hive学习笔记
Posted 一加六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive学习笔记相关的知识,希望对你有一定的参考价值。
安装配置
安装hive
下载hive
 解压
解压

重命名

添加环境变量
Vi /etc/proflie

使环境变量生效
Source /etc/profile
修改配置文件
cp hive-env.sh.template hive-env.sh
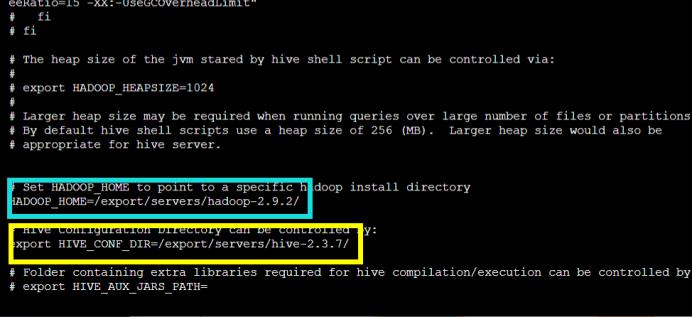
Hive Metastore配置
将自带的derby数据库替换为mysql数据库
参考文章https://my.oschina.net/u/4292373/blog/3497563
登录mysql创建新用户

授权

刷新权限

新增hive-site.xml文件
记坑
hive-default.xml.template 的开头就写明了 WARNING!!!对该文件的任何更改都将被Hive忽略
其实hive-site.xml是用户定义的配置文件
hive在启动的时候会读取两个文件一个是hive-default.xml.template 还有一个就是hive-site.xml
当执行cp复制命令时 hive-site.xml 里就有了hive-default.xml.template的内容
当你继续写入关于mysql的配置保存后进行初始化hive mysql时就会报这个错误,然后hive的Metastore 服务起不来。
解决办法
在复制的hive-site.xml里保存你写的配置项,然后将其他的删掉
hive-site.xml只能写你自己的配置项,其他删掉
原文链接:https://blog.csdn.net/qq_43506520/article/details/83346463
cp hive-default.xml.template hive-site.xml
Vi hive-site.xml 在hive-site.xml文件只保存如下配置
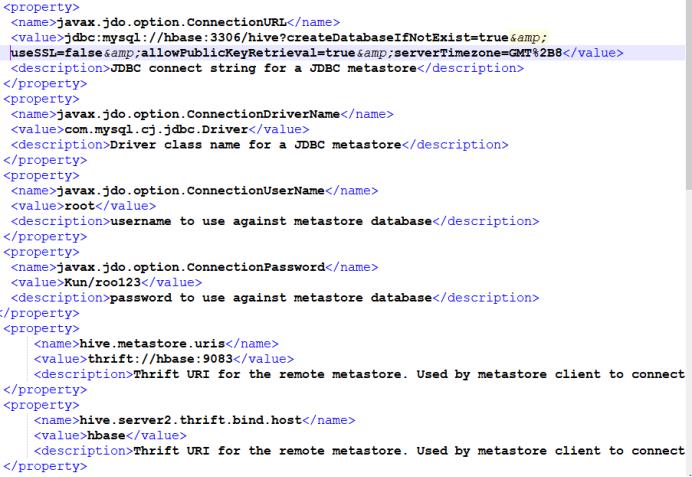
Join全连接查询报错
运行join语句需配置如下条件
文章https://blog.csdn.net/Joseph25/article/details/103507481

Jdbc安装驱动
把连接MySQL的JDBC驱动包复制到Hive的lib目录下
(下载地址:https://dev.mysql.com/downloads/connector/j/)
(驱动包名为:mysql-connector-java-5.1.46-bin.jar)
初始化数据库
schematool -dbType mysql -initSchema

若失败
错误类型和参考如下
https://blog.csdn.net/lsr40/article/details/78026125
https://blog.csdn.net/brotherdong90/article/details/49661731/
开启metastore
本地服务
hive --service metastore
防火墙开启9083
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>在dfs上的路径</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
远程服务
hiveserver2 start
需防火墙开启端口 10000
启动hive client
Commend命令行输入hive即可进入
启动hive
启动出现临时文件夹位置未定义问题
解决方案参考如下文章:
https://www.cnblogs.com/qxyy/articles/5247933.html
数据定义
数据库
#创建
Create database if not exists emp;
#查看
Show databases;
#描述
Describe formatted emp;
#使用
Use emp;
#修改
Alter database set dbproperty;
数据表
创建普通内部表
Create table employee(eid int,ename string,egender tinyint,esalary float);
创建外部表
Create external table emp(eid int,ename string,egender tinyint,esalary float);
内部表外部表转换
alter table table_name set tablepropertiles(‘external’=’true’|false);
分隔符
列分隔符
行分隔符
集合分隔符
Map分隔符
CREATE TABLE students(name string,age int,
subject ARRAY<String>,
score MAP<String,float>,
address STRUCT<houseNumber:int,
street:STRING, city:STRING, province:STRING>
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY "\\001" #-- 列分隔符
COLLECTION ITEMS TERMINATED BY "\\002"
#--MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
MAP KEYS TERMINATED BY "\\003" #-- MAP 中的 key 与 value 的分隔符
LINES TERMINATED BY "\\n" #-- 行分隔符
分区分桶
为什么分:
使用分区技术,避免hive全表扫描,提升查询效率
如何分:
整个表的数据在存储时划分到多个子目录,从而在查询时可以指定查询条件(子目录以分区变量的值来命名)eg:year=‘2018’
分区需注意什么:
PARTIONED BY(colName dataType)
hive的分区字段使用的是表外字段。而mysql使用的是表内字段。
1、hive的分区名区分大小写
2、hive的分区本质是在表目录下面创建目录,但是该分区字段是一个伪列,不真实存在于数据中
3、一张表可以有一个或者多个分区,分区下面也可以有一个或者多个分区
#导入分区
load data local inpath '/usr/local/xxx' into table part1 partition(country='China'); #要指定分区
#二级分区
create table if not exists part2(
uid int,
uname string,
uage int
)
PARTITIONED BY (year string,month string)
row format delimited
fields terminated by ','
;
load data local inpath '/usr/local/xxx' into table part1
partition(year='2018',month='09');
#增加分区
alter table part1 add partition(country='india') partition(country='korea') partition(country='America')
#加载分区数据
location '/user/hive/warehouse/xxx';
#修改分区的存储路径:(hdfs的路径必须是全路径)
alter table part1 partition(country='Vietnam') set location ‘hdfs://hadoop01:9000/user/hive/warehouse/brz.db/part1/country=Vietnam’
#动态分区
#动态分区的属性:
set hive.exec.dynamic.partition=true;//(true/false)
set hive.exec.dynamic.partition.mode=strict;//(strict/nonstrict) #至少有一个静态的值
set hive.exec.dynamic.partitions=1000;//(分区最大数)
set hive.exec.max.dynamic.partitions.pernode=100
#创建动态分区表
create table if not exists dt_part1(
uid int,
uname string,
uage int
)
PARTITIONED BY (year string,month string)
row format delimited
fields terminated by ','
;
#加载数据:(使用 insert into方式加载数据)
insert into dy_part1 partition(year,month) select * from part_tmp ;
分桶
在分区下分桶,分桶使用表内字段
语法格式
CREATE [EXTERNAL] TABLE <table_name>
(<col_name> <data_type> [, <col_name> <data_type> ...])]
[PARTITIONED BY ...]
CLUSTERED BY (<col_name>)
[SORTED BY (<col_name> [ASC|DESC] [, <col_name> [ASC|DESC]...])]
INTO <num_buckets> BUCKETS
CLUSTERED BY (<col_name>):以哪一列进行分桶 选择一列来分桶
SORTED BY (<col_name> [ASC|DESC]:对分桶内的数据进行排序
INTO <num_buckets> BUCKETS:分成几个桶
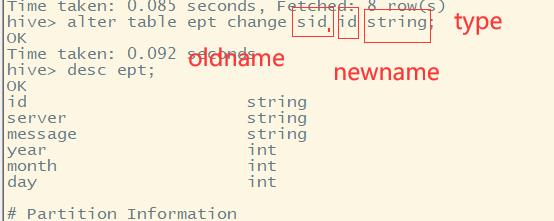
列信息更改
修改名称
Alter table emp change eid id string;
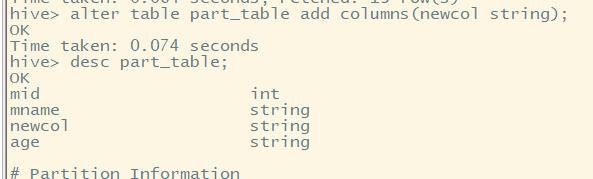
增加列
数据操作
#装载数据
Load data to table inpath ‘’
#插入数据
Insert into table emp partition(year=2021,month=10) select id,name from ept;
#导出数据
#到hdfs
Export table ept to ‘/hom/emp’;
#Insert 导出
Insert overwrite local directory ‘path’ select * from emp;
#到本地
Hfds dfs -get localpath
#Hive shell 命令导出
Hive -e ‘select * from emp;’ > localpath
#导入数据
Import table emp from path;
#HQL查询
Case when
Select name,salary, case
Wehn salary <5000 then ‘low’
When salary >=5000 and salary <7000 then ‘middle’
Whne salary >=7000 then salary < 10000 then ‘high’
Else ‘vary high’
End as bracket from emp;
Like和rlike
使用Like运算符可以进行模糊查询,通配符"%“代表0个或多个字符,”_"代表1个字符。RLIKE子句是Hive中这个功能的一个扩展,其可以通过Java的正则表达式这个更强大的语言来指定匹配条件。
GROUP BY
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个队列结果进行分组,然后对每个组执行聚合操作
HAVING
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
Having
与where不同
(1)where是对表中数据的筛选,having是对分组统计结果的筛选
(2)Where后不能写分组函数,而having后可以使用分组函数。
(3)Having只用于group by分组统计语句。
SELECT Customer,SUM(OrderPrice) FROM Orders
GROUP BY Customer
HAVING SUM(OrderPrice)<2000
Join
内连接
内连接(INNER JOIN)中,只有进⾏连接的两个表中都存在与连接条件相匹配的数据 时,记录才会被筛选出来
SELECT a.empno,a.ename,b.dname FROM emp a JOIN dept b ON a.deptno=b.deptno;
左连接
左外连接(LEFT OUTER JOIN)中,JOIN操作符左边表中符合WHERE⼦句的所有记 录将会出现在查询结果中。右边表中如果没有符合ON后⾯连接条件的记录时,从右边表 指定选择的列的值将会是NULL。
SELECT a.empno,a.ename,b.dname FROM emp a LEFT OUTER JOIN dept b ON a.deptno==b.deptno;
全连接

多表连接
连接 n个表,⾄少需要n-1个连接条件。例如:连接三个表,⾄少需要两个连接条件。
hive> SELECT a.ename,b.dname,c.zip FROM emp a JOIN dept b ON a.deptno=b.deptno JOIN location c ON b.loc=c.loc;
注意:为什么不是表b和表c先进⾏连接操作呢?这是因为Hive总是按照从左到右的顺序 执⾏的。
排序
ORDER BY
ORDER BY⽤于对全局查询结果进⾏排序,也就是说会有⼀个所有的数据都通过⼀个 reducer进⾏处理的过程。
SORT BY
Hive增加了⼀个可供选择的⽅式,即SORT BY,其只会在每个reducer中对数据进⾏排 序,即执⾏⼀个局部排序过程。这会保证每个reducer的输出数据都是有序的(但并⾮ 全局有序)。
ORDER BY 和SORT BY的区别是当reducer的个数⼤于1时,两种操作的输出结果是不 同的,SORT BY是reducer内的局部排序。
DISTRIBUTE BY和SORT BY
如果我们想对同⼀部⻔中的员⼯进⾏排序处理,那么我们可以使⽤DISTRIBUTE BY来保 证具有相同部⻔编号的员⼯被分到同⼀个reducer中去,然后使⽤SORT BY来按照我们 的期望对数据进⾏排序。
hive> SELECT * FROM emp DISTRIBUTE BY deptno SORT BY empno DESC;
CLUSTER BY
当distribute by和sorts by字段相同时,可以使⽤cluster by⽅式。 ⽤cluster b除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序 排序,不能指定排序规则为ASC或者DESC。
hive> select * from emp cluster by deptno;
hive> select * from emp distribute by deptno sort by deptno;
类型转换
Hive会在适当的时候对数值型数据类型进⾏隐式类型转换,有些时候需要显示类型转换 时可以使⽤关键字cast。显示类型转换函数的语法是:
cast(value AS TYPE)
ALTER TABLE employees CHANGE COLUMN salary salary STRING;
SELECT name,salary FROM employees WHERE cast(salary AS FLOAT) < 100000.0;
空字段赋值
NVL:给值为NULL的数据赋值,它的格式是NVL( string1, replace_with)。它的功能是如果 string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值,如果两个参数都为 NULL ,则返回NULL。
hive> select nvl(comm,-1) from emp;
以上是关于hive学习笔记的主要内容,如果未能解决你的问题,请参考以下文章
[原创]java WEB学习笔记61:Struts2学习之路--通用标签 property,uri,param,set,push,if-else,itertor,sort,date,a标签等(代码片段