终于有人把各路StyleGAN做了个大汇总 | Reddit超热
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了终于有人把各路StyleGAN做了个大汇总 | Reddit超热相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
StyleGAN在各种图像处理和编辑任务上,表现很惊艳。
然而,“干一种活”就得换个体系重新“培训”一次,太麻烦。
终于,有人细细研究了一下,发现:
其实只通过预训练和潜空间上的一点小操作,就可以让StyleGAN直接上手各种“活儿”,包括全景图生成、从单张图像生成、特征插值、图像到图像翻译等等。

更厉害的是,它在这些“活儿”上的表现还完全不输每一位单项SOTA选手。
作者顺势做了个全面整理写成了一篇论文,相关讨论在reddit上直接收获了700+的热度:

网友纷纷感叹:这总结真的是太酷了!


All You Need:预训练+一点空间操作
方法都非常简单,我们一个一个来。
前提:fi∈RB×C×H×W表示StyleGAN第i层的中间特征(intermediate features)。
1、空间操作实现直观和逼真的图像
由于StyleGAN是全卷积的,我们可以调整fi的空间维度,从而在输出图像中引起相应的空间变化。
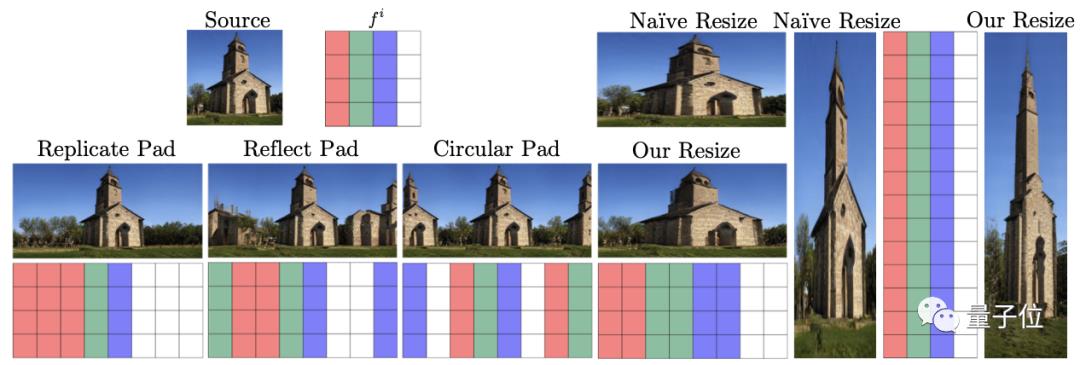
用简单的空间操作(如padding和resize),可以生成更直观和真实的图像。
比如下图通过复制灌木和树丛来扩展背景,与导致纹理模糊等瑕疵的原始resize相比,在特征空间中可以保持更真实的纹理。
2、特征插值
对StyleGAN中间层进行拼贴可以实现图像信息混合,但要拼接的两张图差异太大时效果往往不好。
但采用特征插值就没问题。
具体操作方法:在每个StyleGAN层,分别使用不同的潜噪声生成fAi和fBi。然后用下面这个公式将它俩进行平滑地混合,然后再传递到下一个卷积层进行同样的操作。
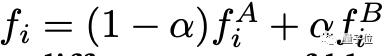
其中α∈ [0, 1]B×C×H×W是一个mask,如果用于水平混合,则mask将从左到右变大。
和对应模型的定性和定量比较:

该特征插值法能够无缝地混合两幅图像,而Suzuki等人的结果存在明显的伪影。
用户研究中,与Suzuki等人相比,87.6%的人也更喜欢该方法。
用户研究包含40人,每人需比较不同方法下的25对图像。
3、从单个图像生成
除了在不同图像之间进行特征插值,我们还可以在单个图像中应用它。
具体操作方法:在一些特征层中,选择相关的patches,并将其与其他区域混合,在空间上进行复制。使用移位运算符Shift(·):
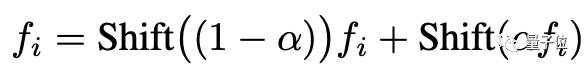
这和SinGAN的功能相同,不过SinGAN涉及采样,而该方法只需要手动选择用于特征插值的patches.
和SinGAN的定性和定量比较:

该方法生成的图像更加多样化和真实;SinGAN则未能以“有意义”的方式改变教堂结构,并产生不够真实的云彩和风景。
用户研究中,83.3%的人更喜欢该方法生成的新图像。
4、改进GAN反演
GAN反演的目的是在W+空间中定位一个样式码(style code),通过该样式码合成与给定目标图像相似的图像。
Wulff等人的模型认为,在简单的非线性变换下,W+空间可以用高斯分布建模。然而,在属性转移设置中,需要反转源图像和参考图像,效果并不令人满意。
最近的研究表明,与W+相比,利用σ进行面部操作的性能更好。
但作者发现,没有任何变换的σ空间也可以建模为高斯分布。
然后在这个空间而不是在GAN反转期间,施加相同的高斯先验。
效果比较:
该方法在图像重建和可编辑性方面获得了显著改进。

5、图像到图像翻译
得益于上部分σ空间的效果,作者建议在图像到图像翻译时freeze产生σ的仿射变换层(affine transformation layer),这一简单的变化能够更好地保留图像翻译的语义(注意下图d中嘴的形状)。
此外,作者发现:
(1)可以在所有空间维度上使用常数α来执行连续翻译;
(2)通过选择要执行特征插值的区域来执行局部图像翻译;
(3)以及使用改进的GAN反演在真实人脸上执行人脸编辑和翻译;
这样获得的效果也更佳。

6、全景生成
作者通过“编织”两幅图像的混合(span)生成全景图,方法如图所示:
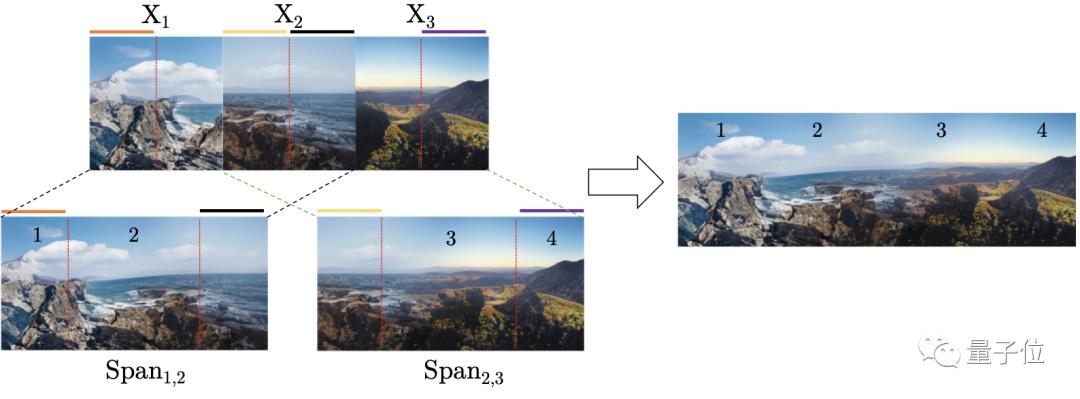
重复这个过程可以生成任意长度的全景图像。
而且该方法不仅限于一次混合两个图像、也不限于只在水平方向生成。
一些示例:

7、属性转移
为了使特征插值能够更好地用于任意人物姿势的图像的属性转移,作者选择在源图像和参考图像之间执行姿势对齐,具体就是对齐W+空间样式代码的前2048个维度。
然后就可以应用特征插值将所选特征进行源图到目标图的转移了。
与现有方法比较:

Collins等人的方法没有准确地转移细节属性,Suzuki等人在姿势不匹配时产生的图像不够真实。
而作者的方法既准确又真实。
用户根据真实感和准确性进行选择的结果也进一步验证了该方法的优越性。

ps. 此外还可以在任意区域执行转移,比如无缝融合两边眼睛明显不同的两半脸:

以上就是无需特定架构或训练范式、在StyleGAN模型潜空间中执行一些操作和微调,就能与其他图像处理任务达到同等或更佳性能的具体方法。
你觉得如何?还有什么需要补充的吗?欢迎在评论区留言。
论文地址:
https : //arxiv.org/abs/2111.01619
项目地址:
https://github.com/mchong6/SOAT
以上是关于终于有人把各路StyleGAN做了个大汇总 | Reddit超热的主要内容,如果未能解决你的问题,请参考以下文章