大数据架构设计与数据计算流程
Posted 李景琰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据架构设计与数据计算流程相关的知识,希望对你有一定的参考价值。
大数据架构设计

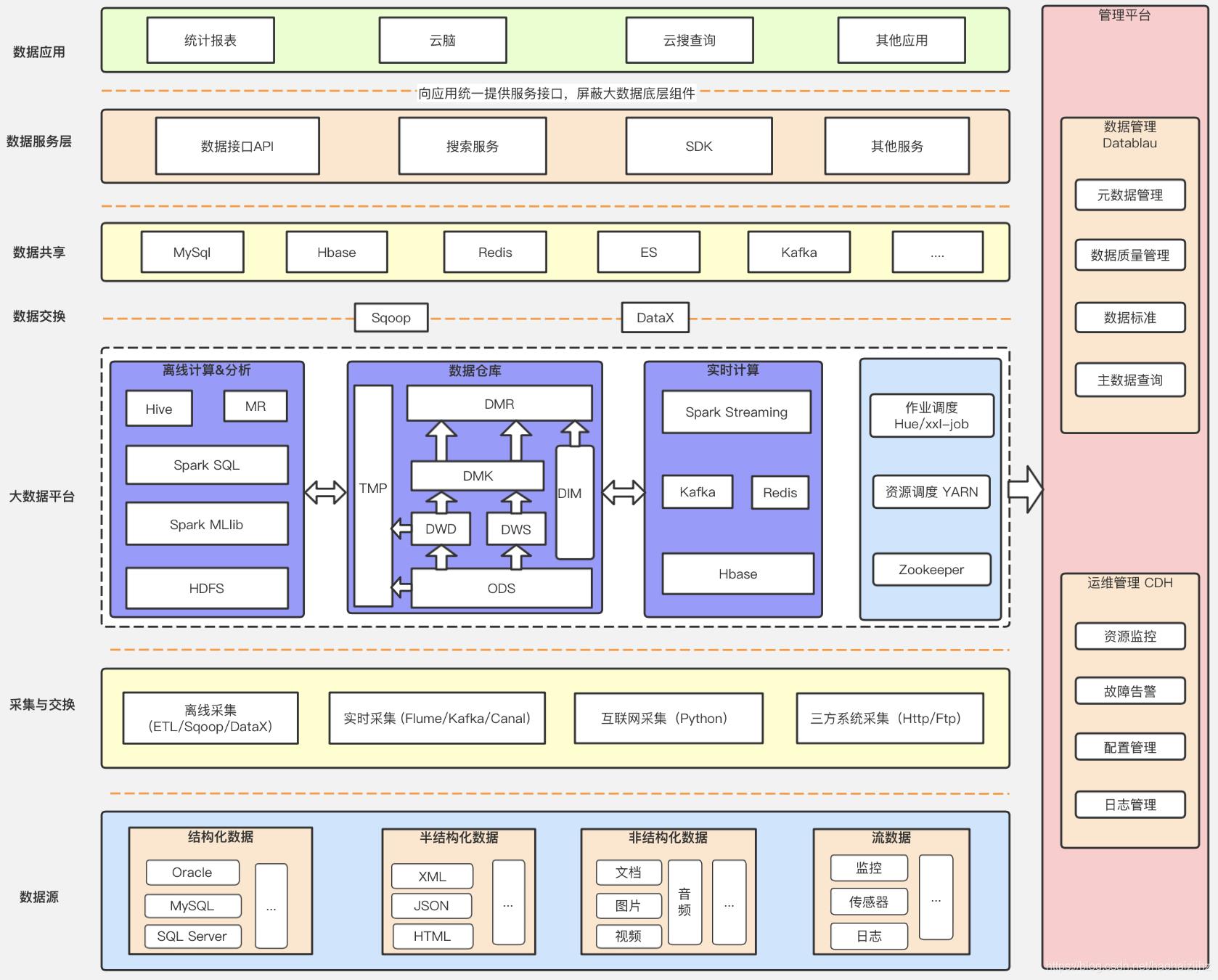
Hadoop有3个核心组件:分布式文件系统HDFS;分布式运算编程框架MapReduce;分布式资源调度平台YARN。
HBase,Hadoop dataBase,基于HDFS的NoSQL数据库,面向列式的内存存储,定期将内存数据刷新到磁盘(刷盘)。使用LSM树结构存储结构。不支持SQL、没有表关系、无法join操作,不支持事务(仅支持行级事务)、不支持回滚。mysql4张表在HBase对应1个表、4个列。

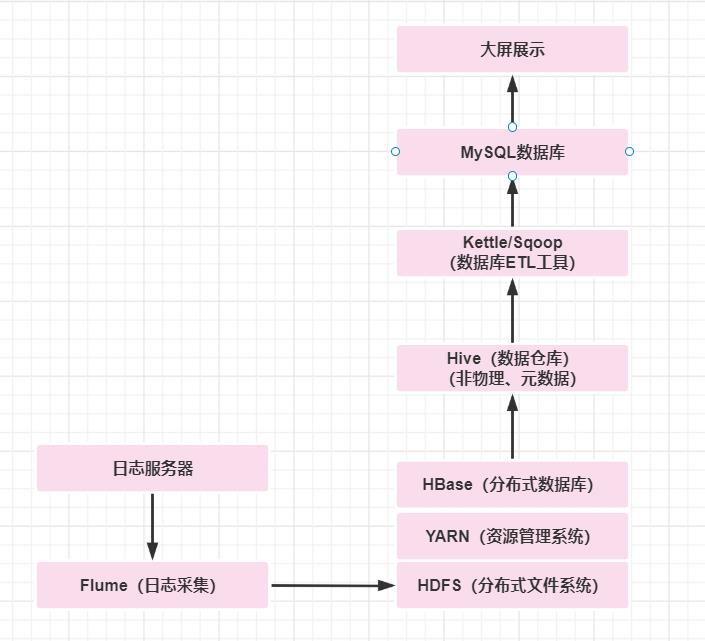
离线计算数据流程
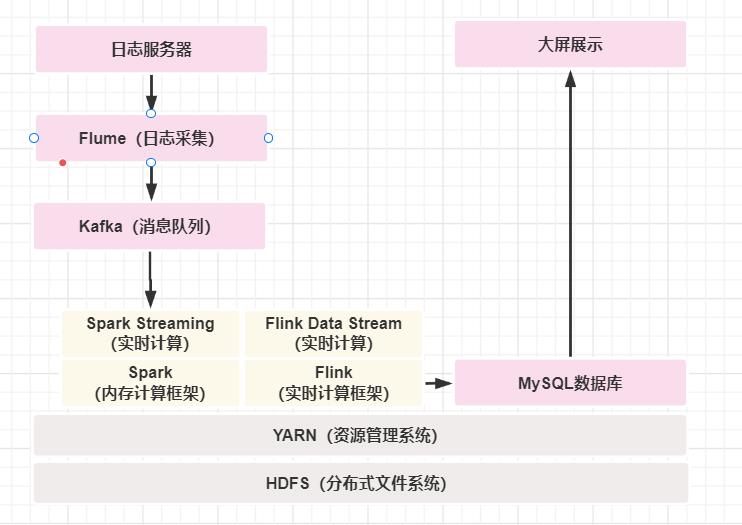
实时计算数据流程
专业术语
OLTP,联机事务处理,Online Transaction Processing。
OLAP,联机实时分析,Online Analytical Processing。
HTAP,混合事务和分析处理,Hybrid Transaction & Analytical Processing。
MPP,大规模并行处理,Massively Parallel Processing。
数据仓库与分层
ODS 数据接入层:所有的数据首先接入ODS层,数据复杂多样,粒度最粗。
DIM 维表层:根据维度及其属性将数据平台上构建的物理化的表,采用宽表设计的原则。
DWD 数据仓库层:经过ODS清洗、处理后的一致性、准确的、干净的数据。
DWS 数据集市层:该层数据是面向主题来组织的轻度汇总级的数据。
DWT 数据应用层: 为了满足具体的分析需求而构建的高度汇总的数据。
ADS 层:为各种报表提供数据。
大数据组件
存储框架
HBase、TiDB、ClickHouse、InfluxDB(时序数据库)、GraphQL、Elasticsearch、Apache Doris等。
数据同步转换组件
Sqoop、canal、DataX、maxwell、Debezium、Flink-CDC、Kettle、StreamSets。
离线批量计算分析引擎
MapReduce、Yarn、Hive、Spark。(Hive无物理存储功能、逻辑表,定义元数据)
实时流式计算引擎
Flink、Storm、Spark Streaming。
存储层
HDFS、Apache Ozone、S3、OSS、Ceph、GlusterFS。
数据湖
Apache Hudi、Apache Iceberg、Delta Lake。
任务调度工具
Azkaban、Airflow、Oozie、Dolphin、Scheduler。
ETL数据抽取工具
Kettle、StreamSets、Apache NiFi、Airbyte。
Hodoop集群管理工具、大数据运维
Ambari、CDH(Cloudera版本)、HDP(Hortonwork版)、CDP(Cloudera和Hortonwork合并版本,收费)、USDP(国产UCloud版)、CRH(基于Apache Ambari+Apache BigTop)、TDH(星环收费闭源)。
以上是关于大数据架构设计与数据计算流程的主要内容,如果未能解决你的问题,请参考以下文章