凛冬已至,雪花算法会了吗?
Posted 一条coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了凛冬已至,雪花算法会了吗?相关的知识,希望对你有一定的参考价值。
15张学习路线导图
10G学习资料
100本计算机书籍
点赞再看,养成习惯。微信搜索【一条coding】关注这个在互联网摸爬滚打的程序员。
本文收录于技术专家修炼,里面有我的学习路线、系列文章、面试题库、自学资料、电子书等。欢迎star⭐️
哈喽,大家好,我是一条~
算下来,已有半月之久没写文章,都是在吃老本,再不写估计就要废了,下班回来告诉自己就算通宵也要把这篇写完。
早上出门看着路边的积雪,不禁感到凛冬已至,咦!好熟悉,这不是王昭君的台词吗。

那索性今天就和大家聊聊雪花算法,一局王者复活的时间就能学会。(死的次数有点多)
本文大纲
分布式ID
聊之前先说一下什么是分布式ID,抛砖引玉。
假设现在有一个订单系统被部署在了A、B两个节点上,那么如何在这两个节点上各自生成订单ID,且ID值不能重复呢?
即在分布式系统中,如何在各个不同的服务器上产生唯一的ID值?
通常有以下三种方案:
- 利用数据库的自增特性,不同节点直接使用相同数据库的自增ID
- 使用UUID算法产生ID值
- 使用雪花算法产生ID值
虽然Java提供了对UUID的支持,使用UUID.randomUUID()即可,但是由于UUID是一串随机的36位字符串,由32个数字和字母混合的字符串和4个“-”组成,长度过长且业务可读性差,无法有序递增,所以一般不用,更多使用的是雪花算法。
由来
为什么叫雪花算法?
雪花算法的由来有两种说法:
- 第一种:Twitter使用scala语言开源了一种分布式 id 生成算法——SnowFlake算法,被翻译成了雪花算法。
- 第二种:因为自然界中并不存在两片完全一样的雪花的,每一片雪花都拥有自己漂亮独特的形状、独一无二。雪花算法也表示生成的ID如雪花般独一无二。(有同学问为什么不是树叶,美团的叫树叶——Leaf)
组成
雪花算法生成的ID到底长啥样?
雪花算法生成的ID是一个64 bit的long型的数字且按时间趋势递增。大致由首位无效符、时间戳差值、机器编码,序列号四部分组成。

如图:
- 首位无效符:第一个 bit 作为符号位,因为我们生成的都是正数,所以第一个 bit 统一都是 0。
- 时间戳:占用 41 bit ,精确到毫秒。41位最好可以表示
2^41-1毫秒,转化成单位年为 69 年。 - 机器编码:占用10bit,其中高位 5 bit 是数据中心 ID,低位 5 bit 是工作节点 ID,最多可以容纳 1024 个节点。
- 序列号:占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生 4096 个ID。
代码
Twitter官方给出的算法实现是用Scala写的,本文用Java实现。
SnowFlake.java
/**
* 雪花算法类
* 一条coding
*/
public class SnowFlake {
//本例将10位机器码看成是“5位datacenterId+5位workerId”
private long workerId;
private long datacenterId;
//每毫秒生产的序列号之从0开始递增;
private long sequence = 0L;
/*
1288834974657L是1970-01-01 00:00:00到2010年11月04日01:42:54所经过的毫秒数;
因为现在二十一世纪的某一时刻减去1288834974657L的值,正好在2^41内。
因此1288834974657L实际上就是为了让时间戳正好在2^41内而凑出来的。
简言之,1288834974657L(即1970-01-01 00:00:00),就是在计算时间戳时用到的“起始时间”。
*/
private long twepoch = 1288834974657L;
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
private long maxWorkerId = -1L ^ (-1L <<workerIdBits);
private long maxDatacenterId = -1L ^ (-1L <<datacenterIdBits);
private long sequenceBits = 12L;
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L <<sequenceBits);
private long lastTimestamp = -1L;
public SnowFlake(long datacenterId, long workerId) {
if ((datacenterId >maxDatacenterId || datacenterId <0)
||(workerId >maxWorkerId || workerId <0)) {
throw new IllegalArgumentException("datacenterId/workerId值非法");
}
this.datacenterId = datacenterId;
this.workerId = workerId;
}
//通过SnowFlake生成id的核心算法
public synchronized long nextId() {
//获取计算id时刻的时间戳
long timestamp = System.currentTimeMillis();
if (timestamp <lastTimestamp) {
throw new RuntimeException("时间戳值非法");
}
//如果此次生成id的时间戳,与上次的时间戳相同,就通过机器码和序列号区
//分id值(机器码已通过构造方法传入)
if (lastTimestamp == timestamp) {
/*
下一条语句的作用是:通过位运算保证sequence不会超出序列号所能容纳的最大值。
例如,本程序产生的12位sequence值依次是:1、2、3、4、...、4094、4095
(4095是2的12次方的最大值,也是本sequence的最大值)
那么此时如果再增加一个sequence值(即sequence + 1),下条语句就会
使sequence恢复到0。
即如果sequence==0,就表示sequence已满。
*/
sequence = (sequence + 1) &sequenceMask;
//如果sequence已满,就无法再通过sequence区分id值;因此需要切换到
//下一个时间戳重新计算。
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
//如果此次生成id的时间戳,与上次的时间戳不同,就已经可以根据时间戳区分id值
sequence = 0L;
}
//更新最近一次生成id的时间戳
lastTimestamp = timestamp;
/*
假设此刻的值是(二进制表示):
41位时间戳的值是:00101011110101011101011101010101111101011
5位datacenterId(机器码的前5位)的值是:01101
5位workerId(机器码的后5位)的值是:11001
sequence的值是:01001
那么最终生成的id值,就需要:
1.将41位时间戳左移动22位(即移动到snowflake值中时间戳应该出现的位置);
2.将5位datacenterId向左移动17位,并将5位workerId向左移动12位
(即移动到snowflake值中机器码应该出现的位置);
3.sequence本来就在最低位,因此不需要移动。
以下<<和|运算,实际就是将时间戳、机器码和序列号移动到snowflake中相应的位置。
*/
return ((timestamp - twepoch) <<timestampLeftShift)
| (datacenterId <<datacenterIdShift) | (workerId <<workerIdShift)
| sequence;
}
protected long tilNextMillis(long lastTimestamp) {
long timestamp = System.currentTimeMillis();
/*
如果当前时刻的时间戳<=上一次生成id的时间戳,就重新生成当前时间。
即确保当前时刻的时间戳,与上一次的时间戳不会重复。
*/
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis();
}
return timestamp;
}
}
TestSnowFlake.java
/**
* 测试类
* 一条coding
*/
public class TestSnowFlake {
//测试1秒能够生成的id个数
public static void generateIdsInOneSecond() {
SnowFlake idWorker = new SnowFlake(1, 1);
long start = System.currentTimeMillis();
int i = 0;
for (; System.currentTimeMillis() - start <1000; i++) {
idWorker.nextId();
}
long end = System.currentTimeMillis();
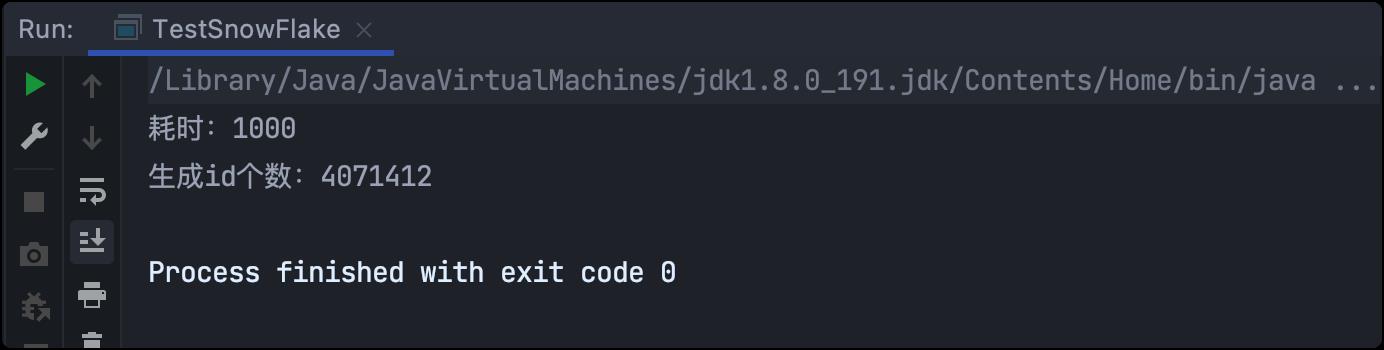
System.out.println("耗时:"+ (end - start));
System.out.println("生成id个数:"+ i);
}
public static void main(String[] args) {
generateIdsInOneSecond();
}
}
测试结果
疑问
雪花算法有缺点吗?
- 雪花算法生成ID一定是唯一的吗?
- 机器码最多可以容纳 1024 个节点,超过 1024 怎么办?
- 数据库的自增ID为什么不用雪花算法?
不要慌,下期和大家聊聊这些问题。
以上是关于凛冬已至,雪花算法会了吗?的主要内容,如果未能解决你的问题,请参考以下文章