论文笔记:Autoregressive Tensor Factorizationfor Spatio-temporal Predictions
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记:Autoregressive Tensor Factorizationfor Spatio-temporal Predictions相关的知识,希望对你有一定的参考价值。
0 摘要
张量因子tensor factorization分解方法在时空数据分析领域很受欢迎,因为它们能够处理多种类型的时空数据,处理缺失值,并提供计算效率高的参数估计程序。
然而,现有的张量因子分解方法并没有尝试学习空间自相关。这些方法使用先前推断的空间依赖性,通常导致插值和未知位置预测问题的性能较差。
本文提出了一种新的张量因子分解方法,通过同时学习空间和时间的自相关来估计低秩潜在因子。在现有空间自回归模型的基础上引入了新的空间自回归正则化方法,并给出了一种有效的估计方法。
1 introduction
在时空数据分析任务中时,数据的数量级、数量的类型、数据缺失值的处理,是目前主要研究的问题。
向量自回归模型(VAR)和高斯过程(GP)是对多元时间序列进行预测的常用方法。这些方法将线性或非线性的空间和时间相关性纳入预测。然而,当我们试图分析一个多元时间序列时,VAR和GP需要指数计算成本。因此,这些模型在分析大尺度时空数据时是不可行的。
大尺度时空数据分析的替代方法是矩阵/张量分解技术。

为了将空间和时间依赖性整合到分解中,大多数现有的分解方法都采用了基于图的正则化项[Collaborative filtering with graph information: Consistency and scalable methods, NIPS 2015],通过表示空间和时间结构的辅助图,使得隐藏层因子平滑化。
这些方法需要事先对加权时空图矩阵进行推理,但是对于如何构造加权时空图矩阵,几乎没有统一的准则。因此,这些方法的性能很大程度上依赖于权值和图结构的选择。此外,这些方法在出现负相关的情况下是不够的。
Yu等人[Temporal regularized matrix factorization for high-dimensional time series prediction NIPS 2016]最近提出了一种新的方法,称为时间正则化矩阵分解(TRMF),该方法在分解框架中引入了自回归正则化器。然而,他们没有考虑学习空间依赖性的问题。因此,我们能否对未知的位置进行精确的插值和预测仍然是个问题。
在本文中,我们解决了插值和预测未知位置的未来观测的问题。
为了解决这个问题,我们提出了一种新的张量分解方法,通过同时学习每个张量潜在因子的时空自相关,将张量分解为潜在因子。
我们在传统自回归模型的基础上引入了空间自回归正则化器。结合我们的空间自回归正则化器和时间自回归正则化器[11],我们可以预测未知位置的特征观测值。
此外,利用数据中所有观测值均为非负值的特性,我们可以从时空数据中提取出更稳健和可解释的潜在因子。
为了估计因子矩阵和系数的空间和时间自回归模型,我们展示了一个计算效率高的程序。
我们在三个公开的时空数据集上实验评估了我们提出的方法的预测性能,并证明了它如何显著提高插值和预测未知位置观测的预测精度。
2 Preliminary
2.1 张量分解
我们把,T个时间戳、M种数据源、P个位置观测到的时空数据表示为一个三向张量
X中被观测到的点被记为:
对于P、T、M我们有:
、
、
。其中
K<<min(P,T,M)
一个最naive的张量分解式子为:

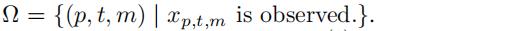


图拉普拉斯正则化被广泛应用于张量分解方法中,其分解具有空间和时间依赖性。表示第N个因子矩阵的加权邻接矩阵为
,则拉普拉斯矩阵为
于是图拉普拉斯正则项可以写成
虽然它在时空分析中显示出有用,但是邻接矩阵权值的构造依赖于用户的选择


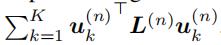
2.2 2D-AR
为了考虑图像分析中的空间自相关性,在计算机视觉领域提出了二维自回归模型(2D-AR)。
我们定义一个L阶滞后集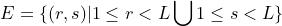 以及权重集合
以及权重集合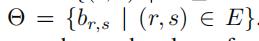
2D-AR是希望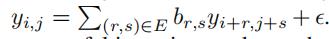
2D-AR模型在许多任务中都取得了成功,比如估计图像的观测值。然而,由于该方法是为计算机视觉设计的,所以它只适用于一组具有网格形状的位置。
3 提出的模型
3.1 自回归张量分解
损失函数为:
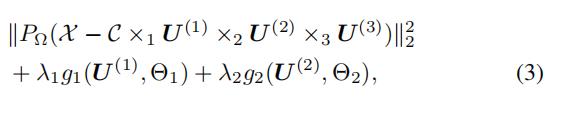
g1,g2分别是空间和时间自回归正则项,PΩ表示只考虑 observed entry
为了学习潜在因素的空间依赖性,我们提出了两种基于空间自回归模型的空间正则化器。这个公式的主要优点是,我们提出的方法不需要预先推断空间和时间的相关性。这种方法可以学习到适合每个潜在因素的个体依赖关系。
3.2 空间自回归模型
与前面2.2所提及的2D-AR模型假设不同,由于道路网络的拓扑条件或传感器的目的,传感器的位置并不总是处于网格形状。因此,该方法不适用于时空数据分析。
为了解决这些问题,我们提出了一种有向自回归(DAR)正则化方法.
我们的关键假设是,传感器观测值之间有一个基于方向的依赖关系,因此传感器的观测值可以由这些系数、基于距离的权重和其邻居的观测值的总和来近似。
我们在图2中说明了DAR的主要思想。我们将2π角分成N个离散方向,并定义每个方向的系数参数。

定义DAR模型的系数为
 ,点p最近的k个邻居为Ep,Ep中的点p'的权重值为
,点p最近的k个邻居为Ep,Ep中的点p'的权重值为 ,其中
,其中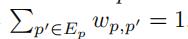
于是我们DAR的惩罚函数为:
np’表示了从p到p'的方向,归一化权值可以表示位置之间的逆距离
3.3 参数估计
我们通过将损失函数重写为约束极小化问题,提出了另一种极小化程序来实现我们所提出的方法的极小化

3.3.1 更新 θ1
从定义中,我们知道,和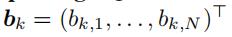 相关的损失函数是:
相关的损失函数是:
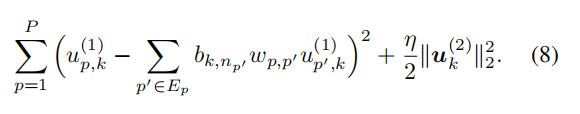
通过最小二乘法,我们有:、 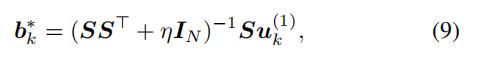
其中 矩阵 表示
表示

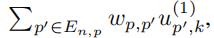
其中
3.3.2 更新 Θ2
线性代数笔记: Cholesky分解_UQI-LIUWJ的博客-CSDN博客
wl的参数估计问题等于求解岭回归问题[11],我们可以用Cholesky分解方法求解,其计算复杂度为
3.3.3 更新U(1) 【空间特征矩阵】
空间特征矩阵U(1)的损失函数为:
其中
,Gk就是Bk
由于这是一个凸极小值问题,我们交替地通过求解最小二乘问题来更新每个因子向量u(1) k:
这里
=

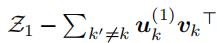
通过将损失函数的梯度设置为0,我们有:

其中
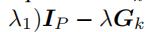
3.3.4 更新 U(2)
U(2)的更新可以写成

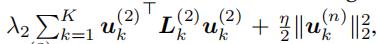
其中
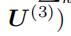
由于该问题属于一类图正则化交替最小二乘问题,因此我们可以利用共轭梯度下降算法得到最小值(时间复杂度  )
)
4 实验
4.1 城市交通需求预测实验
我们使用了纽约市出租车和豪华轿车委员会提供的出租车运输记录数据集和在纽约记录的自行车共享系统数据集。
对于出租车数据集,我们预测出租车在纽约不同位置下车的客户数量。由于该数据集中的记录由GPS位置组成,我们构建了面积为500m2的网格。
对于自行车共享系统数据集,我们预测将自行车归还给不同自行车站的客户数量。
出租车数据和自行车共享系统数据的观测地点分别为640个和344个。观测数据每30分钟收集一次。
我们在每个数据集中使用了两周的记录。
我们选取过去七天中的每一天作为测试日,并将测试日的前七天作为训练数据。
然后我们随机选取10%的位置作为未知的测试位置,其余位置作为已知的训练位置。
我们使用我们提出的方法:DAR正则化(DAR), DAR正则化与非负约束(DAR+NN)进行实验。我们将该方法与高斯过程(GP)、快速多元时空分析(fast)和时间正则化矩阵分解(TRMF)进行了比较。因为FAST不能对未知位置进行预测,所以我们首先对未知位置进行插值观测,然后进行预测。
对于我们提出的方法的空间正则化器DAR的系数W(1),我们采用k-NN,其权重设置为高斯相似测度
,其中rp是 第p个sensor的GPS位置,σ是加权系数(因为不同GPS位置之间的差距相对来说很小,我们设置σ为100)。然后我们对每一行进行归一化。
对于FAST和TRMF,我们使用了元素设置为高斯相似测度的全连通图拉普拉斯矩阵。
对于我们提出的DAR正则化方法,我们将角度划分的数量N设置为4或8,KNN的邻居数量为4或8。超参数λ1和λ2分别设为{0,0.1,1.0,10.0}。我们通过五倍交叉验证调整了超参数。
对于GP,我们使用5000个随机采样数据点进行训练,并通过最大似然估计程序优化超参数。
我们对GP、FAST、TRMF和张量微积分使用了公开可用的matlab代码。

在三种不同类型的预测任务中评估了每种方法的表现。在前人[11]工作的基础上,我们利用归一化偏差(ND)作为误差测量:
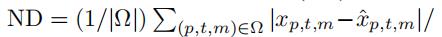
结果如表一、二所示。每个单元格的左右两边的值对应于在不同的测试天进行7次测试得到的ND的平均值和标准偏差。黑体数字表示所有方法中最小的平均误差。


从这些结果中,我们证实了我们提出的方法与DAR正则化器在预测整个数据集的特征观测和未知位置插值任务上优于其他方法。
同时加入DAR正则化和非负约束的方法在没有非负约束的情况下表现出了更好的性能,因为这种约束可以避免过拟合。
在纽约出租车数据和共享单车系统中,我们的DAR正则化器的改进率分别为42.9%和9.8%。该方法在第一个任务上的改进是由于减少了插值未知位置观测的预测误差,因为我们的方法可以利用空间自回归正则化器学习每个潜在因子的不同空间依赖性。
然而,现有的方法不能同时学习空间和时间依赖性。通过对共享单车系统数据集的实验,FAST在预测已知位置的未来观测任务上表现出了最好的性能。
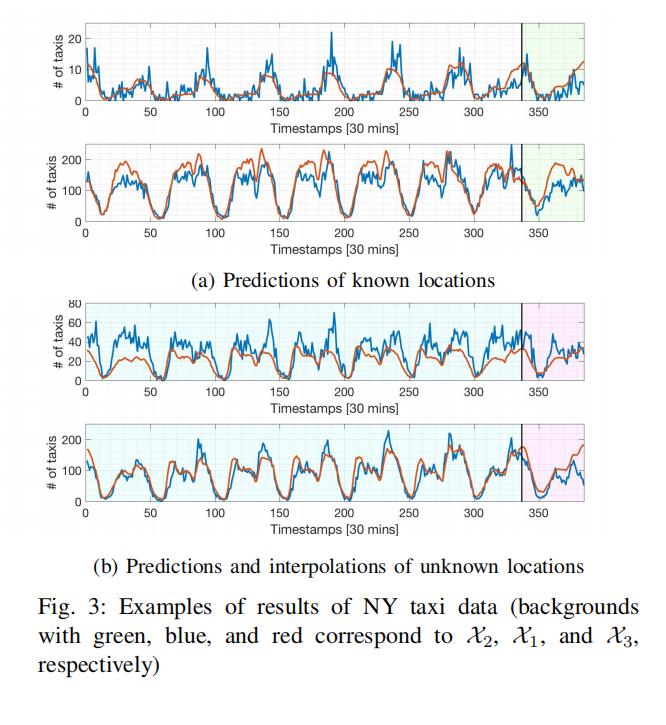
为了检验我们提出的方法的定性性能,我们用图3中的NY出租车数据集来说明DAR正则化器的估计预测。
红线和蓝线分别是预测值和地面真实值。 黑色实线表示训练期的结束。 黄色背景的红线是预测的结果。
从这张图中,我们证实了我们所提出的方法通过捕捉时间动态准确地预测了已知位置的观测结果。它对未知位置的预测也表现良好。这些结果支持了我们提出的DAR正则化器学习空间和时间依赖性的有效性。

在图4中,我们用纽约出租车数据来说明提取的时间和空间因素。
在这些图中,我们还展示了在没有非负约束的情况下提取的时间因素。
从图4a中,我们确认了在每个时间因子中提取了不同的动态特征,并且具有非负约束的空间因子比没有该约束的空间因子获得了光滑且易于解释的形状。
从蓝色的时间因子及其对应的空间因子4b,我们可以很容易地理解这个因子出现在每天下午和帝国大厦附近。
红色的时间因子和相应的空间因子4c表明,曼哈顿和布鲁克林的日常交通都发生在夜间。

以上是关于论文笔记:Autoregressive Tensor Factorizationfor Spatio-temporal Predictions的主要内容,如果未能解决你的问题,请参考以下文章