C/C++ 并行搜索 算法
Posted cpp_learners
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C/C++ 并行搜索 算法相关的知识,希望对你有一定的参考价值。
使用多线程,将一组数据拆分成多组进行查询,提高查询效率!
并发的基本概念
所谓并发是在同一实体上的多个事件同时发生。并发编程是指在在同一台计算机上“同时”处理多个任务。
其实也就是多个工人共同工作,提高工作效率!
并行搜索算法,就是有一组特别大的数据,需要在这组数据里面统计某个数重复的次数。
按正常思维,从头开始遍历,直至最后;这样的话,数据量一大,效率就很低了,所花费的时间就很多了,因为是一个人在干活。
如果安排多个人一起干活,每个人负责某一个区域,那么效率就上来了!
所以,实现并行搜索算法需要使用到多线程的操作!
如果不懂多线程的小伙伴,可以参考此篇博客去学习:
https://blog.csdn.net/cpp_learner/article/details/120415489
算法实现:
当然,搜索操作是在线程方法里面去实现的,如下面就是线程函数,使用最简单的方式遍历:
// 线程处理的函数
unsigned int WINAPI ThreadProc(LPVOID lpParam) {
search *s = (search *)lpParam;
clock_t start, end;
start = clock(); // 开始记录时间
for (size_t i = s->start; i <= s->end; i++) {
if (s->data[i] == NUMBER) {
s->count++;
}
}
end = clock(); // 结束记录时间
printf("time = %d 毫秒\\n", (int)(end - start) * 1000 / CLOCKS_PER_SEC);
return 0;
}
创建多个线程去调用这函数,就可以实现多人工作的效果,提升效果!
代码:
数组个数是:(1024 * 1024 * 300) 等于 314572800。三亿多个数。
#include <iostream>
#include <stdio.h>
#include <Windows.h>
#include <time.h>
#include <process.h>
#define TEST_SIZE (1024*1024*400) // 数字的元素个数
#define NUMBER 888 // 查找的数字
typedef struct _search {
int *data; // 搜索的数据集
size_t start; // 搜索的开始位置
size_t end; // 索索地结束位置
size_t count; // 搜索的结果
}search;
// 线程处理的函数
unsigned int WINAPI ThreadProc(LPVOID lpParam) {
search *s = (search *)lpParam;
clock_t start, end;
start = clock(); // 开始记录时间
for (size_t i = s->start; i <= s->end; i++) {
if (s->data[i] == NUMBER) {
s->count++;
}
}
end = clock(); // 结束记录时间
printf("time = %d 毫秒\\n", (int)(end - start) * 1000 / CLOCKS_PER_SEC);
return 0;
}
int main(void) {
int *data = NULL;
int count = 0; // 记录的数量
int mid = 0; // 数组中间索引
search s1, s2;
data = new int[TEST_SIZE];
for (int i = 0; i < TEST_SIZE; i++) {
data[i] = i;
}
mid = TEST_SIZE / 2; // 计算中间值索引
s1.data = data;
s1.start = 0; // 开始查找的索引位置
s1.end = mid; // 结束查找的索引位置
s1.count = 0; // 查找出的个数
s2.data = data;
s2.start = mid + 1;
s2.end = TEST_SIZE - 1;
s2.count = 0;
UINT threadID1 = 0; // 线程1的身份证
HANDLE hThread1 = NULL; // 线程1的句柄
UINT threadID2 = 0; // 线程2的身份证
HANDLE hThread2 = NULL; // 线程2的句柄
// 创建线程1
hThread1 = (HANDLE)_beginthreadex(NULL, 0, ThreadProc, &s1, 0, &threadID1);
// 创建线程2
hThread2 = (HANDLE)_beginthreadex(NULL, 0, ThreadProc, &s2, 0, &threadID2);
// 合法性检查(检查线程是否创建成功)
if (hThread1 == NULL || hThread2 == NULL) {
printf("_beginthreadex() ERROR! \\n");
return -1;
}
// 等待线程执行完毕
WaitForSingleObject(hThread1, INFINITE);
WaitForSingleObject(hThread2, INFINITE);
printf("线程结束,结果是:count = %d\\n", s1.count + s2.count);
return 0;
}
运行截图:
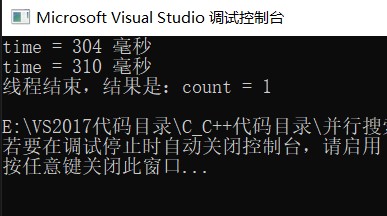
一个线程用了304毫秒,另一个线程用了310毫秒!
当然结果肯定是1,因为数组中只有一个888.
为了凸显效果,我们将代码改一下,用4个线程进行搜索,看看每个线程所花费的时间是多少:
数组个数是:(1024 * 1024 * 300) 等于 314572800。三亿多个数。
#include <iostream>
#include <stdio.h>
#include <Windows.h>
#include <time.h>
#include <process.h>
#define TEST_SIZE (1024*1024*300) // 数字的元素个数
#define NUMBER 888 // 查找的数字
typedef struct _search {
int *data; // 搜索的数据集
size_t start; // 搜索的开始位置
size_t end; // 索索地结束位置
size_t count; // 搜索的结果
}search;
// 线程处理的函数
unsigned int WINAPI ThreadProc(LPVOID lpParam) {
search *s = (search *)lpParam;
clock_t start, end;
start = clock(); // 开始记录时间
for (size_t i = s->start; i <= s->end; i++) {
if (s->data[i] == NUMBER) {
s->count++;
}
}
end = clock(); // 结束记录时间
printf("time = %d 毫秒\\n", (int)(end - start) * 1000 / CLOCKS_PER_SEC);
return 0;
}
int main(void) {
int *data = NULL;
int count = 0; // 记录的数量
int mid = 0; // 数组中间索引
int mid1 = 0, mid2 = 0;
search s1, s2, s3, s4;
data = new int[TEST_SIZE];
for (int i = 0; i < TEST_SIZE; i++) {
data[i] = i;
}
// 将数据分成四段
mid = TEST_SIZE / 2; // 中间值索引
mid1 = mid / 2; // 左边中间值索引
mid2 = (TEST_SIZE + mid) / 2; // 右边中间值索引
// 第一段
s1.data = data;
s1.start = 0; // 开始查找的索引位置
s1.end = mid1; // 结束查找的索引位置
s1.count = 0; // 查找出的个数
// 第二段
s2.data = data;
s2.start = mid1 + 1;
s2.end = mid;
s2.count = 0;
// 第三段
s3.data = data;
s3.start = mid + 1;
s3.end = mid2;
s3.count = 0;
// 第四段
s4.data = data;
s4.start = mid2 + 1;
s4.end = TEST_SIZE - 1;
s4.count = 0;
UINT threadID1 = 0; // 线程1的身份证
HANDLE hThread1 = NULL; // 线程1的句柄
UINT threadID2 = 0; // 线程2的身份证
HANDLE hThread2 = NULL; // 线程2的句柄
UINT threadID3 = 0; // 线程3的身份证
HANDLE hThread3 = NULL; // 线程3的句柄
UINT threadID4 = 0; // 线程4的身份证
HANDLE hThread4 = NULL; // 线程4的句柄
// 创建线程1
hThread1 = (HANDLE)_beginthreadex(NULL, 0, ThreadProc, &s1, 0, &threadID1);
// 创建线程2
hThread2 = (HANDLE)_beginthreadex(NULL, 0, ThreadProc, &s2, 0, &threadID2);
// 创建线程3
hThread3 = (HANDLE)_beginthreadex(NULL, 0, ThreadProc, &s3, 0, &threadID3);
// 创建线程4
hThread4 = (HANDLE)_beginthreadex(NULL, 0, ThreadProc, &s4, 0, &threadID4);
// 合法性检查(检查线程是否创建成功)
if (hThread1 == NULL || hThread2 == NULL || hThread3 == NULL || hThread4 == NULL) {
printf("_beginthreadex() ERROR! \\n");
return -1;
}
// 等待线程执行完毕
WaitForSingleObject(hThread1, INFINITE);
WaitForSingleObject(hThread2, INFINITE);
WaitForSingleObject(hThread3, INFINITE);
WaitForSingleObject(hThread4, INFINITE);
printf("线程结束,结果是:count = %d\\n", s1.count + s2.count + s3.count + s4.count);
return 0;
}
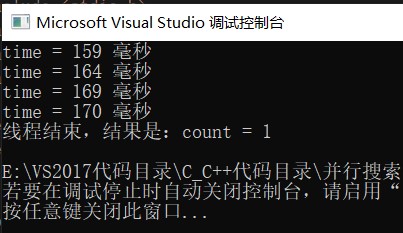
看到没有,平均每个线程花费166毫秒,效率一下子又上去了!
当然结果肯定是1,因为数组中只有一个888.
总结:
感觉并行搜索算法并不难,就是考你多线程的用法,把多线程搞定了,这个算法自然而然就会了!算是多线程的一个小例子吧!
以上是关于C/C++ 并行搜索 算法的主要内容,如果未能解决你的问题,请参考以下文章