Beats:使用 Filebeat 中的 HTTP JSON input 来摄入网络服务数据
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Beats:使用 Filebeat 中的 HTTP JSON input 来摄入网络服务数据相关的知识,希望对你有一定的参考价值。
我们知道在许多的 Web Service 中,有许多的数据是以 JSON 形式提供的。有些时候,我们希望使用一种方式能够把这些数据摄入到 Elasticsearch 中,并对这些数据进行分析。针对一些用户来说,它们可能想到的工具就是使用常用的编程语言,比如 Java, Python, Go, Nodejs, Ruby 等来对数据进行抓取,并把数据导入到 Elasticsarch 中。这种方法虽然很好,但是需要有专业的技术人员进行编程,但是它还不能充分运用 Filebeat 里所提供的强大的一些 processors 所提供的对数据情绪的功能。Filebeat 针对数据的摄入还有其它的一些好处,比如 flow control 等。在今天的文章中,我来介绍如何使用 Filebeat 来对这些 Web Service 的数据进行摄入。

在我们之前的文章 “Logstash:运用 Logstash 对 Service API 数据进行分析” 里,我也详述了如何使用 Logstash 来对 Web Service 的数据进行采集。针对大多数的开发者来说,使用最多的 Filebeat input type 可能就是 log。如果你想了解更多其它的 Filebeat 的 input type,请参阅我之前的文章 “Beats:为 Filebeat 配置 inputs”。
在今天的教程中,我将使用 Filebeat 的 HTTP JSON input。
HTTP JSON input
使用 httpjson 输入从带有 JSON 有效负载的 HTTP API 读取消息。
此输入支持:
- 认证
- 基本的
- OAuth2
- 以可配置的时间间隔检索
- 分页
- 重试
- 速率限制
- 代理
- 请求转换
- 响应转换
一些典型的用例:
filebeat.inputs:
# Fetch your public IP every minute.
- type: httpjson
interval: 1m
request.url: https://api.ipify.org/?format=json
processors:
- decode_json_fields:
fields: ["message"]
target: "json"filebeat.inputs:
- type: httpjson
request.url: http://localhost:9200/_search?scroll=5m
request.method: POST
response.split:
target: body.hits.hits
response.pagination:
- set:
target: url.value
value: http://localhost:9200/_search/scroll
- set:
target: url.params.scroll_id
value: '[[.last_response.body._scroll_id]]'
- set:
target: body.scroll
value: 5m此外,它还支持通过基本身份验证、HTTP 标头或 oauth2 进行身份验证。
带有身份验证的示例配置:
filebeat.inputs:
- type: httpjson
request.url: http://localhost
request.transforms:
- set:
target: header.Authorization
value: 'Basic aGVsbG86d29ybGQ='filebeat.inputs:
- type: httpjson
auth.oauth2:
client.id: 12345678901234567890abcdef
client.secret: abcdef12345678901234567890
token_url: http://localhost/oauth2/token
request.url: http://localhost动手实践
首先我们按照如下的文章来安装好 Elasticsearch 及 Kibana:
我们今天练习的一个网络服务的网址:https://api.github.com/repos/elastic/beats/issues?per_page=100。我们点击这个链接,我们可以看到:
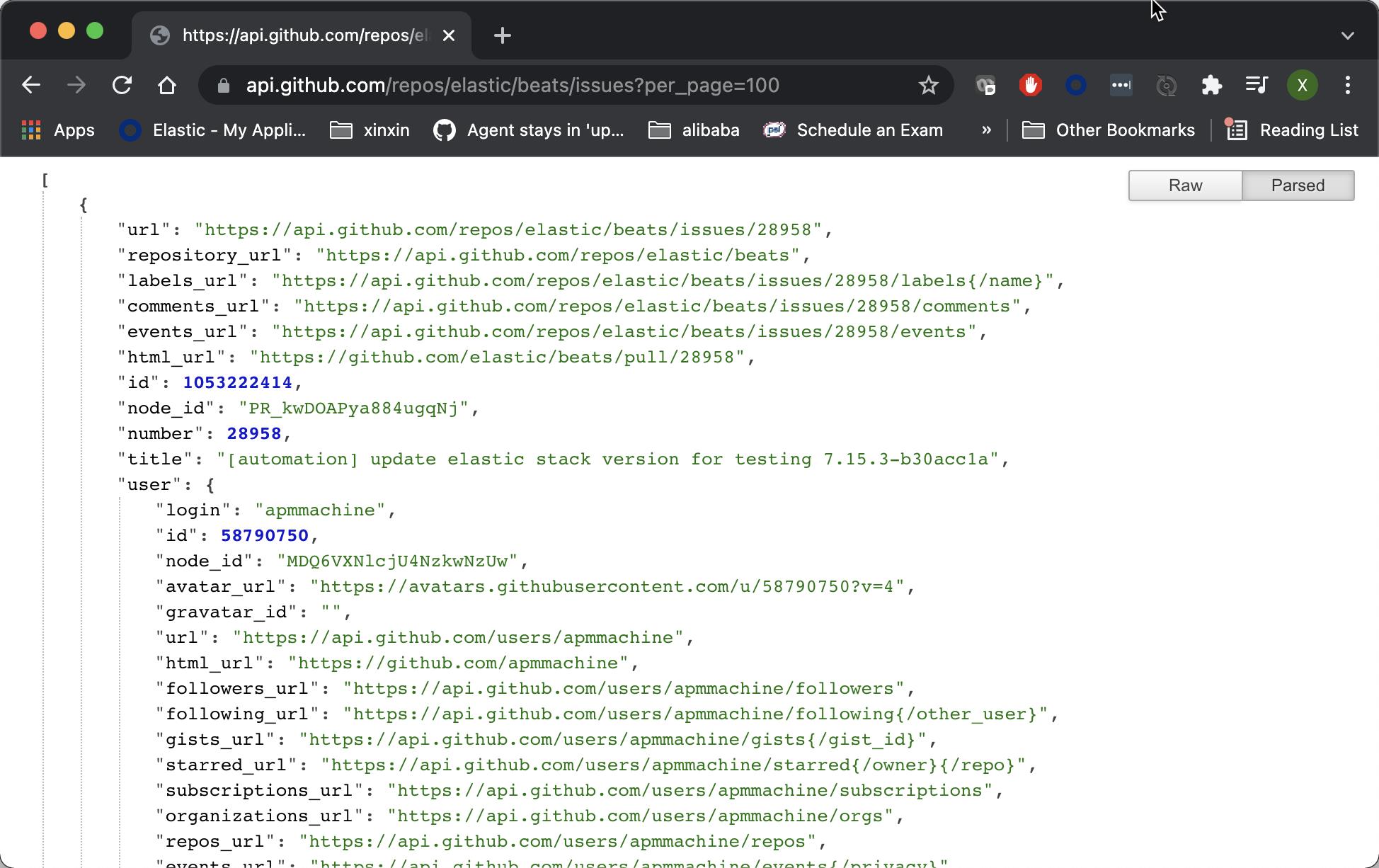
这是在 github 上的一个服务。它提供了所有关于 beats 的一些 issues。当然我们甚至可以书写如下类似的一个 Python 脚本来完成:
from elasticsearch import Elasticsearch
import requests
r = requests.get("https://api.github.com/repos/elastic/beats/issues")
es = Elasticsearch(["host1", "host2"])
for doc in r.json():
res = es.index(index="github-beat-issues", document=doc)如果你想了解如何使用 Python 来导数据至 Elasticsearch,请参考文章 “Elastic:开发者上手指南”。使用代码的问题是如何获得多个 page 的数据以及如何避免多次运行应用造成的一个文档多个实例的问题。
在 Filebeat 中,它已经有一个现成的 httpjson input 类型可以供我们使用。我们不需要重新创建轮子。在接下来的介绍中,我们来展示如何通过 httpjson input type 来实现对 Web Service 的数据进行抓取。
首先,我们在自己的系统上安装好 Filebeat。如果你对 Fillebeat 的使用还不是很熟的话,请参阅我之前的文章:
然后,我们在 fillebeat.yml 文件的最上面添加如下的类容:
filebeat.yml
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: httpjson
interval: 1m
config_version: 2
request.url: https://api.github.com/repos/elastic/beats/issues?per_page=100
request.method: GET我们接下来运行 Filebeat:
./filebeat -e我们到 Kibana 中进行查看:
GET filebeat-7.15.0/_count{
"count" : 200,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}上面显示有 200 个文档。它表明数据在收集。因为我们是每1分钟运行一次,那么在几分钟中过后,我们可以看到文档的数据在不断增加。在 Kibana 的 Discover 中,我们也可以看到如下的内容:

首先,我们看到所有的内容都显示在 message 字段。没有任何的化。它不便于我们对数据进行分析。另外所有的数据都集中在被采集的时段,而不是安装 issue 被提交的时间来进行显示的。显然这是一个良好的开始。它表示 httpjson input 确实是在工作。
我们接下来针对上面的 httpjson input 来进行如下的修改:
- type: httpjson
interval: 1m
config_version: 2
request.url: https://api.github.com/repos/elastic/beats/issues?per_page=100
request.method: GET
processors:
- add_fields:
fields:
service: github
- decode_json_fields:
fields: ["message"]
target: "json"在上面,我们使用 Filebeat 所提供的 processors 来对数据进行处理:
- 添加一个 service 字段。假如你有多个服务,那么你可以通过 service 这个字段对数据分别进行分析。
- 对 JSON 数据结构化,这样我们可以对数据更好地分析。使用 decode_json_fields 处理器来对数据进行结构化
我们可以在 Kibana 中删除 Filebeat 的所有数据:
DELETE filebeat-7.15.0*然后,我们再次重新运行 Filebeat:
./filebeat -e我们再次回到 Kibana 中:

我们可以看到一个新增加的 service 字段为 github 外,我们还可以看到一个新增加的 json 字段,而它里面的内容是之前 message 字段的格式化数据:
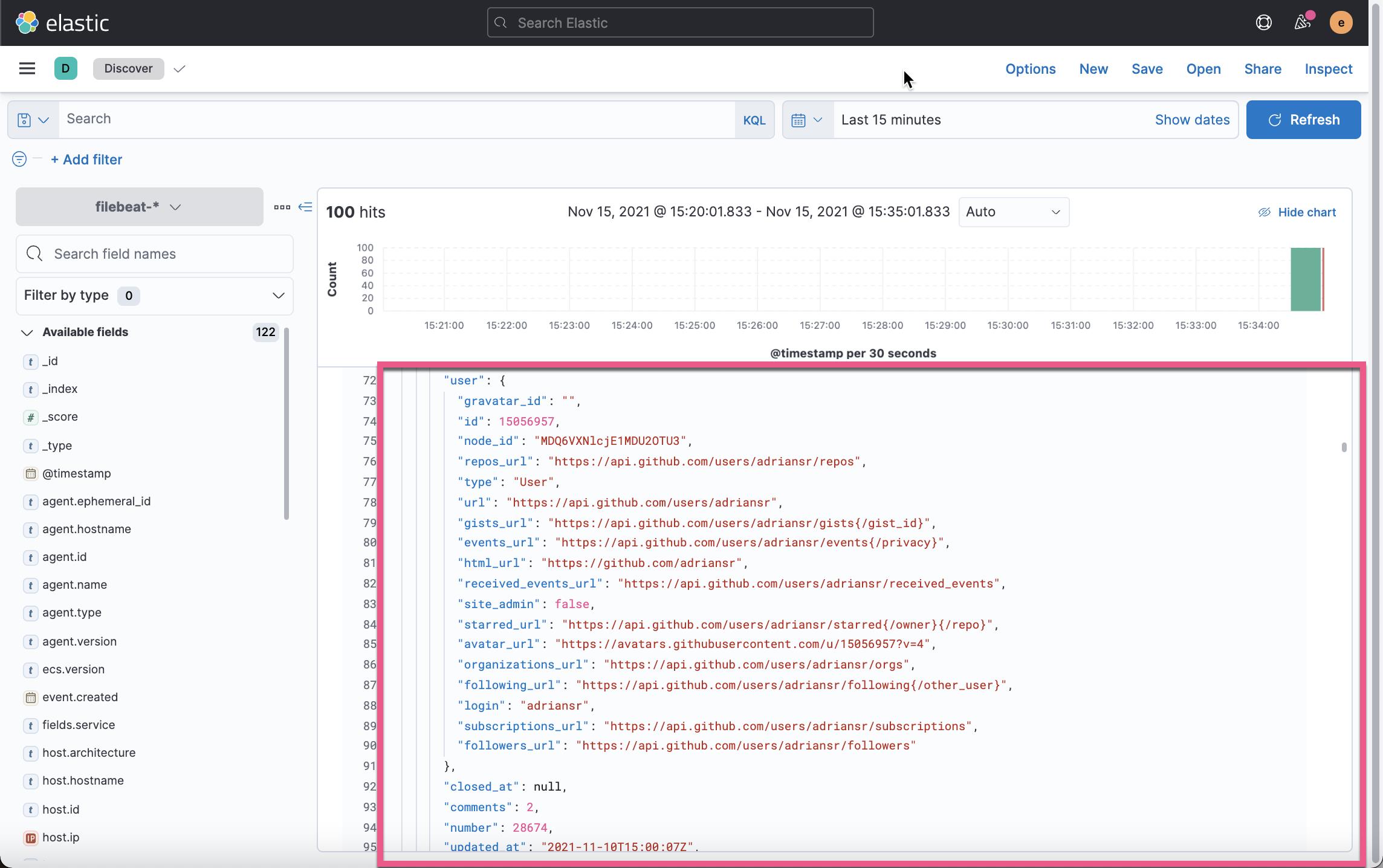
我们可以比较之前的 Web Service 请求输出:

我们发现数据都是集中在被采集的时段,这是因为我们没有使用 issue 的 timestamp 作为文档的 timestamp 所致。我们接着修改 httpjson input。在 json object 里有一个叫做 create_at 的字段。它是 issue 被创建的时间。我们使用这个字段作为文档的 timestamp。我们可以使用 Filebeat 所提供的 timestamp 处理器:
- type: httpjson
interval: 1m
config_version: 2
request.url: https://api.github.com/repos/elastic/beats/issues?per_page=100
request.method: GET
processors:
- add_fields:
fields:
service: github
- decode_json_fields:
fields: ["message"]
target: "json"
- timestamp:
field: json.created_at
layouts:
- '2006-01-02T15:04:05Z'
- '2006-01-02T15:04:05.999Z'
- '2006-01-02T15:04:05.999-07:00'
test:
- '2019-06-22T16:33:51Z'
- '2019-11-18T04:59:51.123Z'
- '2020-08-03T07:10:20.123456+02:00'我们重新删除 filebeat 里的所有数据:
DELETE filebeat-7.15.0*重新运行 Filebeat:
./filebeat -e我们在 Kibana 里进查看:

这次我们发现事件的时间不再是数据采集的时间,而是真实的 issue 所提交的时间。
如果这个时候我们把 Filebeat 停下来,在不删除 filebeat 索引的情况下,再次运行 Filebeat,那么我们可以发现同样的一个文档(issue)被导入两次,虽然他们的 id 并不相同。我们可以参照我之前的文档 “Logstash:运用 fingerprint 过滤器处理重复的文档”。我们在 Fillebeat 里使用同样的技巧。我们来使用 fingerprint 处理器:
- type: httpjson
interval: 5m
config_version: 2
request.url: https://api.github.com/repos/elastic/beats/issues?per_page=100
request.method: GET
processors:
- add_fields:
fields:
service: github
- decode_json_fields:
fields: ["message"]
target: "json"
- timestamp:
field: json.created_at
layouts:
- '2006-01-02T15:04:05Z'
- '2006-01-02T15:04:05.999Z'
- '2006-01-02T15:04:05.999-07:00'
test:
- '2019-06-22T16:33:51Z'
- '2019-11-18T04:59:51.123Z'
- '2020-08-03T07:10:20.123456+02:00'
- fingerprint:
fields: ["json.id"]
target_field: "@metadata._id"在上面,我们通过把 json.id 映射为 Elasticsearch 索引中的文档 _id 字段。我们重新运行 Filebeat。这次我们发现无论我们运行 Filebeat 多少次,针对同样的一个 issue,我们不会看到重复的文档,因为每次摄入数据时,文档的 _id 都是一样的,不再是每次摄入时由 Elasticsearch 自动分配一个不同的 id。
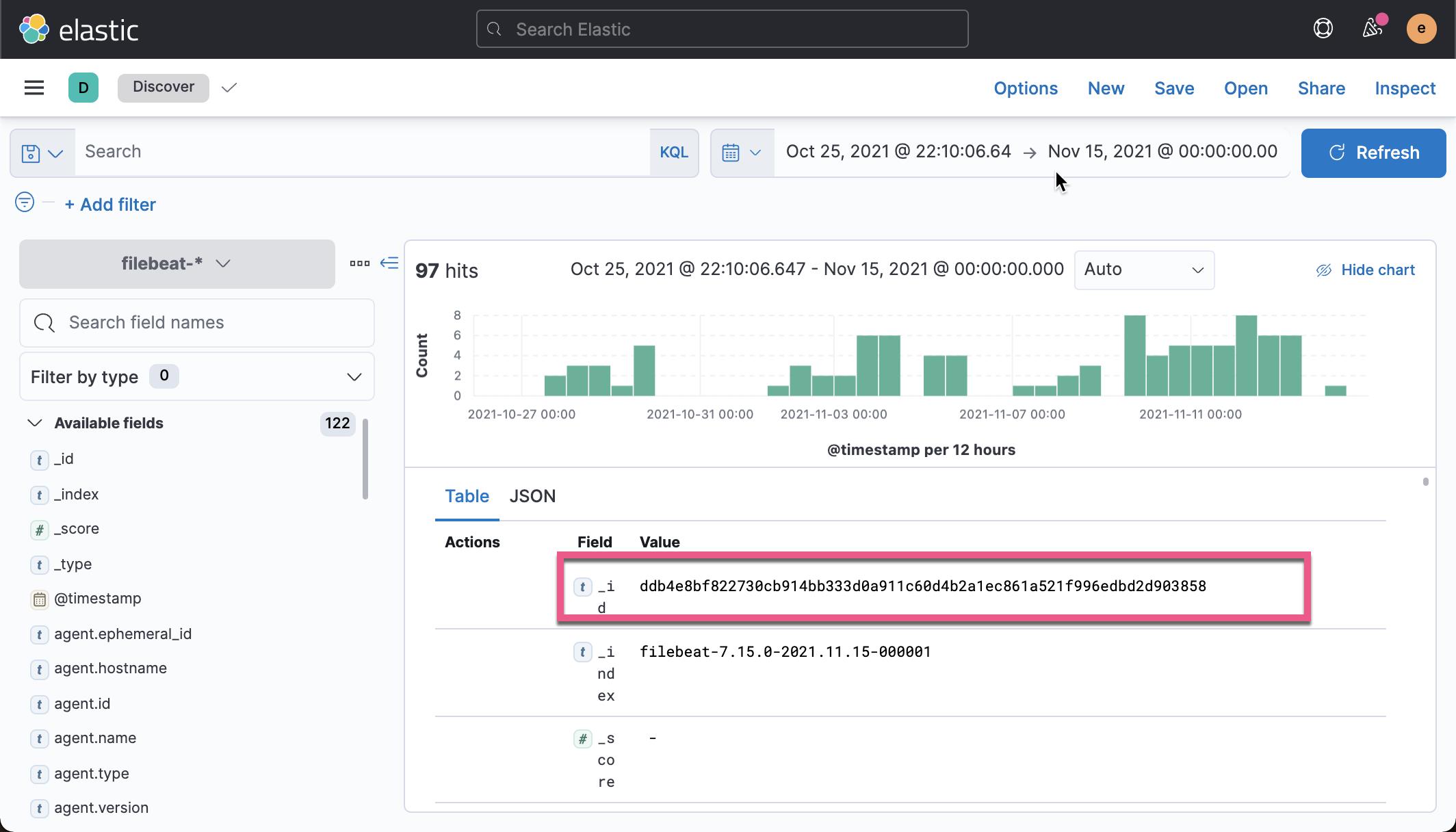
针对 Filebeat 来说,默认的 op_type 是 create。它的意思是,在摄入时,如果一个文档的 id 已经存在,那么就不会摄入数据了。如果该文档的 id 在索引中没有存在,那么就创建一个新的文档。
我们可以使用 script processor 来修改 Filebeat 的这种默认的 op_type。在下面的例子中,我们把它的 op_type 修改为 index,也就是说无论该 id 文档之前是否存在,重新创建一个崭新的文档。详细情况可以参考 https://github.com/elastic/beats/issues/23091
- type: httpjson
interval: 5m
config_version: 2
request.url: https://api.github.com/repos/elastic/beats/issues?per_page=100
request.method: GET
processors:
- add_fields:
fields:
service: github
- decode_json_fields:
fields: ["message"]
target: "json"
- timestamp:
field: json.created_at
layouts:
- '2006-01-02T15:04:05Z'
- '2006-01-02T15:04:05.999Z'
- '2006-01-02T15:04:05.999-07:00'
test:
- '2019-06-22T16:33:51Z'
- '2019-11-18T04:59:51.123Z'
- '2020-08-03T07:10:20.123456+02:00'
- fingerprint:
fields: ["json.id"]
target_field: "@metadata._id"
- script:
lang: javascript
id: update_instead_of_ignore_same_id
source: >
function process(event) {
event.Put("@metadata.op_type", "index")
}接下来,我们来处理分页。我们使用 github 所提供的 API 并进行如下的修改:
- type: httpjson
interval: 5m
config_version: 2
request.url: https://api.github.com/repos/elastic/beats/issues?per_page=100
request.method: GET
reponse.pagination:
- set:
target: url.params.page
value: '[[add .last_reponse.page 1]]'
fail_on_template: true
processors:
- add_fields:
fields:
service: github
- decode_json_fields:
fields: ["message"]
target: "json"
- timestamp:
field: json.created_at
layouts:
- '2006-01-02T15:04:05Z'
- '2006-01-02T15:04:05.999Z'
- '2006-01-02T15:04:05.999-07:00'
test:
- '2019-06-22T16:33:51Z'
- '2019-11-18T04:59:51.123Z'
- '2020-08-03T07:10:20.123456+02:00'
- fingerprint:
fields: ["json.id"]
target_field: "@metadata._id"
- script:
lang: javascript
id: update_instead_of_ignore_same_id
source: >
function process(event) {
event.Put("@metadata.op_type", "index")
}在上面,我们添加了如下的部分:
reponse.pagination:
- set:
target: url.params.page
value: '[[add .last_reponse.page 1]]'
fail_on_template: true 最后,我们发现 json.body 及 message 字段占用太多的空间,而且也不是我们想要的。我们可以通过添加 drop_fields 处理器把这些不需要的字段删除:
- type: httpjson
interval: 5m
config_version: 2
request.url: https://api.github.com/repos/elastic/beats/issues?per_page=100
request.method: GET
reponse.pagination:
- set:
target: url.params.page
value: '[[add .last_reponse.page 1]]'
fail_on_template: true
processors:
- add_fields:
fields:
service: github
- decode_json_fields:
fields: ["message"]
target: "json"
- timestamp:
field: json.created_at
layouts:
- '2006-01-02T15:04:05Z'
- '2006-01-02T15:04:05.999Z'
- '2006-01-02T15:04:05.999-07:00'
test:
- '2019-06-22T16:33:51Z'
- '2019-11-18T04:59:51.123Z'
- '2020-08-03T07:10:20.123456+02:00'
- fingerprint:
fields: ["json.id"]
target_field: "@metadata._id"
- script:
lang: javascript
id: update_instead_of_ignore_same_id
source: >
function process(event) {
event.Put("@metadata.op_type", "index")
}
- drop_fields:
fields: ["message", "json.body"]
ignore_missing: false我们删除 filebeat 索引,并重新启动 Filebeat。我们再次在 Kibana 中查看,我们将再也看不到 message 及 json.body 字段了。
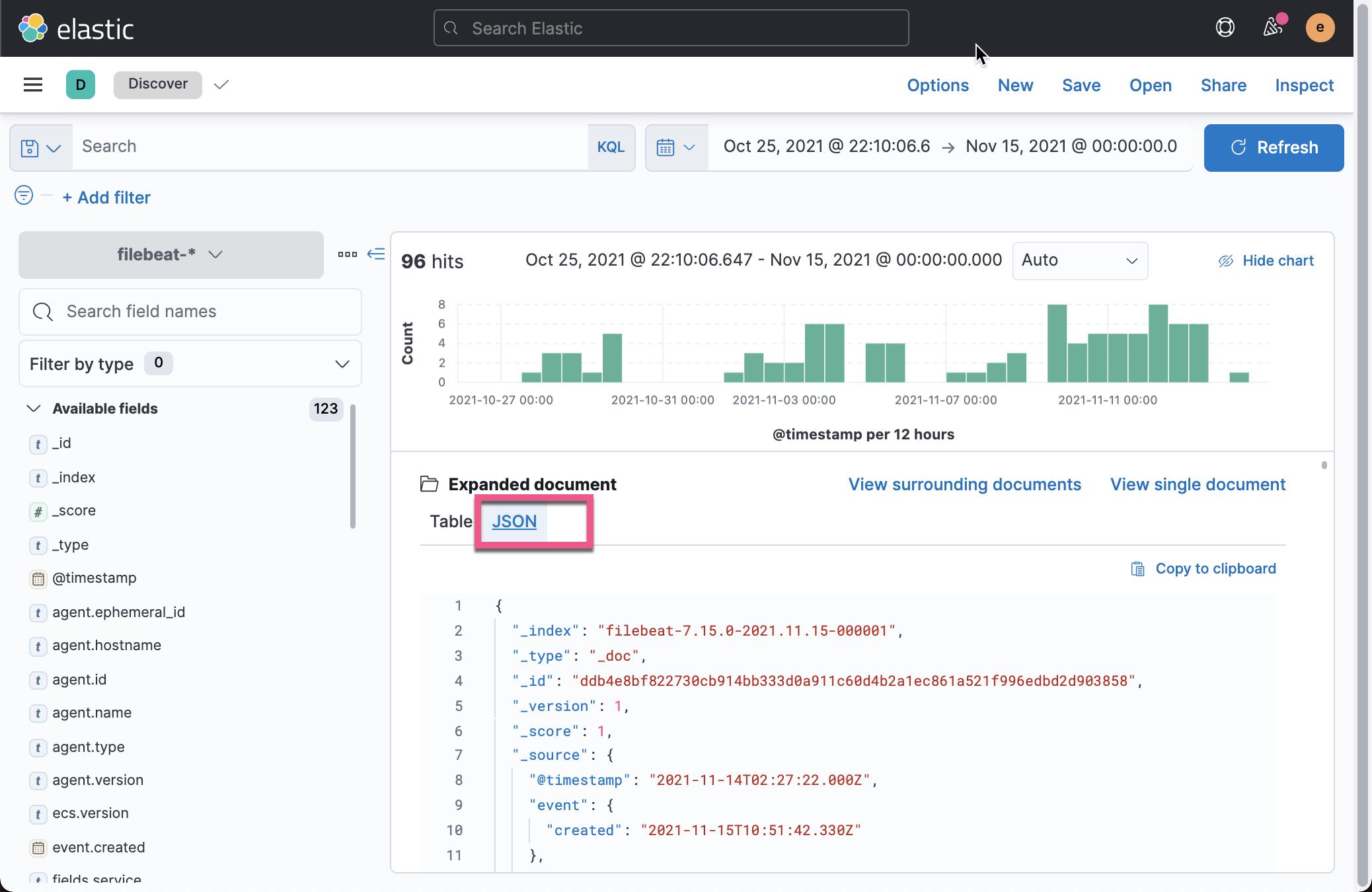
以上是关于Beats:使用 Filebeat 中的 HTTP JSON input 来摄入网络服务数据的主要内容,如果未能解决你的问题,请参考以下文章