k8s 部署智能化日志收集平台
Posted 笨小孩@GF 知行合一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s 部署智能化日志收集平台相关的知识,希望对你有一定的参考价值。

-
为什么要收集日志?
- 不管是在项目开发还是测试过程中,项目运行一旦出现问题日志信息就非常重要了。日志是定位问题的重要手段,就像侦探人员要根据现场留下的线索来推断案情。
- 日志级别:
第一级:DEBUG
调试信息,也是最详细的日志信息
第二级:INFO
证明事件按照预期工作
第三级:WARNING
表明发生了一些暂时不影响运行的错误,
第四级:ERROR
这一级就是比较重要的错误了,软件的某些功能已经不能继续执行了 - 传统物理机下部署应用应该采集哪些日志?
1、系统日志: 所有的系统应用都会在/var/log 目录下创建日志文件,系统日志主要存放系统内置程序或系统内核之类的日志信息,如 btmp 等
2、应用日志:应用日志主要是安装的第三方应用产生的日志,如 tomcat7 、apache2 等。
-
k8s 集群应该采集哪些日志?
-
K8S 系统的组件日志:apiserver、scheduler、kubelet
K8S 集群里面部署的应用程序日志
在 Kubernetes 集群上运行多个服务和应用程序时,日志收集系统可以帮助你快速分类和分析由Pod 生成的大量日志数据。
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方推荐的一种方案。 -
在 k8s 集群中应用一般有如下日志输出方式:
直接遵循 docker 官方建议把日志输出到标准输出或者标准错误输出输出日志到容器内指定目录中,应用直接发送日志给日志收集系统 -
采集日志的方案:
Filebeat(日志采集工具)+Logstach(数据处理引擎)+Elasticserch(数据存储、全文检索、分布式搜索引擎)+Kibana(展示数据、绘图、搜索)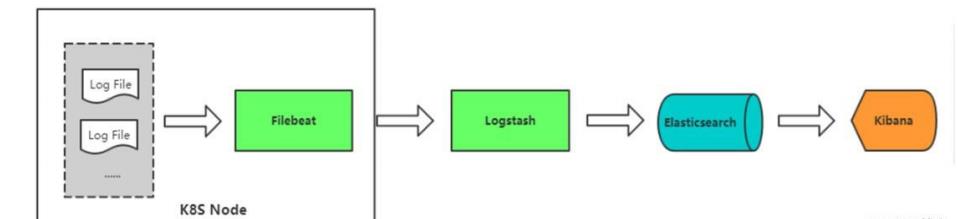
-
分布式搜索引擎 elasticsearch 深度解读
-
Elasticsearch 概述
-
Elasticsearch 是一个实时的,分布式的,可扩展的搜索引擎,它允许进行全文本和结构化搜索以及对日志进行分析。它通常用于索引和搜索大量日志数据,也可以用于搜索许多不同种类的文档。
-
elasticsearch 具有三大功能,搜索、分析、存储数据
-
Elasticsearch 通常与 Kibana 一起部署,kibana 是 Elasticsearch 的功能强大的数据可视化的dashboard(仪表板)。Kibana 允许你通过 Web 界面浏览 Elasticsearch 日志数据,也可自定义查询条件快速检索出 elasticccsearch 中的日志数据。
-
Elasticsearch 特点
1、分布式的文档存储引擎
2、分布式的搜索引擎和分析引擎
3、可以横向扩展至数百甚至数千个服务器节点,同时可以处理 PB 级数据。 -
Elasticsearch 基本概念
1、集群(cluster):包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称)来决定,节点可以分散到各个机器上。有一个主节点,通过选举产生,从外部来看 es 集群,在逻辑上是个整体,与任何一个节点的通信和与整个 es 集群通信是等价的。
2、节点(node),集群中的一个节点,如果默认启动 1 个或者多个节点,那么他们自动组成一个集群。一个 elasticsearch 实例就是一个节点。每个节点可以有多个 shard,但是 primary shard 和对应replica shard 不能在同一个节点上。
3、document 文档,es 中最小的数据单元,由 json 串组成,里面包含多个 field,每个 field 即是一个数据字段。
4、index 索引,包含一堆具有相似结构的文档数据,一个索引默认有 5 个 primary shard,一个primary shard 对应一个 replica shard,即 5 个 primary shard 和 5 个 replica shard。一个完整索引可以分成多个分片分布到不同节点,分布式存储分布式搜索分片的数量只能在索引创建前指定,并且索引创建后不能更改。
5、type 类型,每个索引有一个或者多个 type,type 是 index 中的一个逻辑数据分类,一个 type下的 document,应该都有相同 field。es6 时,官方就提到了 es7 会删除 type,并且 es6 时已经规定每一个 index 只能有一个 type。在 es7 中使用默认的_doc 作为 type,官方说在 8.x 版本会彻底移除type。 -
高效的日志收集组件 fluentd 原理
-
fluentd 概述
-
Fluentd 是一个流行的开源数据收集器,专为处理数据流设计,使用 JSON 作为数据格式。在Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
-
常见的日志收集组件对比分析
1、Logstash
Logstash 是一个开源数据收集引擎,具有实时管道功能。Logstash 可以动态地将来自不同数据源的数据统一起来,并将数据标准化输出到你所选择的目的地。
logstash 具有 filter 功能,能过滤分析日志
优势:
Logstash 主要的优点就是它的灵活性,主要因为它有很多插件,可以在网上找到很多资源,几乎可以处理任何问题。
劣势:
Logstash 的问题是它的性能以及资源消耗(默认的堆大小是 1GB)。另一个问题是它目前不支持缓存,目前的典型替代方案是将 Redis 或 Kafka 作为中心缓冲池:
2、Filebeat
Filebeat 是一个轻量级的日志传输工具,它的存在正弥补了 Logstash 的缺点:Filebeat 作为一个轻量级的日志传输工具可以将日志推送到中心 Logstash。
在版本 5.x 中,Elasticsearch 具有解析的能力(像 Logstash 过滤器)— Ingest。这也就意味着可以将数据直接用 Filebeat 推送到 Elasticsearch,并让 Elasticsearch 既做解析的事情,又做存储的事情。
不需要使用缓冲,因为 Filebeat 也会和 Logstash 一样记住上次读取的偏移,如果需要缓冲(例如,不希望将日志服务器的文件系统填满),可以使用 Redis/Kafka,因为 Filebeat 可以与它们进行通信。
优势:
Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少。
一般结构都是 filebeat 采集日志,然后发送到消息队列,redis,kafaka。然后 logstash 去获取,利用 filter 功能过滤分析,然后存储到 elasticsearch 中
3、Fluentd
fluentd 是一个针对日志的收集、处理、转发系统。通过丰富的插件系统,可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
fluentd 常常被拿来和 Logstash 比较,我们常说 ELK,L 就是这个 agent。
fluentd 是随着Docker,和 es 一起流行起来的 agent。
fluentd 比 logstash 更省资源。 -
数据的探索和可视化分析:kibana
-
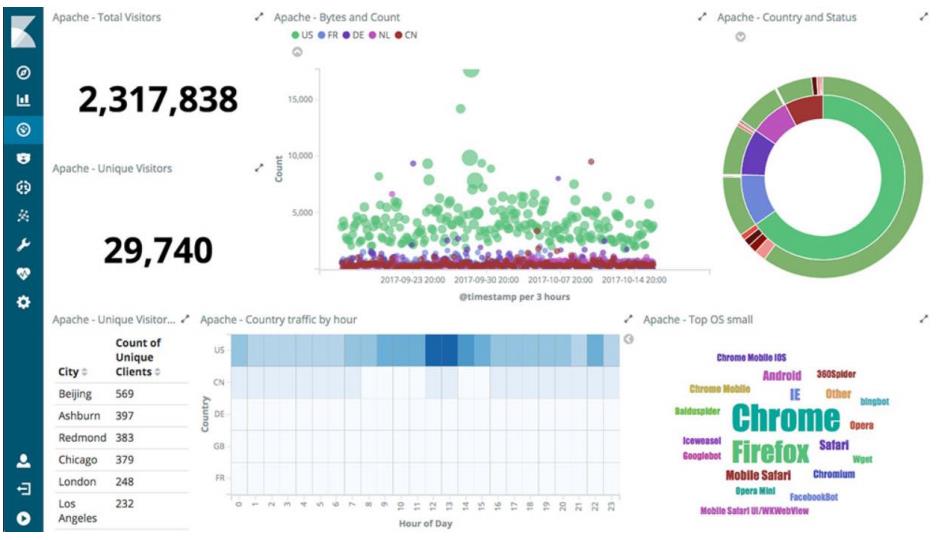
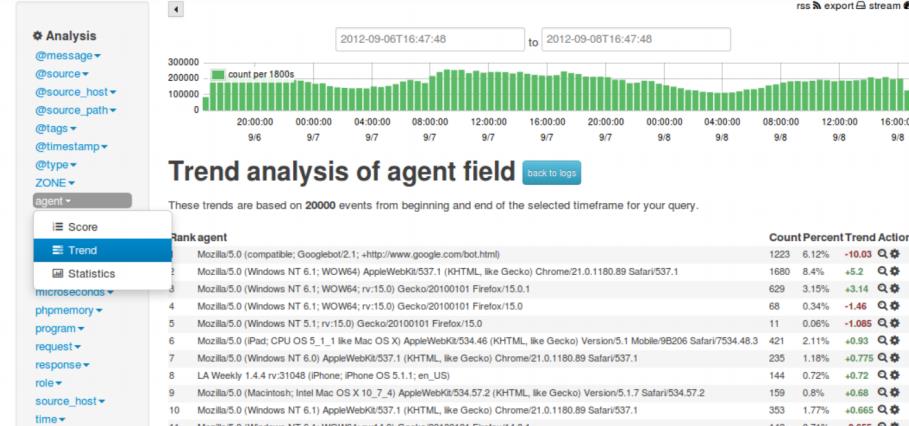
kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据。Kibana 功能众多,在“Visualize” 菜单界面可以将查询出的数据进行可视化展示,“Dev Tools” 菜单界面可以让户方便地通过浏览器直接与 Elasticsearch 进行交互,发送 RESTFUL 对Elasticsearch 数据进行增删改查。。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示 Elasticsearch 查询动态。设置 Kibana 非常简单。无需编码或者额外的基础架构,几分钟内就可以完成 Kibana 安装并启动 Elasticsearch 索引监测。
-
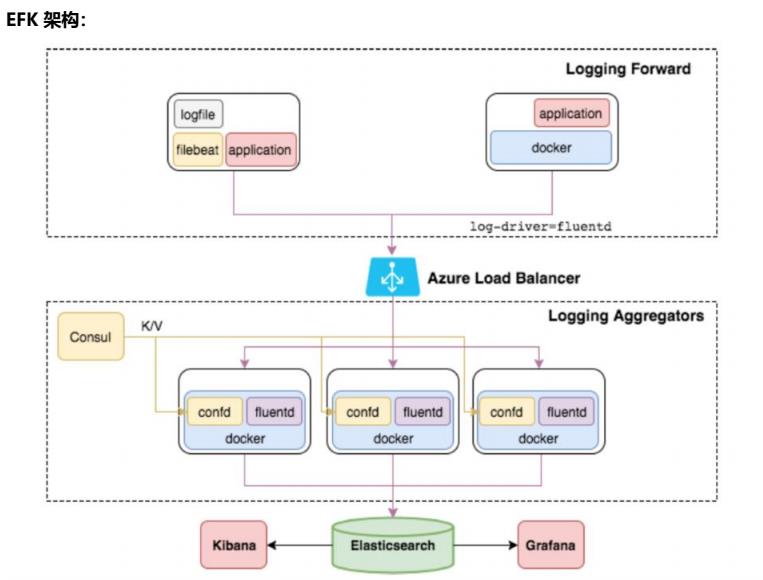
EFK 日志处理流程
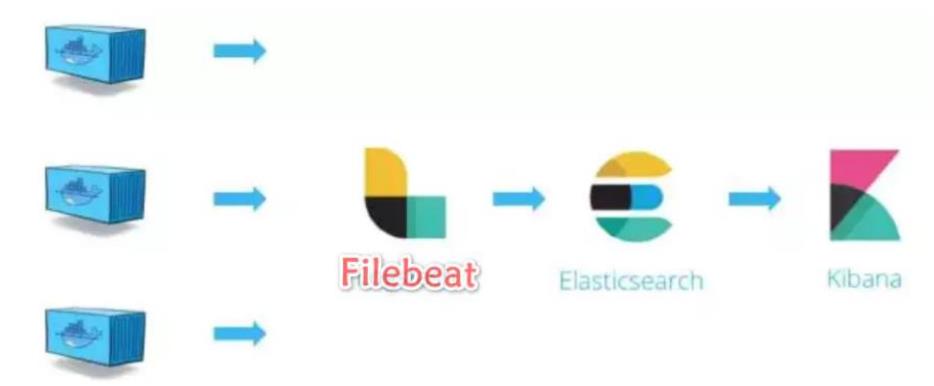
filebeat 从各个节点的 Docker 容器中提取日志信息
filebeat 将日志转发到 ElasticSearch 进行索引和保存
Kibana 负责分析和可视化日志信息
-
在 k8s 中安装 EFK 组件
- 先来配置启动一个可扩展的 Elasticsearch 集群,然后在 Kubernetes 集群中创建一个 Kibana 应用,最后通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod
- 安装 elasticsearch 组件
在安装 Elasticsearch 集群之前,先创建一个名称空间,在这个名称空间下安装日志收工具elasticsearch、fluentd、kibana。
-
创建一个 kube-logging 名称空间,将 EFK 组件安装到该名称空间中。
-
下面安装步骤均在 k8s 控制节点操作:
1.创建 kube-logging 名称空间
vim kube-logging.yaml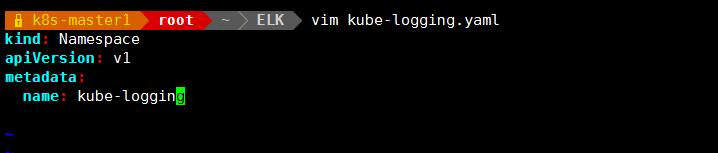
-
安装 elasticsearch 组件
#创建 headless service
vim elasticsearch_svc.yaml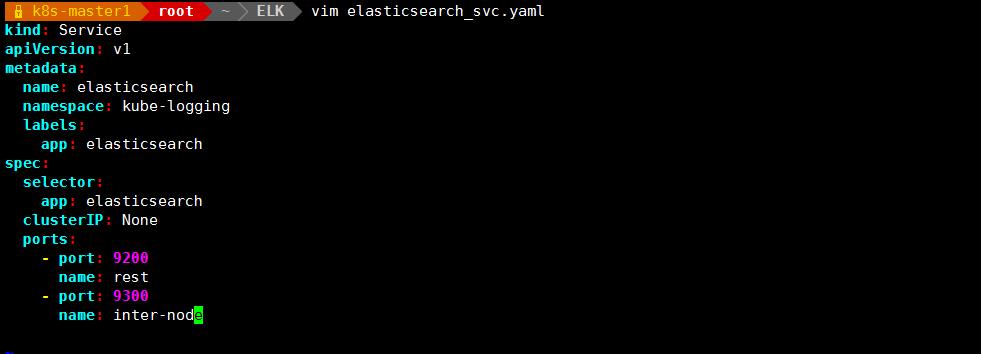
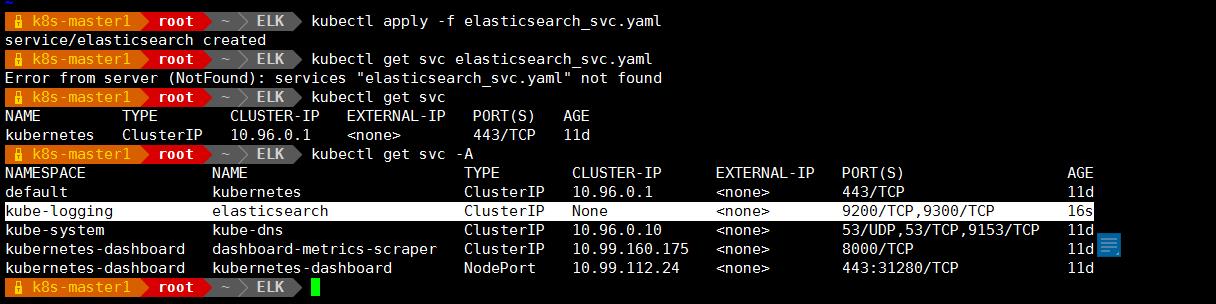
-
创建 storageclass
vim es_class.yaml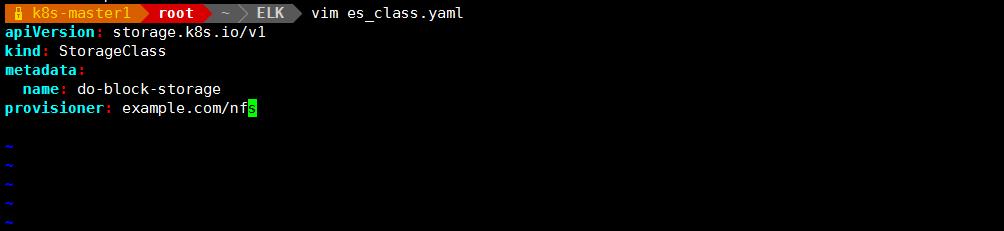

vim elasticsearch-statefulset.yaml
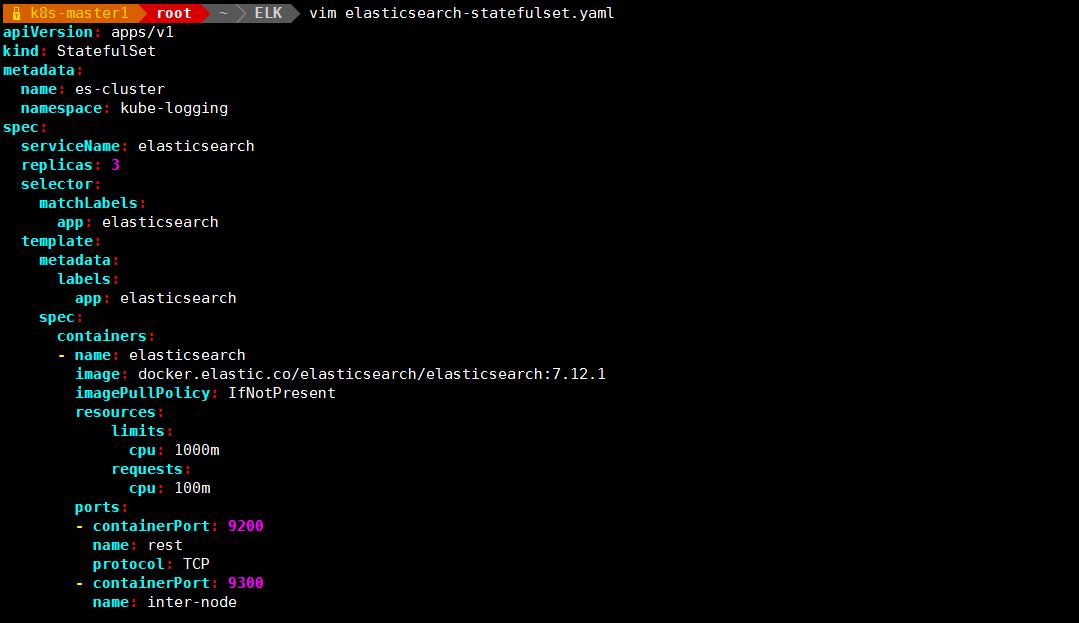
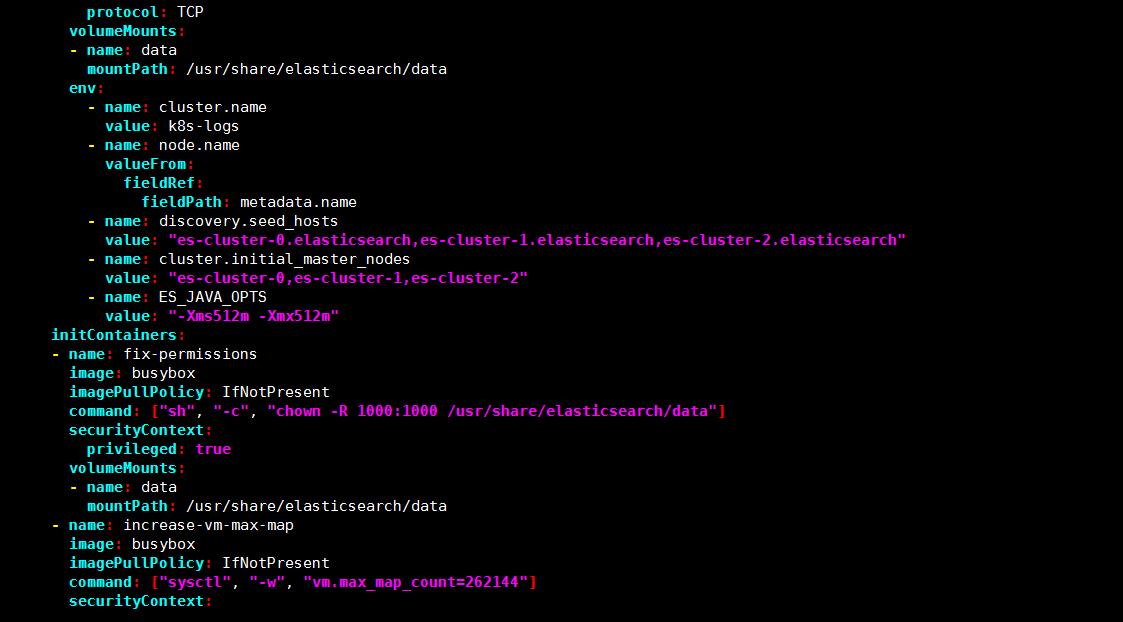
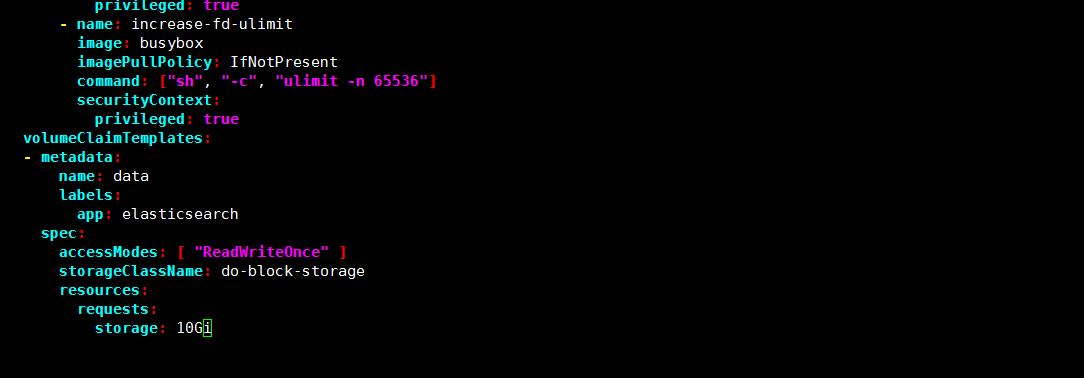
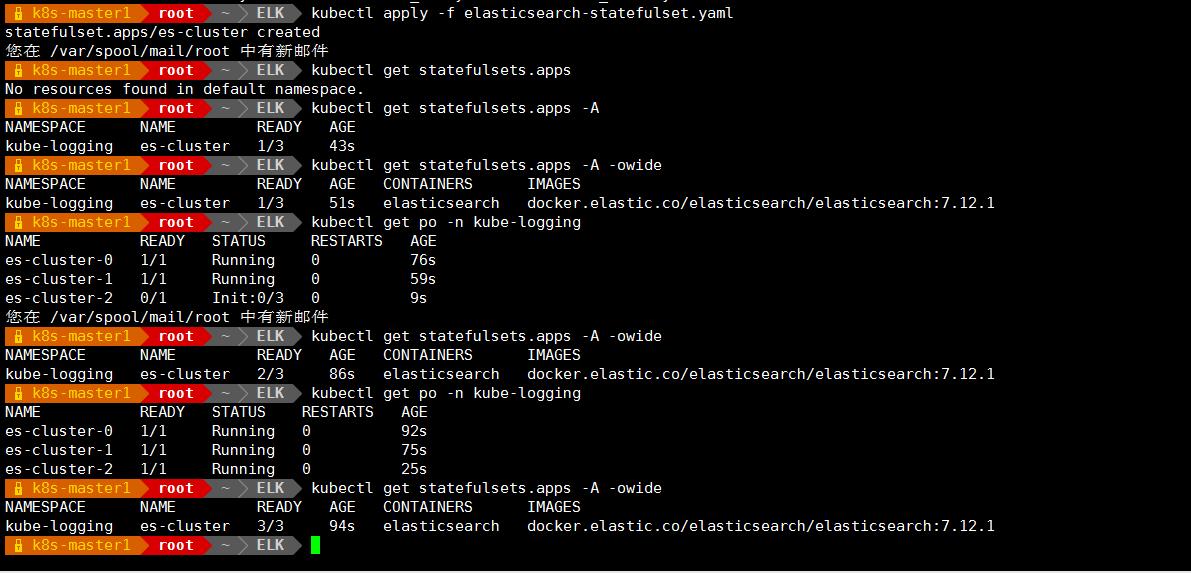
pod 部署完成之后,可以通过 REST API 检查 elasticsearch 集群是否部署成功,使用下面的命令将本地端口 9200 转发到 Elasticsearch 节点(如 es-cluster-0)对应的端口:
kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
然后,在另外的终端窗口中,执行如下请求,新开一个终端:
curl http://localhost:9200/_cluster/state?pretty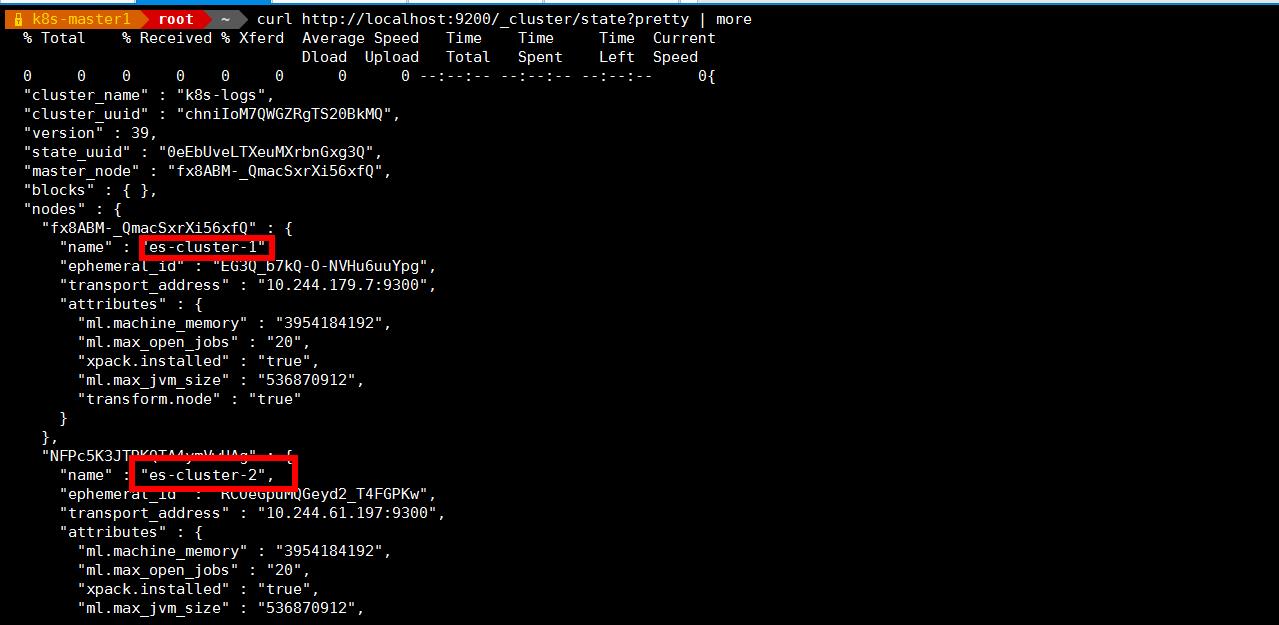
 看到上面的信息就表明我们名为 k8s-logs 的 Elasticsearch 集群成功创建了 3 个节点:escluster-0,es-cluster-1,和 es-cluster-2,当前主节点是 "master_node" : "fx8ABM-_QmacSxrXi56xfQ", es-cluster-1。
看到上面的信息就表明我们名为 k8s-logs 的 Elasticsearch 集群成功创建了 3 个节点:escluster-0,es-cluster-1,和 es-cluster-2,当前主节点是 "master_node" : "fx8ABM-_QmacSxrXi56xfQ", es-cluster-1。 -
安装 kibana 组件
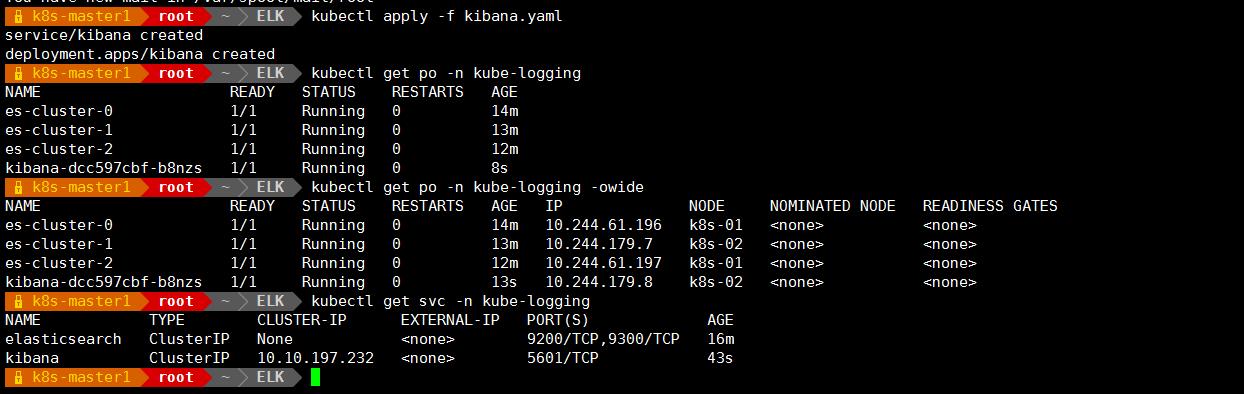
vim kibana.yaml
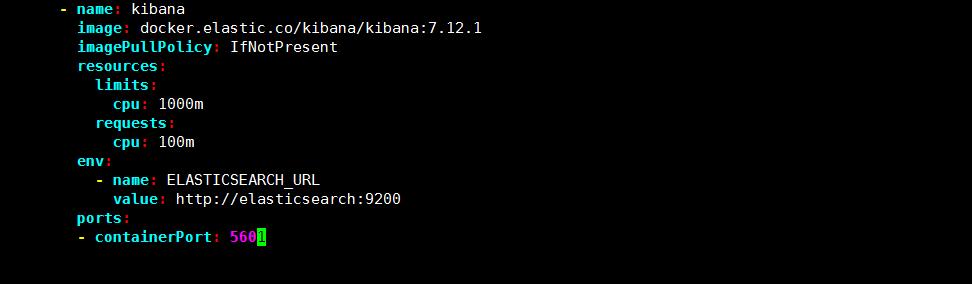
#上面我们定义了两个资源对象,一个 Service 和 Deployment,为了测试方便,我们将 Service 设置为了 NodePort 类型,Kibana Pod 中配置都比较简单,唯一需要注意的是我们使用ELASTICSEARCH_URL 这个环境变量来设置 Elasticsearch 集群的端点和端口,直接使用Kubernetes DNS 即可,此端点对应服务名称为 elasticsearch,由于是一个 headless service,所以该域将解析为 3 个 Elasticsearch Pod 的 IP 地址列表。
-
修改 service 的 type 类型为 NodePort:
kubectl edit svc kibana -n kube-logging
把 type: ClusterIP 变成 type: NodePort
保存退出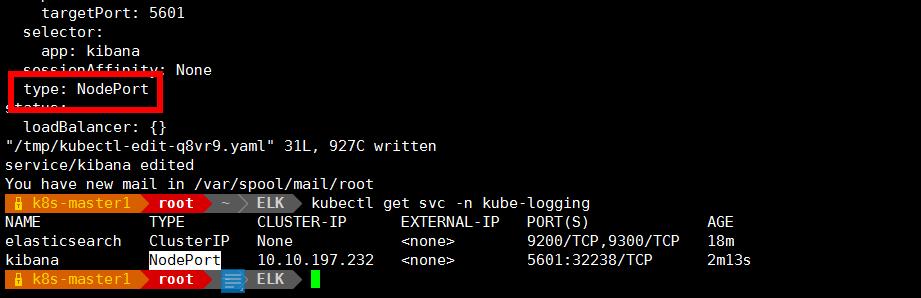
-
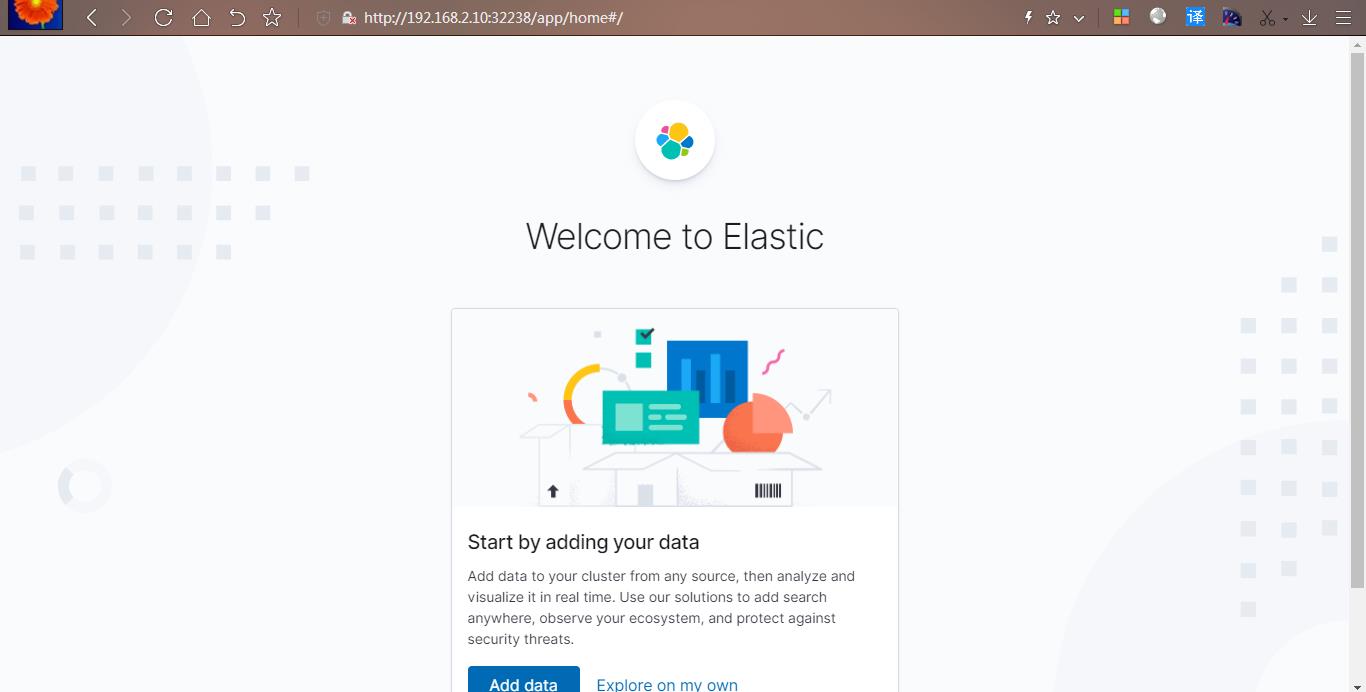
在浏览器中打开 http://<k8s 集群任意节点 IP>:32238 即可,如果看到如下欢迎界面证明 Kibana 已经成功部署到了 Kubernetes 集群之中。
-
安装 fluentd 组件
-
使用 daemonset 控制器部署 fluentd 组件,这样可以保证集群中的每个节点都可以运行同样fluentd 的 pod 副本,这样就可以收集 k8s 集群中每个节点的日志,在 k8s 集群中,容器应用程序的输入输出日志会重定向到 node 节点里的 json 文件中,fluentd 可以 tail 和过滤以及把日志转换成指定的格式发送到 elasticsearch 集群中。除了容器日志,fluentd 也可以采集 kubelet、kube-proxy、docker 的日志。
-
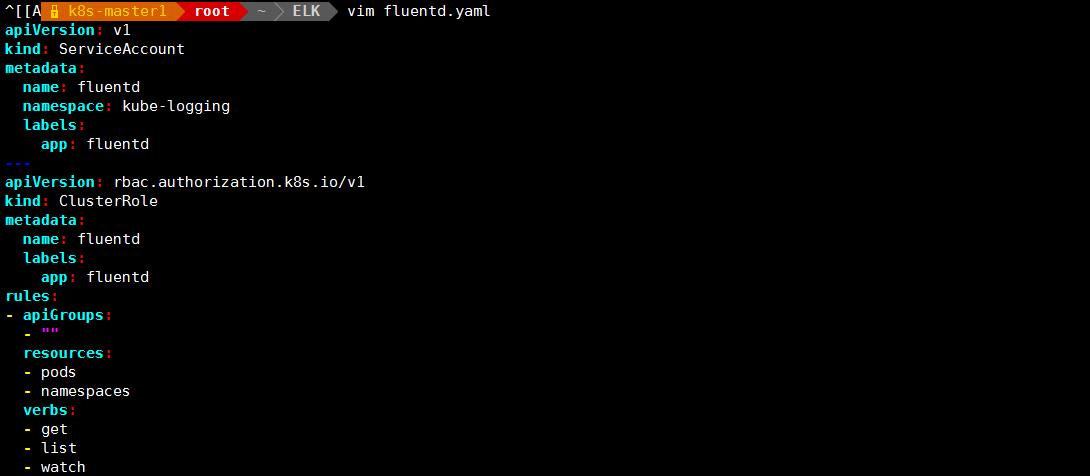
vim fluentd.yaml
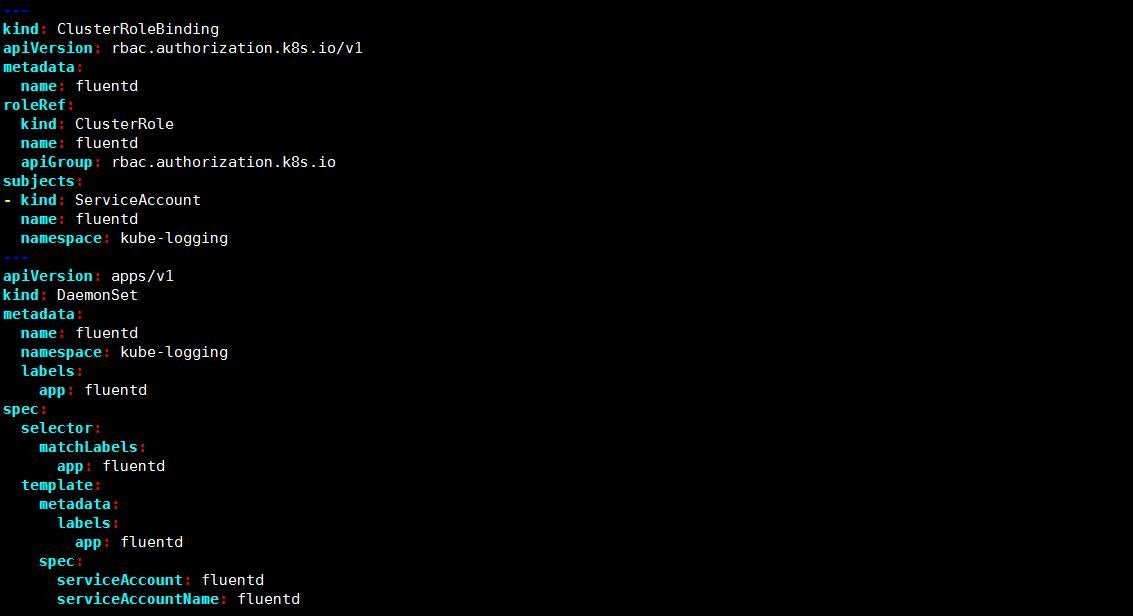
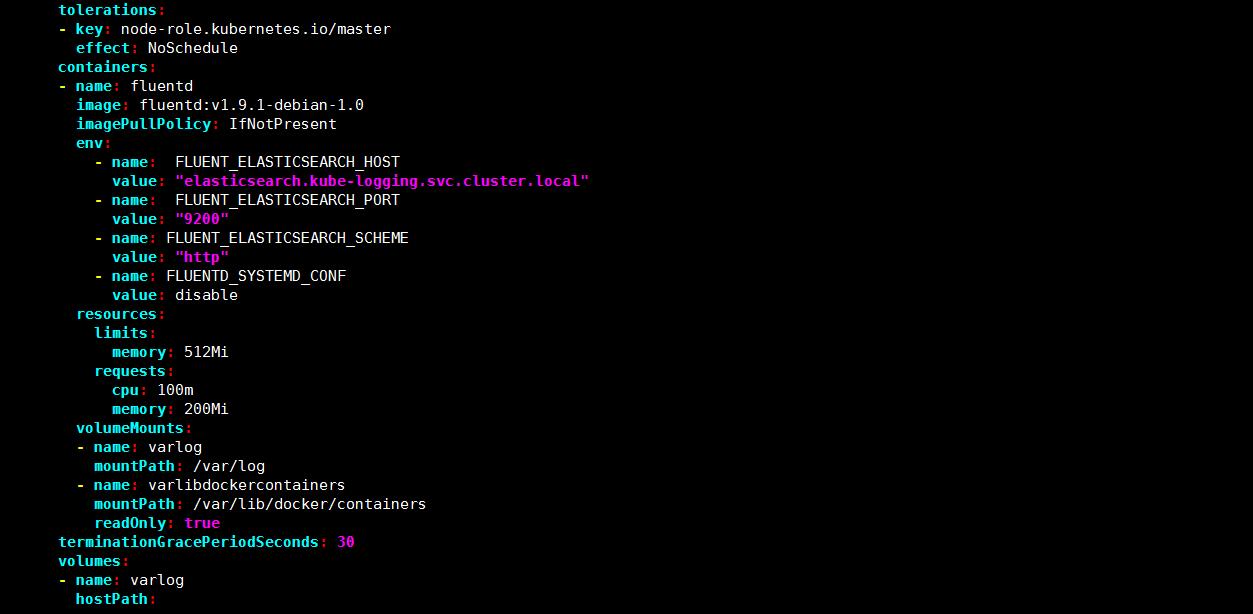

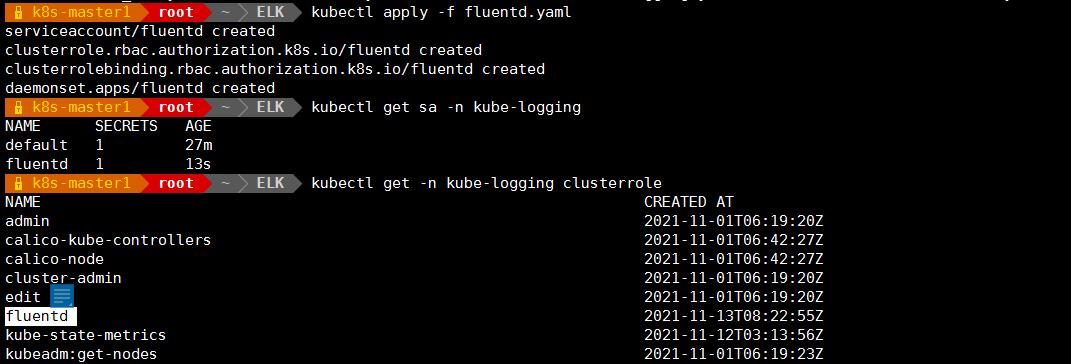

-
Fluentd 启动成功后,前往 Elastic 的 home 页面中,点击 kibana,可以看到如下配置页面:
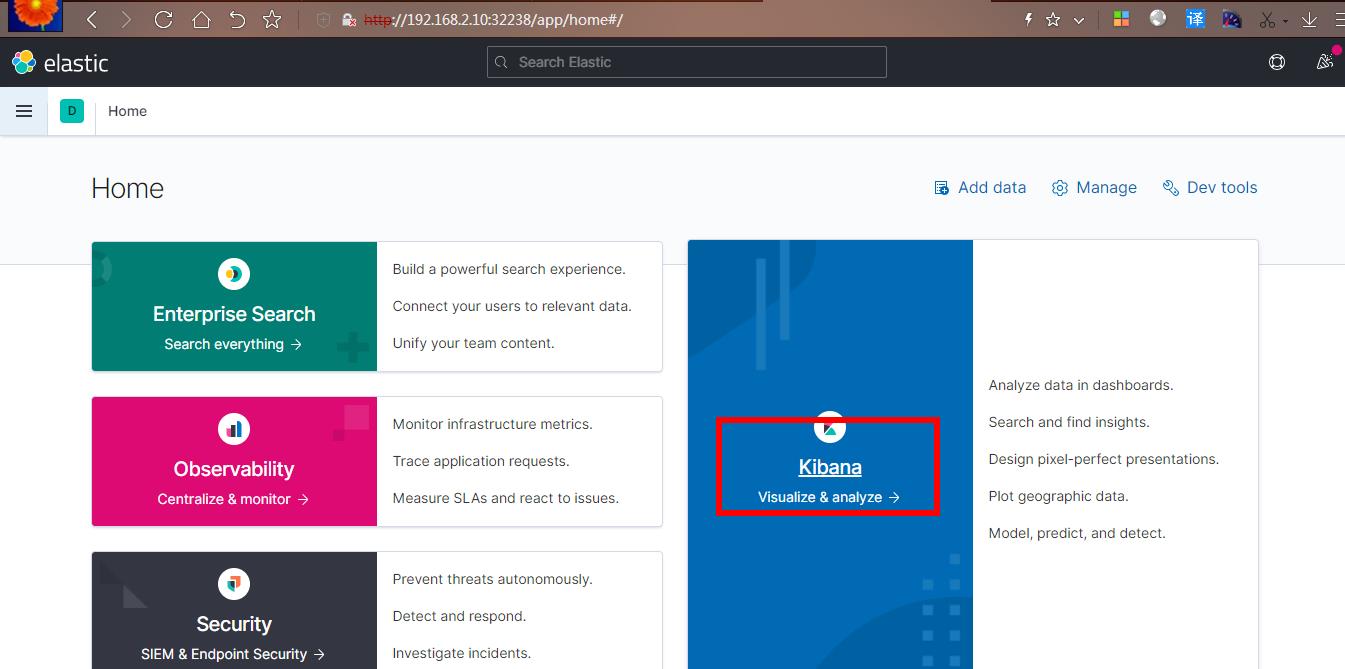
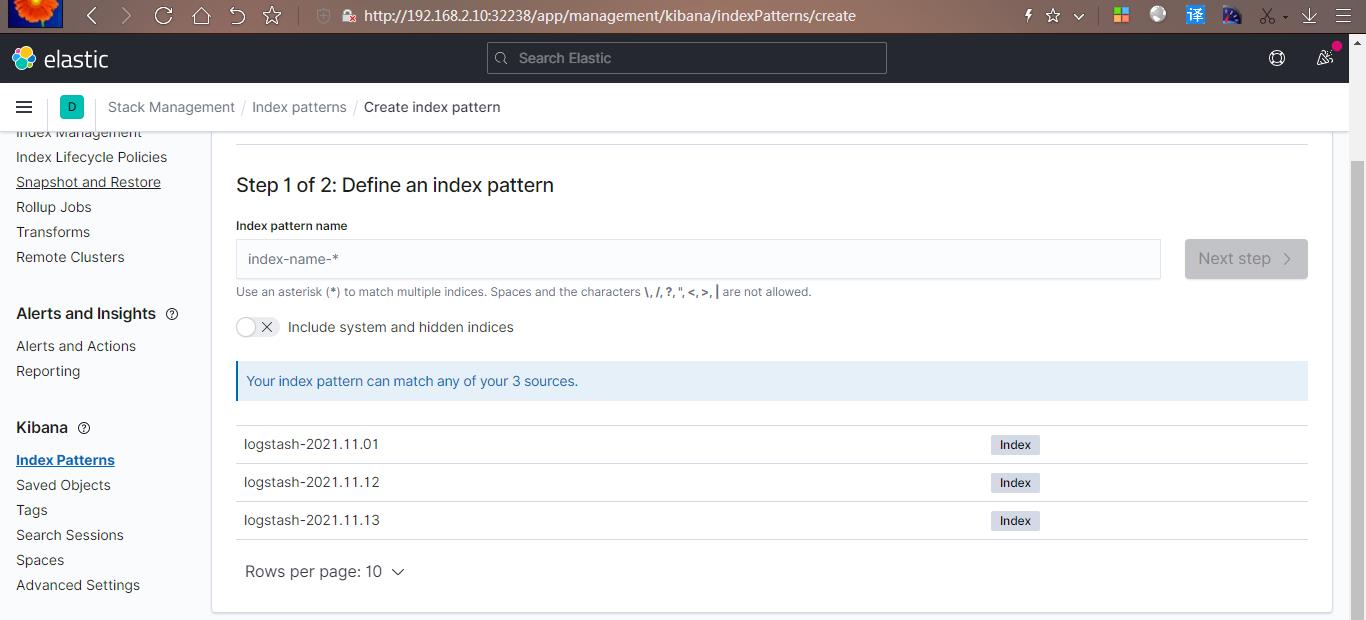
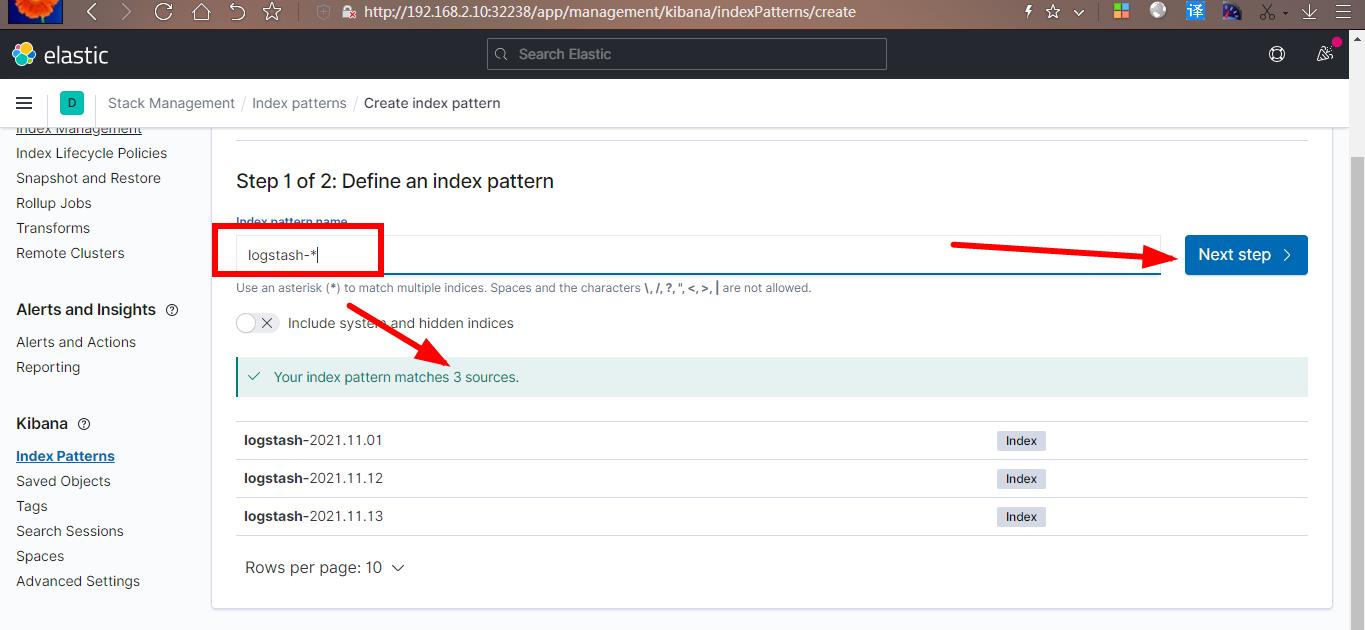
在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,这里只需要在文本框中输入 logstash-*即可匹配到 Elasticsearch 集群中的所有日志数据,然后点击下一步,进入以下页面:
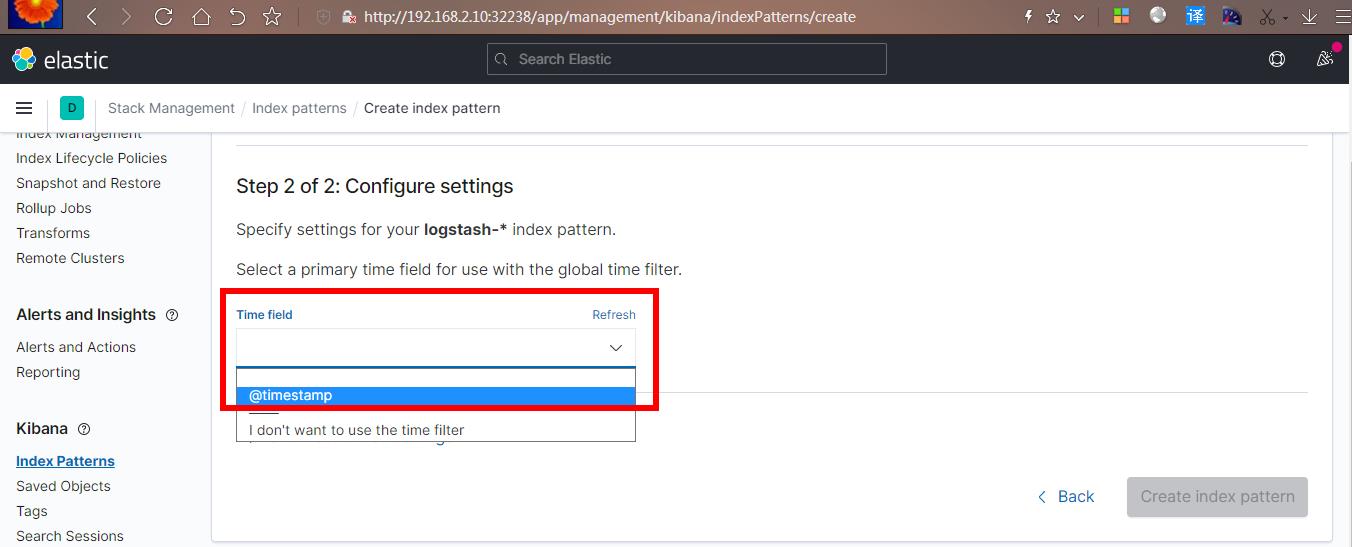
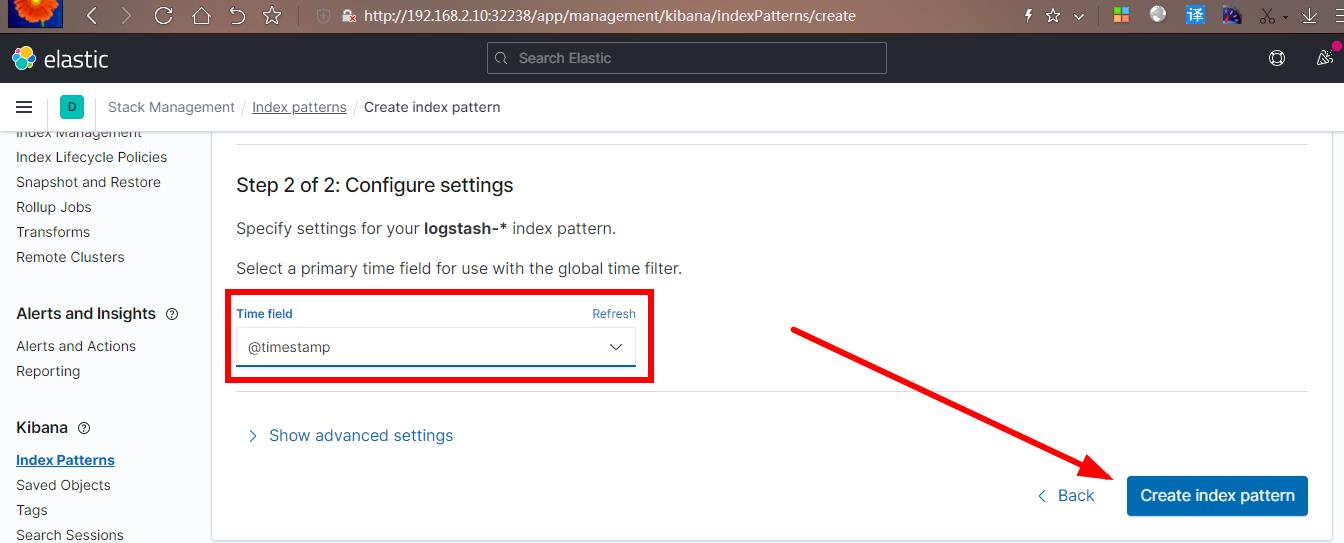
点击 next step,出现如下 ,选择@timestamp,创建索引
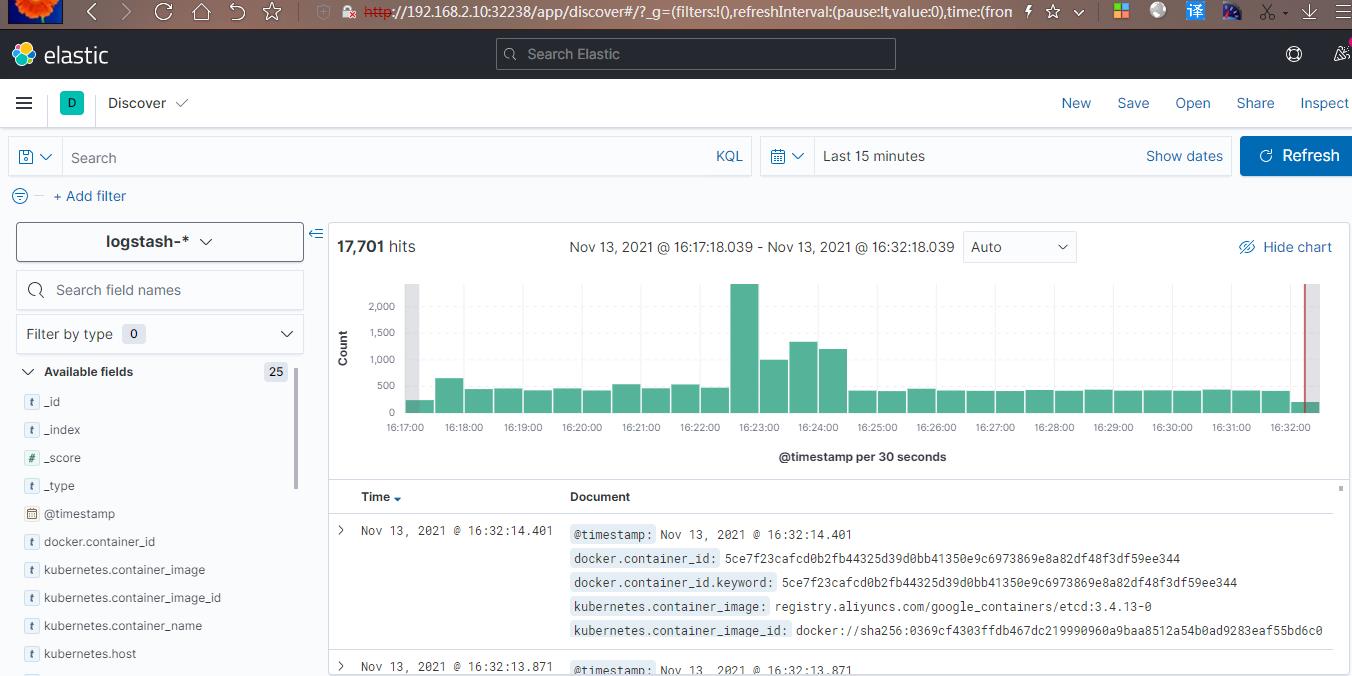
点击 Home ---> kibana ----> discover,可看到如下:
官方手册:
Kibana Query Language | Kibana Guide [7.12] | Elastic https://www.elastic.co/guide/en/kibana/7.12/kuery-query.html
https://www.elastic.co/guide/en/kibana/7.12/kuery-query.html
-
测试收集 pod 业务日志
vim pod.yaml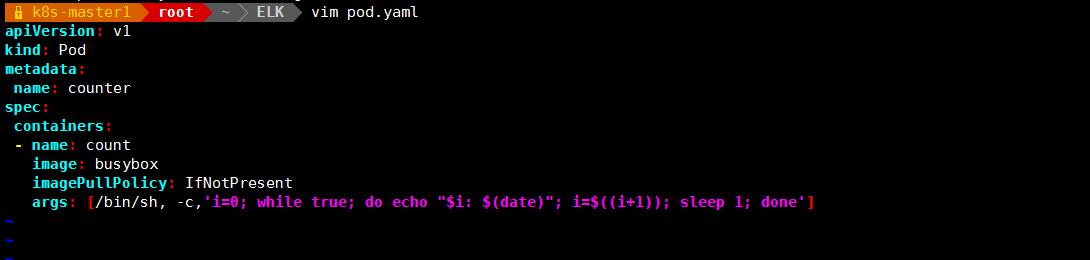
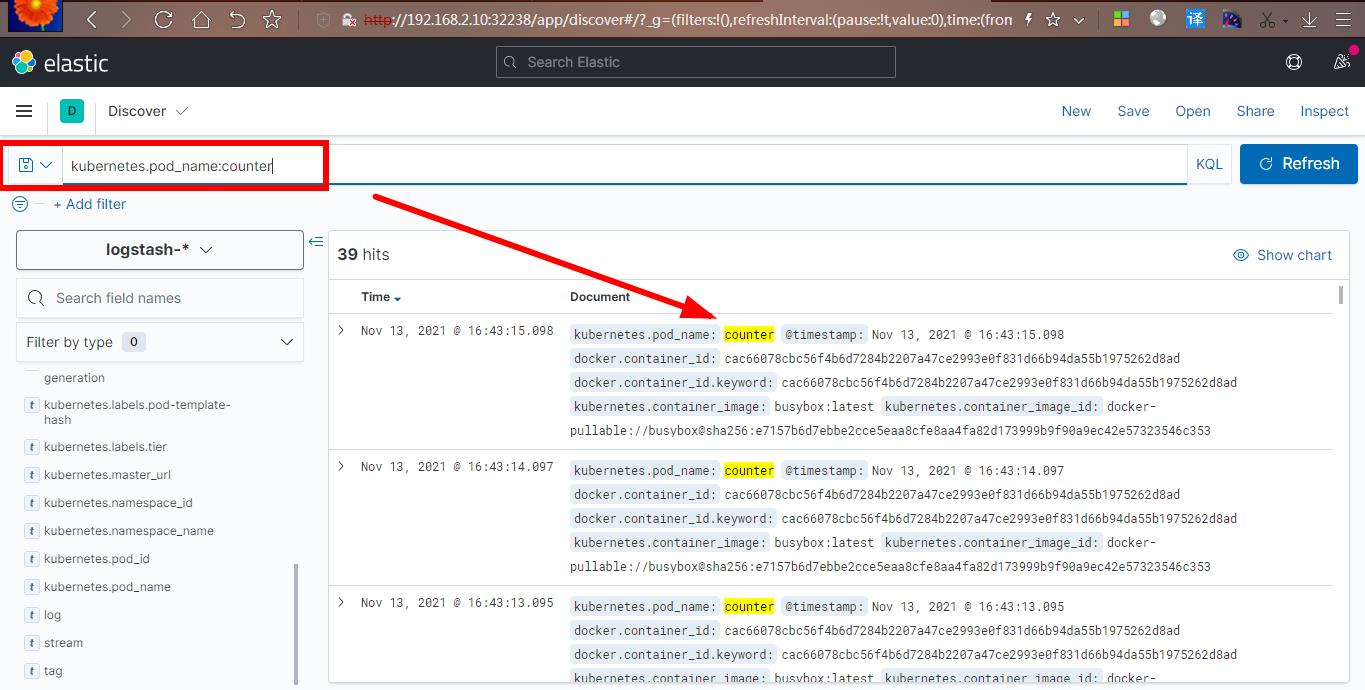
更新 yaml 后,登录到 kibana 的控制面板,在 discover 处的搜索栏中输入 kubernetes.pod_name:counter,这将过滤名为的 Pod 的日志数据 counter,如下所示:
以上是关于k8s 部署智能化日志收集平台的主要内容,如果未能解决你的问题,请参考以下文章