Hadoop部署—— (在第一个克隆机上)安装JKD安装Hadoop
Posted 玛丽莲茼蒿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop部署—— (在第一个克隆机上)安装JKD安装Hadoop相关的知识,希望对你有一定的参考价值。
一、准备
将jdk和hadoop的压缩包下载好了以后,用pscp上传到/home/opt目录下面

二、JDK安装
我之前下载过JDK(在这一篇博文),但是JDK的版本跟教程中带的不一样。我先用着之前的那个,如果有版本不匹配的问题再回来改
三、Hadoop安装
1、解压
cd来到压缩包所在的目录,然后用下面的命令
[root@hadoop102 opt]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module
2、添加环境变量
在(在这一篇博文)中,我们直接在/etc/profile这个文件后面加了3个环境变量。这里采用第二种方法。
1)进入/etc/profile.d目录,创建新文件my_env.sh
vim my_env.sh
加入下面3个新环境变量
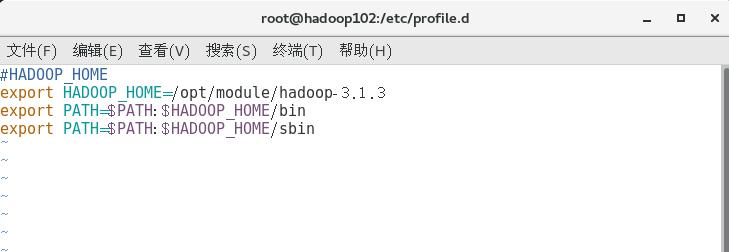
2)source一下才能用
[root@hadoop102 profile.d]# source /etc/profile
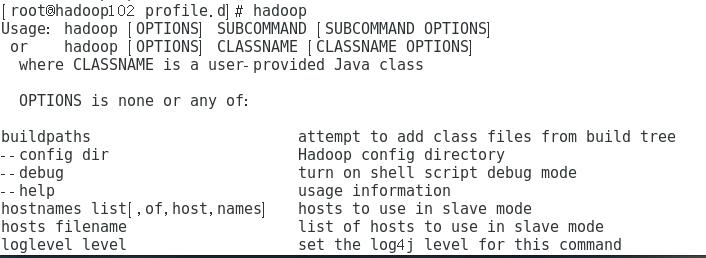
3)输入Hadoop命令看一看成功没有
[root@hadoop102 profile.d]# Hadoop
三、Hadoop下各个文件夹介绍
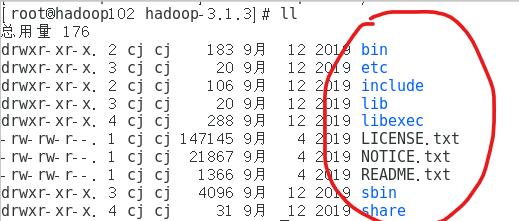
bin目录:存放以后用的命令。常用hdfs、yarn、mapred(MapReduce)
etc目录:配置文件。常用的如下
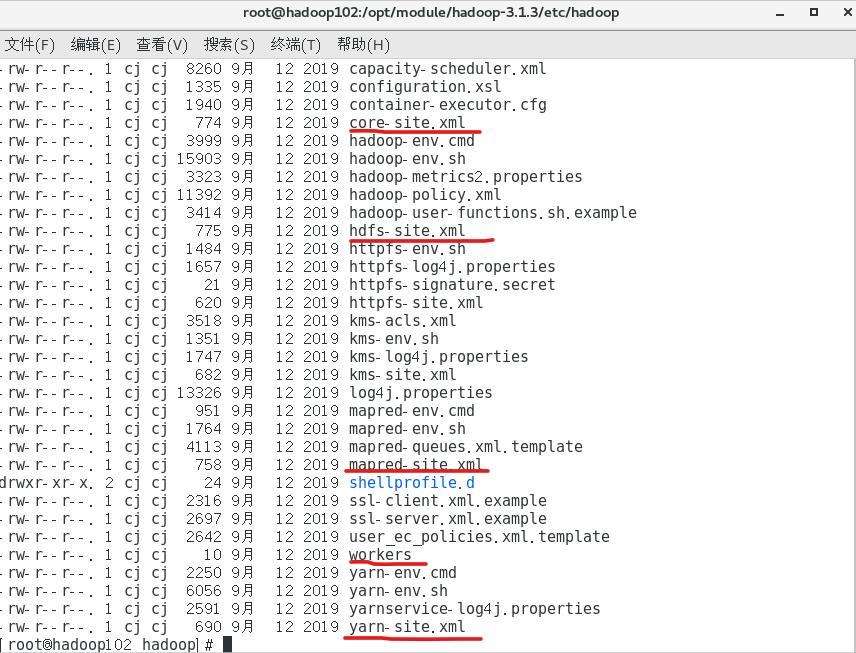
include目录:存放头文件。以后用不到
lib目录:本地动态链接库。以后一般用不到。
sbin目录:命令。常用的比如start-yarn.sh用来启动yarn
share目录:学习资料。案例。
以上是关于Hadoop部署—— (在第一个克隆机上)安装JKD安装Hadoop的主要内容,如果未能解决你的问题,请参考以下文章