js 数据结构 字典 哈希表
Posted lin-fighting
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了js 数据结构 字典 哈希表相关的知识,希望对你有一定的参考价值。
字典
字典的主要特点就是对应关系,使用键值对存储数据,并且无序。
有些语言称这种映射关系为字典,有些称为Map。
在java中,对象和字典区别较大,对象一般是编译期确定下来的结构,不可以动态增加,但是字典是基于哈希表的数据结构去实现的一种可以动态增删的结构。
在早期js中,没有字典的说法,但是可以用对象去代替,es6后新增了Map的类型。
目前我们基于js的object来实现字典,
字典的实现与集合差不多,可以参考集合
哈希表
哈希表一般是通过数组实现的,但它相对数组有一些优点,
我们知道数组添加的时候很耗费性能,因为他的内存是连续的,所以需要申请新的内存,然后对应的值都往后移动,再添加数据。进行查找操作,如果基于下标,则效率较高,如果基于内容,则效率较低,删除操作效率也不高。
而哈希表:
- 提供非常快的插入-删除-查找操作
- 无论多少数据,插入删除的时间级都是o(1),只需要几个机器指令即可完成。
- 查找的速度比树还要快,可以瞬间找到
缺点: - 哈希表没有顺序
- 哈希表的key是不重复的。
哈希表的数据结构
哈希表的结构就是数组,但它神奇的地方是下标的变换。变换的规则函数称为哈希函数。通过哈希函数可以获取hashCode。
生活案例
公司员工的存储,一般用员工的名字通过特定的方法生成索引值。这个特定的方法就是通过哈希函数推算出来的。
电话薄,用名字通过哈希函数生产对应的索引值,想查某个人的电话时就可以直接知道索引值,从而快速获取电话号码。
字母转数字
上面的例子都指向了,字符串转成对应的数值。
设定一套规则,比如a是1,b是2,以此类推
第一个方法:相加 cat就是3 + 1 + 20 = 24,不过这种方法容易造成大量重复。
第二个方法:幂相乘 如cat = 3 * 10^3 + 1 * 10^2 + 20 = 1120,这种方法容易数组过大,而且很浪费。
第三个方法:压缩方法。比如5000个单词,就需要10000个数组即可。
- 哈希化,将大的数字转化为数组范围内下标的过程,成为哈希化。
- 哈希函数:一般将字母转为大的数字,再通过一个函数进行转化,这个函数就称为哈希函数
- 哈希表:最终将数据插入到数组中,并进行封装,得到哈希表。
现在的问题:
即使通过一些压缩方法,比如求余。(从1-199中取出5位数字,求余10放入数组,如11,24,35,78,96,那么他们的索引就是1,4,5,8,6,这种方法虽然会重复,但是概率较低)
但还是会有冲突,就是下标值重复的问题。
解决办法:堆地址法,开放地址法
堆地址法
数组中的每个位置不单单是存放value,应该放一个链表,或者数组,当有索引值重复的时候,将值push进该位置的链表或者数组的首部或尾部。查询的时候获取到索引值,将链表和数组拿出来进行线性探测。一个一个遍历获取。
如
[[[key, value], [key, value], [key, value]], [], [], []]
开放地址法
-
线性探测
这个方法就是,当你遇到值重复的时候,比如index = 2,如果2有值了,就继续index+1,往下面查找没有值的位置存放。比如22存放到2,32来了之后,通过index+1,存放到3,那么13来了之后,3已经有人了,所以又只能往4放。以此类推。
获取只需要,拿到index,然后判断是不是,不是就index+1继续判断。直到找到或者遇到了空位置就停止。因为不可能跳过空位置去插入的。
删除的时候呢,不能单单将该位置置为null,会影响查询,应该为-1等值,告诉查询,这个有值的,只是被我删除了。
这种方法的缺点就是聚集。比如第一次插入,11,22,33,44,55,66,再插入71的时候,就需要找很多歌位置了。比较浪费性能
-
二次探测
如果说线性探测是index+1 index+2,二次探测就是index+1 index+2^2 index+3^2每次都是通过平方去加。这样能解决线性探测聚集的问题,但是又会产生另类的聚集。比如11,21,31,41,51,这些,他们的探测方式都是一样的,下次再插入61的话,就要探测很多遍了。
-
再哈希法
通过跟哈希函数不一样的值,将索引继续哈希一遍,获取到新的结果,将这个新的结果作为“步长”去探测。比如11的索引是1,经过再哈希函数,就变成了4,然后在1+4= 5 的位置上插入。而21的索引是1,经过再哈希函数,就变成了8,然后在1+8=9的位置上插入。每个关键字的再哈希化都是不一样的结果。同个关键字的再哈希化都是同样的结果。
效率
装填因子:总数据项/哈希表长度
连地址法:无限
开放地址法:最大为1.
线性探测:

链地址法:
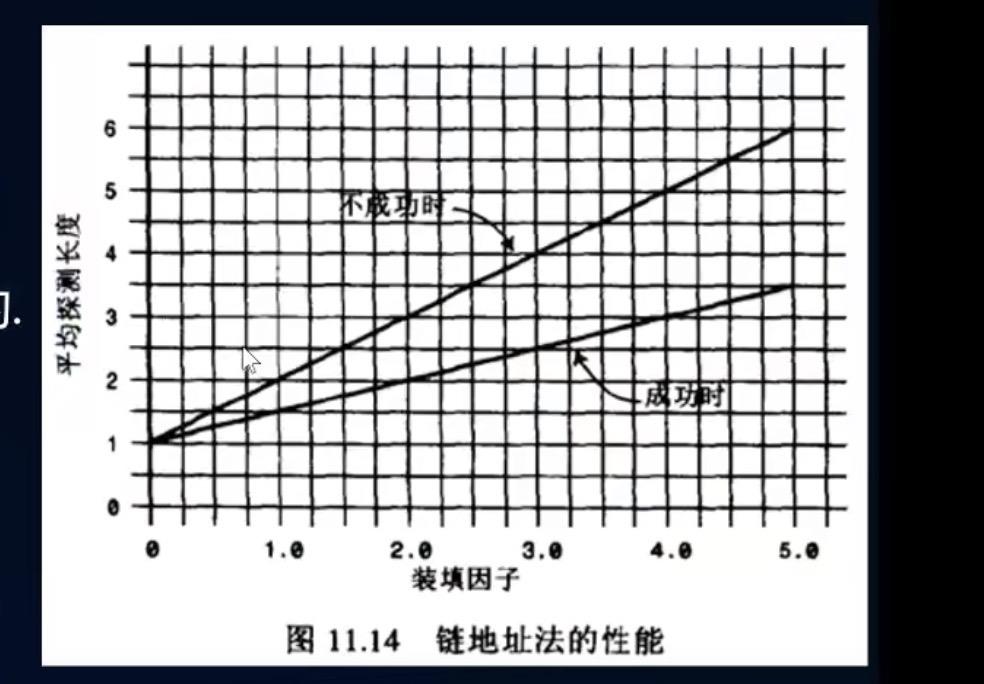
一般采用链地址法
实现哈希表(基于链地址法)
优秀的哈希函数
特点: 1 值分布均匀 2 快速计算
封装哈希函数
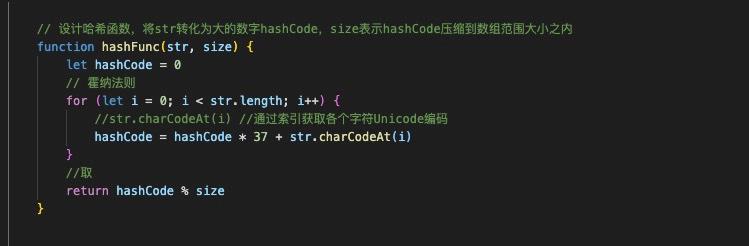
然后封装哈希表
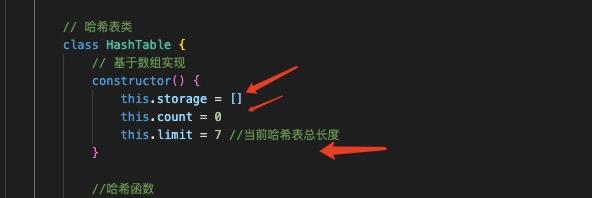
哈希表基于数组,然后需要有个长度。count用于计算当前个数
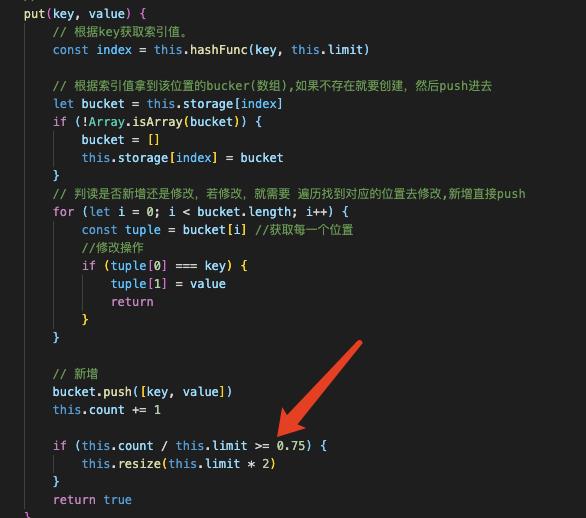
增加或者编辑操作
因为哈希表的特殊性,增加和编辑都是同样的操作。
都需要先通过key获取索引,然后拿到对应位置的数组,我们称之为bucket。如果bucket没有值,就需要重新建一个数组。如果有值,就直接遍历就行,然后该编辑编辑,该增加增加。如
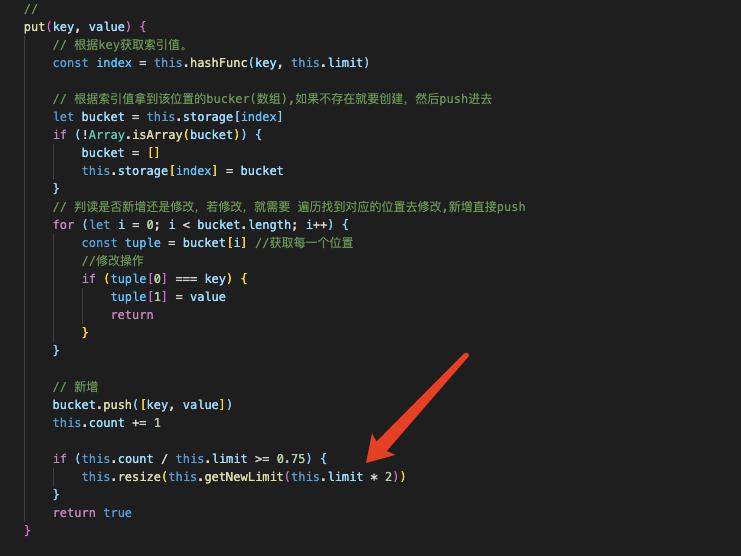
put(key, value) {
// 根据key获取索引值。
const index = this.hashFunc(key, this.limit)
// 根据索引值拿到该位置的bucker(数组),如果不存在就要创建,然后push进去
let bucket = this.storage[index]
if (!Array.isArray(bucket)) {
bucket = []
this.storage[index] = bucket
}
// 判读是否新增还是修改,若修改,就需要 遍历找到对应的位置去修改,新增直接push
for (let i = 0; i < bucket.length; i++) {
const tuple = bucket[i] //获取每一个位置
//修改操作
if (tuple[0] === key) { //如果遇到key一样的就直接修改
tuple[1] = value
return
}
}
// 新增
bucket.push([key, value])
this.count += 1
return true
}
如果遍历的过程中遇到ke y一样的就直接修改value,因为哈希表不允许索引重复。如果遍历完还是找不到,就证明是新增操作,直接push进bucket就行。
查找操作
get(key) {
const index = this.hashFunc(key, this.limit)
const bucket = this.storage[index]
if (!Array.isArray(bucket)) {
return false
}
for (let i = 0; i < bucket.length; i++) {
if (bucket[i][0] === key) {
return bucket[i][1]
}
}
return false
}
思路也一样的,直接通过key获取索引,然后拿出bucket,进行遍历
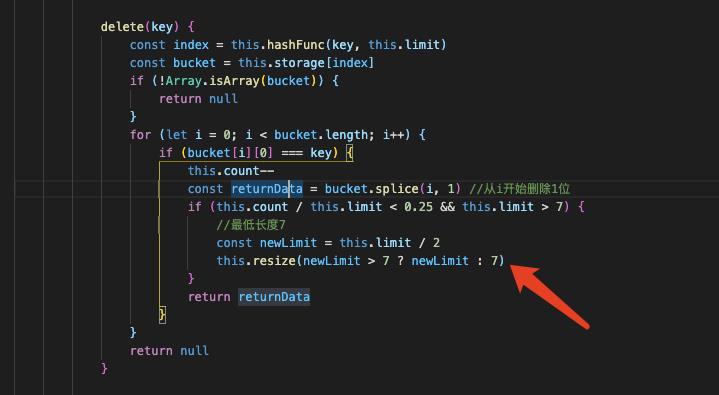
删除操作
delete(key){
const index = this.hashFunc(key, this.limit)
const bucket = this.storage[index]
if (!Array.isArray(bucket)) {
return null
}
for (let i = 0; i < bucket.length; i++) {
if (bucket[i][0] === key) {
return bucket.splice(i,1) //从i开始删除1位
}
}
return null
}
一样的逻辑,只不过这次不是返回,而是删除。
哈希扩容与缩容
目前是基于链地址法创建哈希表,当然可以插入无限个,但是数据一多,效率就变低了。所以就需要扩容。
扩容可以简单的将长度扩大一倍,但是所有数据必须重新通过哈希函数计算hashCode。这是必要的。一般在装填因子>0.75的时候可以进行扩容。
当装填因子<0.25的时候就要进行缩容,但必须有个最低长度,不能一直缩小。
实现
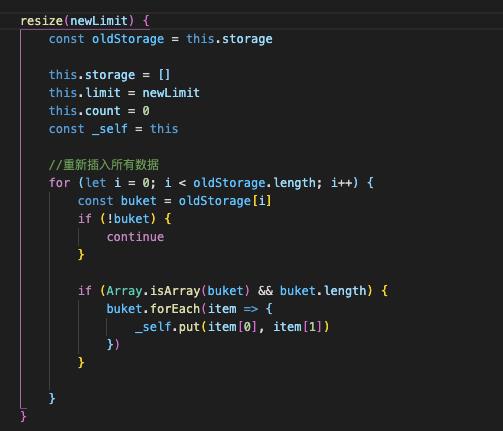
扩容的方法,然后需要在插入的删除的时候判断装填因子,
容量质数
将数组的长度设为质数(只能被1和自己整除),可以有利于数据均匀分布。在每次扩容的时候判断,放大两倍的长度是不是质数,不是的话就继续往上寻找,直到获取质数。
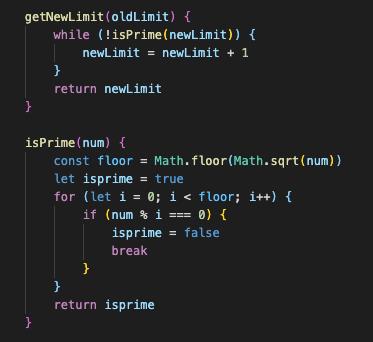
定义两个方法获取新长度。
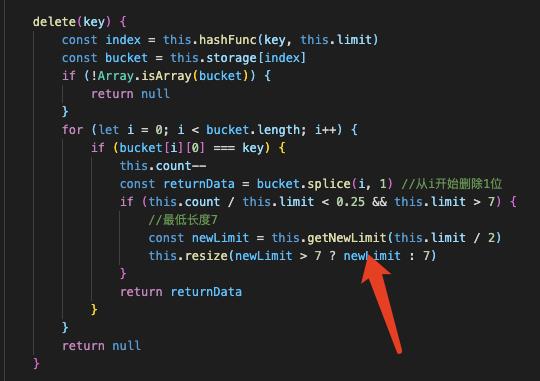
以上是关于js 数据结构 字典 哈希表的主要内容,如果未能解决你的问题,请参考以下文章