Dubbo3中服务端线程模型,线程处理(基于Dubbo3)
Posted Leo Han
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dubbo3中服务端线程模型,线程处理(基于Dubbo3)相关的知识,希望对你有一定的参考价值。
通过之前我们对Dubbo服务端启动流程的源码分析dubbo服务端启动源码分析(基于Dubbo 3),我们知道默认的Dubbo协议底层是基于Netty的,之前我们分析Netty相关线程模型的时候 Netty中线程处理 - NioEventLoopGroup,NioEventLoop
也了解到Netty是有自己的线程处理的,那么Dubbo中是怎么来处理业务上的需要和Netty线程模型的?
官网给出的线程模型图:
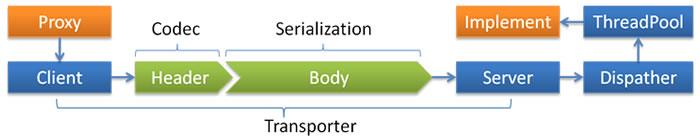
首先我们再次回顾下之前的分析,在生成NettyServer的时候:
public NettyServer(URL url, ChannelHandler handler) throws RemotingException {
super(ExecutorUtil.setThreadName(url, SERVER_THREAD_POOL_NAME), ChannelHandlers.wrap(handler, url));
}
这里有一个:
ChannelHandlers.wrap(handler, url)
我们看下其实现:
public static ChannelHandler wrap(ChannelHandler handler, URL url) {
return ChannelHandlers.getInstance().wrapInternal(handler, url);
}
return new MultiMessageHandler(new HeartbeatHandler(ExtensionLoader.getExtensionLoader(Dispatcher.class)
.getAdaptiveExtension().dispatch(handler, url)));
}
可以看到,这里会通过SPI机制去获取Dispatcher这个类的实现类,这个我们放在后面讲解,然后在启动NettyServer的方法doOpen:
protected void doOpen() throws Throwable {
bootstrap = new ServerBootstrap();
bossGroup = NettyEventLoopFactory.eventLoopGroup(1, "NettyServerBoss");
workerGroup = NettyEventLoopFactory.eventLoopGroup(
getUrl().getPositiveParameter(IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS),
"NettyServerWorker");
final NettyServerHandler nettyServerHandler = new NettyServerHandler(getUrl(), this);
channels = nettyServerHandler.getChannels();
boolean keepalive = getUrl().getParameter(KEEP_ALIVE_KEY, Boolean.FALSE);
bootstrap.group(bossGroup, workerGroup) .channel(NettyEventLoopFactory.serverSocketChannelClass())
.option(ChannelOption.SO_REUSEADDR, Boolean.TRUE)
.childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE)
.childOption(ChannelOption.SO_KEEPALIVE, keepalive)
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
int idleTimeout = UrlUtils.getIdleTimeout(getUrl());
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);
if (getUrl().getParameter(SSL_ENABLED_KEY, false)) {
ch.pipeline().addLast("negotiation",
SslHandlerInitializer.sslServerHandler(getUrl(), nettyServerHandler));
}
ch.pipeline()
.addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
.addLast("server-idle-handler", new IdleStateHandler(0, 0, idleTimeout, MILLISECONDS))
.addLast("handler", nettyServerHandler);
}
});
ChannelFuture channelFuture = bootstrap.bind(getBindAddress());
channelFuture.syncUninterruptibly();
channel = channelFuture.channel();
}
可以看到,这里在Netty的handler链上传入了一个NettyServerHandler类,而这个类汇总又传入了当前NettyServer作为一个ChannelHandler
public NettyServerHandler(URL url, ChannelHandler handler) {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
if (handler == null) {
throw new IllegalArgumentException("handler == null");
}
this.url = url;
this.handler = handler;
}
我们选取一个读取事件,看下是NettyServerHandler怎么处理的
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
handler.received(channel, msg);
}
可以看到,这里就是调用了传入的handler处理,也就是NettyServer,而NettyServer中则是在父类AbstractPeer实现received:
public void received(Channel ch, Object msg) throws RemotingException {
if (closed) {
return;
}
handler.received(ch, msg);
}
可以看到,这里又调用了AbstractPeer中的handler,而这个handler正是开头我们说的NettyServer中传入的ChannelHandlers.wrap(handler, url)这个ChannelHandler,而这个则是如下实现:
return new MultiMessageHandler(new HeartbeatHandler(ExtensionLoader.getExtensionLoader(Dispatcher.class)
.getAdaptiveExtension().dispatch(handler, url)));
}
最终是MultiMessageHandler 嵌套一个HeartbeatHandler,HeartbeatHandler在通过ExtensionLoader.getExtensionLoader(Dispatcher.class) .getAdaptiveExtension().dispatch(handler, url)嵌套一个handler,而这里ExtensionLoader.getExtensionLoader(Dispatcher.class)则对应多种实现:
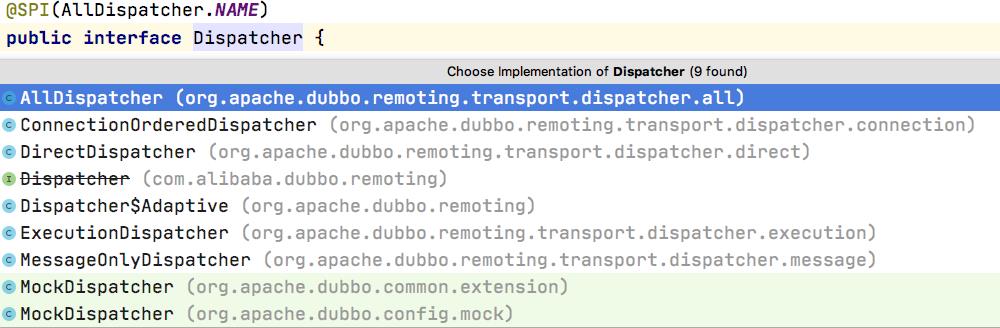
这里可以看到,默认就是all这个实现,对应的就是AllDispatcher,而其dispatch返回的则是AllChannelHandler,也就是说后续的调度都是给这个AllChannelHandler,继承自WrappedChannelHandler,WrappedChannelHandler中对 连接、断开、发送、接收这四个事件都是默认实现,都是通过Netty的worker线程去调度的
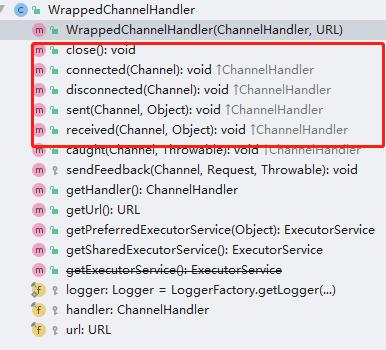
在AllChannelHandler中重写了下面这几个方法,都是单独自己通过线程调度,没在使用worker线程调度执行。
public void connected(Channel channel) ;
public void disconnected(Channel channel)
public void received(Channel channel, Object message)
我们主要看下消息读取这块是怎么处理的:
public void received(Channel channel, Object message) throws RemotingException {
ExecutorService executor = getPreferredExecutorService(message);
try {
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
if(message instanceof Request && t instanceof RejectedExecutionException){
sendFeedback(channel, (Request) message, t);
return;
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
可以看到,这里将到来的处理事件封装成一个ChannelEventRunnable,由线程池去调度,而这里的线程池仍然是通过Dubbo的SPI机制加载:
public ExecutorService getPreferredExecutorService(Object msg) {
if (msg instanceof Response) {
Response response = (Response) msg;
DefaultFuture responseFuture = DefaultFuture.getFuture(response.getId());
// a typical scenario is the response returned after timeout, the timeout response may has completed the future
if (responseFuture == null) {
return getSharedExecutorService();
} else {
ExecutorService executor = responseFuture.getExecutor();
if (executor == null || executor.isShutdown()) {
executor = getSharedExecutorService();
}
return executor;
}
} else {
return getSharedExecutorService();
}
}
public ExecutorService getSharedExecutorService() {
ExecutorRepository executorRepository =
ExtensionLoader.getExtensionLoader(ExecutorRepository.class).getDefaultExtension();
ExecutorService executor = executorRepository.getExecutor(url);
if (executor == null) {
executor = executorRepository.createExecutorIfAbsent(url);
}
return executor;
}
这里通过获取URL中的threadpool选项,来选择不同的线程池,默认是fixed,Dubbo对线程池抽象了一个ThreadPool对象,官网给出的线程池有如下选项:
fixed固定大小线程池,启动时建立线程,不关闭,一直持有。(缺省)cached缓存线程池,空闲一分钟自动删除,需要时重建。limited可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。eager优先创建Worker线程池。在任务数量大于corePoolSize但是小于maximumPoolSize时,优先创建Worker来处理任务。当任务数量大于maximumPoolSize时,将任务放入阻塞队列中。阻塞队列充满时抛出RejectedExecutionException。(相比于cached:cached在任务数量超过maximumPoolSize时直接抛出异常而不是将任务放入阻塞队列)

可以看到,这里正好对应了ThreadPool的几个实现,其中FixedThreadPool实现如下:
public class FixedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, DEFAULT_THREAD_NAME);
int threads = url.getParameter(THREADS_KEY, DEFAULT_THREADS);
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
最后返回了一个固定大小的ThreadPoolExecutor.
这样我们通过ThreadPool能够获取到一个Executor,然后来执行AllChannelHandler中生成的ChannelEventRunnable,而在ChannelEventRunnable的run实现如下:
public void run() {
if (state == ChannelState.RECEIVED) {
try {
handler.received(channel, message);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel
+ ", message is " + message, e);
}
} else {
switch (state) {
case CONNECTED:
try {
handler.connected(channel);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel, e);
}
break;
case DISCONNECTED:
try {
handler.disconnected(channel);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel, e);
}
break;
case SENT:
try {
handler.sent(channel, message);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel
+ ", message is " + message, e);
}
break;
case CAUGHT:
try {
handler.caught(channel, exception);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel
+ ", message is: " + message + ", exception is " + exception, e);
}
break;
default:
logger.warn("unknown state: " + state + ", message is " + message);
}
}
}
这里还是交由保护被包装的handler去处理,只不过这时不在由worker线程去处理了,worker线程到这里的任务就结束了,接下来就是由指定的线程池去执行了
我们再看下MessageOnlyDispatcher怎么处理的:
public ChannelHandler dispatch(ChannelHandler handler, URL url) {
return new MessageOnlyChannelHandler(handler, url);
}
与AllDispatcher一样,MessageOnlyDispatcher生成了一个MessageOnlyChannelHandler去进行调度,而MessageOnlyChannelHandler里面只重写了一个方法:
public void received(Channel channel, Object message) throws RemotingException {
ExecutorService executor = getPreferredExecutorService(message);
try {
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
if(message instanceof Request && t instanceof RejectedExecutionException){
sendFeedback(channel, (Request) message, t);
return;
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
可以看到,这里只对请求读取进行单独线程池调度处理,其他仍然交给Netty的worker线程调度。
其他的几个调度大家可以去看下。
结合官网介绍和上面的研究,Dubbo的调度Dispatcher总结如下:
- all 所有消息都派发到线程池,包括请求,响应,连接事件,断开事件,心跳等。
- direct 所有消息都不派发到线程池,全部在 IO 线程上直接执行。
- message 只有请求响应消息派发到线程池,其它连接断开事件,心跳等消息,直接在 IO 线程上执行。
- execution 只有请求消息派发到线程池,不含响应,响应和其它连接断开事件,心跳等消息,直接在 IO 线程上执行。
- connection 在 IO 线程上,将连接断开事件放入队列,有序逐个执行,其它消息派发到线程池。
线程池ThreadPool主要有如下选项:
fixed固定大小线程池,启动时建立线程,不关闭,一直持有。(缺省)cached缓存线程池,空闲一分钟自动删除,需要时重建。limited可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。eager优先创建Worker线程池。在任务数量大于corePoolSize但是小于maximumPoolSize时,优先创建Worker来处理任务。当任务数量大于maximumPoolSize时,将任务放入阻塞队列中。阻塞队列充满时抛出RejectedExecutionException。(相比于cached:cached在任务数量超过maximumPoolSize时直接抛出异常而不是将任务放入阻塞队列)
一般可以将Dispatcher设置为message,网络相关事件除读写外其他交由Netty的worker线程处理,ThreadPool设置为cached。
以上是关于Dubbo3中服务端线程模型,线程处理(基于Dubbo3)的主要内容,如果未能解决你的问题,请参考以下文章