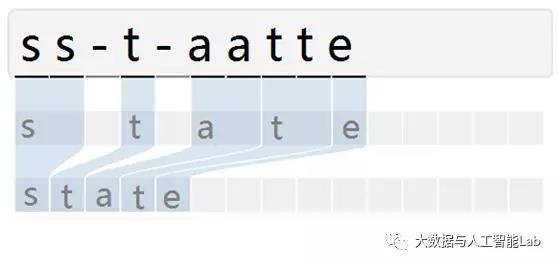
CTC(Connectionist Temporal Classifier,联接时间分类器),主要用于解决输入特征与输出标签的对齐问题。例如下图,由于文字的不同间隔或变形等问题,导致同个文字有不同的表现形式,但实际上都是同一个文字。在识别时会将输入图像分块后再去识别,得出每块属于某个字符的概率(无法识别的标记为特殊字符”-”),如下图:

由于字符变形等原因,导致对输入图像分块识别时,相邻块可能会识别为同个结果,字符重复出现。因此,通过CTC来解决对齐问题,模型训练后,对结果中去掉间隔字符、去掉重复字符(如果同个字符连续出现,则表示只有1个字符,如果中间有间隔字符,则表示该字符出现多次),如下图所示:
以上是关于文字识别(输入为自然场景中的图像)的主要内容,如果未能解决你的问题,请参考以下文章