Filebeat日志采集器实例
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Filebeat日志采集器实例相关的知识,希望对你有一定的参考价值。
目录
1 概述

Beats是用于单用途数据托运人的平台。它们以轻量级代理的形式安装,并将来自成百上千台机器的数据发送到Logstash或Elasticsearch。(通俗地理解,就是采集数据,并上报到Logstash或Elasticsearch)
Beats对于收集数据非常有用。它们位于你的服务器上,将数据集中在Elasticsearch中,Beats也可以发送到Logstash来进行转换和解析。
为了捕捉(捕获)数据,Elastic提供了各种Beats(如Filebeat):

2 安装Filebeat
https://www.elastic.co/cn/beats/filebeat
https://www.elastic.co/cn/downloads/beats/filebeat

2.1 配置Filebeat
配置文件:filebeat.yml
为了配置Filebeat:
1. 定义日志文件路径
对于最基本的Filebeat配置,你可以使用单个路径。例如:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
在这个例子中,获取在/var/log/*.log路径下的所有文件作为输入,这就意味着Filebeat将获取/var/log目录下所有以.log结尾的文件。
为了从预定义的子目录级别下抓取所有文件,可以使用以下模式:/var/log//.log。这将抓取/var/log的子文件夹下所有的以.log结尾的文件。它不会从/var/log文件夹本身抓取。目前,不可能递归地抓取这个目录下的所有子目录下的所有.log文件。
(假设配置的输入路径是/var/log//.log,假设目录结构是这样的:

那么只会抓取到2.log和3.log,而不会抓到1.log和4.log。因为/var/log/aaa/ccc/1.log和/var/log/4.log不会被抓到。
)
2. 如果你发送输出目录到Elasticsearch(并且不用Logstash),那么设置IP地址和端口以便能够找到Elasticsearch:
output.elasticsearch:
hosts: ["192.168.1.42:9200"]
3. 如果你打算用Kibana仪表盘,可以这样配置Kibana端点:
setup.kibana:
host: "localhost:5601"
4. 如果你的Elasticsearch和Kibana配置了安全策略,那么在你启动Filebeat之前需要在配置文件中指定访问凭据。例如:
output.elasticsearch:
hosts: ["myEShost:9200"]
username: "filebeat_internal"
password: "{pwd}"
setup.kibana:
host: "mykibanahost:5601"
username: "my_kibana_user"
password: "{pwd}"
2.2 配置Filebeat以使用Logstash
如果你想使用Logstash对Filebeat收集的数据执行额外的处理,那么你需要将Filebeat配置为使用Logstash。
output.logstash:
hosts: ["127.0.0.1:5044"]
3 案例
我们将前面所学习到的Elasticsearch + Logstash + Beats + Kibana整合起来做一个综合性的练习,目的就是能够更加深刻的理解Elastic Stack的使用。
3.1 流程说明

- 应用APP生产日志,用来记录用户的操作
- [INFO] 2019-03-15 22:55:20 [Main] - DAU|5206|使用优惠券|2019-03-15 03:37:20
- [INFO] 2019-03-15 22:55:21 [Main] - DAU|3880|浏览页面|2019-03-15 07:25:09
- 通过Filebeat读取日志文件中的内容,并且将内容发送给Logstash,原因是需要对内容做处理
- Logstash接收到内容后,进行处理,如分割操作,然后将内容发送到Elasticsearch中
- Kibana会读取Elasticsearch中的数据,并且在Kibana中进行设计Dashboard,最后进行展示
说明:日志格式、图表、Dashboard都是自定义的
3.2 日志环境介绍
APP在生产环境应该是真实系统,然而,现在我们学习的话,为了简化操作,所以就做数据的模拟生成即可。
业务代码如下:
package com.log;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.RandomUtils;
import org.joda.time.DateTime;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@Slf4j
@SpringBootApplication
public class Main {
public static final String[] VISIT = new String[]{"浏览页面", "评论商品", "加入收藏", "加入购物车", "提交订单", "使用优惠券", "领取优惠券", "搜索", "查看订单"};
public static void main(String[] args) throws Exception {
while(true){
Long sleep = RandomUtils.nextLong(200, 1000 * 5);
Thread.sleep(sleep);
Long maxUserId = 9999L;
Long userId = RandomUtils.nextLong(1, maxUserId);
String visit = VISIT[RandomUtils.nextInt(0, VISIT.length)];
DateTime now = new DateTime();
int maxHour = now.getHourOfDay();
int maxMillis = now.getMinuteOfHour();
int maxSeconds = now.getSecondOfMinute();
String date = now.plusHours(-(RandomUtils.nextInt(0, maxHour)))
.plusMinutes(-(RandomUtils.nextInt(0, maxMillis)))
.plusSeconds(-(RandomUtils.nextInt(0, maxSeconds)))
.toString("yyyy-MM-dd HH:mm:ss");
String result = "DAU|" + userId + "|" + visit + "|" + date;
log.error(result);
}
}
}
我们可以启动运行,就是不断的生成日志,模拟了我们的实际业务
09:18:32.721 [main] ERROR com.log.Main - DAU|8183|加入购物车|2020-09-25 06:10:25
09:18:33.599 [main] ERROR com.log.Main - DAU|7097|提交订单|2020-09-25 06:18:31
09:18:37.265 [main] ERROR com.log.Main - DAU|1468|查看订单|2020-09-25 02:04:10
09:18:39.634 [main] ERROR com.log.Main - DAU|7821|领取优惠券|2020-09-25 02:04:07
09:18:41.909 [main] ERROR com.log.Main - DAU|7962|提交订单|2020-09-25 03:02:39
09:18:43.596 [main] ERROR com.log.Main - DAU|3358|评论商品|2020-09-25 08:14:19
然后我们将该项目使用下面命令进行打包
mvn clean install
打包完成后,到target目录下,能够看到我们生成的jar包
#打包成jar包,在linux上运行
java -jar itcast-dashboard-generate-1.0-SNAPSHOT.jar
#运行之后,就可以将日志写入到/itcast/logs/app.log文件中
3.3 配置Filebeat
在有了不断产生日志的应用程序后,我们就需要创建一个Filebeat的配置文件,用于日志的收集
# 打开配置文件
vim mogu-dashboard.yml
# 写入数据
filebeat.inputs:
- type: log
enabled: true
paths:
- /soft/app/*.log
setup.template.settings:
index.number_of_shards: 1
output.logstash:
hosts: ["127.0.0.1:5044"]
然后我们就可以启动了【需要我们把Logstash启动起来】
./filebeat -e -c mogu-dashboard.yml
3.4 配置Logstash
3.4.1 Logstash输出到控制台
Logstash的主要目的就是处理Filebeat发送过来的数据,进行数据的清洗,过滤等,我们首先简单的将logstash获得的数据输出到控制台
# 打开配置文件
vim mogu-dashboard.conf
# 添加以下内容
input {
beats {
port => "5044"
}
}
output {
stdout { codec => rubydebug }
}
然后启动我们的logstash 【注意,启动时间比较长,需要我们等待】
./bin/logstash -f mogu-dashboard.conf
启动logstash完成后,我们需要再次启动filebeat,回到上面的启动步骤,然后就能看到logstash输出我们的日志
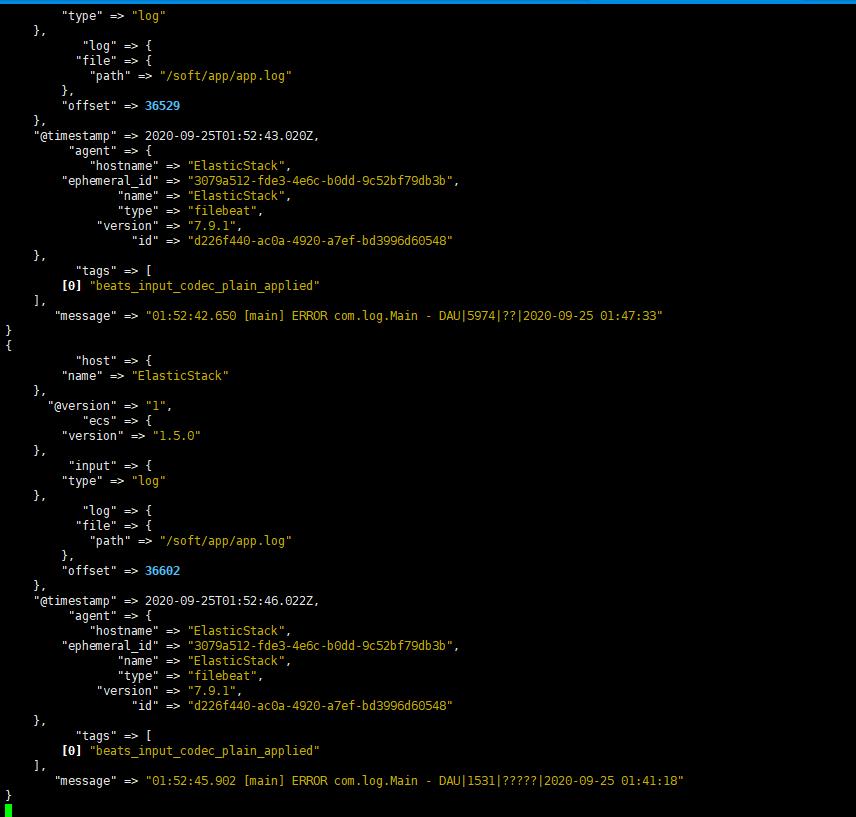
3.4.2 配置Logstash连接ElasticSearch
上面的数据,其实还是我们的原始数据,并没有经过处理,所以我们这个时候就需要使用到Logstash的其它功能了。我们继续修改配置文件
# 打开配置文件
vim mogu-dashboard.conf
然后修改一下的值
input {
beats {
port => "5044"
}
}
filter {
mutate {
split => {"message"=>"|"}
}
mutate {
add_field => {
"userId" => "%{[message][1]}"
"visit" => "%{[message][2]}"
"date" => "%{[message][3]}"
}
}
mutate {
convert => {
"userId" => "integer"
"visit" => "string"
"date" => "string"
}
}
mutate {
remove_field => [ "host" ]
}
}
#output {
# stdout { codec => rubydebug }
#}
output {
elasticsearch {
hosts => [ "127.0.0.1:9200"]
}
}
然后再次启动
./bin/logstash -f mogu-dashboard.conf
其实能够看到,我们原来的数据,就经过了处理了,产生了新的字段

同时我们还可以对我们的数据,进行类型转换,为了方便我们的下游进行处理
mutate {
convert => {
"userId" => "integer"
"visit" => "string"
"date" => "string"
}
}
4 Kibana分析业务
4.1 启动Kibana
我们最后就需要通过Kibana来展示我们的图形化数据
#启动
./bin/kibana
#通过浏览器进行访问
http://192.168.40.133:5601/app/kibana
4.1.1 添加到索引库
添加Logstash索引到Kibana中:
http://192.168.40.133:5601/app/kibana/indexPatterns/create
输入我们的匹配规则,然后匹配到logstash,然后选择时间字段后创建

4.1.2 创建柱形图
我们点击右侧Visualizations,然后开始创建图标
然后选择柱形图

在选择我们的索引
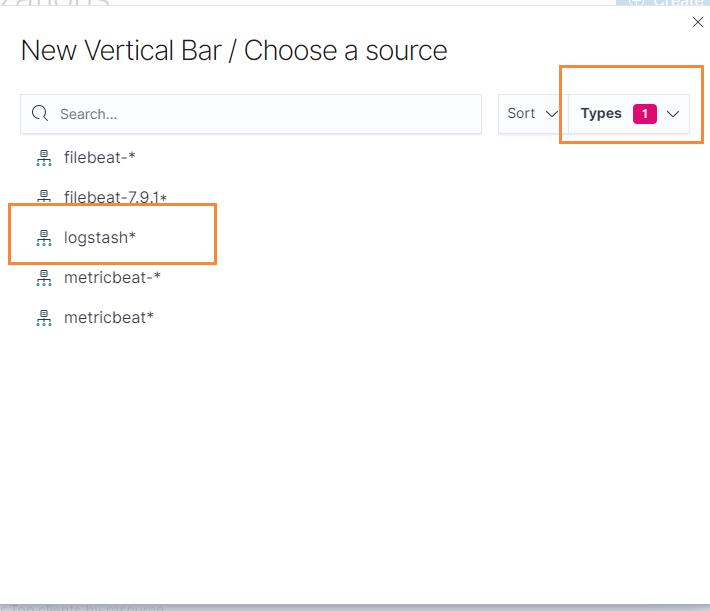
最后我们定义我们的X轴,选择按照时间进行添加

最后更新我们的页面,然后在选择最近的30分钟

就能够看到我们的日志在源源不断的生成了,同时我们可以对我们的这个图表进行保存

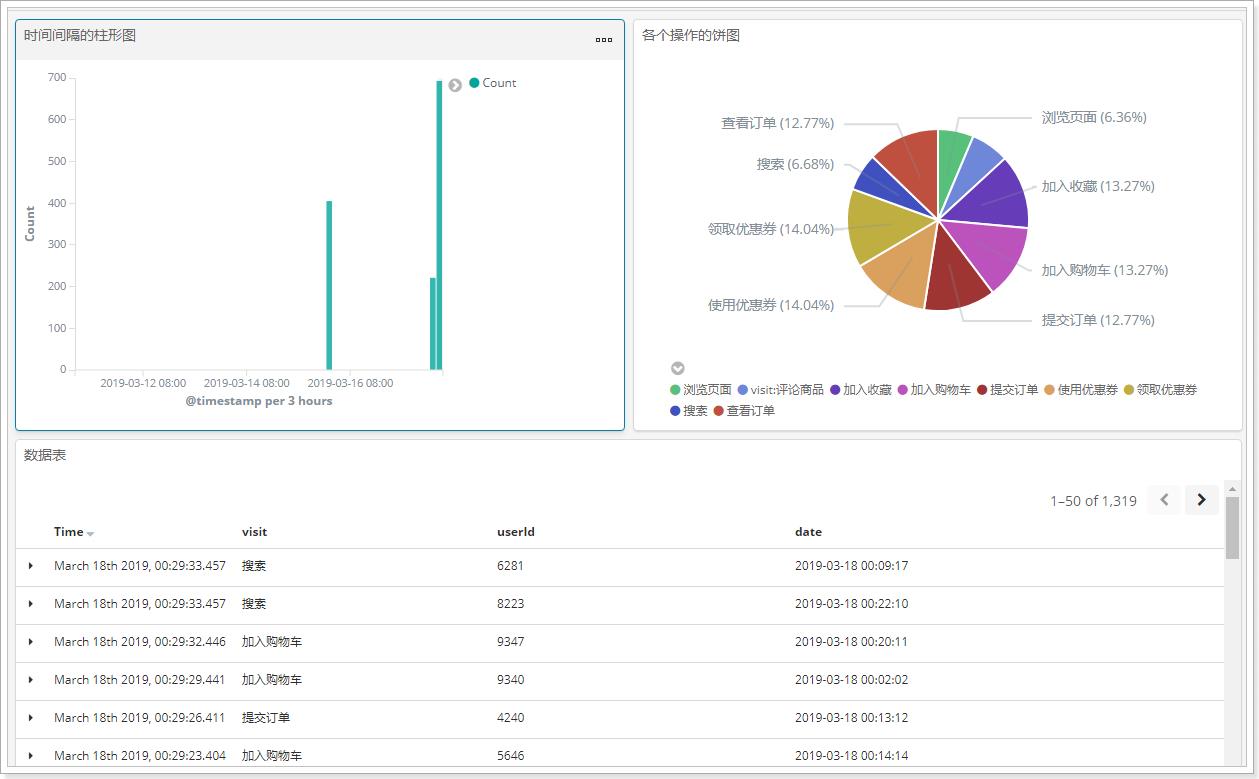
说明:x轴是时间,以天为单位,y轴是count数
保存:(my-dashboard-时间间隔的柱形图)

4.1.3 创建饼图

统计各个操作的数量,形成饼图。
保存:(my-dashboard-各个操作的饼图)

4.1.4 数据表格
在图标中,选择我们需要显示的字段即可

在数据探索中进行保存,并且保存,将各个操作的数据以表格的形式展现出来。
保存:(my-dashboard-表格)

4.2 制作Dashboard
以上是关于Filebeat日志采集器实例的主要内容,如果未能解决你的问题,请参考以下文章