什么是ETL?一文掌握ETL设计过程
Posted 大数据v
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是ETL?一文掌握ETL设计过程相关的知识,希望对你有一定的参考价值。

导读:ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
作者:范钢 孙玄
来源:数仓宝贝库(ID:DataBaby_Family)

未经过任何加工的原始数据,往往存在着诸多的问题,数据质量不高,所以数据分析成本很高。原始数据必须要经过一个ETL过程,才能用于后续的分析挖掘工作。
更关键的是,数据来源的业务系统也是在不断地更新维护中的,任何一个变更都会对下游的数据分析程序产生巨大的影响。因此,有了ETL过程作为一个缓冲区,当上游的业务系统变更时,只需要对ETL过程进行相应变更,下游的数据分析就能够比较稳定,从而降低系统维护成本。
01 数据清洗
首先进行数据清洗,对原始数据中的错误予以纠正,或者对缺失数据进行补填。譬如,现在要建设一个增值税发票的数据中台。这时,系统从许多不同的来源采集与增值税发票相关的数据。当收集完这些原始数据以后,进行数据清洗工作。增值税发票的数据结构如下图所示。
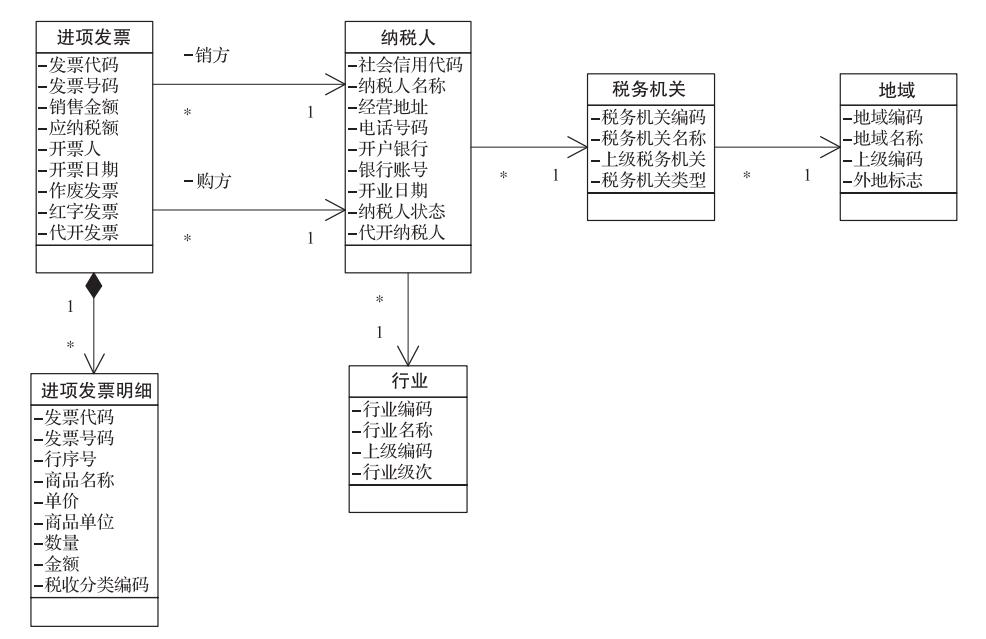
▲增值税发票的数据结构图
在正常的增值税发票的数据结构中,每张进项发票都应当有至少一条发票明细。然而,可能由于采集的数据不一致,发票与明细经常不是同时到来,可能相差几天,造成用发票分析的数据与用发票明细分析的数据不一致。
这时,必须要先补填一个发票明细,虽然商品名称与数量不知道,但至少要保证发票明细的金额之和要等于发票金额,才不至于影响后续的分析质量。至于商品名称,可以暂时补填一个“未知商品”。这样,当该发票真正的发票明细到来时,再覆盖原有补填的明细。
此外,原本每张发票都应当有购方纳税人与销方纳税人,然而由于纳税人信息的基础数据来源于不同的系统,可能造成该发票的纳税人信息不在纳税人信息表中的情况。这时,必须要补填一条纳税人信息,使得发票表与纳税人能够对应上,不会造成数据无法关联而缺失数据。
同理,每个纳税人都应当有各自的税务机关、地域和行业,这些信息都可能缺失。对于税务机关和地域,可以通过纳税人社会信用代码中的内容进行推测。但是,行业信息是无法推测的。即使无法推测,也不能将其置为null,而是填一个默认值X99999,对应到行业表中的“未知行业”。
数据清洗的过程通过SparkSQL来实现。通过SparkSQL从原始表中查询数据,然后经过以下处理过程,最终写入ETL临时表中:
object ZzsfpJx {
def main(args: Array[String]): Unit = {
val task = LogUtils.start("zzsfpJxQd")
try {
val spark = SparkUtils.init("zzsfpJx")
val ETLFPMAPNUM = PropertyFile.getProperty("ETLFPMAPNUM").toInt
spark.udf.register("getJxfpId", (fpdm:String, fphm:String, kprq:String) =>
if(null==kprq) fpdm+"X"+fphm+"X" else fpdm+"X"+fphm+"X"+kprq)
UdfRegister.fillNsr(spark)
UdfRegister.fillSwjg(spark)
UdfRegister.cutSL(spark)
val result = spark.sql("SELECT getJxfpId(D.FPDM,D.FPHM,D.KPRQ) JXFP_ID,D.FPDM,D.
FPHM,'YB' FP_LB,D.JE JE,cast(cutSL(D.SE/D.JE) as double) SL,D.
SE SE,fillNsr(D.XFSBH) XF_NSRSBH, D.XFMC XF_NSRMC, fillNsr(D.GFSBH) GF_NSRSBH,
D.GFMC GF_NSRMC,D.KPRQ, D.KPRQ RZSJ, D.XF_QXSWJG_DM SWJG_DM,
from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') CZSJ,NSR.SWJG_KEY GF_SWJG_DM,
getSwjg(D.XF_QXSWJG_DM,fillNsr(D.XFSBH)) XF_SWJG_DM, case trim(D.fpzt_dm)
when '0' then 'N' when '1' then 'N' else 'Y' end ZFBZ,'' SKM,'' SHRSBH,'
' SHRMC,'' FHRSBH,'' FHRMC,'' QYD,'' SKPH, D.JSHJ,'' CZCH,'' CCDW,''
YSHWXX,D.BZ,D.tspz_dm as TSPZBZ,CASE WHEN
length(trim(D.zfrq))>15 THEN D.zfrq ELSE NULL END ZFSJ FROM dzdz.DZDZ_FPXX_ZZSFP
D JOIN DW.DW_DM_NSR NSR ON D.GFSBH = NSR.NSR_KEY and
NSR.WDBZ='1'").repartition(ETLFPMAPNUM)
DataFrameUtils.saveAppend(result, "etl", "etl_jxfp")
LogUtils.end(task)
} catch { case ex:Exception => LogUtils.error(task, ex) }
}
}在以上SparkSQL程序中,首先从原始数据dzdz.DZDZ_FPXX_ZZSFP中查询数据,通过公用方法UdfRegister.fillNsr(spark)与UdfRegister.fillSwjg(spark)对纳税人与税务机关进行补填,保证发票在与纳税人信息、税务机关信息关联时不会因为数据为null而造成数据缺失。最终,将结果数据写入etl_jxfp的临时表中。
此外,在处理发票明细时加入了这样一段语句:
val result1 = spark.sql("SELECT getJxfpqdId(R.FPDM,R.FPHM,R.KPRQ,'00','1') JXFPQD_ID,
getJxfpId(R.FPDM,R.FPHM,R.KPRQ) JXFP_ID ,1.0 HH,'YB' FP_LB,
'无商品明细' WP_MC,'' WP_DW,'' WP_XH,1.0 WP_SL,R.JE DJ,R.JE, cast(cutSL(R.SL) as double) SL,R.SE,R.RZSJ, from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') CZSJ,R.KPRQ,'00' QDBZ,'' SKPH,'' SFZHM,'' CD,'' HGZS,'' JKZMSH,'' SJDH,'' FDJHM,
'' CJHM,'' DH,'' ZH,'' KHYH,'' DW,'' XCRS,0.0 JSHJ,'9999999999999999999' spbm "+s"FROM dzdz.DZDZ_HWXX_ZZSFP D
RIGHT JOIN etl.ETL_JXFP R ON (D.FPDM = R.FPDM AND D.FPHM = R.FPHM)
WHERE (D.FPDM is null or D.FPHM is null) and R.FP_LB='YB' ").repartition(ETLFPMAPNUM)
DataFrameUtils.saveAppend(result1, "etl", "etl_jxfp_qd")通过该语句在发票明细中加入了名为“无商品明细”的记录,保证发票明细、发票的金额与税额没有缺失,保障后续数据分析的准确性。
02 数据转换
以上一系列的数据清洗,可以有效杜绝因为缺失数据或关联不上造成的数据分析质量问题。接着,就是数据转换与集成。
数据中台的数据来源于不同的业务系统,因此数据格式、计算口径都可能存在差异。当把它们都抽取到数据中台以后,应当将其转换成统一口径,并规范计算口径。
譬如,如何识别代开发票,不同的系统有不同的判断逻辑,但经过数据转换以后,可以在表中增加一个“是否代开发票”字段,这样后续的分析业务就不必再去判断了,直接看该字段即可。此外,同样是税务机关代码,有的系统是9位,有的系统是11位,应该将它们都统一成11位。以上这些工作就是数据转换。
03 数据集成
清洗和转换工作完成以后,将相同或者相似的数据都集成在一起。譬如,从各个不同路径采集的纳税人信息,包括纳税人的基础信息、认证信息、核定信息、资格信息,都集成到了纳税人表中;从各个不同路径采集的各种不同的增值税发票,如增值税专票、增值税普票、机动车统一销售发票、电子发票等类型的发票,都统一集成到发票信息表中。
它们都来源于不同的业务系统,字段与类型都各不相同。因此,在集成的过程中,需要进行转换或补填,彼此格式一致,并最终存入同一张表中。譬如,其他发票都有发票明细,但机动车统一销售发票没有,因此需要给它补填一条发票明细,商品就是那辆汽车,金额与税额都是那张发票的金额与税额。
在具体设计实现上,就是为每一种发票都编写一个发票与发票明细的SparkSQL程序。它们分别从各自的原始数据中获取,但经过一个SQL语句的转换,最终都存入名为etl_jxfp与etl_jxfp_qd的发票与发票明细临时表中。
本文摘编自《架构真意:企业级应用架构设计方法论与实践》,经出版方授权发布。

延伸阅读👇

《架构真意:企业级应用架构设计方法论与实践》
推荐语:资深架构专家撰写,孙玄老师的“百万年薪架构师”训练营配套书籍,从架构设计方法论、分布式架构设计与实践、大数据架构设计三方面介绍架构设计方法。
干货直达👇
更多精彩👇
在公众号对话框输入以下关键词
查看更多优质内容!
读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
👇
以上是关于什么是ETL?一文掌握ETL设计过程的主要内容,如果未能解决你的问题,请参考以下文章