Sklearn机器学习基础(day01基本数据处理)
Posted HUTEROX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sklearn机器学习基础(day01基本数据处理)相关的知识,希望对你有一定的参考价值。
文章目录
环境
python 3.7
sklearn
numpy
scipy
pip3 install numpy
pip3 install scipy
pip3 install sklearn
(本文为笔记整理)
数据集
sklearn 自带一些常用的数据集帮助我们进行相关的测试。
sklearn.datasets
load_* 获取小规模数据集
fetch_* 获取大规模数据集
sklearn小数据集
sklearn.datasets.load_iris()
sklearn大数据集 sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
这里注意的是获取大数据集其实是从对应的网站下载的,data_home 是指那个对应的下载保持目录(有默认的) subset 是指你要下载哪一些东西
test 表示要测试数据 all 表示要test和train训练好的都要。
例子:
from sklearn.datasets import load_iris
Iris = load_iris()
print("查看数据描述:",Iris["DESCR"])
print("查看特征值名字:",Iris.feature_name)
print("查看特征值:",Iris.data)
print("查看数据集: ",Iris)
这个数据集是关于那个 鸢尾(花) 的样子的数据集合
特征提取
作用:将其他的数据类型(例如 文本) 按照特定的算法进行“扁平化处理”,即转化为特定的规律的具备”关系“的矩阵
字典特征提取
这个的作用其实就是把字典类型的数据转化为矩阵,这样一来方便相关的运算,那么字典特征提取就是类似的算法。
直接举个例子就懂了:
data = [{"city":"北京","template":25},
{"city":"上海","template":55},
{"city":"南昌","template":45}
]
直接查看处理好之后的数值:
特征名字: ['city=上海', 'city=北京', 'city=南昌', 'template']
特征值: [[ 0. 1. 0. 25.]
[ 1. 0. 0. 55.]
[ 0. 0. 1. 45.]
]
当然这个是没有压缩的展现效果,如果压缩了,那就是一个压缩矩阵
特征名字: ['city=上海', 'city=北京', 'city=南昌', 'template']
特征值: (0, 1) 1.0
(0, 3) 25.0
(1, 0) 1.0
(1, 3) 55.0
(2, 2) 1.0
(2, 3) 45.0
ok那么这里直接看代码:
from sklearn.feature_extraction import DictVectorizer
def DictVectorizer_Test():
data = [{"city": "北京", "template": 25},
{"city": "上海", "template": 55},
{"city": "南昌", "template": 45}
]
transfer = DictVectorizer()
new_data = transfer.fit_transform(data)
print("特征名字:",transfer.get_feature_names())
print("特征值:",new_data)
我们这里最重要的就是用到了这个 DictVectorizer
文本特征提取
既然已经大致知道了这个特征提取是啥子东西,那么我们接下来就来看看对于,文本进行特征提取。
那么关于文本提取 sklearn 主要有两种比较有名的玩意,同时处理文本的时候又分为,英文处理和中文处理。
一个一个来。
One-Hot 编码
大道理就不说了,直接说效果吧,那就是这个可以吧一句话当中出现的单词的频率统计出来。至于有啥用,那作用多了去了。
直接举个例子:
data = ["life is short i like python","python is great but i prefer golan
处理之后的结果:
特征名字: ['but', 'golang', 'great', 'is', 'life', 'like', 'prefer', 'python', 'short']
特征值: [
[0 0 0 1 1 1 0 1 1]
[1 1 1 1 0 0 1 1 0]
]
同样这个也是没有压缩的,压缩后效果和上面类似。
代码
from sklearn.feature_extraction.text import CountVectorizer
def CountVertorizer_Test():
data = ["life is short i like python","python is great but i prefer golang"]
tranfer = CountVectorizer()
new_data = tranfer.fit_transform(data)
print("特征名字:",tranfer.get_feature_names())
print("特征值:",new_data.toarray())
中文文本处理
这边我们还是举个例子,用 one-hot 编码处理一下。
这里的话我们需要使用到一个第三方库 jieba
这个玩意主要是做中文分割的。
直接上代码:
def To_Chinese_World(worlds):
"""
返回一个切个好的中文数组
:param worlds:
:return:
"""
index = 0
for word in worlds:
worlds[index] = " ".join(list(jieba.cut(word)))
index+=1
def CountVectorizer_Chinese(data):
To_Chinese_World(data)
tranfer = CountVectorizer()
new_data = tranfer.fit_transform(data)
print("特征名字:",tranfer.get_feature_names())
print("特征值:",new_data.toarray())
if __name__ == '__main__':
data = ["我爱大中华,我是中国人"]
CountVectorizer_Chinese(data)
TF-IDF 处理
这个其实也是用来对文本进行特征提取的。不过这里的主要作用是用来提取关键词的。
关键词定义:在当前的文本当中出现的频率极高,但是在其他的文本当中出现的频率极低。具备非常明显的分类属性
那么这个 TF - IDF 就是用来处理这件事情的。
运算规则
这个算法的运算规则还是比较简单的。举个例子:
data = [
"water water water x",
"apple apple apple x",
"pear pear pear x",
]
假设每一个字符串都是一个文本 那么很明显关键词一次是:
water apple pear
那么要想实现这个效果首先是这样运算的
TF 是同频,例如 apple 在 "apple apple apple x"出现的频率 这里是3/4
IDF 是逆文档频率 例如 apple 在 三个字符串当中有哪几个字符串是有 apple的,这里是 1 那么 IDF = lg (3/1)
TF-IDF = TF * IDF
代码
from sklearn.feature_extraction.text import TfidfVectorizer
def TFIDFVectorizerTest():
data = [
"water water water x",
"apple apple apple x",
"pear pear pear x",
]
transfer = TfidfVectorizer()
new_data = transfer.fit_transform(data)
print("特征名字:",transfer.get_feature_names())
print("特征值:",new_data.toarray())
结果:
特征名字: ['apple', 'pear', 'water']
特征值: [
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]
]
此时一目了然 第一个关键词是 water 以此类推
到这里你自己都可以实现一个简单的文章分类器了。
数据预处理
归一化
这个老熟悉了,作用就是统一衡量,也就是无量纲化,这个在神经网络的数值预测里面还是很重要的,当初数学建模的时候要是没有归一化处理数据,BP神经网络直接死那了。
对应的归一化的算法也很多,看你喽,最简单的就是:
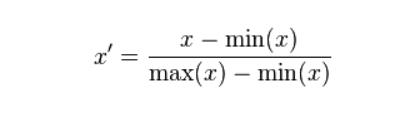
这个也是最典型的,所有的数据的范围都在(0,1)之间。
对应API
sklearn.preprocrssing.MinMaxScaler
直接举个例子:
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import pandas as pd
def MinMaxScalerTest():
"""
归一化
:return:
"""
# 1、获取数据只要前三列,\\t 是为了正常输出
data = pd.read_csv("dating.txt",sep="\\t")
data = data.iloc[:, :3]
print("data:\\n", data)
# 2、实例化一个转换器类
#transfer = MinMaxScaler(feature_range=[2, 3])
transfer = MinMaxScaler(feature_range=[2, 3])
#默认[0,1]
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\\n", data_new)
数据集:
链接:https://pan.baidu.com/s/1Q-4zKBx3ICFNLmGbmVsoPQ
提取码:6666
data:
milage Liters Consumtime
0 40920 8.326976 0.953952
1 14488 7.153469 1.673904
2 26052 1.441871 0.805124
3 75136 13.147394 0.428964
4 38344 1.669788 0.134296
.. ... ... ...
995 11145 3.410627 0.631838
996 68846 9.974715 0.669787
997 26575 10.650102 0.866627
998 48111 9.134528 0.728045
999 43757 7.882601 1.3324
data_new:
[[0.44832535 0.39805139 0.56233353]
[0.15873259 0.34195467 0.98724416]
[0.28542943 0.06892523 0.47449629]
...
[0.29115949 0.50910294 0.51079493]
[0.52711097 0.43665451 0.4290048 ]
[0.47940793 0.3768091 0.78571804]]
标准化
由于归一化很容易受到超大数据的干扰,稳定性较差(在数据相差较大的场景当中)所以我们这里还有一个叫做标准化。
x* = (x - μ ) / σ
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
此外
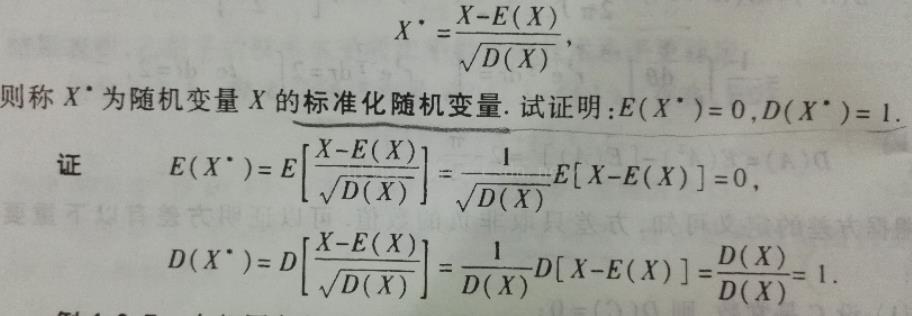
z-score 标准化后的数据标准差为1
没关系不懂调 API 就好。
sklearn.preprocrssing.StandarScaler
例子:
def StandardScalerTest():
data = pd.read_csv("dating.txt",sep="\\t")
data = data.iloc[:, :3]
print("data:\\n", data)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\\n", data_new)
其实你发现调用规则都是一样的,就是算子不同(用Flink的话来说)
降维
降低数据的维度。其实和数据结构里面的那个矩阵存储不一样。
因为我们前面处理的都是使用二维数组来搞的,对于高维的我们必然是要搞到二维里面去的。有点像“拍扁”。也就是说,我们会损失一部分的数据(减少不必要的数据干扰项,减少数据冗余),来实现“拍扁”。
特征选择
大白话:从原有特征当中找出主要特征。
Filter 过滤方式
数据集:
链接:https://pan.baidu.com/s/1uj6cuR0P6lZLDOm35jKm9A
提取码:6666
低方差过滤
计算方差,把方差低的过滤不要
from sklearn.feature_selection import VarianceThreshold
def VarianceThresholdTest():
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1:-2] #有些数据不要,有些列,例如第一列
print("data:\\n", data)
transfer = VarianceThreshold(threshold=10)
data_new = transfer.fit_transform(data)
print("data_new:\\n", data_new, data_new.shape)
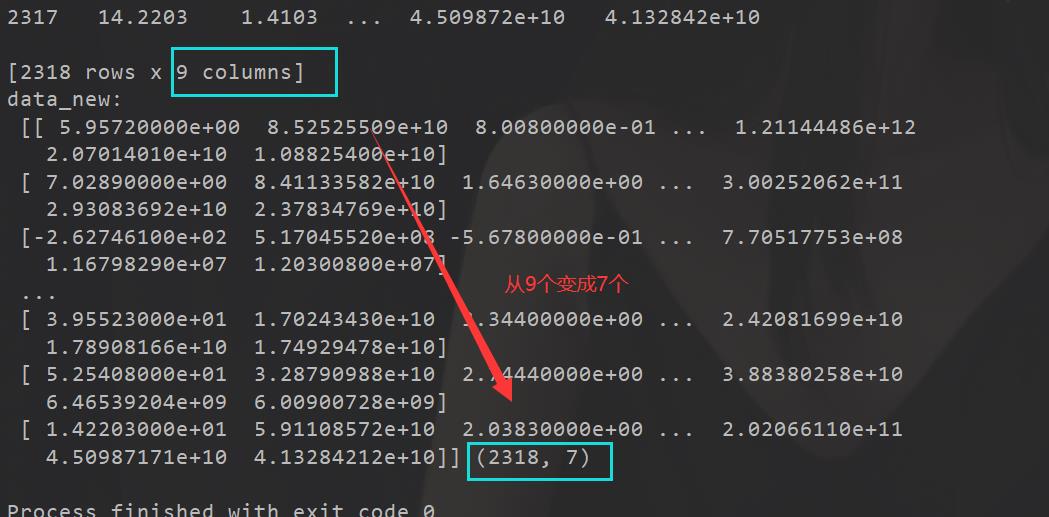
png)]
相关系数
这个我们要避免冗余呗,所以相关系数太近直接处理然后pass
这个相关系数怎么求,把两两的特征作为x ,y 然后求取相关性系数呗。这个怎么算,查查百度或者去问问高中数学老师去呗。
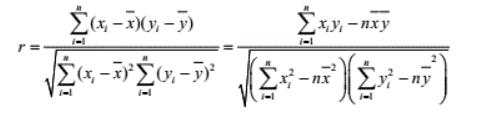
这里还是上例子吧:
from scipy.stats import pearsonr
# 计算某两个变量之间的相关系数
r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])
print("相关系数:\\n", r1)
r2 = pearsonr(data['revenue'], data['total_expense'])
print("revenue与total_expense之间的相关性:\\n", r2)
那么之后怎么做还用我说吗,直接for循环比较筛选出特征,然后那啥从data里面筛选。
主成分分析 PCA
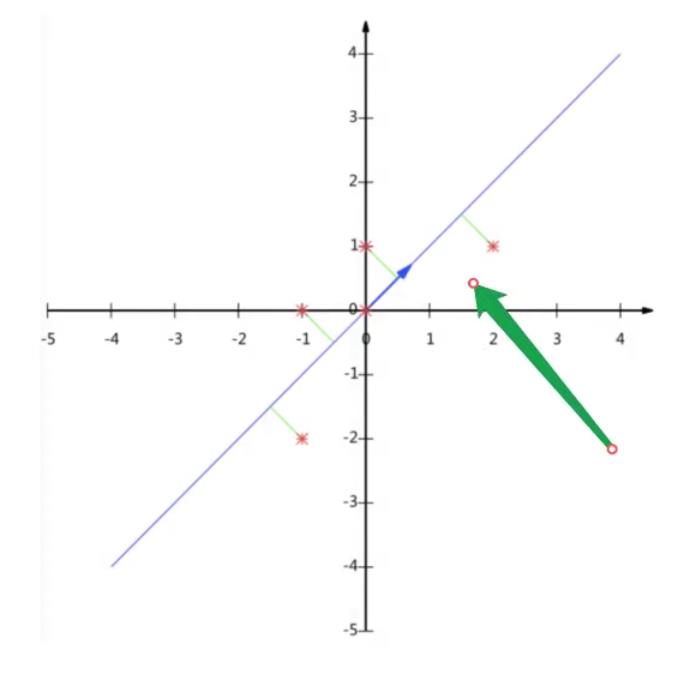
大白话:高维变低纬,但是这个过程当中可能会舍弃原有数据并创造新的数据,有可能损失信息。作用就是压缩数据,应用,聚类分析,回归分析。
举个例子
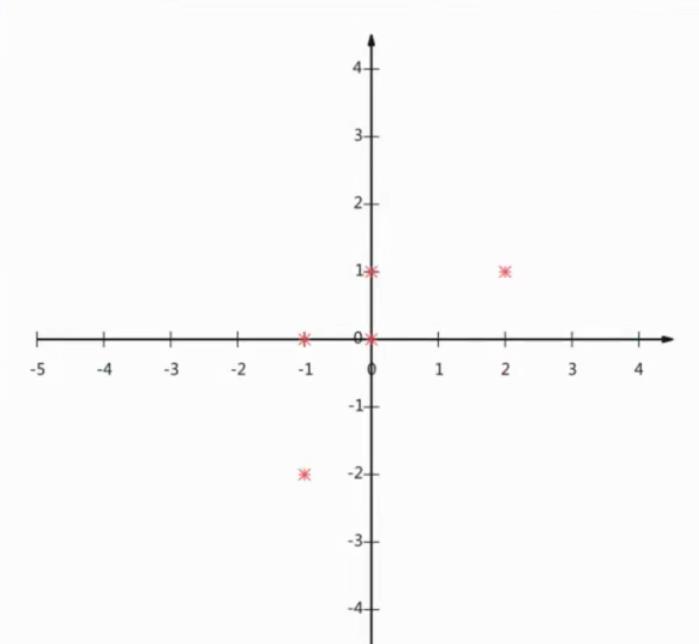
现在把这个压缩到一条直线并且尽可能地去贴合原有特征。

def PCATest():
"""
PCA降维
:return:
"""
data = [[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]]
# 1、实例化一个转换器类
transfer = PCA(n_components=0.95)
# n_components=0.95 保留 95%特征 如果传入整数就是减少到多少空间也就是降到几维度 n_components=2
data_new = transfer.fit_transform(data)
print("data_new:\\n", data_new)
小结
好好学习,天天向上,自己选的路死都要走下去!
以上是关于Sklearn机器学习基础(day01基本数据处理)的主要内容,如果未能解决你的问题,请参考以下文章