秒懂+史上最全:JVM进程Java进程的用户空间与内核空间如何区分? 如何区分Java进程的内核态与用户态?
Posted 架构师-尼恩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了秒懂+史上最全:JVM进程Java进程的用户空间与内核空间如何区分? 如何区分Java进程的内核态与用户态?相关的知识,希望对你有一定的参考价值。
文章很长,建议收藏起来慢慢读!疯狂创客圈总目录 语雀版 | 总目录 码云版| 总目录 博客园版 为您奉上珍贵的学习资源 :
-
免费赠送 经典图书:《Java高并发核心编程(卷1)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Java高并发核心编程(卷2)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《SpringCloud Nginx高并发核心编程》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
推荐:入大厂 、做架构、大力提升Java 内功 的 精彩博文
| 入大厂 、做架构、大力提升Java 内功 必备的精彩博文 | 2021 秋招涨薪1W + 必备的精彩博文 |
|---|---|
| 1:Redis 分布式锁 (图解-秒懂-史上最全) | 2:Zookeeper 分布式锁 (图解-秒懂-史上最全) |
| 3: Redis与MySQL双写一致性如何保证? (面试必备) | 4: 面试必备:秒杀超卖 解决方案 (史上最全) |
| 5:面试必备之:Reactor模式 | 6: 10分钟看懂, Java NIO 底层原理 |
| 7:TCP/IP(图解+秒懂+史上最全) | 8:Feign原理 (图解) |
| 9:DNS图解(秒懂 + 史上最全 + 高薪必备) | 10:CDN图解(秒懂 + 史上最全 + 高薪必备) |
| 11: 分布式事务( 图解 + 史上最全 + 吐血推荐 ) | 12:seata AT模式实战(图解+秒懂+史上最全) |
| 13:seata 源码解读(图解+秒懂+史上最全) | 14:seata TCC模式实战(图解+秒懂+史上最全) |
| Java 面试题 30个专题 , 史上最全 , 面试必刷 | 阿里、京东、美团… 随意挑、横着走!!! |
|---|---|
| 1: JVM面试题(史上最强、持续更新、吐血推荐) | 2:Java基础面试题(史上最全、持续更新、吐血推荐 |
| 3:架构设计面试题 (史上最全、持续更新、吐血推荐) | 4:设计模式面试题 (史上最全、持续更新、吐血推荐) |
| 17、分布式事务面试题 (史上最全、持续更新、吐血推荐) | 一致性协议 (史上最全) |
| 29、多线程面试题(史上最全) | 30、HR面经,过五关斩六将后,小心阴沟翻船! |
| 9.网络协议面试题(史上最全、持续更新、吐血推荐) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
| SpringCloud 精彩博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| SpringCloud gateway (史上最全) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
高可用中间件的 原理与实操 实战 视频背景:
下一个视频版本,从架构师视角,尼恩为大家打造高可用、高并发中间件的原理与实操。
目标:通过视频和博客的方式,为各位潜力架构师,彻底介绍清楚架构师必须掌握的高可用、高并发环境,包括但不限于:
-
高可用、高并发nginx架构的原理与实操
-
高可用、高并发mysql架构的原理与实操
-
高可用、高并发nacos架构的原理与实操
-
高可用、高并发rocketmq架构的原理与实操
-
高可用、高并发es架构的原理与实操
-
高可用、高并发minio架构的原理与实操
why 高可用、高并发中间件的原理与实操:
- 实际的开发过程中,很多小伙伴,常常是埋头苦干,聚焦crud开发,复杂一点的环境出了问题,都不能自己去启动,出了问题,就想热锅上的蚂蚁,无从下手。
- 常常的现象是: 大家 低头看路的时间多,抬头看天的时间少,技术视野比较狭窄。常常是埋头苦干业务开发,很少投入精力进行技术提升。
- 作为架构师,或者未来想走向高端开发,或者做架构,必须掌握高可用、高并发中间件的原理,掌握其实操。
本系列博客的具体内容,请参见 疯狂创客圈总目录 语雀版 | 总目录 码云版| 总目录 博客园版
插曲:由于高可用中间件 涉及到非常多的底层原理,作为铺垫,先给大家来点 底层原理的知识
Java进程的用户空间与内核空间如何区分? 如何区分Java进程的内核态与用户态度?
社群的交流如下:
已知:java线程是和操作系统线程一一对应
问题:java线程在用户空间还是在内核空间?
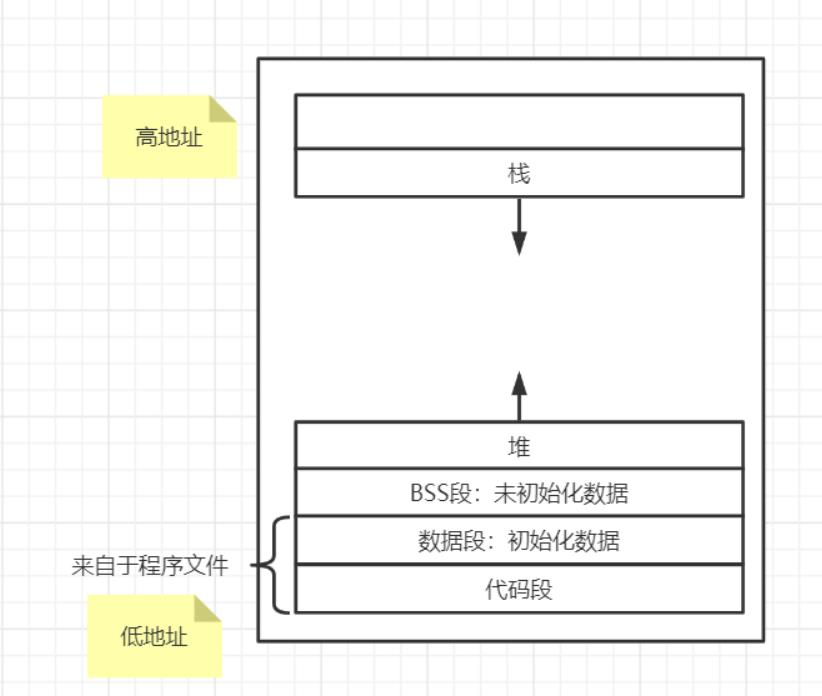
用户空间的构成
-
**运行时栈:**由编译器自动释放,存放函数的参数值,局部变量和方法返回值等。每当一个函数被调用时,该函数的返回类型和一些调用的信息被存储到栈顶,调用结束后调用信息会被弹出并释放掉内存。
栈区是从高地址位向低地址位增长的,是一块连续的内在区域,最大容量是由系统预先定义好的,申请的栈空间超过这个界限时会提示溢出,用户能从栈中获取的空间较小。
-
**运行时堆:**用于存放进程运行中被动态分配的内存段,位于 BSS 和栈中间的地址位。由卡发人员申请分配(malloc)和释放(free)。堆是从低地址位向高地址位增长,采用链式存储结构。
频繁地 malloc/free 造成内存空间的不连续,产生大量碎片。当申请堆空间时,库函数按照一定的算法搜索可用的足够大的空间。因此堆的效率比栈要低的多。
-
**代码段:**存放 CPU 可以执行的机器指令,该部分内存只能读不能写。通常代码区是共享的,即其他执行程序可调用它。假如机器中有数个进程运行相同的一个程序,那么它们就可以使用同一个代码段。
-
**未初始化的数据段:**存放未初始化的全局变量,BSS 的数据在程序开始执行之前被初始化为 0 或 NULL。
-
**已初始化的数据段:**存放已初始化的全局变量,包括静态全局变量、静态局部变量以及常量。
-
**内存映射区域:**例如将动态库,共享内存等虚拟空间的内存映射到物理空间的内存,一般是 mmap 函数所分配的虚拟内存空间。
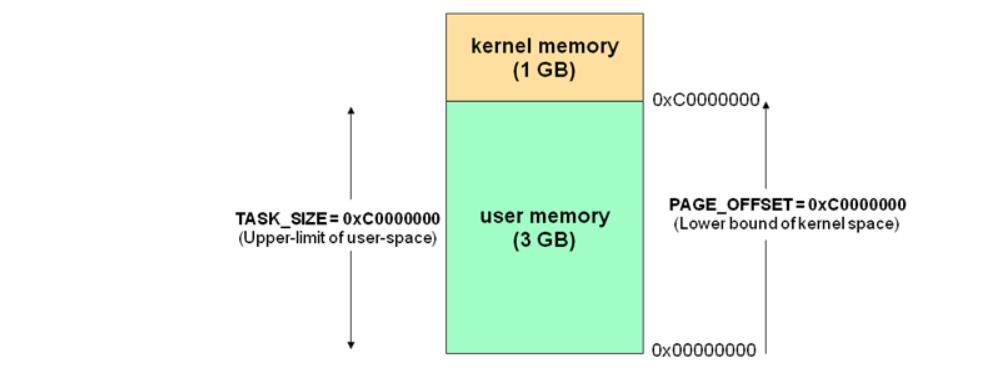
用户空间与内核地址空间和划分(以32位CPU为例)
最高的 1G 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF)由内核态使用,称为内核空间。而较低的 3G 字节(从虚拟地址 0x00000000 到 0xBFFFFFFF)由各个进程使用,称为用户空间。
32位Linux内核地址空间划分03G为用户空间,34G为内核空间。
注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的
用户空间和内核空间的详细内存布局:
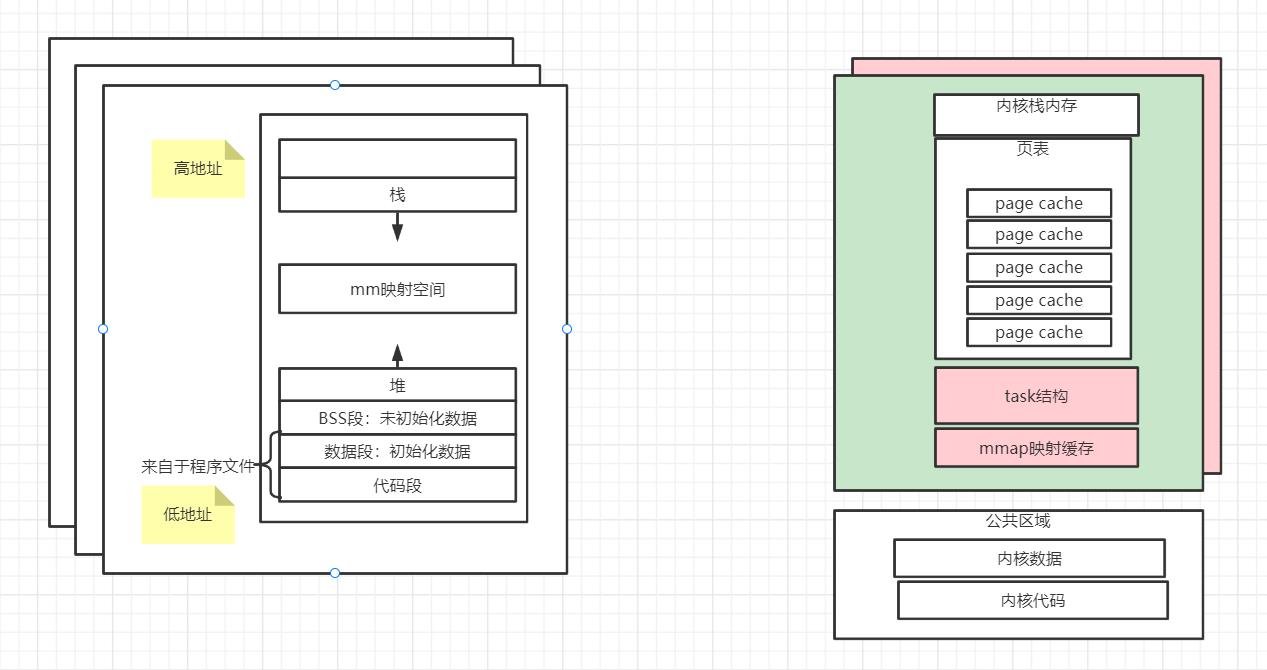
为什么要划分用户空间和系统空间呢?
- 第一点,分开存放,管理上很方便。
不同的身份,数据放置的位置必然不一样,否则大混战就会导致系统的数据和用户的数据混在一起,系统就不能很好的运行了。
分开来存放,就让系统的数据和用户的数据互不干扰,保证系统的稳定性。
- 第二点,对两部分的数据的访问进行分开控制。
而更重要的是,将用户的数据和系统的数据隔离开,就可以对两部分的数据的访问进行控制。
这样就可以确保用户程序不能随便操作系统的数据,这样防止用户程序误操作或者是恶意破坏系统。
区分内核空间和用户空间本质上是要提高操作系统的稳定性及可用性。
谁来划分内存空间的呢?
在电脑开机之前,内存就是一块原始的物理内存。什么也没有。
- 划分的时机
开机加电,系统启动后,就对物理内存进行了划分。
- 逻辑上划分
划分内存空间的规则这是系统的规定,物理内存条上并没有划分好的地址和空间范围。这些划分都是操作系统在逻辑上的划分。
不同版本的操作系统划分的结果都是不一样的。
进程的内核态与用户态
内核态:
当进程(或者线程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态(或简称为内核态)。
此时处理器处于特权级最高的(0级)内核代码中执行。
- 特点:
CPU可以访问内存所有数据,包括外围设备(硬盘、网卡),允许访问内核空间、用户空间,CPU也可以将自己从一个程序切换到另一个程序;
用户态:
当进程(或者线程)在执行用户自己的代码时,则称其处于用户运行态(用户态)。
即此时处理器在特权级最低的(3级)用户代码中运行。
当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。这与处于内核态的进程的状态有些类似。
- 特点:
只能受限的访问内存,且不允许访问外围设备,不容许访问内核空间,占用CPU的能力被剥夺,CPU资源可以被其他程序获取;
进程上下文context:
上下文context简单说来就是一个环境。
用户空间的应用程序,通过系统调用,进入内核空间。
这个时候用户空间的进程要传递 很多变量、参数的值给内核,内核态运行的时候也要保存用户进程的一些寄存 器值、变量等。
所谓的“进程上下文”,可以看作是用户进程传递给内核的这些参数以及内核要保存的那一整套的变量和寄存器值和当时的环境等。
相对于进程而言,就是进程执行时的环境。
具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。
一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文。
(1)用户级上下文: 正文、数据、用户堆栈以及共享存储区;
(2)寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
(3)系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
当发生进程调度时,进行进程切换就是上下文切换(context switch).
操作系统必须对上面提到的全部信息进行切换,新调度的进程才能运行。
而系统调用进行的模式切换(mode switch)。
模式切换与进程切换比较起来,容易很多,而且节省时间,因为模式切换最主要的任务只是切换进程寄存器上下文的切换。
用户态和内核态的切换涉及的CPU上下文切换
我们都知道,Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。
而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。
而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。
它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
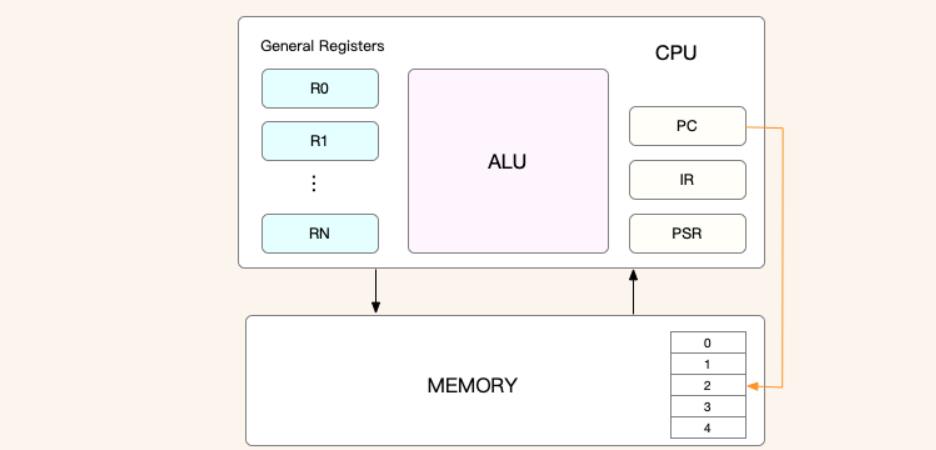
pc 程序计数器, 指向当前指令的下条指令的地址
lr 链接寄存器, 程序调用返回地址
psr 当前程序状态寄存
知道了什么是 CPU 上下文,我想你也很容易理解 CPU 上下文切换。
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
用户态和内核态的切换涉及的CPU上下文切换
第一次切换:
CPU寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
第二次切换:
而系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次CPU上下文切换。
不过,需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。
Linux 系统调用的中断处理流程
Linux的系统调用概述
- 系统调用(陷阱)是特殊异常事件,是OS为用户程序提供服务的手段
- Linux提供了几百种系统调用,主要分为以下几类:进程控制,文件操作,文件系统操作,系统控制,内存管理,网络管理,用户管理,进程通信等
- 系统调用号是系统调用跳转表索引值,跳转表给出系统调用服务例程首地址。
Linux的系统调用执行流程
-
Linux 系统为每一个系统调用准备了一个号码,为系统调用号,对于32bit系统而言:exit 为 1, write 为4等。
-
每当应用程序调用系统调用函数时,如write,首先到 C 库中,(glibc中),调用对应的函数 write。
-
C库中的writehansh ,将对应的调用号保存到对应的寄存器中,一般是R7寄存器。然后调用 SWI(old)或者SVC(new),触发一个异常(软中断),CPU需处理该异常(软中断),需跳转到异常向量表的对应位置去处理。
-
Linux 系统的异常向量表是在内核启动初始化时,会建立异常向量表(向量表初始地址是0XFFFF0000),软中断入口为 vector_swi,应用程序触发了软中断,然后CPU会到该入口去处理这个软中断。
5,进入到软中断 vector_swi入口之后,从R7寄存器中取出之前保存的系统调用号,然后在内核已经准备好的以系统调用号为索引下标的系统调用表中,找到对应的系统调用函数,(如果是4号 write,则对应的系统调用是sys_write),然后执行,(此时已经进入了内核空间)。
- 返回用户空间。
总结:用户空间到内核空间,是通过软中断实现的,其中的桥梁就是C库实现的对应的“系统调用”中产生的对应的系统调用号,已经使用该系统调用号作为索引的异常向量表。
实例:Linux系统中printf()函数的执行过程
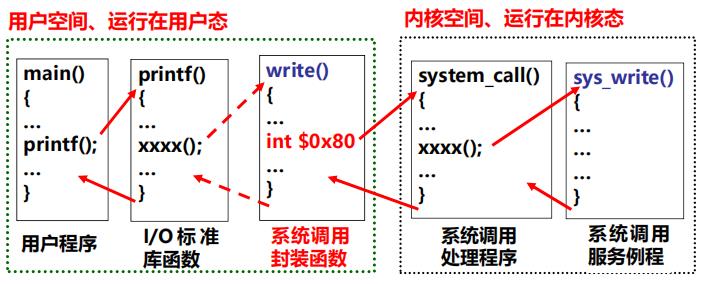
软中断指令int $0x80的执行过程,它是陷阱类(编程异常)事件,因此它与异常响应过程一样。
- 将IDTi(i=128)中段选择符(0x60)所指GDT中的内核代码段描述符取出, 其DPL=0,此时CPL=3(因为int $0x80指令在用户进程中执行),因而CPL>DPL且IDTi 的 DPL=CPL,故未发生13号异常。
- 读 TR 寄存器,以访问TSS,从TSS中将内核栈的段寄存器内容和栈指针装入SS和ESP;
- 依次将执行完指令int $0x80时的SS、ESP、EFLAGS、CS、EIP的内容(即断点和程序状态)保存到内核栈中,即当前SS∶ESP所指之处;
- 将IDTi(i=128)中段选择符(0x60)装入CS,偏移地址装入EIP。这里,CS:EIP即是系统调用处理程序system_call(所有系统调用的入口程序)第一条指令的逻辑地址
执行int $0x80需一连串的一致性和安全性检查,因而速度较慢。
从Pentium II开始,Intel引入了指令sysenter和sysexit,分别用于从用户态到内核态、从用户态到内核态的快速切换。
用户态和内核态的切换耗费时间的原因
当程序中有系统调用语句,程序执行到系统调用时,首先使用类似int 80H的软中断指令,保存现场,去系统调用,在内核态执行,然后恢复现场,每个进程都会有两个栈,一个内核态栈和一个用户态栈。
当int中断执行时就会由用户态栈转向内核态栈。
系统调用时需要进行栈的切换。而且内核代码对用户不信任,需要进行额外的检查。系统调用的返回过程有很多额外工作,比如检查是否需要调度等。
进程需要从用户态切换到内核态,而这种切换是需要消耗很多时间的,有可能比用户执行代码的时间还要长。
常见的Java涉及用户态和内核态的切换的操作
- io操作
- 线程操作,如线程的创建,线程切换
- java程序的加锁和解锁
- 内存分配 malloc()
Java堆内存的一次网络 Send 操作
线程上下文切换
Linux内核在2.2版本中引入了类似线程的机制。
Linux提供的vfork函数可以创建线程,此外Linux还提供了clone来创建一个线程,通过共享原来调用进程的地址空间,clone能像独立线程一样工作。
Linux内核的独特,允许共享地址空间,clone创建的进程指向了父进程的数据结构,从而完成了父子进程共享内存和其他资源。
clone的参数可以设置父子进程共享哪些资源,不共享哪些资源。
进程还是线程的创建都是由父进程/父线程调用系统调用接口实现的。
创建的主要工作实际上就是创建task_strcut结构体,并将该对象添加至工作队列中去。
而线程和进程在创建时,通过CLONE_THREAD flag的不同,而选择不同的方式共享父进程/父线程的资源,从而造成在用户空间所看到的进程和线程的不同。
实质上Linux内核并没有线程这个概念,或者说Linux不区分进程和线程。
Linux喜欢称他们为任务。除了clone进程以外,Linux并不支持多线程,独立数据结构或内核子程序。
线程上下文切换, 从内核的角度而已实质上,就是 进程的上下文切换,只是涉及的范围稍微窄了一点而已。
进程的上下文切换
进程是现代操作系统的核心概念之一,用于分配系统(CPU,内存)资源的使用。
了解linux进程及进程切换的知识,首先要理解进程与程序的区别:
- 进程是执行流,是动态概念;
- 程序是数据与指令序列的集合,是静态概念。
系统调用和进程上下文切换是不一样的:
进程上下文切换,是指从一个进程切换到另一个进程运行。而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
那么,进程上下文切换跟系统调用又有什么区别呢?
首先,你需要知道,进程是由内核来管理和调度的,进程的切换只能发生在内核态。
所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态,这些都属需要维护起来。
具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。
一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文。
(1)用户级上下文: 正文、数据、用户堆栈以及共享存储区;
(2)寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
(3)系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
简单来说:
进程上下文切换时间 = 用户态到内核态时间 + 保存pre进程的时间+ 加载next进程的时间 + 内核态到用户态切换时间
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成。

根据 行业的一些测试报告,每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。
这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。
举例:堆栈地址切换
linux的进程有两种栈,用户栈和内核栈,它们在不同的内存区域,用户栈在用户态中使用,在用户地址空间分配(03G),内核栈在内核态中使用,在内核地址空间分配(3G4G)。
用户栈主要用于函数调用和存储局部变量,内核栈除此之外还要保存进程切换额外的信息,如通用寄存器等。
不管是用户栈还是内核栈,CPU都是用ESP寄存器保存栈顶地址,因此早在进程切换前,进程进入内核态后,用户栈就需要被切换出去,整个切换过程,都是在内核栈上工作,因而用户栈与进程切换无关。
ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
(1)A的用户态–>A的内核态, 这一过程是由中断,异常或系统调用实现的。
每次从用户态切换到内核态,内核栈都会被清空,ESP直接指向内核栈的栈底,而用户栈的信息则会保存到内核栈中。
(2)A的内核态–>A的用户态,
执行与(1)相反的过程,从内核栈中取出(1)中保存的用户栈信息,装载相应寄存器,切换到用户栈。
回到线程上下文切换
一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文。
(1)用户级上下文: 正文、数据、用户堆栈以及共享存储区;
(2)寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
(3)系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
线程共享了父进程的系统级上下文,所以,线程的上下文切换的大致时间为:
进程上下文切换时间 = 进程上下文切换时间 - 保存pre进程的系统级上下文 - 加载pre进程的系统级上下文的时间
其中:
进程上下文切换时间 = 用户态到内核态时间 + 保存pre进程的时间+ 加载next进程的时间 + 内核态到用户态切换时间
数据结构 task_struct
以下是摘自Linux内核2.6.32版的task_struct源码。
Linux中无论是进程还是线程,只要是调度单元,都通过 struct task_struct表示。
这也是为什么讲说进程和线程在内核相同的原因。
struct task_struct有保存有关线程/进程中的一切信息,主要包括有线程/进程状态、与其他线程/进程关系、虚拟内存相关、日志相关、线程/进程限制等。该结构体定义在include/linux/sched.h文件中,感兴趣可以详细阅读
那么,进程和线程在task_struct结构体中是否有标识上的不同?
实际上,在struct task_struct中并没有明确的标识(枚举类型),区分该task是线程还是进程,不过可以通过pid和tgid简单判断当前task是哪种类型。
在该结构体中如下段code所示,全局pid和tgid保存在task_struct结构体中。pid_t一般为int型,即可以同时使用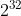 不同标识的id。
不同标识的id。
pid用于标识不同进程和线程。
tgid用于标识线程组id,在同一进程中的所有线程具有同一tgid。tgid值等于进程第一个线程(主线程)的pid值。接着以CLONE_THREAD来调用clone建立的线程,都具有同样的tgid。(后文会详细描述创建过程)
group_leader 线程组中的主线程的task_struct指针。
struct task_struct {
...
pid_t pid;
pid_t tgid;
...
struct *group_leader;
}
那么除了tgid和group_leadr是进程/线程的区别外,还有什么其他的区别么?
1.进程状态
volatile long state;
表示进程运行时的状态,-1表示不可运行,0表示可运行,>0表示已经停止。
state的可能取值如下:
TASK_RUNNING:表示进程要么正在执行,要么正要准备执行(已经就绪),正在等待cpu时间片的调度。
TASK_INTERRUPTIBLE:表示进程因为等待一些条件而被挂起(阻塞)而所处的状态。这些条件主要包括:硬中断、资源、一些信号……,一旦等待的条件成立,进程就会从该状态(阻塞)迅速转化成为就绪状态TASK_RUNNING(执行或准备执行态)。
TASK_UNINTERRUPTIBLE:意义与上一个类似对于处于此状态的进程,即使传递一个信号或者有一个外部中断都不能唤醒他们。只有它所等待的资源可用的时候,它才会被唤醒。这个标志很少用,但是并不代表没有任何用处,其实他的作用非常大,特别是对于驱动刺探相关的硬件过程很重要,这个刺探过程不能被一些其他的东西给中断,否则就会让进程进入不可预测的状态。
TASK_STOPPED:表示进程被停止执行,当进程接收到SIGSTOP、SIGTTIN、SIGTSTP或者SIGTTOU信号之后就会进入该状态。
TASK_TRACED:表示进程被debugger等进程监视,进程执行被调试程序所停止,当一个进程被另外的进程所监视,每一个信号都会让进程进入该状态。
2.进程标志
unsigned long flags;
进程当前的标志状态,但不是运行状态,用于内核识别进程当前的状态,以备下一步操作。
flags可能取值如下:
PF_FORKNOEXEC 进程刚创建,但还没执行。
PF_SUPERPRIV 超级用户特权。
PF_DUMPCORE dumped core。
PF_SIGNALED 进程被信号(signal)杀出。
PF_EXITING 进程开始关闭。
3.进程优先级
int prio, static_prio, normal_prio;
unsigned int rt_priority;
表示此进程的运行优先级
prio:表示动态优先级,根据static_prio和交互性奖罚算出。
static_prio:进程的静态优先级,在进程创建时确定,范围从-20到19,越小优先级越高。
normal_prio的优先级取决于静态优先级和调度策略。rt_priority用于保存实时优先级,范围是0到MAX_RT_PRIO-1(即99)。
4.进程标识符
pid_t pid;
pid_t tgid;
pid进程标识符,相当于每一个学生的学号一样,标识符唯一标识进程。
tpid是线程组号。
5.进程内核栈
void *stack;
进程内核栈。Linux内核通过thread_union联合体来表示进程的内核栈,其中THREAD_SIZE宏的大小为8192。
通过alloc_thread_info函数分配它的内核栈,通过free_thread_info函数释放所分配的内核栈。
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
6.进程的亲属关系
struct task_struct *real_parent; /* real parent process */
struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
real_parent——是进程的“亲生父亲”。如果创建进程的父进程不再存在,则指向PID为1的init进程
parent——是进程的父进程。进程终止时,必须向它的父进程发送信号。它的值通常与real_parent相同。
children——表示链表的头部,链表中的所有元素都是它的子进程。
sibling——用于把当前进程插入到兄弟链表中。
group_leader——指向其所在进程组的领头进程
7.ptrace系统调用
unsigned int ptrace;
ptrace 提供了一种父进程可以控制子进程运行,并可以检查和改变它的核心image。
它主要用于实现断点调试。一个被跟踪的进程运行中,直到发生一个信号,则进程被中止,并且通知其父进程。在进程中止的状态下,进程的内存空间可以被读写。父进程还可以使子进程继续执行,并选择是否是否忽略引起中止的信号。成员ptrace被设置为0时表示不需要被跟踪。
8.调度策略相关
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
sched_class:调度类
se:普通进程的调用实体,每个进程都有其中之一的实体
rt:实时进程的调用实体,每个进程都有其中之一的实体
9.进程地址空间
struct mm_struct *mm, *active_mm;
mm:进程所拥有的用户空间内存描述符,内核线程无的mm为NULL
active_mm:指向进程运行时所使用的内存描述符, 对于普通进程而言,这两个指针变量的值相同。但是内核线程kernel thread是没有进程地址空间的,所以内核线程的tsk->mm域是空(NULL)。
但是内核必须知道用户空间包含了什么,因此它的active_mm成员被初始化为前一个运行进程的active_mm值。
10.判断标志
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned int personality;
unsigned did_exec:1;
unsigned in_execve:1; /* Tell the LSMs that the process is doing an
* execve */
unsigned in_iowait:1;
exit_code:用于设置进程的终止代号,这个值要么是_exit()或exit_group()系统调用参数(正常终止),要么是由内核提供的一个错误代号(异常终止)。
exit_signal:被置为-1时表示是某个线程组中的一员。只有当线程组的最后一个成员终止时,才会产生一个信号,以通知线程组的领头进程的父进程。
personality:用于处理不同的ABI,参见Linux-Man。
did_exec:用于记录进程代码是否被execve()函数所执行。
in_execve:用于通知LSM是否被do_execve()函数所调用。
in_iowait:用于判断是否进行iowait计数。
11.时间
cputime_t utime, stime, utimescaled, stimescaled;
cputime_t gtime;
cputime_t prev_utime, prev_stime;
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time; /* monotonic time */
struct timespec real_start_time; /* boot based time */
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires;
struct list_head cpu_timers[3];
utime/stime:用于记录进程在用户态/内核态下所经过的节拍数(定时器)。
utimescaled/stimescaled:用于记录进程在用户态/内核态的运行时间,但它们以处理器的频率为刻度。
gtime:以节拍计数的虚拟机运行时间(guest time)。
prev_utime/prev_stime:是先前的运行时间,
请参考补丁说明http://lkml.indiana.edu/hypermail/linux/kernel/1003.3/02431.html。
nvcsw/nivcsw:自愿(voluntary)/非自愿(involuntary)上下文切换计数。
start_time、real_start_time:都是进程创建时间,real_start_time还包含了进程睡眠时间,常用于/proc/pid/stat,补丁说明请参考http://lkml.indiana.edu/hypermail/linux/kernel/0705.0/2094.html
cputime_expires:用来统计进程或进程组被跟踪的处理器时间,其中的三个成员对应着cpu_timers[3]的三个链表。
min_flt,maj_flt:缺页统计。
12.信号处理
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
signal:指向进程的信号描述符。
sighand:指向进程的信号处理程序描述符。
blocked:表示被阻塞信号的掩码,real_blocked表示临时掩码。
pending:存放私有挂起信号的数据结构。
sas_ss_sp:是信号处理程序备用堆栈的地址,sas_ss_size表示堆栈的大小。
notifier_data/notifier_mask:设备驱动程序常用notifier指向的函数来阻塞进程的某些信号(notifier_mask是这些信号的位掩码),notifier_data指的是notifier所指向的函数可能使用的数据。
13.其他
(1)用于保护资源分配或释放的自旋锁
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed,
* mempolicy */
spinlock_t alloc_lock;
(2)进程描述符使用计数,被置为2时,表示进程描述符正在被使用而且其相应的进程处于活动状态。
atomic_t usage;
(3)用于表示获取大内核锁的次数,如果进程未获得过锁,则置为-1。
int lock_depth; /* BKL lock depth */
(4)在SMP上帮助实现无加锁的进程切换(unlocked context switches)
#ifdef CONFIG_SMP
#ifdef __ARCH_WANT_UNLOCKED_CTXSW
int oncpu;
#endif
#endif
(5)preempt_notifier结构体链表
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* list of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
(6)FPU使用计数
unsigned char fpu_counter;
(7)、blktrace是一个针对Linux内核中块设备I/O层的跟踪工具。
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
(8)RCU同步原语
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
char rcu_read_unlock_special;
struct list_head rcu_node_entry;
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TREE_PREEMPT_RCU
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#ifdef CONFIG_RCU_BOOST
struct rt_mutex *rcu_boost_mutex;
#endif /* #ifdef CONFIG_RCU_BOOST */
(9)用于调度器统计进程的运行信息
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
(10)、用于构建进程链表
struct list_head tasks;
(11)、防止内核堆栈溢出
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary;
#endif
(12)PID散列表和链表
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group; //线程组中所有进程的链表
(13)do_fork函数
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
在执行do_fork()时,如果给定特别标志,则vfork_done会指向一个特殊地址。
如果copy_process函数的clone_flags参数的值被置为CLONE_CHILD_SETTID或CLONE_CHILD_CLEARTID,则会把child_tidptr参数的值分别复制到set_child_tid和clear_child_tid成员。这些标志说明必须改变子进程用户态地址空间的child_tidptr所指向的变量的值。
(14)进程权能
const struct cred __rcu *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task
* credentials (COW) */
struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */
(15)相应的程序名
char comm[TASK_COMM_LEN]
(16)文件
/* file system info */
int link_count, total_link_count;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
fs:用来表示进程与文件系统的联系,包括当前目录和根目录。\\
files:表示进程当前打开的文件。
(17)进程通信(SYSVIPC)
#ifdef CONFIG_SYSVIPC
/* ipc stuff */
struct sysv_sem sysvsem;
#endif
(18)处理器特有数据
struct thread_struct thread;
(19)命名空间
struct nsproxy *nsproxy;
(20)进程审计
struct audit_context *audit_context;
#ifdef CONFIG_AUDITSYSCALL
uid_t loginuid;
unsigned int sessionid;
#endif
(21)secure computing
seccomp_t seccomp;
(22)用于copy_process函数使用CLONE_PARENT 标记时
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
(23)中断
#ifdef CONFIG_GENERIC_HARDIRQS
/* IRQ handler threads */
struct irqaction *irqaction;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
unsigned int irq_events;
unsigned long hardirq_enable_ip;
unsigned long hardirq_disable_ip;
unsigned int hardirq_enable_event;
unsigned int hardirq_disable_event;
int hardirqs_enabled;
int hardirq_context;
unsigned long softirq_disable_ip;
unsigned long softirq_enable_ip;
unsigned int softirq_disable_event;
unsigned int softirq_enable_event;
int softirqs_enabled;
int softirq_context;
#endif
(24)task_rq_lock函数所使用的锁
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
(25)基于PI协议的等待互斥锁,其中PI指的是priority inheritance(优先级继承)
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task */
struct plist_head pi_waiters;
/* Deadlock detection and priority inheritance handling */
struct rt_mutex_waiter *pi_blocked_on;
#endif
(26)死锁检测
#ifdef CONFIG_DEBUG_MUTEXES
/* mutex deadlock detection */
struct mutex_waiter *blocked_on;
#endif
(27)lockdep,参见内核说明文档linux-2.6.38.8/Documentation/lockdep-design.txt
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
int lockdep_depth;
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
gfp_t lockdep_reclaim_gfp;
#endif
(28)JFS文件系统
/* journalling filesystem info */
void *journal_info;
(29)块设备链表
/* stacked block device info */
struct bio_list *bio_list;
(30)内存回收
struct reclaim_state *reclaim_state;
(31)存放块设备I/O数据流量信息
struct backing_dev_info *backing_dev_info;
(32)I/O调度器所使用的信息
struct io_context *io_context;
(33)CPUSET功能
#ifdef CONFIG_CPUSETS
nodemask_t mems_allowed; /* Protected by alloc_lock */
int mems_allowed_change_disable;
int cpuset_mem_spread_rotor;
int cpuset_slab_spread_rotor;
#endif
(34)Control Groups
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock */
struct list_head cg_list;
#endif
#ifdef CONFIG_CGROUP_MEM_RES_CTLR /* memcg uses this to do batch job */
struct memcg_batch_info {
int do_batch; /* incremented when batch uncharge started */
struct mem_cgroup *memcg; /* target memcg of uncharge */
unsigned long bytes; /* uncharged usage */
unsigned long memsw_bytes; /* uncharged mem+swap usage */
} memcg_batch;
#endif
(35)futex同步机制
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
#endif
(36)非一致内存访问(NUMA Non-Uniform Memory Access)
#ifdef CONFIG_NUMA
struct mempolicy *mempolicy; /* Protected by alloc_lock */
short il_next;
#endif
(37)文件系统互斥资源
atomic_t fs_excl; /* holding fs exclusive resources */
(38)RCU链表
struct rcu_head rcu;
(39)管道
struct pipe_inode_info *splice_pipe;
(40)延迟计数
1. #ifdef CONFIG_TASK_DELAY_ACCT
2. struct task_delay_info *delays;
3. #endif
(41)fault injection,参考内核说明文件linux-2.6.38.8/Documentation/fault-injection/fault-injection.txt
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
#endif
task_struct的thread_struct
task_struct是进程在内核中对应的数据结构,它标识了进程的状态等各项信息。
其中有一项thread_struct结构的变量thread,记录了CPU相关的进程状态信息,如内核控制的断点和栈指针等。
malloc()调用的用户态到内核态切换
C函数库中的内存分配函数malloc(),它具体是使用sbrk()系统调用来分配内存,当malloc调用sbrk()的时候就涉及一次从用户态到内核态的切换
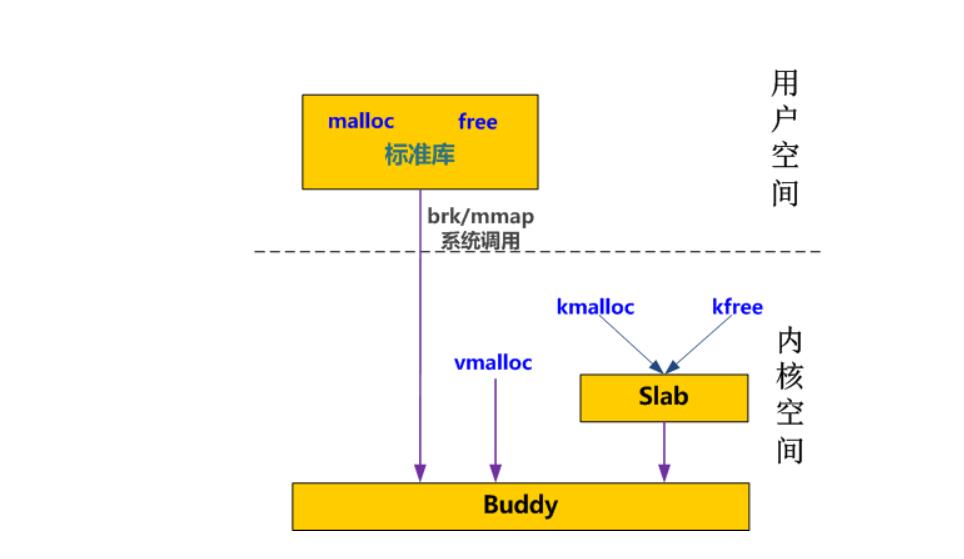
Buddy 分配page内存
CPU看到的内存管理都是对page(4k)的管理,接下来我们看一下用来管理page的经典算法–Buddy
Buddy 是著名的伙伴分配算法:
我们通过一个简单的例子来说明该算法的工作原理。
Linux的伙伴算法把所有的空闲页面分为10个块组,每组中块的大小是2的幂次方个页面,例如,第0组中块的大小都为20 (1个页面),第1组中块的大小为都为21(2个页面),第9组中块的大小都为29(512个页面)。也就是说,每一组中块的大小是相同的,且这同样大小的块形成一个链表。
假设要求分配的块其大小为128个页面(由多个页面组成的块我们就叫做页面块)。
该算法先在块大小为128个页面的链表中查找,看是否有这样一个空闲块。如果有,就直接分配;如果没有,该算法会查找下一个更大的块,具体地说,就是在块大小为256个页面的链表中查找一个空闲块。如果存在这样的空闲块,内核就把这256个页面分为两等份,一份分配出去,另一份插入到块大小为128个页面的链表中。
如果在块大小为256个页面的链表中也没有找到空闲页块,就继续找更大的块,即512个页面的块。如果存在这样的块,内核就从512个页面的块中分出128个页面满足请求,然后从384个页面中取出256个页面插入到块大小为256个页面的链表中。然后把剩余的128个页面插入到块大小为128个页面的链表中。
如果512个页面的链表中还没有空闲块,该算法就放弃分配,并发出出错信号。
对上面的文字,不了解的,没有关系,我马上要讲netty源码,会细致深入介绍 这个算法。
Slab分配小内存
采用伙伴算法分配内存时,每次至少分配一个页面。但当请求分配的内存大小为几十个字节或几百个字节时应该如何处理?如何在一个页面中分配小的内存区,小内存区的分配所产生的内碎片又如何解决?
在Linux中,伙伴系统(buddy system)是以页为单位管理和分配内存。
但是现实的需求却以字节为单位,假如我们需要申请20Bytes,总不能分配一页吧!那岂不是严重浪费内存。
那么该如何分配呢?slab分配器就应运而生了,专为小内存分配而生。
slab分配器分配内存以Byte为单位。但是slab分配器并没有脱离伙伴系统,而是基于伙伴系统分配的大内存进一步细分成小内存分配。
对上面的文字,不了解的,没有关系,我马上要讲netty源码,会细致深入介绍 这个算法。
参考文献:
https://blog.csdn.net/pointer_y/article/details/54292093
https://www.cnblogs.com/fengdejiyixx/p/13285838.html
https://blog.csdn.net/u013291303/article/details/70199645
https://blog.csdn.net/frodocheng/article/details/106718244
https://blog.csdn.net/qq_43811102/article/details/103340748
以上是关于秒懂+史上最全:JVM进程Java进程的用户空间与内核空间如何区分? 如何区分Java进程的内核态与用户态?的主要内容,如果未能解决你的问题,请参考以下文章