Logstash快速入门
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Logstash快速入门相关的知识,希望对你有一定的参考价值。
目录
1 Logstash简介

Logstash是一个具有实时流水线功能的开源数据收集引擎.Logstash可以动态地统一来自不同来源的数据,并将数据规范化为您选择的目的地。为多样化的高级下游分析和可视化用例清理和民主化所有数据。
虽然Logstash最初推动了日志收集方面的创新,但它的功能远远超出了该用例。任何类型的事件都可以通过大量的输入、筛选和输出插件来丰富和转换,许多本机编解码器进一步简化了摄入过程。Logstash通过利用更大的数据量和更多的数据来加速您的洞察力。
1.1 参加资料
https://www.elastic.co/guide/en/logstash/current/index.html

1.2 用途
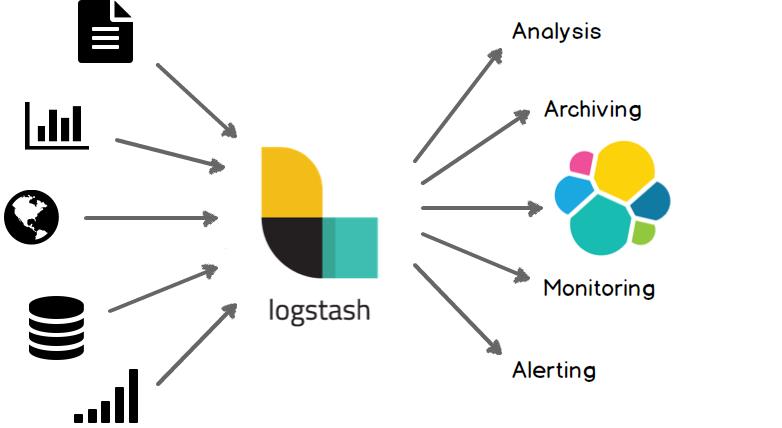
2 部署安装
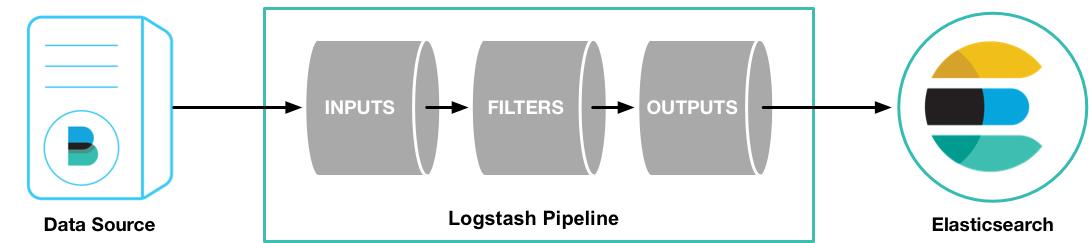
Logstash主要是将数据源的数据进行一行一行的处理,同时还直接过滤切割等功能。
首先到官网下载logstash:https://www.elastic.co/cn/downloads/logstash
选择我们需要下载的版本:
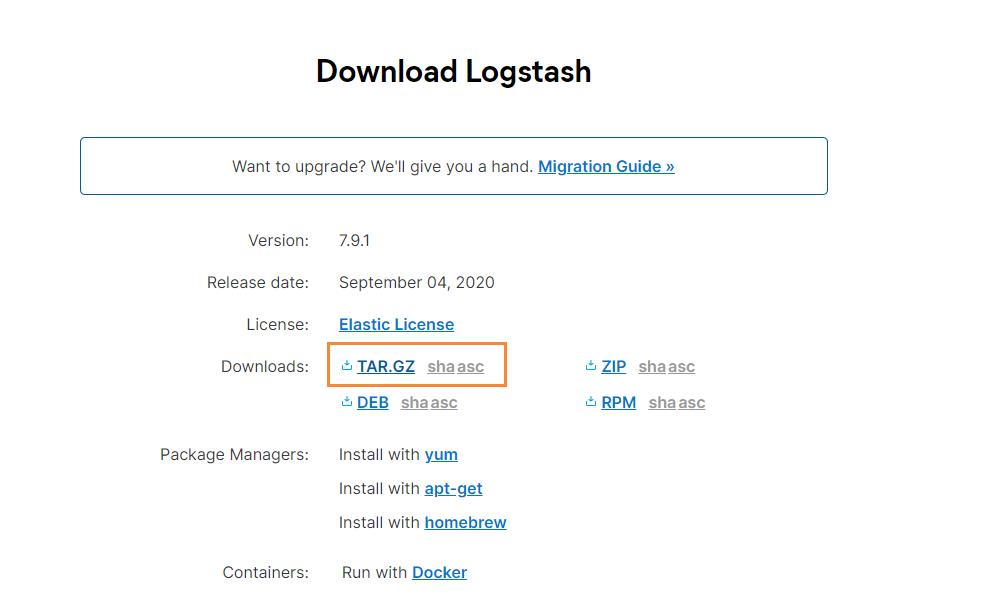
下载完成后,使用xftp工具,将其丢入到服务器中
#检查jdk环境,要求jdk1.8+
java -version
#解压安装包
tar -xvf logstash-7.9.1.tar.gz
#第一个logstash示例
bin/logstash -e 'input { stdin { } } output { stdout {} }'
其实原来的logstash的作用,就是为了做数据的采集,但是因为logstash的速度比较慢,所以后面使用beats来代替了Logstash,当我们使用上面的命令进行启动的时候,就可以发现了,因为logstash使用java写的,首先需要启动虚拟机,最后下图就是启动完成的截图

2.1 测试
我们在控制台输入 hello,马上就能看到它的输出信息

2.2 配置详解
Logstash的配置有三部分,如下所示
input { #输入
stdin { ... } #标准输入
}
filter { #过滤,对数据进行分割、截取等处理
...
}
output { #输出
stdout { ... } #标准输出
}
2.2.1 输入
- 采集各种样式、大小和来源的数据,数据往往以各种各样的形式,或分散或集中地存在于很多系统中。
- Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。

输入input{}配置文件详解:
在Logstash中可以在 input{} 里面添加file配置,默认的最小化配置如下:
input {
file {
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*"
}
}
filter {
}
output {
stdout {}
}
当然也可以监听多个目标文件:
input {
file {
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"]
}
}
filter {
}
output {
stdout {}
}
文件的路径名需要时绝对路径,并且支持globs写法。
其他的配置
另外,处理path这个必须的项外,file还提供了很多其他的属性:
input {
file {
#监听文件的路径
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"]
#排除不想监听的文件
exclude => "1.log"
#添加自定义的字段
add_field => {"test"=>"test"}
#增加标签
tags => "tag1"
#设置新事件的标志
delimiter => "\\n"
#设置多长时间扫描目录,发现新文件
discover_interval => 15
#设置多长时间检测文件是否修改
stat_interval => 1
#监听文件的起始位置,默认是end
start_position => beginning
#监听文件读取信息记录的位置
sincedb_path => "E:/software/logstash-1.5.4/logstash-1.5.4/test.txt"
#设置多长时间会写入读取的位置信息
sincedb_write_interval => 15
}
}
filter {
}
output {
stdout {}
}
其中值得注意的是:
1 path
是必须的选项,每一个file配置,都至少有一个path
2 exclude
是不想监听的文件,logstash会自动忽略该文件的监听。配置的规则与path类似,支持字符串或者数组,但是要求必须是绝对路径。
3 start_position
是监听的位置,默认是end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,这个配置也就失去作用了。
4 sincedb_path
这个选项配置了默认的读取文件信息记录在哪个文件中,默认是按照文件的inode等信息自动生成。其中记录了inode、主设备号、次设备号以及读取的位置。因此,如果一个文件仅仅是重命名,那么它的inode以及其他信息就不会改变,因此也不会重新读取文件的任何信息。类似的,如果复制了一个文件,就相当于创建了一个新的inode,如果监听的是一个目录,就会读取该文件的所有信息。
5 其他的关于扫描和检测的时间,按照默认的来就好了,如果频繁创建新的文件,想要快速监听,那么可以考虑缩短检测的时间。
6 add_field
就是增加一个字段,例如:
file {
add_field => {"test"=>"test"}
path => "D:/tools/logstash/path/to/groksample.log"
start_position => beginning
}
2.2.2 过滤
- 实时解析和转换数据
- 数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。

2.2.3 输出
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。

3 读取自定义日志
前面我们通过Filebeat读取了nginx的日志,如果是自定义结构的日志,就需要读取处理后才能使用,所以,这个时候就需要使用Logstash了,因为Logstash有着强大的处理能力,可以应对各种各样的场景。
3.1 日志结构
2019-03-15 21:21:21|ERROR|1 读取数据出错|参数:id=1002
可以看到,日志中的内容是使用“|”进行分割的,使用,我们在处理的时候,也需要对数据做分割处理。
3.2 编写配置文件
vim mogublog-pipeline.conf
然后添加如下内容
input {
file {
path => "/soft/beats/logs/app.log"
start_position => "beginning"
}
}
filter {
mutate {
split => {"message"=>"|"}
}
}
output {
stdout { codec => rubydebug }
}
启动
#启动
./bin/logstash -f ./mogublog-pipeline.conf
然后我们就插入我们的测试数据
echo "2019-03-15 21:21:21|ERROR|读取数据出错|参数:id=1002" >> app.log
然后我们就可以看到logstash就会捕获到刚刚我们插入的数据,同时我们的数据也被分割了
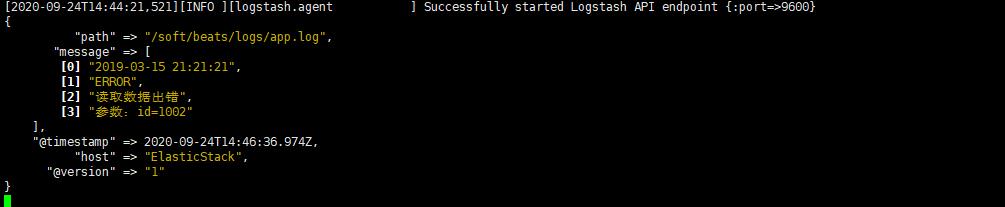
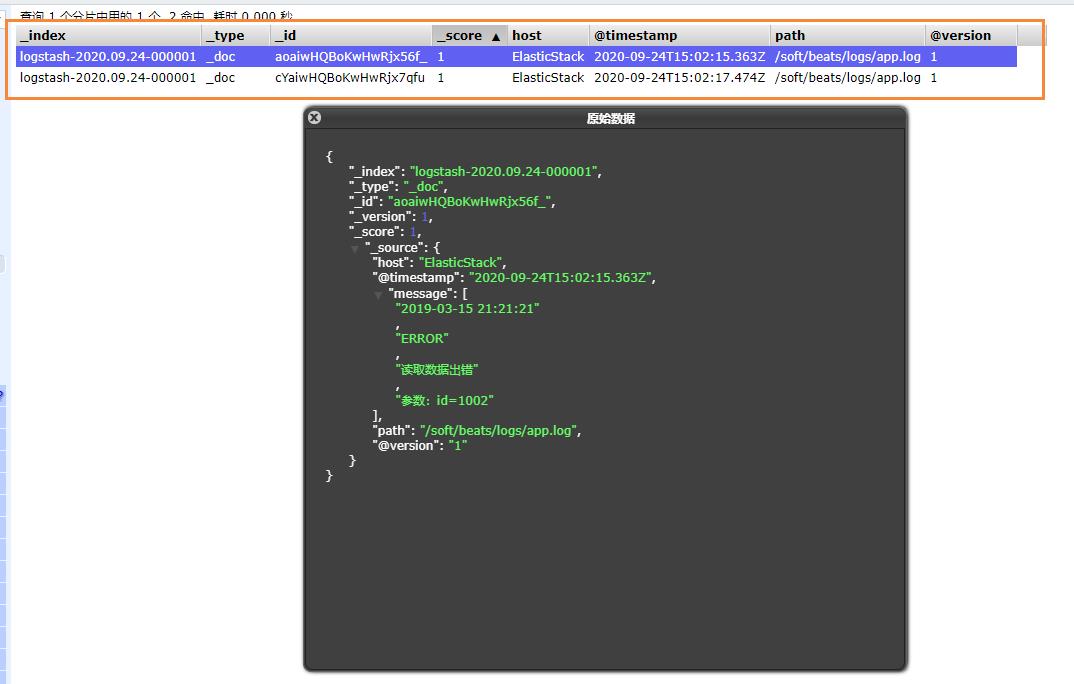
3.3 输出到Elasticsearch
我们可以修改我们的配置文件,将我们的日志记录输出到ElasticSearch中
input {
file {
path => "/soft/beats/logs/app.log"
start_position => "beginning"
}
}
filter {
mutate {
split => {"message"=>"|"}
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
}
}
然后在重启我们的logstash
./bin/logstash -f ./mogublog-pipeline.conf
然后向日志记录中,插入两条数据
echo "2019-03-15 21:21:21|ERROR|读取数据出错|参数:id=1002" >> app.log
echo "2019-03-15 21:21:21|ERROR|读取数据出错|参数:id=1002" >> app.log
最后就能够看到我们刚刚插入的数据了
以上是关于Logstash快速入门的主要内容,如果未能解决你的问题,请参考以下文章