恒源云_基于梯度的NLP对抗攻击方法
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云_基于梯度的NLP对抗攻击方法相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区(专注人工智能/深度学习云GPU服务器训练平台,官方体验网址:gpushare.com/ )
原文作者 | Mathor
前言:
Facebook提出了一种NLP通用的攻击方法,而且可以通过梯度优化,论文发表在EMNLP2021,名为Gradient-based Adversarial Attacks against Text Transformers,源码在facebookresearch/text-adversarial-attack
BACKGROUND
我们首先定义模型 h : X h:\\mathcal{X} h:X → Y →\\mathcal{Y} →Y,其中 X \\mathcal{X} X和 Y \\mathcal{Y} Y分别是输入输出集。设测试样本 x ∈ X x∈\\mathcal{X} x∈X被模型正确预测为标签 y y y,则有 y = h ( x ) ∈ Y y=h(x)∈\\mathcal{Y} y=h(x)∈Y。如果一个与 x x x无限接近的对抗样本 x ′ \\mathbf{x}^′ x′使得 h ( x ′ ) ≠ y h(\\mathbf{x}^{\\prime})\\neq y h(x′)=y,则 x ′ \\mathbf{x}^{\\prime} x′是一个好的对抗样本。我们可以通过定义函数 ρ : X × X → R ≥ 0 \\rho: \\mathcal{X}\\times \\mathcal{X} \\to \\mathbb{R}_{\\ge 0} ρ:X×X→R≥0 来量化 x \\mathbf{x} x和 x ′ \\mathbf{x}^{\\prime} x′的接近程度。设阈值 ϵ > 0 \\epsilon > 0 ϵ>0,如果 ρ ( x , x ′ ) ≤ ϵ \\rho (\\mathbf{x},\\mathbf{x}^{\\prime})\\leq \\epsilon ρ(x,x′)≤ϵ,则认为对抗样本 x ′ \\mathbf{x}^{\\prime} x′与样本 x \\mathbf{x} x非常接近
寻找对抗样本的过程通过被视为一个优化问题,例如对于分类问题来说,模型
h
h
h输出一个logits向量
ϕ
h
(
x
)
∈
R
K
\\phi_h(\\mathbf{x})\\in \\mathbb{R}^K
ϕh(x)∈RK,使得
y
=
arg
m
a
x
k
ϕ
h
(
x
)
k
y = \\arg max_{k}\\phi_h(\\mathbf{x})_k
y=argmaxkϕh(x)k ,为了使得模型预测错误,我们可以将margin loss选作对抗损失: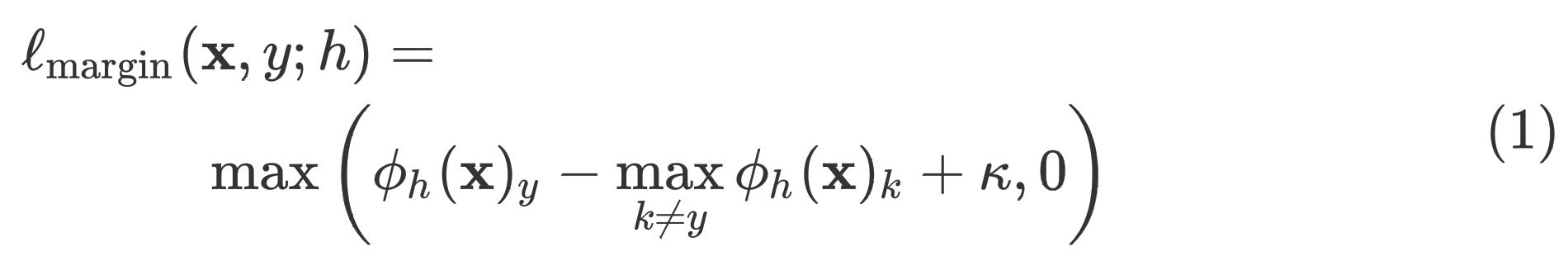
当损失为0的时候,模型会在超参数 κ \\kappa κ的控制下预测错误。margin loss在2017年的论文Towards evaluating the robustness of neural networks,关于图像对抗算法中就被证明过有效
这部分注释我想仔细解释下为什么margin loss可以使得模型分类错误。模型训练的最终目的是为了优化margin loss,使得它的损失值降为0,即
只要满足上式情况,损失值就为0了。通过变形我们可以得到
其中, ϕ h ( x ) y ϕ_h(\\mathbf{x})_y ϕh(x)y指的是输入 x \\mathbf{x} x被模型正确预测为类别 y y y的logit值。不妨设
并且 i ≠ y i\\neq y i=y,这表明在所有的错误类别中,第 i i i类的logit最大,并且结合上面的不等式可得
总结一下,我们的优化目标永远都是使得损失值降为0,但是损失降为0并不一定代表就要模型对所有的样本都正确预测,margin loss优化的目标就是使得模型预测错误类别 i i i的logit比预测正确类别 y y y的logit大 κ \\kappa κ。但凡存在一个样本预测正确,损失都不可能为0
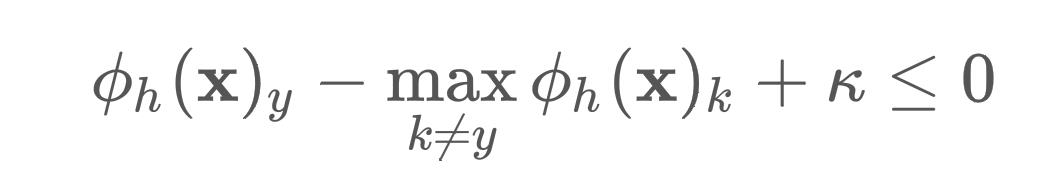
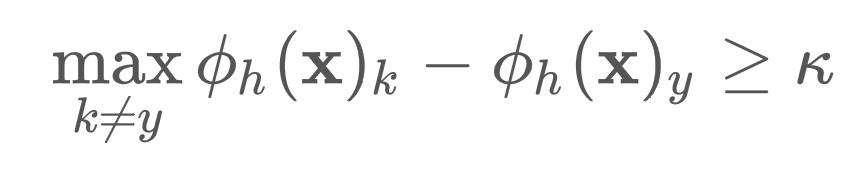


给定对抗损失
ℓ
\\ell
ℓ,构造对抗样本的过程可以被视为一个有限制的优化问题: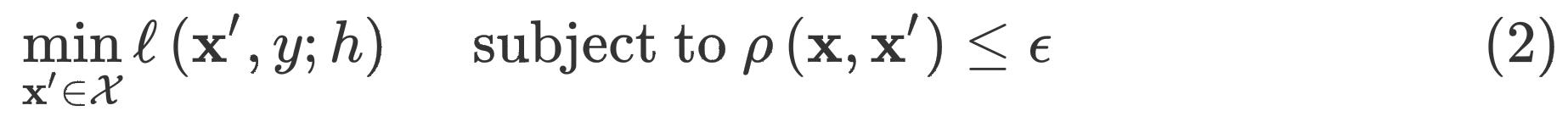
我们可以把约束
ρ
\\rho
ρ带入损失函数中,将原本的硬约束变为软约束
如果约束函数 ρ \\rho ρ是可微的,就可以用基于梯度的优化器来优化了
式(2)在图像或者语音等连续数据领域已被广泛应用,但实际上它并不适用于文本数据,主要有两点原因:
- 数据空间 X \\mathcal{X} X是离散的,因此无法利用梯度进行优化
- 约束函数 ρ \\rho ρ难以度量文本数据,例如在一个句子中插入"不是",这个词会否定整个句子的意义,但如果我们用编辑距离去计算两个句子的差异,它们的编辑距离仅为1
GBDA: GRADIENT-BASED DISTRIBUTIONAL ATTACK
论文作者所提出的方法解决了上面两个问题:
- 利用**Gumbel-Softmax**使得采样过程可以被梯度优化
- 通过引入困惑度和语义相似度这两个软约束,促使对抗样本的语义更加流畅以及与原样本间的语义更接近
Adversarial Distribution
令
z
=
z
1
z
2
⋯
z
n
\\mathbf{z} = z_1z_2\\cdots z_n
z=z1z2⋯zn是句子
z
\\mathbf{z}
z的token序列,其中
z
i
z_i
zi 来自于一个固定的词汇表
V
=
1
,
…
,
V
\\mathcal{V} = {1,…,V}
V=1,…,V。设概率分布
P
Θ
P_{\\Theta}
PΘ来自于一个参数化的概率矩阵
Θ
∈
R
n
×
V
\\Theta \\in \\mathbb{R}^{n\\times V}
Θ∈Rn×V,句子
z
∼
P
Θ
z∼P Θ
z∼PΘ中的每个token都是通过下面的公式独立抽样出来的
其中, π i = Softmax ( Θ i ) \\pi_i = \\text{Softmax}(\\Theta_i) πi=Softmax(Θi)表示第 i i i个token概率分布的向量
我们的目标是优化参数矩阵
Θ
\\Theta
Θ,使得
z
∼
P
Θ
\\mathbf{z}\\sim P_{\\Theta}
z∼PΘ 为模型
h
h
h的对抗样本,为了做到这一点,我们需要优化的目标函数为
其中, ℓ \\ell ℓ为可选的对抗损失,例如margin loss
Extension to probability vector inputs
公式(5)很明显不是一个可导的函数,因为分布是离散的,并且我们是通过采样得到的,采样这个操作没有公式,也就无法求导。但是,我们可以对公式(5)进行缩放,将概率向量作为输入,并且使用Gumbel-Softamx作为
arg
max
\\arg \\max
argmax的估计值,以此来引入梯度
句子
z
\\mathbf{z}
z中每个token
z
i
z_i
zi 在Vocabulary中的索引
i
i
i可以通过Word Embedding表查到相应的词向量。特别地,我们定义
e
(
⋅
)
\\mathbf{e}(\\cdot)
e(⋅)为embedding函数,因此token
z
i
z_i
zi 的embedding为
e
(
z
i
)
∈
R
d
e
\\mathbf{e}(z_i)\\in \\mathbb{R}^de
e(zi)∈Rde,其中
d
d
d是embedding维度。给定一个概率向量
π
i
\\pi_i
πi ,它决定了token
z
i
z_i
zi 的抽样概率,则我们定义
为对应于概率向量
π
i
\\pi_i
πi的嵌入向量。特别地,如果token
z
i
z_i
zi的概率向量
π
i
\\pi_i
πi是一个one-hot向量,则
e
(
π
i
)
=
e
(
z
i
)
\\mathbf{e}(\\pi_i)=\\mathbf{e}(z_i)
e(πi)=e(zi)。有了公式(6),我们可以将输入概率向量序列
π
=
π
1
⋯
π
n
\\boldsymbol{\\pi} = \\pi_1\\cdots \\pi_n
π=π1⋯π< 以上是关于恒源云_基于梯度的NLP对抗攻击方法的主要内容,如果未能解决你的问题,请参考以下文章 华为开源自研AI框架昇思MindSpore应用实践:FGSM网络对抗攻击