DCTCP之FCT优化随想
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DCTCP之FCT优化随想相关的知识,希望对你有一定的参考价值。
IDC网络和广域网有什么不同?如果把网络抽象成BDP管道,那么:
- 广域网:B中等,D超级大。
- IDC网络:B超级大,D超级小。
将一次传输的RTT分为三部分:
R T T = T p r o c e s s + T p r o p + T q u e u e RTT=T_{process}+T_{prop}+T_{queue} RTT=Tprocess+Tprop+Tqueue
对于广域网, T p r o p T_{prop} Tprop维持在10ms~100ms量级,因此可以通过观测或者调整1ms~50ms量级的 T q u e u e T_{queue} Tqueue来进行拥塞控制。
对于IDC网络, T p r o p T_{prop} Tprop维持在1us~100us量级,但 T q u e u e T_{queue} Tqueue依然是1ms~50ms量级,这意味着交换机拥塞排队将会导致RTT产生10倍到百倍的飙升,产生严重的业务抖动。
雪上加霜的是,由于IDC网络的超高带宽,这意味着轻微的突发都可能导致严重的拥塞排队,使得抖动更容易发生,这实属一种悲哀。
因此,IDC网络的拥塞控制策略必须改变。和传统拥塞控制的目标不同,IDC网络根本没有时间等待 T q u e u e T_{queue} Tqueue的反馈,与之相反,它必须严格控制 T q u e u e T_{queue} Tqueue在极小的阈值之下。
总的来讲,广域网的 T p r o p T_{prop} Tprop占大头,因此可以忽略 T p r o c e s s T_{process} Tprocess,并利用 T q u e u e T_{queue} Tqueue反馈做cc,对于IDC而言, T p r o p T_{prop} Tprop和 T p r o c e s s T_{process} Tprocess差不多, T q u e u e T_{queue} Tqueue是全局敏感量,必须限制在阈值内,同时针对 T p r o c e s s T_{process} Tprocess做优化。
从云原生看IDC网络,结论依然不变。
在云原生环境,IDC内部遍布微服务,IDC网络更重要的职责在微服务调用间的消息传递而非大块数据传输,数据传输更多的是要解决数据同步等分布式一致性问题。消息传递只有一个需求,低延时!
DCTCP是IDC内部的算法,它的目标:
- 保持低时延。
- 长流不损害短流。
- 长流保持高吞吐。
支持ECN的交换机在排队超过阈值 K K K时会对TCP数据包进行标记,该标记通过接收端的ACK回送到发送端,DCTCP会采集被标记数据包的比例 F F F,采用下面的公式控制拥塞窗口:
α = ( 1 − g ) × α + F × α \\alpha=(1-g)\\times\\alpha+F\\times\\alpha α=(1−g)×α+F×α
W = ( 1 − α 2 ) W W=(1-\\dfrac{\\alpha}{2})W W=(1−2α)W
可见以下特性:
- 若无拥塞, F F F为0, α \\alpha α逐渐平滑到0, W W W保持。
- 若有拥塞, F F F增加, α \\alpha α逐渐增大, W W W减小。
- 拥塞越剧烈, F F F越大, α \\alpha α越大, W W W减小越剧烈。
和广域网上拥塞窗口陡然变化不同,DCTCP更有利于发现突然的变化并无级变速。但这种策略不利于突发短流:
- 突发短流开始前,长流的 α \\alpha α已经平滑到0,多条短流突发导致拥塞, α \\alpha α的移指平均导致长流 W W W下降过缓,新的短流受到抑制。
谁需要为拥塞负责是个问题。
站在业务的角度,突发短流的FCT指标更重要,而不是带宽利用率,公平收敛等传统指标,比如数量众多的pingpong查询流,而长流反而是可适当延迟的背景流量。因此最短完成优先,最短总时间优先可能是更好的策略。
如何利好突发短流呢?一个想法是,惩罚长流,变相优待短流。
在
α
\\alpha
α的移指计算中引入一个参数
t
t
t,即连接建议到现在的时间,
t
t
t的演化
f
(
t
)
f(t)
f(t)使
α
\\alpha
α满足:
- t t t越小, α \\alpha α越接近标准DCTCP算法的结果
- t t t越大, α \\alpha α相比标准DCTCP算法的结果越偏大。
类似下面的函数是满足要求的:
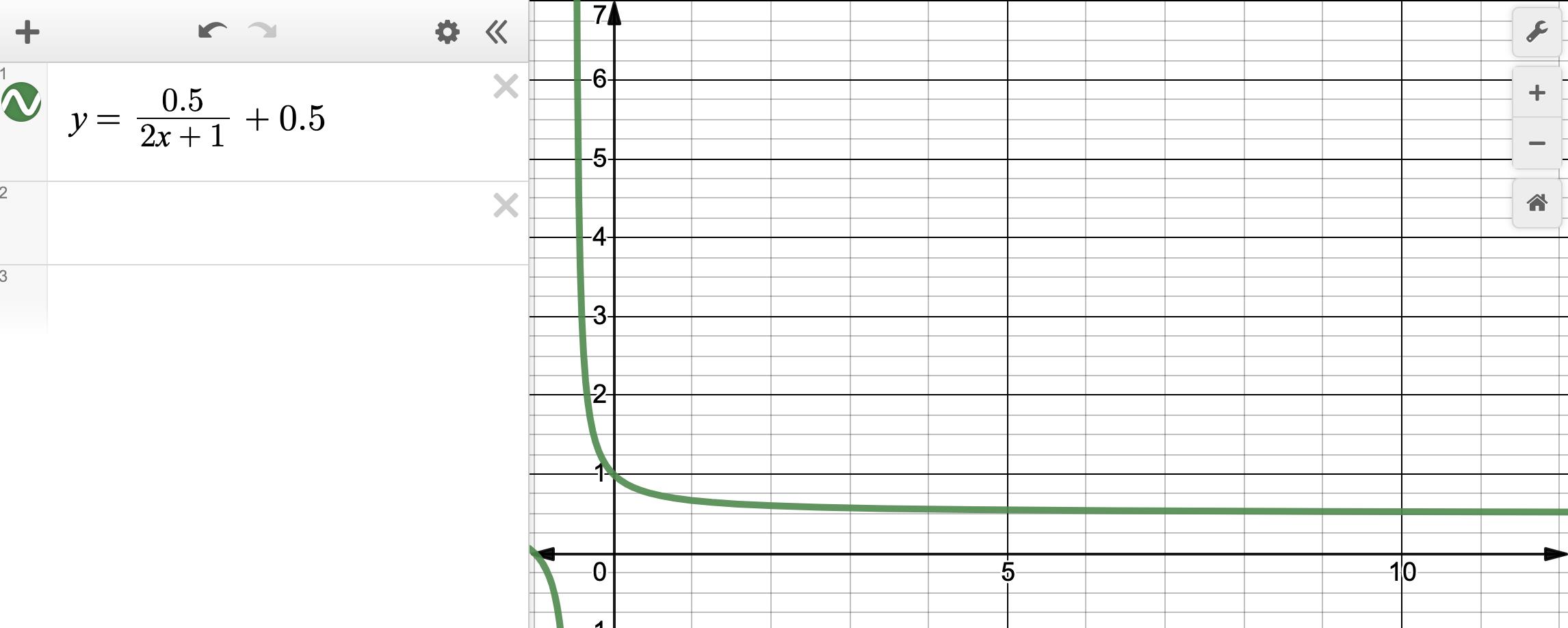
y = 0.5 2 x + 1 + 0.5 y=\\frac{0.5}{2x+1}+0.5 y=2x+10.5+0.5
下面是它的图像:
新的 α \\alpha α移指表达式为:
α = ( 1 − g ∗ f ( t ) ) × α + F × α \\alpha=(1-g*f(t))\\times\\alpha+F\\times\\alpha α=(1−g∗f(t))×α+F×α
它需要满足:
- 当 t t t为0时, f ( t ) = 1 f(t)=1 f(t)=1,维持和标准DCTCP一致。
- 当 t t t大于0时,稍微陡峭不要太缓慢地减少。
- f ( t ) f(t) f(t)以 y = k > 0 y=k>0 y=k>0为渐近线,保证 α \\alpha α可以平滑到0。
这就修正了标准DCTCP平等对待所有流的问题,利好短流FCT。
我的观点依然是:
- 广域网的拥塞控制一视同仁,网络简单些,端到端复杂些。
- IDC的拥塞控制需要区分业务,网络复杂些,端到端简单些。
- IDC交换机回送ECN标识本身就可以让不同类型的流区分对待。
- IDC网络是协作非博弈网络,无需无条件公平收敛保证。
你是怎么想的呢?欢迎讨论,有机会赢温州名牌皮鞋👞!
PS:Linux内核的DCTCP的实现并没有根据ECN标记实时调整拥塞窗口,而只是在检测到丢包时才作出反应。这背后的假设依然是丢包作为拥塞的信号。这和ECN相悖,ECN的意思是,交换机通过显式的通知告诉发送端发生了拥塞,而不是丢包,否则包都丢了,谁负责通知呢?所以,Linux的DCTCP算法需要修改,别总觉得能发一个包就多发一个包,反正能等到丢包信号,这不还是传统的广域网拥塞控制思维吗?要改。
传统意义的拥塞控制是针对运营商的广域网用户而言的,其目标在于公平收敛,提高带宽利用率,毕竟互联网第一次拥塞崩溃事件就发生在广域网,拥塞控制控制由此诞生。
对于IDC网络,强交互特征意味着它更关注低延时而不是传输效能,但传统的拥塞控制策略并不能有效降低延时,这意味着挑战,也意味着新的趣味。周末随便写点与此有关的东西,就有了本文。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于DCTCP之FCT优化随想的主要内容,如果未能解决你的问题,请参考以下文章