Linux中的RCU机制
Posted 宋宝华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux中的RCU机制相关的知识,希望对你有一定的参考价值。
内容
基本原理
使用方法
GP 的生命周期
QS 的判定与标记
优势何在
存在的问题
RCU机制是自内核2.5版本引入的(2002年10月),而后不断完善,其在Linux的locking机制中的使用占比也是逐年攀升。

1.基本原理
RCU的基本思想是这样的:先创建一个旧数据的copy,然后writer更新这个copy,最后再用新的数据替换掉旧的数据。这样讲似乎比较抽象,那么结合一个实例来看或许会更加直观。
假设有一个单向链表,其中包含一个由指针p指向的节点:
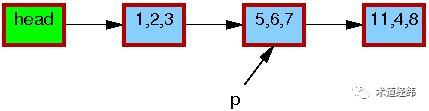
现在,我们要使用RCU机制来更新这个节点的数据,那么首先需要分配一段新的内存空间(由指针q指向),用于存放这个copy。

然后将p指向的节点数据,以及它和下一节点[11, 4, 8]的关系,都完整地copy到q指向的内存区域中。
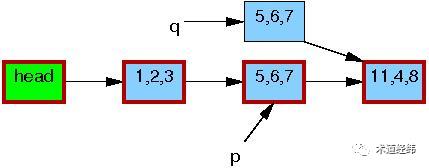
接下来,writer会修改这个copy中的数据(将[5, 6, 7]修改为[5, 2, 3])。

修改完成之后,writer就可以将这个更新“发布”了(publish),对于reader来说就“可见”了。因此,pubulish之后才开始读取操作的reader(比如读节点[1, 2, 3]的下一个节点),得到的就是新的数据[5, 2, 3](图中红色边框表示有reader在引用)。

而在publish之前就开始读取操作的reader则不受影响,依然使用旧的数据[5, 6, 7]。

等到所有引用旧数据区的reader都完成了相关操作,writer才会释放由p指向的内存区域。

可见,在此期间,reader如果读取这个节点的数据,得到的要么全是旧的数据,要么全是新的数据,反正不会是「半新半旧」的数据,数据的一致性是可以保证的。
重要的是,RCU中的reader不用像rwlock中的reader那样,在writer操作期间必须spin等待了。

RCU的全称是"read copy update",可以这样来理解:read和进行copy的线程并行,目的是为了update。好像有点"copy on write"的意思?反正有人觉得RCU的命名不够准确,宁愿叫它"publish protocol"(比如 Fedor Pikus)。不管怎样,RCU的命名已经成了业界默认的,我们还是就叫它RCU吧。
那RCU具体应该如何使用呢?这得走进真正的代码,才能一探究竟。
2.使用方法
前面的例子为了简化,采用的是单向链表来演示,这里我们切换到Linux中常用的双向链表上来。由于RCU可理解为是基于rwlock演进而来的,所以笔者将结合上文讲解的rwlock的用法,来对比讨论RCU的使用。
假设现在reader正在遍历/查询一个链表,而writer正在删除该链表中的一个节点。那么,使用rwlock(左)和RCU(右)来实现的读取一侧的代码分别是这样的:

同rwlock类似,rcu_read_lock()和rcu_read_unlock()界定了RCU读取一侧的critical section。如果在内核配置时选择了"CONFIG_PREEMPT",那么这2个函数实际要做的工作仅仅是分别关闭和打开CPU的可抢占性而已,等同于preempt_disable()和preempt_enable()。
这种命名,体现了RCU和rwlock的「一脉相承」,但在RCU的读取一侧,其实并没有什么"lock",所以可能命名为rcu_enter()和rcu_exit()之类的更加贴切。
在写入一侧的RCU实现中,为了防止多个writer对链表的同时操作,使用了一个标准的spinlock。

list_del_rcu()的实现和普通的list_del()基本一致,但多了一个对"prev"指针的"poison"处理,以避免接下来reader再通过该节点访问前向节点。
static inline void list_del_rcu(struct list_head *entry)
{
__list_del_entry(entry);
entry->prev = LIST_POISON2;
}此外,在调用kfree()释放节点之前,多了一个synchronize_rcu()函数。synchronize就是「同步」,那它在和谁同步呢?
就是前面说的那些“引用旧数据区的reader”啦,因为此时它们可能还在引用指针p。这相当于给了这些reader一个优雅退出的宽限区,因此这段同步等待的时间被称为Grace Period(简称GP)。
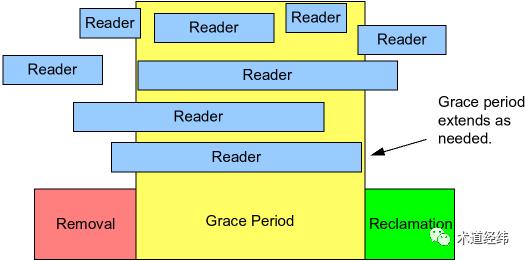
不过,必须是在synchronize之前就已经进入critical section的reader才可以,至于之后的reader么,直接读新的数据就可以了,用不着writer来等待。
比如下面这个场景中,作为writer的CPU 1只会等待CPU 0,CPU 0离开critical section后就结束同步,而不会理会CPU 2。

也许,把synchronize_rcu()改名成wait_for_readers_to_leave()会更加直观。
等待与回调
如果grace period的时间比较长,writer这么干等着,岂不是会影响这个CPU上更高优先级的任务执行?在这种情况下,可以使用基于callback机制的call_rcu()来替换synchronize_rcu()。
void call_rcu(struct rcu_head *head, rcu_callback_t func);call_rcu()会注册一个回调函数"func",当所有的reader都退出critical section后,该回调函数将被执行。
第一个参数的类型是struct rcu_head,它的定义是这样的:
struct callback_head {
struct callback_head *next;
void (*func)(struct callback_head *head);
} __attribute__((aligned(sizeof(void *))));
#define rcu_head callback_headCPU调用call_rcu()后就可以离开去做其他事情了,之后它完全可能再次调用call_rcu(),所以它每次注册的回调函数,需要通过"next"指针排队串接起来,等grace period结束后,依次执行。如果需要处理的回调函数比较多,可能需要分批进行。
第二个参数就是前面讲的回调函数,其功能主要就是释放掉“旧指针”指向的内存空间。
来看一个使用call_rcu()的具体实例:
call_rcu(&old->rcu, kvfree_rcu);rcu_head是注册时传递给"kvfree_rcu"的参数,可是要释放的旧指针在哪里?
static void kvfree_rcu(struct rcu_head *head)
{
struct list_lru_memcg *mlru;
mlru = container_of(head, struct list_lru_memcg, rcu);
kvfree(mlru);
}原来啊,它同"list_head"一样,往往是「嵌」在某个结构体中,通过container_of()的技巧来获得所在结构体的首地址的。
新旧更迭
本着循序渐进的原则,以上代码采用的是基于链表的"delete"操作来讨论,仅涵盖了对“旧指针”的处理。而本文的开头,使用的例子是链表的"replace"操作,还包括了对“新指针”的处理,所以接下来看下代码中和“新指针”有关的部分吧。
static inline void __list_add_rcu(struct list_head *new,
struct list_head *prev, struct list_head *next)
{
new->next = next;
new->prev = prev;
rcu_assign_pointer(list_next_rcu(prev), new);
next->prev = new;
}和普通的list_add()相比,多了一个rcu_assign_pointer()。它起的作用就是前面说的"publish",publish之后,writer就可以进入grace period了。同时,它的实现中包含了一个Memory Barrier,以避免在“新指针”准备好之前,就被引用了。
#define rcu_assign_pointer(p, v) smp_store_release(&(p), (v));这里使用的是list_add_rcu(),而不是list_replace_rcu()来讲解,这是因为"delete"只需要synchronize_rcu()/call_rcu(),而"add"只需要rcu_assign_pointer(),它们都是最基础的操作,而"replace"完全可以视作是先进行"delete",再进行"add"的复合操作。理解了基础操作,复合操作就不在话下了。
并行的粒度
以grace period为界,整个更新操作被划分为了"removal"和"reclamation"两个阶段,writer的角色也被对应地划分为了updater和reclaimer。
还是用链表操作的这个例子,removal阶段将一个节点从链表中移除,而等待所有reader解除对该节点的引用后,就进入回收/释放这个节点所占内存的reclamation阶段。

因为writer在removal阶段就会解除对节点的引用,所以reader需要调用rcu_dereference()宏,将节点指针的值赋给一个临时指针,保存起来。它的实现可简单理解成这样:
#define rcu_dereference(p) READ_ONCE(p);接下来这些reader对该节点的操作都是引用这个临时指针,它们访问到的也都是publish之前的数据。不过,因为该节点的内存会在最后一个引用它的reader退出临界区后,被reclaimer释放,所以对这个节点的引用,只在读取一侧的临界区内有效。
rcu_read_lock();
p1 = rcu_dereference(p);
rcu_read_unlock();
x = p1->address;像上述代码这种退出临界区还在使用,是不行的。下图中的"p1"和"p2"分别代表reader保存的引用"data 1"和"data 2"的指针。

虽然seqlock也可以实现reader和writer的并行,但在writer操作期间,reader的操作需要推到重来,所以其实是无效的。而在RCU中,reader和updater可以实现真正的并行,updater你更新你的,反正我reader读的是旧的数据。updater和reclaimer也可以并行,所以在某一时刻,一份数据可能有多个version(图中蓝色箭头表示“旧指针”,黑色箭头表示“新指针”)。

但updater和updater之间不能并行,需要加spinlock来互斥。至于reader和reclaimer之间能不能并行,则取决于reclaimer对应的grace period是否包含相关的reader。
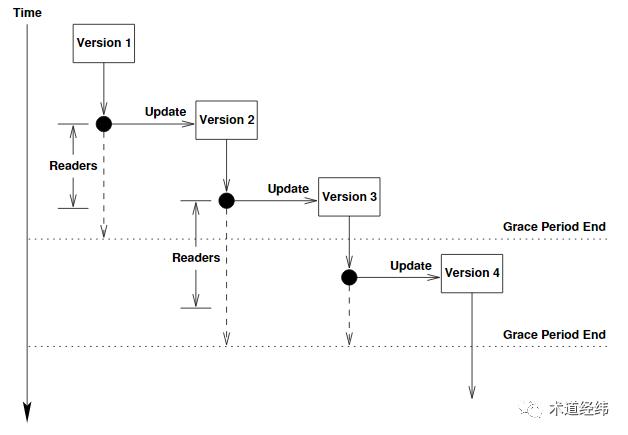
从上文seqlock和本文RCU的实现来看,读取一侧其实都是没有锁的,reader和writer的同步在seqlock中靠的是sequence number,而在RCU中主要靠的是grace period。
对于RCU,不能简单地说它是只支持“多读一写”还是支持“多读多写”的,但它但它通过对writer更细粒度的划分,确实比seqlock提供了更高的并行度。更高的并行度意味着能让更多的CPU处在busy的状态,也就能让硬件资源得到更充分的利用,提高效率。
三角关系
伴随着对RCU基本原理和使用方法的讲解,RCU中读取一侧和写入一侧5个基础的API其实也都逐步出现了,事实上,RCU的很多其他API都是基于这5个API组合而成的,就像红黄蓝三原色一样。
由于writer角色和功能的划分,RCU中存在的是reader, updater和reclaimer三者之间的关联。借助下面这张图,我们可以一览RCU的全貌,同时梳理这些联系。
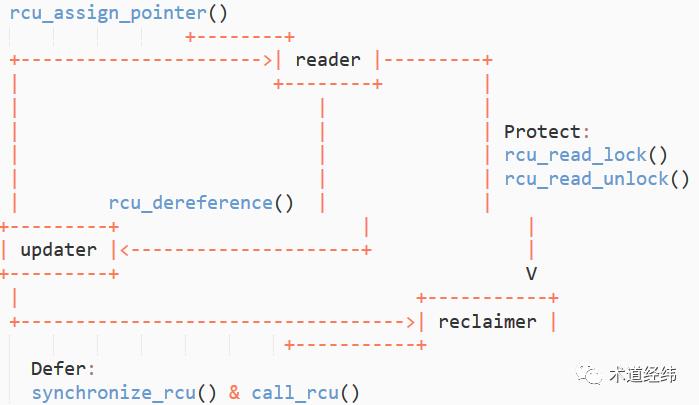
以链表的"replace"操作为例,作为updater,在对copy的数据更新完成后,需要通过rcu_assign_pointer(),用这个copy替换原节点在链表中的位置,并移除对原节点的引用,而后调用synchronize_rcu()或call_rcu()进入grace period。
因为synchronize_rcu()会阻塞等待,所以只能在进程上下文中使用,而call_rcu()可在中断上下文中使用。
作为reader,在调用rcu_read_lock()进入临界区后,因为所使用的节点可能被updater解除引用,因而需要通过rcu_dereference()保留一份对这个节点的指针指向。
进入grace period意味着数据已经更新,而这些reader在退出临界区之前,只能使用旧的数据,也就是说,它们需要暂时忍受“过时”的数据,不过这在很多情况下是没有多大影响的。
作为reclaimer,对于所有进入grace period之前就进入临界区的reader,需要等待它们都调用了rcu_read_unlock()退出临界区,之后grace period结束,原节点所在的内存区域被释放。
当内存不再需要了就回收,讲到这里,你有没有觉得,RCU的方法有点"Garbage Collection"(GC)的味道?它确实可以算一种user-driven的GC机制(区别于automatic的)。
3.GP 的生命周期
上文留了一个问题,即“reclaimer 是如何判断 reader 已经退出临界区的”。这得从一个Grace Period(以下统称 "GP")从产生到结束的生命周期说起。

何时开始
GP是由作为writer的CPU发起的,当writer调用synchronize_rcu()/call_rcu()之后,就标志着进入了一个GP。
synchronize_rcu()
--> wait_rcu_gp(...)
--> wait_for_completion(...)何时结束
根据 rcu_read_lock() 的实现,对于默认的 non-preemptible 的 RCU,进入临界区(read section)时,reader 所在的 CPU 上的调度是关闭的,直到退出临界区后,调度才会重新打开。除开下文将介绍的 SRCU 的情况,临界区内的代码被要求是不能睡眠/阻塞的,因而不会发生线程切换。
#ifndef CONFIG_PREEMPT_RCU
static inline void __rcu_read_lock(void)
{
preempt_disable();
}
static inline void __rcu_read_unlock(void)
{
preempt_enable();
}
#endif如果接下来该 CPU 开始执行其他任务,那么说明发生了线程切换(开启了调度),进而可说明该 CPU 已退出了临界区。另外,由于临界区的代码一定是在内核执行的,如果判断出该CPU 已经开始执行用户态的代码,同样可以判断临界区已退出。第三种可作为判断依据的情况是已处在 idle loop 中。
从退出 GP,到可以判定已经离开临界区的这段时期,被称为 "Quiescent State"(以下统称 "QS")。
换个角度看,从申请释放一个 object,到可以释放一个 object 的这段时间,即为 GP,其本质上是一个 waiting period。凡是还在 read section 的 CPU,都是阻止 GP 结束的,当一个 CPU 进入QS,相当于宣布 "I'm done",也就意味着不再阻止 GP。
QS 是 CPU 私有,而 GP 是全局的,这有点类似于“一票否决制”,需要所有 CPU 都同意(所有 CPU 都进入 QS),GP 才能结束。
4.QS 的判定与标记
如何判断
前面列举了三种可作为判别依据的情景,在使能了 tick 的系统中,可在 tick 发生时获取 CPU 的状态。但现在发行版大多默认采用 tickless 的模式,那么就需要在发生 context switch,进入/退出 idle 状态时进行 QS 的判断。
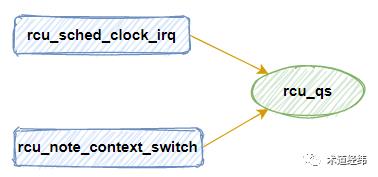
如何标记
那怎么知道所有的 CPU 都已经“同意”了呢?内核采用的办法是:每判断一个 CPU 完成了一次 QS,就进行一处标记。对于标记的具体方法,目前的 Linux 主要提供了两种版本。先来看下相对比较简单,适用于 CPU 数目比较少的 Tiny RCU 的实现。
分配一个 bitmap(在 CPU 这里一般叫做 cpumask),开始一个 GP 后,将 bitmap 中所有的 bits 置 1,当一个 CPU 退出 QS 后,就将自己对应的 bit 清零。所有 bits 都被置 0 后,就可以判断 GP 的结束了。
在此过程中,多个 CPU 可能同时操作 bitmap 对应的这个全局变量,因此需要使用一个spinlock 来保护,如果 CPU 的数目较多,对 spinlock 的争抢就可能很激烈。同时由于 RCU 在 read section 不能睡眠的要求,在 GP 内,没有争抢成功的 CPU 也不能 sleep,白白增加功耗。
这就好像员工直接向老板汇报工作,汇报的内容不能让其他员工听到,所以办公室只能容纳一人,其他等待汇报工作的员工只能在办公室外等着。几个人的小公司这样做还行,上百人的大公司也这样弄还得了?所以现代企业多采用层级管理结构,每个基层员工向中层的 leader 汇报工作,leader 汇总后,再向上级的 manager 汇报。
对应到 RCU 中 QS 的标记上来,就是每个 CPU 拥有一个 "rcu_data",该结构体专注于 QS 的记录。多个 CPU 共同向一个上层的 "rcu_node" 汇报,该结构体负责向上传递 QS 的信息。每个 "rcu_node "有一个 "qsmask" 位图,初始时位图中所有 bits 为1,当其下属的 CPU 都标记 QS 后,"qsmask" 中所有 bits 都变为0,此时它就可以向更上一层的 rcu_node 汇报。

在实际的应用中,通常 16 个 CPU 共享一个 rcu_node,每个 rcu_node 包含一个 spinlock,以互斥这 16 个 CPU 对 "qsmask" 的更改。这种更细粒度的划分降低了 QS 标记中 CPU 之间的竞争,增强了系统的扩展性,由于采用树形结构,因而被称为 "Tree RCU"。
虽说是树形结构,但 Tree RCU 并没有采用 rbtree 或者 radix tree,而是以 array 的内存形式存在,然后通过指针的连接形成了一种逻辑上的树形关系,同时也让“广度优先遍历”变成了数组的线性搜索。
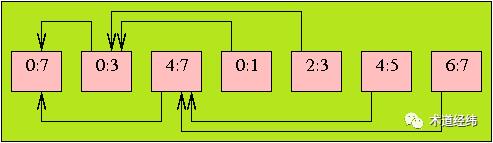
一个 rcu_node 代表多个CPU,而最顶层的 rcu_node 则代表了所有的 CPU,因此当最顶层的 rcu_node 的 "qsmask" 为 0 时,就意味着所有 CPU 都经过了 QS,那么 GP 就可以结束了。
5.优势何在
适用场景
rwlock 中的 reader 需要对读取一侧的 reference count 的值进行更新,这是一个 RMW 的原子操作,当作为 reader 的 CPU 数目较多时,会造成激烈的 cache contention。而对于 RCU 中的一个 reader 来说,则不存在这些问题,仅仅是需要暂时忍受过时的数据,在性能上并没有额外的开销。
有句话是这样说的:当你感觉岁月静好的时候,一定是另外有一个人帮你承担了。reader 是轻松了,但对于 RCU 中的一个 writer 来说(包括 updater 和 reclaimer),需要申请新的内存空间,向内核注册回调函数,以及进行数据的更新操作,同时还要考虑与其他 writer 之间的互斥问题,开销较大。
因此,RCU 同 seqlock 一样,适合“读多写少”的情景(比如链表操作),更新越少,受过时数据的影响越低,就越适合使用 RCU。
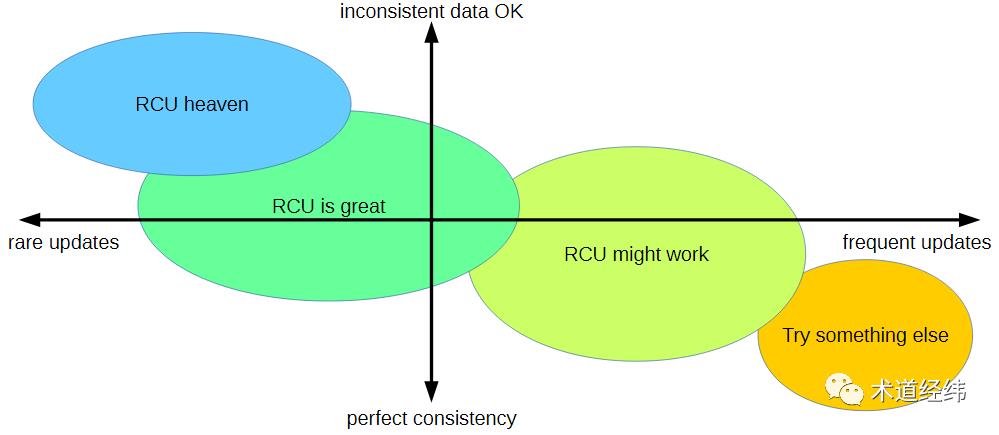
无惧死锁
前面讨论过 spinlock 的死锁问题,对于 rwlock,情况略有不同。因为 rwlock 中 reader 本身就是可以并行的,所以这样使用没有问题:
read_lock(&rwlock);
read_lock(&rwlock);但是 reader 和 writer 之间不能并行,所以如下的场景会产生死锁:
read_lock(&rwlock);
write_lock(&rwlock);而对于 RCU 来说,天然地具有防死锁特性,所以也没有 "rcu_read_lock_irqdisable()" 一类的函数,因为不需要关中断,即便来了中断,在 ISR 里不管是读还是写,都可以完成后返回,不会形成死锁。
6.存在的问题
GP 是 RCU 实现 reader 和 writer 同步的关键,而它的长度取决于 reader 临界区的执行时间。如果其中某个 reader 在临界区中陷入了死循环,那么 GP 就无法结束,形成 RCU Stall。
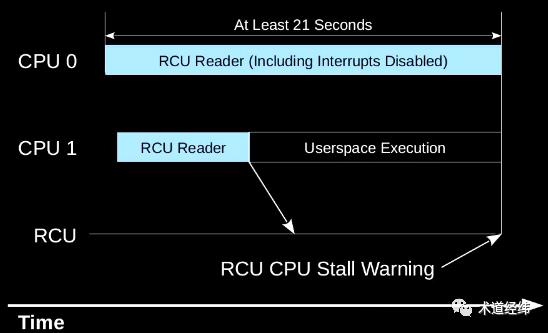
针对这种情况,内核提供了一套 debug 机制,可以在检测到 CPU stall 后报告 warning,产生 stack dump trace,以辅助调试和分析。

【SRCU】
以上介绍的是传统的 RCU,它对读取一侧的临界区的要求同spinlock一样,不能睡眠/阻塞。然而,作为 RCU 的主要 developer,Paul McKenney 不断的收到开发支持睡眠的 RCU 的要求。
这些人的理由是:对于可抢占的内核,从实时性的角度,“不能调度”将可能导致高优先级的任务被低优先级的任务阻塞,得不到执行。
Paul 最开始是拒绝的。如果允许读取一侧临界区的睡眠,那 GP 岂不是会变得很长,GP 不能结束,那作为 writer 就不能释放旧数据所占据的内存资源。如果一个系统中这样的情况比较多,甚至有内存耗尽的风险。
不过,随着对 Linux 的实时性日益高涨的呼声,Paul 最终还是找到一个可以平衡这两种需求的折中的设计方案,即 "sleepable RCU"(SRCU),其着力点主要是如何减少需要等待 GP 后才能释放的内存总量。
第一,SRCU 摒弃了异步的 call_rcu(),因为使用这个 API 的线程,理论上可以产生大量等待 GP 结束后释放的内存,而使用同步的 synchronize_rcu() 的线程,最多产生一个。SRCU 提供的对应API是 synchronize_srcu()。
第二,如果系统中 CPU 数量较多,那么一个 reader 在临界区的阻塞可能影响众多的CPU,所以 SRCU 将整个系统进行了细分,划分为若干个 subsystem。这样,一个 reader 只会影响和它同属一个 subsystem 的其他 CPU。
比如在下列的场景中,作为 writer 的 CPU 1 只需要等待 CPU 0,不需要等待 CPU 3,因为 CPU 0 和 CPU 1 同属一个 subsytem(参数都是"s1"),而 CPU 3 则不是。

SRCU 作为 Classic RCU 的 sleepable 版本,就像 workqueue 之于 softirq,mutex 之于 spinlock。
不过,SRCU 并不等同于 Preemptible RCU,详情请参考这篇文章(https://lwn.net/Articles/253651/)。SRCU 和 Preemptible RCU 都允许临界区内的抢占,因而不能通过线程切换来判断临界区的结束,而是需要在进入/退出临界区时加/减一个 counter,借助 counter 的值来判断是否已退出。
/* SRCU */
int __srcu_read_lock(struct srcu_struct *ssp)
{
this_cpu_inc(ssp->sda->srcu_lock_count[idx]); ...
}
/* Preemptible RCU */
void __rcu_read_lock(void)
{
current->rcu_read_lock_nesting++; ...
}以上是关于Linux中的RCU机制的主要内容,如果未能解决你的问题,请参考以下文章